🖊️Abstract 🖊️
We explore how generating a chain of thought—a series of intermediate reasoning
steps—significantly improves the ability of large language models to perform
complex reasoning. In particular, we show how such reasoning abilities emerge
naturally in sufficiently large language models via a simple method called chain-of-thought prompting, where a few chain of thought demonstrations are provided as
exemplars in prompting.
Experiments on three large language models show that chain-of-thought prompting
improves performance on a range of arithmetic, commonsense, and symbolic
reasoning tasks. The empirical gains can be striking. For instance, prompting a
PaLM 540B with just eight chain-of-thought exemplars achieves state-of-the-art
accuracy on the GSM8K benchmark of math word problems, surpassing even
finetuned GPT-3 with a verifier.
📖 세 줄 요약 📖
❔ 질문 ❔
왜 이 논문을 선택했나요?
거대 언어모델의 성능을 높이는 여러 방법 중 프롬프트를 활용하는 방법에 관심이 생겼고 실제로 성능향상을 보인 좋은 방법론이 있다고 해서 흥미가 생겼다.
어떤 문제를 해결하는 논문인가요?
기존의 언어모델(gpt-3)가 잘 해결하지 못한 ‘추론’ task에서의 성능을 ‘Chain-of-Thought Prompting’ 이라는 방법으로 향상시켰다. 여기서 추론 task란 산술, 상식, 상징적인 추론과 같은 task들을 말한다. 기존엔 추론 성능을 올리기 위해 거대한 데이터셋을 추가하고 모델 크기를 늘렸으나 유의미한 효과를 보지 못했다고 한다.
왜 해당 문제를 푸는 것이 중요한가요?
거대 언어모델이 해결할 수 있는 여러 문제들 중 유독 추론 task에 약세를 보인다. 인간이 문제를 풀 때 풀이과정을 거쳐가며 최종적인 답안을 내듯이 언어모델이 인간의 사고방식을 비슷하게 흉내낸다면 그 속에서 생각치못한 해답과 가치를 발굴해낼 수 있을 것이다.
기존 연구가 어느정도로 이루어졌나요?
기존 언어모델들은 처음부터 중간단계의 자연어를 생성하는 방법을 고안하거나 pre-trained된 모델을 fine tuning하거나, neuro-symbolic 이라는 방법을 사용했다.
또한 프롬프트를 활용한 few-shot learning이 학습 단에서 어느정도 이루어졌다고 한다. 이는 각 task마다 따로 언어모델을 학습시키는 것이 아닌 몇 개의 input-output 예제들을 통해 모델을 ‘prompt’하는 것을 의미한다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
언어모델이 추론문제에서 잘 작동하지 않고, 모델 크기를 늘려도 향상되지 않던 두 한계를 극복하기 위해 input과 output 사이에 chain of thought 라는 일종의 secondary window를 제공하여 reasoning step을 직접 추가해주었다. 이를 통해 언어 모델이 몇 개 안되는 예제들을 통해 추론 능력을 훨씬 상승시킬 수 있는 간단하고 강력한 방법을 제안했다.
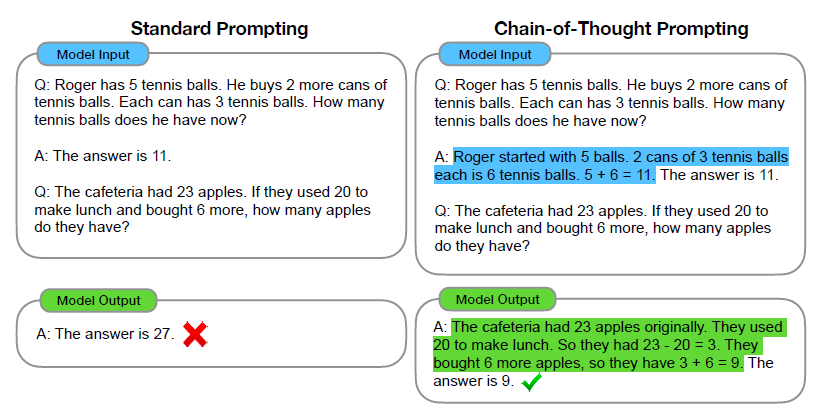
일반적으로 우리가 문제를 풀때 풀이과정을 단계적으로 적어가며 최종 답변으로 향하는 과정을 학습과정에 담았다는 것이 핵심이다.
“After Jane gives 2 flowers to her mom she has 10 … then after she gives 3 to her dad she will have 7…so the answer is 7.”
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
Chain-of-thought 주요 특징
- 문제 상황을 중간 단계별로 구분하여 더 많은 추론이 필요할 경우 추가 자원을 할당할 수 있다.
- 최종 답으로 가는 과정을 보여주므로 답이 틀린 경우 어디서 틀렸는지 디버깅할 수 있고 왜 이런 답이 나왔는지를 논리적이고 가시적으로 보여준다.
- 수학 문제, 상식 추론, 상징 조작과 같은 추론 task에서 활용 가능하다.
- 기존 언어 모델들에 chain-of-thought sequence 예제들을 포함시키는 것만으로 적용시킬 수 있다.
모델
- 기본적으로 모든 실험 결과는 inference-time에서 이루어진다.
- 즉, 각각의 모델들은 그대로 가져오고 추론과정에서 프롬프트로 추가해준 것이다.
- GPT-3(text-ada-001, text-babbage-001, text-curie-001, and text-davinci-002)
- LaMDA(442M, 2B, 8B, 68B, 137B)
- PaLM(8B, 62B, 540B)
- UL2 20B
- Codex(code-davinci-002)
- 프롬프트 예시

실험 결과
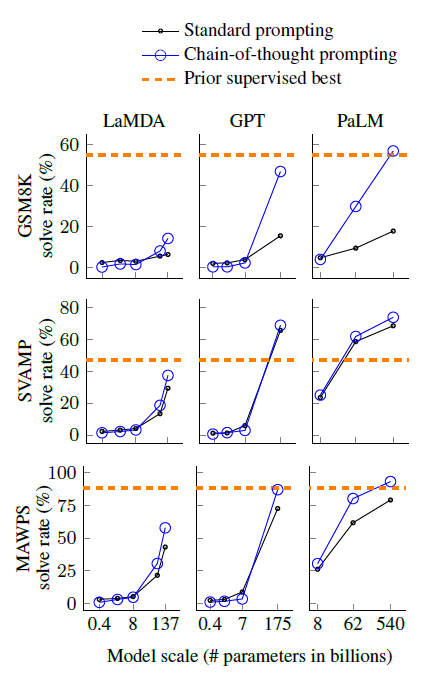
- standard prompting과 비교해서 보여준다.
- 작은 모델엔 별 효과가 없었다.
- PaLM 540B 모델이 GSM8K, SVAMP, MAWPS 벤치마크에서 SOTA를 찍었다.
- 왜 잘되는지 더 이해하기 위해 직접 100개의 output(맞춘거 못맞춘거 반반)을 뽑았다.
- 맞춘 경우 : 우연히 답을 맞춘 2개 정도 제외하면 논리적이게 나왔다!
- 못맞춘 경우 : 46%는 거의 맞았으나 사소한 실수, 54%는 의미론적인 이해나 일관성
에서 문제가 생겼다.
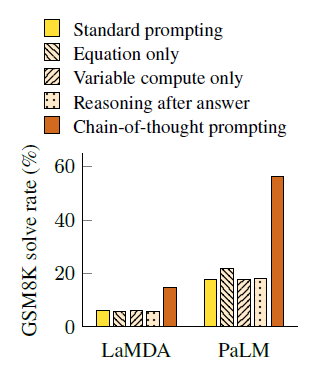
Ablation Study(인과관계 추론)
- 직접 모델학습이 없어서 그런지 결과가 잘 나온것만 강조하지 않고 왜 이런 결과가 나온 것인지 세세하게 다뤄주는 모습을 보인다.
- 방정식만 프롬프트로 추가해주는 것은 큰 의미가 없었다고 한다.
- 이는 자연어로 이루어진 프롬프트, 즉 chain-of-thought 가 필요하다는 뜻이다.
- 길이 동일하게 dot(…)만 찍어서(variable compute) 단순히 연산이 늘어서 성능이 좋아진건가 확인했다. 당연히 전혀 아니라고 떴다…
- 사전 학습된 지식에 잘 접근하게 만드는 방식이니 실제로 그런지 확인해봤다.
- chain-of-thought prompt를 답변 이후에 줘봤으나 baseline이랑 차이가 없었다.
- 즉, 실제로 잘 적용되어 성능이 향상되었음을 알 수 있다.
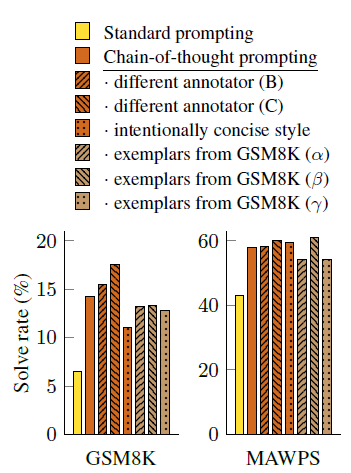
Robustness
- 해당 실험에서만 잘되는 것일수도 있으니 완전히 독립인 다른 annotator B와C를 활용해 robust하게 적용되는 방법인질 확인해봤다.
- 3개 모두 standard prompting보다 월등히 높아졌고 robust함을 보여준다.
Commonsense Reasoning
- 상식 추론 task도 진행했고, CSQA와 StrategyQA 에서 좋은 성적이 나왔다고 한다.
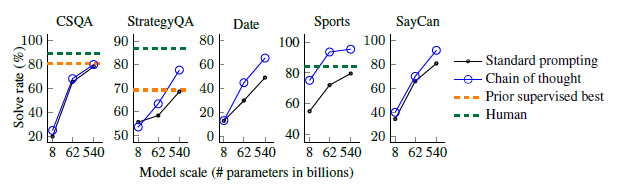
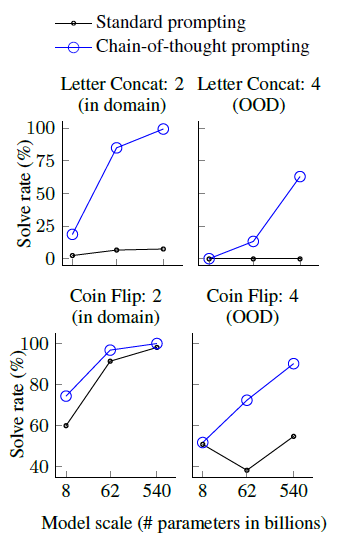
Symbolic Reasoning
- Last letter concatenation(마지막 글자 이어붙이기)와 Coin flip(마지막 코인 뒤집혔나 안뒤집혔나?)를 통해 확인했다. 사람은 쉽게 맞추지만 모델에겐 어렵다고 한다.
- Amy Brown —> yn
- A coin is heads up. Phoebe flips the coin. Osvaldo does not flip the coin. Is the coin still heads up? —> no
- PaLM 540B 모델의 경우 거의 100% 다 맞춘다고 한다.
- 여전히 작은 모델들은 잘 못한다.
결론과 시사점을 적어주세요
Chain-of-Thought prompting은 거대언어모델의 multi-step 추론을 유도하는 아주 간단한 메커니즘이다. 3개의 분야에서 좋은 성능 향상과 robust함을 보였고 단순히 기존 언어모델에 prompt를 추가함으로써 이룩한 결과이다.
이는 우리의 표준적인 언어모델의 성능이 저평가되어있고 더 향상될 여지가 있음을 보여준다. 또다른 방식이나 모델의 크기에 따라 어떻게 변화될지 모른다.
하지만 인간의 사고방식을 모델에 적용해본 것이 실제로 모델이 추론했음을 보장하진 않는다. 또한 정답을 무조건 맞추지 못하고 모델 크기에 따라 효과가 다르므로 범용성이 뛰어나진 않는다. 추론을 위한 대표적인 샘플들을 만드는 비용 또한 고려해봐야 할 것이다.
인간의 사고방식을 언어모델에 적용시키고자하는 시도가 굉장히 놀라웠다. 마치 실제로 생각하는 것처럼 느껴지는 것만 같은 결과들을 보면서 거대 언어모델이 가지고 있을 잠재력이 어디까지인지 더 궁금해졌다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- LaMDA
- majority voting(=beam search)
- State of the Art
