🖊️Abstract 🖊️
Natural language understanding comprises a wide range of diverse tasks such
as textual entailment, question answering, semantic similarity assessment, and
document classification. Although large unlabeled text corpora are abundant,
labeled data for learning these specific tasks is scarce, making it challenging for
discriminatively trained models to perform adequately. We demonstrate that large
gains on these tasks can be realized by generative pre-training of a language model
on a diverse corpus of unlabeled text, followed by discriminative fine-tuning on each
specific task. In contrast to previous approaches, we make use of task-aware input
transformations during fine-tuning to achieve effective transfer while requiring
minimal changes to the model architecture. We demonstrate the effectiveness of
our approach on a wide range of benchmarks for natural language understanding.
Our general task-agnostic model outperforms discriminatively trained models that
use architectures specifically crafted for each task, significantly improving upon the
state of the art in 9 out of the 12 tasks studied. For instance, we achieve absolute
improvements of 8.9% on commonsense reasoning (Stories Cloze Test), 5.7% on
question answering (RACE), and 1.5% on textual entailment (MultiNLI).
📖 세 줄 요약 📖
- GPT-1 논문
- Decoder Based multi-layer model
- 적은 find-tuning으로도 여러 task에 적용시킬 수 있는 방법
❔ 질문 ❔
왜 이 논문을 선택했나요?
NLP 시장을 선도하고 있는 GPT-4모델의 decoder base 구조를 처음 제안하고 당시엔 아직 익숙치 않았던 pre-train과 fine-tuning 개념을 잘 정립한 논문이라고 생각했다.
어떤 문제를 해결하는 논문인가요?
기존에 잘 해결되지 않았던 두 가지 문제, text representation을 학습시키는 optimization objective가 불분명하였고 target task에 어떻게 transfer시킬 것인지 명확하지 않았었다. 이를 unsupervised pre-training과 supervised fine-tuning을 합친 semi-supervised learning을 제안하여 해결하였다. 즉, 일반적으로 높은 성능을 낼 수 있는 특성을 학습시킨 후 특정 task에 맞게 조금만 바꾸어서 다양한 task에 적용가능하게 만든 모델이다.
왜 해당 문제를 푸는 것이 중요한가요?
- unlabeled text data는 풍부한데 반면 labeld data는 구하기 어렵기에 unlabeled data로 pre-training이 가능하다면 시간, 가격 측면에서 효율적이다.
- 약간의 변형만으로 특정 task에 적용시키는 범용성을 띄고 있다.
기존 연구가 어느정도로 이루어졌나요?
기존엔 unlabeld data로 단어 또는 구문 수준의 통계값을 연산하고 이를 supervised learning의 특성으로 사용하는 방식이 있었다.
좋은 initial parameter point를 제공하는 연구는 있었으나 LSTM 기준이라 제약이 많았다.
기존의 문제점을 해결할 수 있는 새로운 방향성을 잘 제안했나요?
- 단어 임베딩을 사용하는 방식이 좋은건 맞으나 단어보다 높은 차원의 의미를 포착해내는 방법을 시도했다.
- transformer 구조를 사용해 더 길고 성능이 좋아졌다.
- 기존에 비해 transfer 시 상대적으로 훨씬 적은 변화(ex. 모델 구조의 변화 거의 없이) 가능하게 더 넓은 범위의 task로 확장가능해졌다.
제안한 방식의 실험 또는 이론적 결과가 어떤가요?
Overview
- unlabeled data로 모델의 initial parameter를 찾기 위한 pre-training을 진행한다.
- 이 파라미터들을 target task에 fine-tuning시키는 과정에 적용시켜 사용한다.
- Transformer의 decoder만을 사용했다.
- RNN에 비해 긴 sequence와 다양한 task에서도 robust했다.
- 12개 task 중 9개에서 SOTA를 달성했다.
Framework
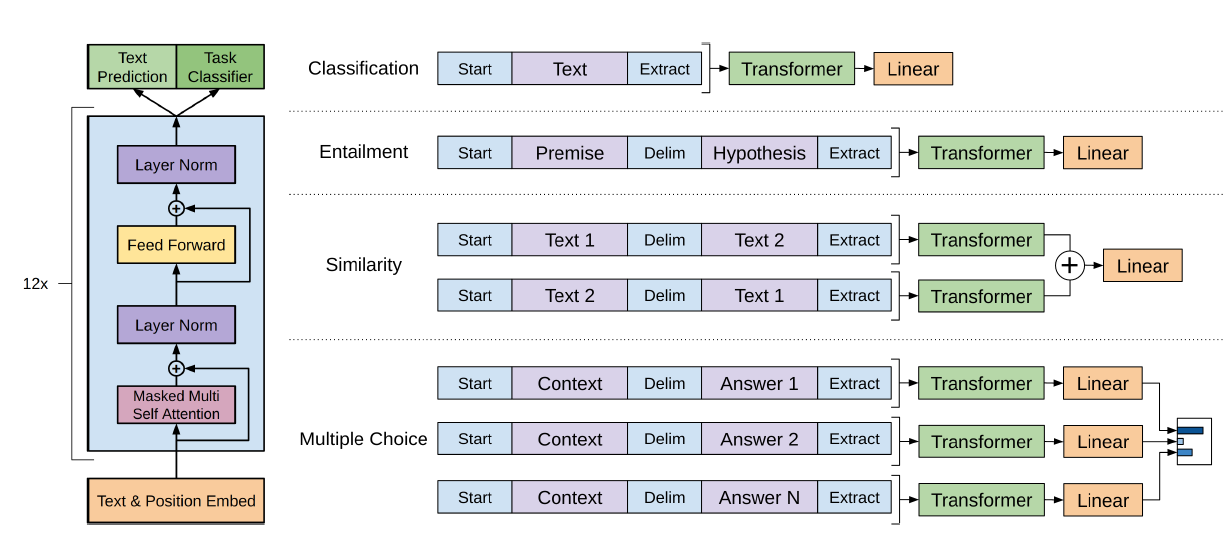
-
Unsupervised pre-training
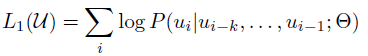
- 다음의 likelihood를 최대화하는 objective 사용
- k는 window size, SGD로 학습
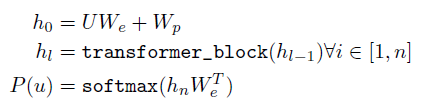
- multi-layer transformer decoder를 사용했다.
- : 토큰의 문맥 벡터
- : 토큰 임베딩 행렬
- : 포지션 임베딩 행렬
- n : layer 수
-
Supervised fine-tuning
-
labeled data로 fine-tuning 진행
-
마지막 decoder layer의 activation을 input으로 하는 linear layer 추가
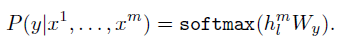
-
목적함수는 다음과 같다.
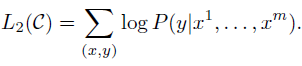
-
전체 과정에서 추가학습해야 하는 파라미터는 와 delimeter 토큰에 대한 임베딩밖에 없다.
-
Task-specific input transformations
- traversal-style approach
- 구조화된 입력을 pre-trained 모델이 사용할 수 있는 순서화된 시퀀스로 변환
- 약간의 변형만으로 여러 task에 적용 가능
- 모든 변형은 랜덤하게 초기화된 start, end token을 포함한다.
Experiments
-
Setup
- BookCorpus Dataset
- 12개 decoder layer(768dim, 12 head)
- Adam optimizer
- max lr : 2.5e-4 with 2000 updates using cosine schedule
- 100 epochs
- BPE encoding
- GELU activation func
-
fine-tuning
- 그대로 하이퍼파라미터 사용하되 lr는 6.25e-5로 바꾸고
- 분류는 dropout 추가
- epoch 3, batch size 32로 짧게 훈련했으나 충분!
-
Natural Language Inference(NLI)
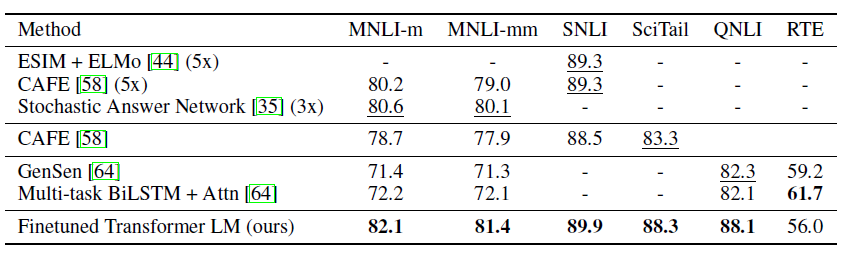
- 자연어 추론, 두 문장 쌍 간 관계를 contradiction, entailment, neutral로 구분
- 기존보다 우수한 것을 알 수 있음.
-
QA(Question Answering) and commonsense reasoning(상식 추론)
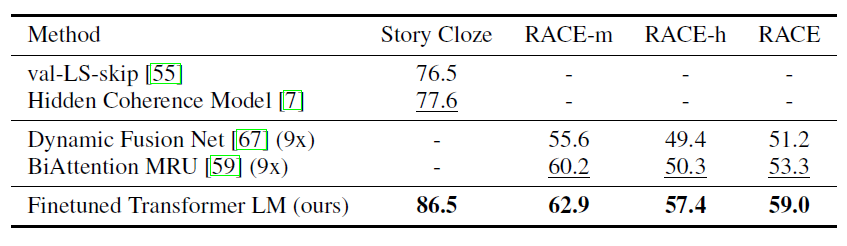
- 긴 context 포함된 데이터셋을 평가에 사용해서 long-range context에도 효과적임을 보였다.
- 성능 역시 기존보다 우수하다.
-
Semantic Similarity
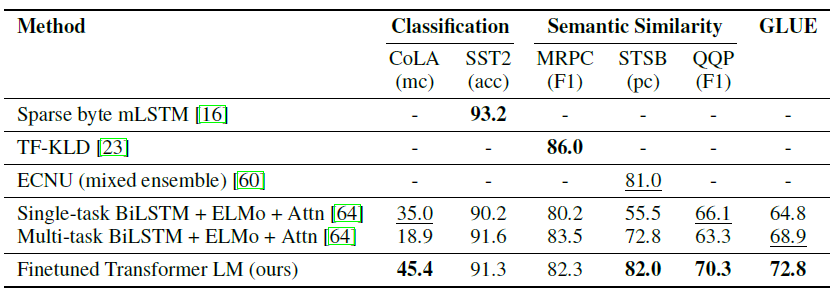
- 의미 유사성 분석
- 평가 데이터셋 세 개중 두 개에서 SOTA 달성!
-
Classification
- CoLA 데이터셋(문법 맞는가?)에서 SOTA 달성!
- SST-2(영화 코멘트 긍,부정)에서 SOTA 에 가깝게 접근
-
GLUE에서도 SOTA 달성했다!!
Analysis
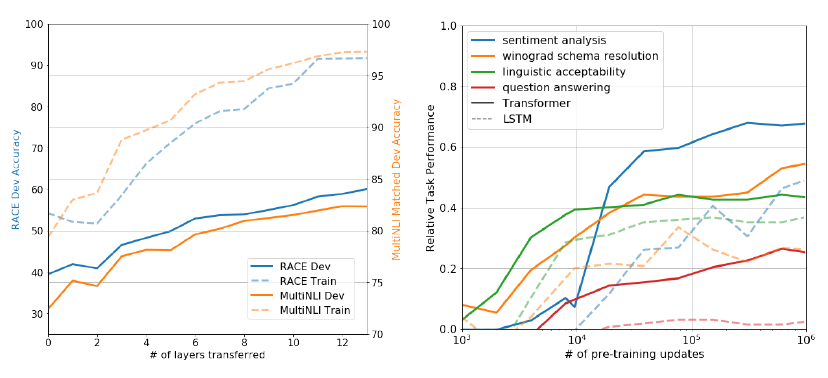
- MultiNLI에서 full transfer를 해보니 각각의 transformer 레이어가 9%까지 추가 향상이 나는걸 보면 각 레이어가 target task 수행 시 유용한 정보를 담고있다는 것을 알 수 있다.
- generative model의 performance가 unsupervised fine-tuning하지 않았을 때 성능을 보면 지속적으로 향상하고 LSTM에 비해 분산도 작은 것을 알 수 있다.
- transformer 구조의 inductive bias가 transfer에 도움이 된다.
- inductive bias : 학습 시 만나보지 않았던 상황에 대하여 정확한 예측을 하기 위해 사용되는 추가적인 가정
- 즉, 일반화가 잘 되었는가?
결론과 시사점을 적어주세요
기존보다 긴 텍스트에서 단어 개념 이상의 문맥, 문장 단위의 일반적인representation을 학습하여 적은 find-tuning으로도 여러 task에 적용시킬 수 있는 방법을 제안했다. 또한 unsupervised text 데이터로 학습이 가능해져서 더 정교하고 많은 데이터를 훈련시킬 수 있는 확장성 또한 겸비하게 되었다. 추후 GPT-4까지 발전하게되는 기본적인 틀을 마련한 기념비적인 논문이다.
같이 읽거나 알아보면 좋을 개념이나 논문 (키워드 + 링크)
- BERT
- GPT-2
- inductive bias
- GELU
