Collection Framework
1. Hashset
2. HashMap
3. ArrayList
자바에서는 데이터를 수집, 저장을 하고 사용할 수 있도록
틀(framework)을 제공한다
java.util.Collection
java.util.Set
java.util.List
java.util.Map
Set - 구슬 주머니라고 생각 , 비순차적 저장, 중복 데이터 x
- HashSet, TreeSet, LinkedHashSet(순서 유지 기능 존재)
Map - 비순차적 저장, 중복 데이터 허용
List - 순차적 저장 , 중복 데이터 허용
HashSet - 구슬 주머니
import java.util.HashSet;
import java.util.Iterator;
public class HashSetTest {
public static void main(String[] args) {
//제네릭을 사용하지않은 HashSet
HashSet hs = new HashSet();
hs.add("hello"); //hashset은 추가할때 add를 사용한다
hs.add(10); // new Integer(10) auto-boxing
hs.add(20);
hs.add(30);
hs.add(30);
//순서가 없기때문에 get으로 가져올수가없어 반복하는 iterator를 이용해 순회한다
Iterator it = hs.iterator(); // 반복자
while(it.hasNext()) { // 순회
System.out.println(it.next());
}
System.out.println("===========");
System.out.println(hs.size());
System.out.println(hs.isEmpty());
System.out.println(hs.remove(30));
System.out.println(hs.contains(30));
System.out.println(hs.size());
System.out.println("===========");
//이미 it 는 순회했기 때문에 다시 생성해 순회해야한다
it = hs.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
위에 방법으로 사용하게 되면 hs.add() 부분에서 오토박싱을 하여 문제가 되진않지만
보통 컬렉션 프레임워크를 사용할 때는 제네릭을 써준다
import java.util.HashSet;
import java.util.Iterator;
public class HashSetTest2 {
public static void main(String[] args) {
HashSet<Integer> hs = new HashSet<>();
//Generic 선언 <>
// 제네릭 = 일반화 시킨다 - hashset안에 들어간 내용은 이런거야라고 이야기 하는것
//hs.add("hello"); // Integer로 들어가기에 사용할 수 없다
hs.add(10); // new Integer(10) auto-boxing
hs.add(20);
hs.add(30);
hs.add(30);
//순서가 없기때문에 get으로 가져올수가없어 반복하는 iterator를 이용해 순회한다
//반복자도 integer 제네릭으로 만들어야된다
Iterator<Integer> it = hs.iterator(); // 반복자
while(it.hasNext()) { // 순회
System.out.println(it.next());
}
System.out.println("===========");
System.out.println(hs.size());
System.out.println(hs.isEmpty());
System.out.println(hs.remove(30));
System.out.println(hs.contains(30));
System.out.println(hs.size());
System.out.println("===========");
//이미 it 는 순회했기 때문에 다시 생성해 순회해야한다
it = hs.iterator();
while(it.hasNext()) {
System.out.println(it.next());
}
}
}
HashMap
HashMap<Integer, String> hm = new HashMap<>();
//해쉬 맵은 key값과 value 값을 저장하는 저장소
//hm.put("hello", 100);
hm.put(10,"tester");
// 해당자료를 가지고올때는 set과 다르게 get을 사용할 수 있다.
System.out.println(hm.get(10));
System.out.println(hm.get("hello"));
System.out.println(hm.get(1212));
Set<Integer> keys = hm.keySet(); // 키의 묶음
Iterator<Integer> it = keys.iterator(); // 키의 반복자
while(it.hasNext()) {
System.out.println(it.next());
}
for(Object o : keys) {
System.out.println(o);
}
Collection<String> values = hm.values();
for(String o : values) {
System.out.println(o);
}
it = keys.iterator();
while(it.hasNext()) {
Integer key = it.next();
String value = hm.get(key);
System.out.println(key + ":" + value);
}
}
}ArrayList
일반적인 배열이라 생각하면 된다
import java.util.ArrayList;
public class ArrayListTest {
public static void main(String[] args) {
ArrayList<Integer> al = new ArrayList<>();
al.add(100); // 추가
al.add(12);
al.add(21);
al.add(31);
al.add(142);
al.add(1,200);
al.remove(3);
for(int i = 0 ; i <al.size(); i++) {
System.out.println(al.get(i));
}
}
}Collection 에 저장할 클래스가 wrapper(integer, float,등) 클래스 가아닌경우.
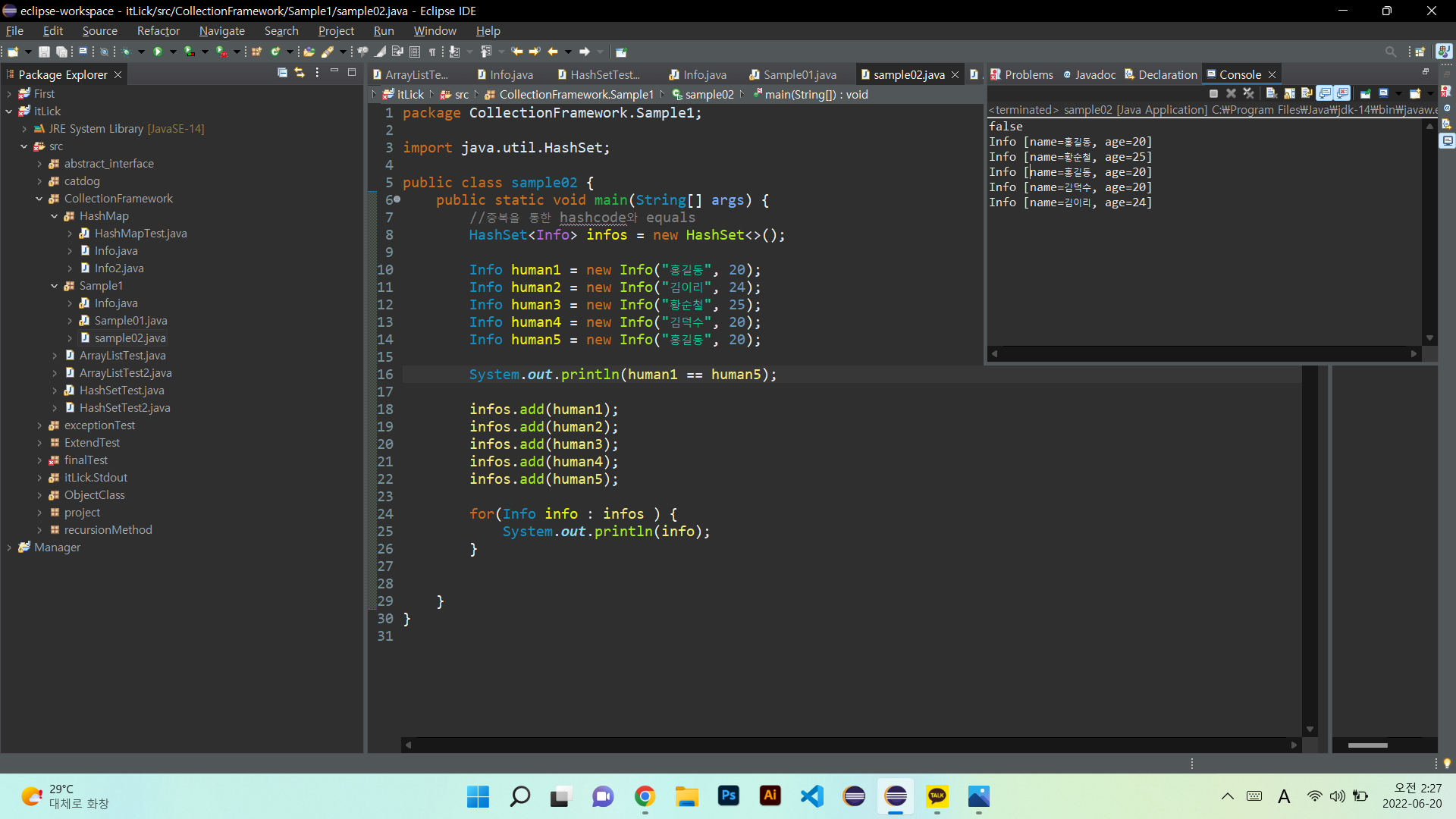
그림을 보게 되면 HashSet은 중복데이터가 있으면 저장하지 않지만
객체를 받는 collection인경우 같은데이터를 저장하게 됩니다.
-이러한 부분을 해결하는방법 -
1. 객체의 hashCode()결과를 비교 - 동일성
2. 1의 결과가 같으면 equals() 결과를 비교 아니면 다른 객체(동등성)
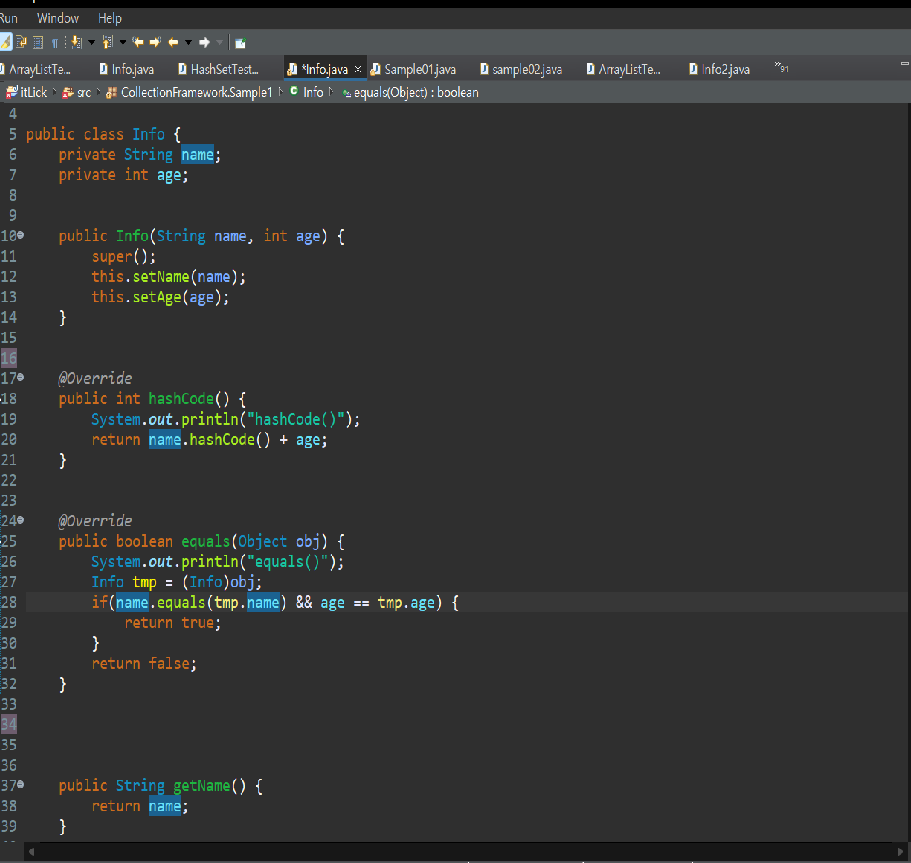
해쉬코드를 오버라이딩하여 그이름의 해쉬코드 + 나이를 더하는 것을 만들었습니다.
그 이후 비교하는 hashcode()와 기존 hashcode()와 같으면 equals() 결과를 비교하게되는데 이또한 오버라이딩 하여
비교하는 이름과 나이가 같으면 true를 반환해 같은 데이터라 판단하는 기능을 구현하였습니다.

웹 개발자의 기초부터 심화까지