.png)
출처 : Dive into Deeplearning
Overview
matrix fatorization(이하 MF)도 훌륭한 성능을 보이지만 근본적으로 linear model(선형모델)이다. 이러한 모델은 사용자의 선호도를 예측하는 것과 같은 복잡하고 비선형적인 데이터를 잘 다루지 못한다. 그리하여 이번 section에서는 AutoReC (nonlinear neural network collaborative filtering model : 비선형 신경망 CF 모델)을 소개하고자 한다. 이 모델은 Explicite Data를 기반으로 autoencoder 아키텍쳐로 CF를 구성하고 CF를 비선형에 적용될 수 있게 한다. 이는 MF의 한계를 극복하고 표현을 더 풍부하게 만든다.
AutoRec은 autoencoder와 똑같은 구조를 가지고 있지만 다른 점이 있다. autoencoder는 hidden layer에 input을 저차원으로 압축하는 역할을 하지만, AutoRec은 users/items를 저차원으로 embedding하기 보다는 interaction matrix를 input으로 output layer에 복원하는 것에 초점을 둔다. 이는 hidden layer보다 output layer에 집중했다는 것과 같은 의미이다.
AutoRec은 부분적으로 관측된 interaction matrix를 input으로 하여 완성된 rating matrix를 복원하는것을 목적으로 한다. AutoRec에는 user-based/item-based로 두개의 종류가 있다. 본 section에서는 item-based AutoRec을 소개한다.
16.4.1 Model
- AutoRec 수식
위의 식은 hidden layer가 한개 있는 autoencoder 모델의 수식과 동일하다.
- loss function(RMSE) 수식*** 추가 사항이 기호의 의미는 관측된 rating의 weight만 back propagation에 기여한다는 의미이다. 자세한 설명을 아래 코드 설명에 기술되어 있다.
16.4.2 Implementating the Model
from torch import nn
class AutoRec(nn.Module):
def __init__(self, num_hidden, num_users, dropout=0.05):
super(AutoRec, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(num_users, num_hidden, bias = True),
nn.Sigmoid(),
# nn.ReLU(True),
nn.Dropout(dropout)
)
self.decoder = nn.Sequential(
nn.Linear(num_hidden, num_users, bias=True),
# nn.ReLU(True),
)
self.type = type
def forward(self, input, type='train'):
x = self.encoder(input)
pred = self.decoder(x)
if type == 'train': # Mask the gradient during training
return pred * torch.sign(input)
else:
return pred[keypoint!]
- activation : sigmoid
- Dropout : 0.05 (과적합 방지) ⇒ 0.05퍼센트의 wegith를 0으로 처리해 일반화 성능을 높인다.
- 위의 RMSE 수식에서 관측된 rating의 weight만 backpropagate 하는 코드
forward의 if문 : 관측된 rating만 모델 학습에 기여하기 위해 관측되지 못한 input은 지운다.
pred * torch.sign(input)
# np.sign : x<0 -> -1, x==0 -> 0, x>0 -> 1 # rating의 점수를 모두 1로 바꿔주는것
# pred * input : 관측된 rating만 pred로 출력하기 위해 (관측O : 1, 관측X : 0)16.4.3 Evaluator
- test inference
def evaluator(net, test_iter, device):
loss = 0
for i, values in enumerate(test_iter):
x = values.to(device).float()
output = net(x, type='test')
loss += loss_func(output,x).cpu().detach().numpy()
return loss/(i+1)16.4.4 Training
- Data preparing : inference matrix (user*item)
import torch
from torch.utils.data import DataLoader
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# Load the MovieLens 100K dataset
df, num_users, num_items = read_data_ml100k()
train_data, test_data = split_data_ml100k(df, num_users, num_items)
_, _, _, train_inter_mat = load_data_ml100k(train_data, num_users,
num_items)
_, _, _, test_inter_mat = load_data_ml100k(test_data, num_users,
num_items)
train_iter = DataLoader(train_inter_mat, shuffle=True, batch_size=256)
test_iter = DataLoader(test_inter_mat, shuffle=True,batch_size=256)- training
# param
lr, num_epoch, weight_decay, num_hidden = 0.002, 100, 1e-5, 500
net = AutoRec(num_hidden, num_users).to(device)
loss_func = nn.MSELoss()
optimizer = torch.optim.Adam(net.parameters(), lr = lr, weight_decay=weight_decay)
from tqdm import tqdm
train_arr, test_arr = [], []
for epoch in tqdm(range(num_epoch)):
train_loss = 0
test_loss = 0
for i, x in enumerate(train_iter):
x = x.to(device).float()
# ===================forward=====================
output = net.forward(x)
loss = loss_func(output,x)
# ===================backward====================
optimizer.zero_grad()
loss.backward()
optimizer.step()
# =================loss calculate==================
train_loss += loss.cpu().detach().numpy()
train_arr.append(train_loss/(i+1))
test_arr.append(evaluator(net, test_iter, device))- visualization
import matplotlib.pyplot as plt
plt.plot(val_epoch_loss_lst, label='train loss')
plt.plot(train_epoch_loss, label='val loss')
plt.legend()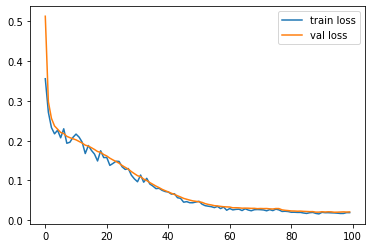
16.4.5 Summary
- 우리는 matrix factorization 알고리즘을 autoencoder로 대체할 수 있다. 이는 비선형 레이어와 dropout 정규화를 포함한다.
- MovieKLens 100K 데이터셋을 사용한 실험에서 AutoRec은 MF 보다 더 뛰어난 성능을 보인다.
16.4.6 Exercises
- AutoRec의 hidden dimension 다양하게 실험하여 모델 성능에 미치는 영향을 비교하여라.
- hidden layer를 더 추가해봐라. 모델 성능을 향상시켰는가?
- decoder와 encoder의 활성화 함수에 더 좋은 조합이 있었는가?(다른 활성 함수 적용)
의문점
dive into deeplearning의 AutoRec 부분을 공부하며 생긴 여러 의문점이 생겼다.
1. 모델의 수식과 코드가 일치하지 않는다.
16.4.1 model 부분의 모델 수식에서 적용된 decoder의 활성화 함수를 코드에서는 적용하지 않았다. 16.4.6 Exercises의 3번째 제안사항과 더불어 실험을 진행하였다.
- Sigmoid
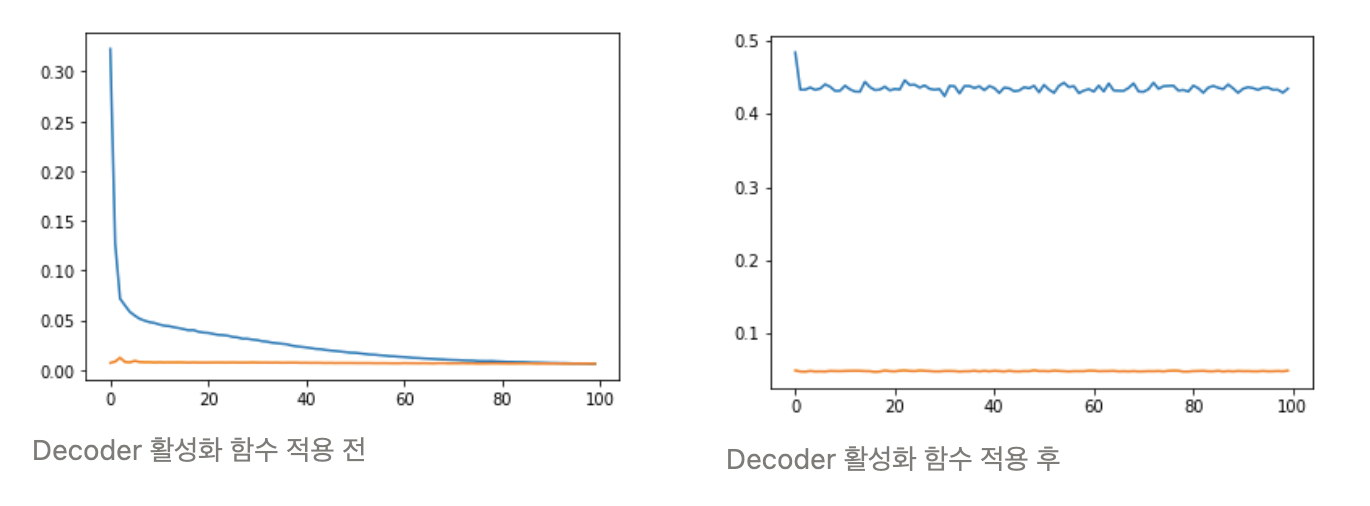 => Decoder를 적용하고 더 성능이 안좋아졌다.
=> Decoder를 적용하고 더 성능이 안좋아졌다. - ReLU
 => Decoder를 적용하든 안하든 별로 차이가 없다.
=> Decoder를 적용하든 안하든 별로 차이가 없다.
전체적으로 Sigmoid보다는 ReLU를 적용하는 것이 데이터 학습에 더 적합한 것으로 보인다.
2. input, target 데이터가 잘못 들어가고 있다.
이전 챕터인 MF와 input이 똑같이 들어가는 코드이다. 모델 구조상 MF는 user+item+rating의 형태로 들어가고 AutoRec은 user*item interection 행렬이 들어가게 되는데 말이 안된다고 생각하여 제대로 코드를 바꾸어 진행하였다.
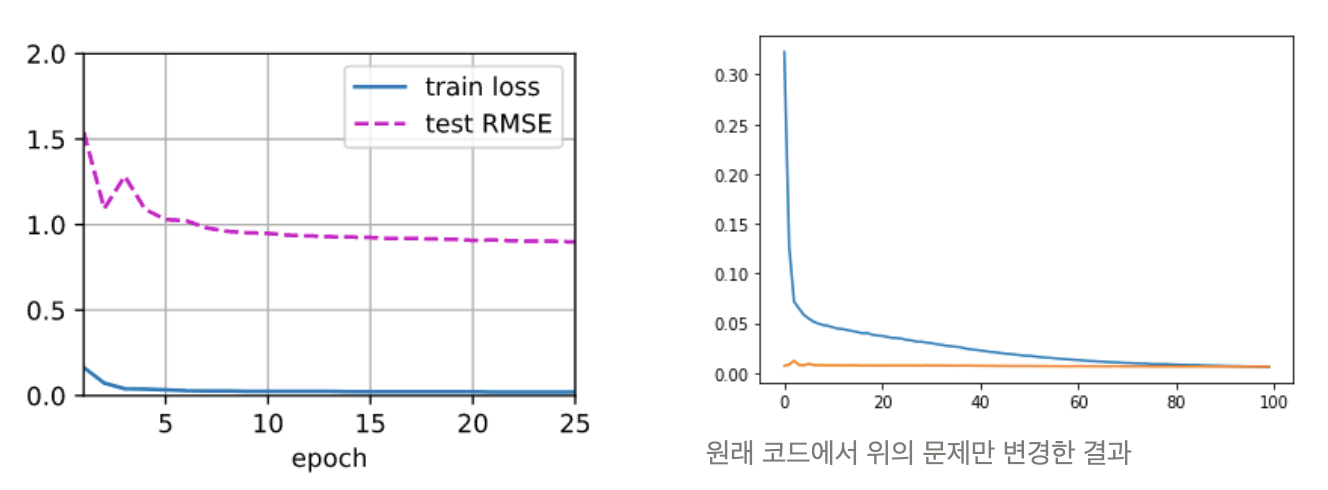
그 결과 본문의 loss 보다 더 좋은 성능을 모델을 만들 수 있었다.
3. np.sing 코드는 test 에도 적용되어야 한다.
np.sign이 training 부분에만 적용이 되어있다. 생각을 해보면 AutoRec의 경우 input데이터의 관측된 데이터를 올바르게 복원하는 데 초점이 있고 학습이 잘 되는지 판단하는 기준인 test loss는 이 데이터의 loss를 판단해야 한다. 하지만 코드에서는 모든 데이터의 loss 를 계산하고 있고 이는 학습이 되지도 않는 non-observed 데이터인 0과 생성된 데이터의 loss 를 계산하여 결과적으로는 절대 줄어들지 않는 loss를 만들어낸다. 이는 전체 모델의 학습 경향성을 파악하기 어려워 제 기능을 못한다고 판단하여 둘을 비교하는 실험을 하였다.
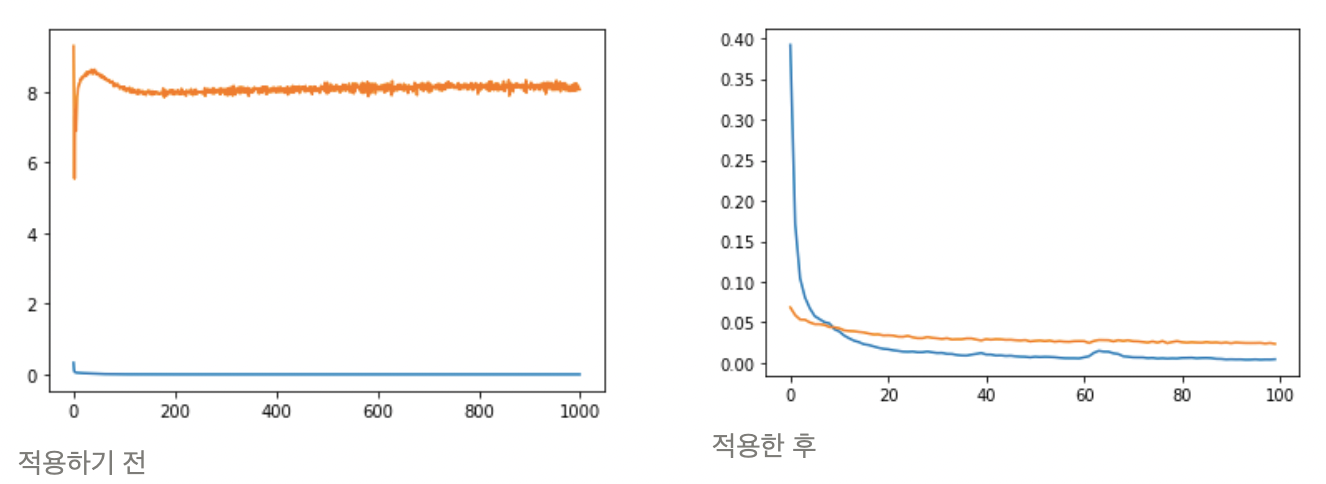
위의 해결방안으로 해본 결과 당연하게 기존에 비해 loss가 급격하게 줄어들고 학습의 경향성도 파악할 수 있었다.
