개인 정리용으로 정확하지 않은 부분이 있을 수 있습니다.
레시피 페이지 추천 IBCF 구현
프로젝트 구현 목표는 특정 레시피 id와 가장 유사한 레시피 id 5개를 item간 유사도를 계산하여 추천하는 것이다. 유사도 계산할 때는 데이터 전처리와 가중치 계산이 필요하므로 데이터 분석에 특화된 python을 사용하였다. 그러기 위해서 node.js 서버와 python과의 통신이 필요하므로 Redis 메시지 브로커를 사용하여 데이터 전송을 처리했다. 전체 흐름은 아래와 같다.
💡workflow
- node.js 서버로 /recommendations/:id?recipeId=?로 get요청이 들어오면, 사용자들이 페이지에 체류한 시간, 즐겨찾기, 좋아요를 누른 데이터들과 추천 대상인 레시피 id를 Redis 채널 (recommendation_request)에 publish 한다.
- python 스크립트에 Redis 리스너 (recommendation_request 구독)에서 받은 데이터로 pandas 데이터 프레임을 생성하고 데이터 전처리와 함께 레시피 id 간의 코사인 유사도를 계산하고 가장 유사한 레시피 id 5개를 선택해서 Redis 채널 (recommendation_response) publish한다.
- node.js 서버에서 Redis 리스너 (recommendation_response 구독)에서 데이터를 받고, 5개의 유사한 레시피 id를 json으로 클라이언트에 응답한다.
1. 데이터 수집 구현
협업 필터링은 레시피 조회나 좋아요와 같은 사용자 행동 데이터를 기반으로 추천한다. 그래서 레시피 방문 날짜, 체류 시간 (페이지에 머문 시간), 좋아요, 즐겨 찾기와 같은 사용자 행동 데이터 수집을 위해 스키마와 API를 구현해주었다. 이 API를 통해 클라이언트로부터 사용자 행동 데이터를 전송받아, DB (mongodb)에 저장된다. 아래는 Visit Schema이다.
visit schema
const mongoose = require("mongoose");
const VisitSchema = new mongoose.Schema(
{
recipeId: {
type: String,
required: true
},
userId: {
type: String,
required: true
},
// 얼마 동안 사용자가 레시피 페이지에 체류했는지
timeSpent: {
type: Number,
required: true,
},
visitTime: {
type: Date,
required: true,
default: Date.now
}
}
)
module.exports = mongoose.model("Visit", VisitSchema);
timeSpent는 체류 시간, visitTime은 언제 방문했는 지를 나타낸다. visitTime은 최근에 조회된 레시피들을 추천 가중치를 더 높이기 위한 변수이다. 쿠팡이나 유튜브와 같은 서비스에서도 최근에 관심있는 아이템들이 더 비중 높게 추천되는 모습을 볼 수 있는데 동일한 원리로 생각하면 될 것 같다. 이 외에 Favorite Schema, Like Schema는 맨 아래 github 코드를 참고하면 될 것 같다!
2. 데이터 전처리
아이템 협업 필터링에서는 각각의 아이템 (여기서는 레시피)간의 유사도를 측정하기 위해, item(행)-user(열) 행렬 데이터를 만들어야 한다. 그러기 위해서는 데이터 전처리 과정이 필요한데 아무래도 node.js보다 python이 데이터 처리나 유사도 측정 관련 레퍼런스들이 많아서 데이터 전처리 단계부터 유사도 측정은 python 스크립트로 구현했다.
그리고 각 애플리케이션간 실시간 데이터 통신이 필요하므로 메시지 브로커 역할인 Redis의 Pub/Sub 기능을 사용했다. python 스크립트에서 Node.js로부터온 메시지를 수신하는 코드는 다음과 같다.
recommendation.py
import redis
import json
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics.pairwise import cosine_similarity
conn = redis.Redis(host='localhost', port=6379, db=0)
pubsub = conn.pubsub()
pubsub.subscribe('recommendation_request')
...
for message in pubsub.listen():
if message['type'] == 'message':
requestData = json.loads(message["data"].decode("utf-8"))
recipeId = requestData['recipeId']
visits = requestData['visits']
favorites = requestData['favorites']
likes = requestData['likes']
visits_df = pd.DataFrame(visits)
favorites_df = pd.DataFrame(favorites)
likes_df = pd.DataFrame(likes)
# 각 레시피와 유저간의 상호작용을 나타내는 데이터프레임 생성
item_user_matrix = create_item_user_matrix(visits_df, favorites_df, likes_df)추천 대상이 될 recipeId와 사용자의 상호작용한 데이터가 담긴 Visit Schema, Favorite Schema, Likes Schema를 가져와서 데이터프레임을 생성한다. 그리고 item-user 행렬 생성을 위해 create_interactions_df 함수를 호출한다.
create_interactions_df
create_interactions_df 함수는 상호작용한 데이터 3개를 인자로 받고, 이것을 item-user 행렬 하나로 합쳐서 반환시키는 함수이다.
def create_item_user_matrix(visits_df, favorites_df, likes_df):
# (0)
timeSpentWeight = 0.5
favoriteWeight = 0.3
likeWeight = 0.2
# (1)
recipe_ids = pd.concat([visits_df['recipeId'], favorites_df['recipeId'], likes_df['recipeId']]).unique()
# (2)
item_user_matrix = pd.DataFrame(0, index=recipe_ids, columns=visits_df['userId'].unique())
# (3)
for idx, row in visits_df.iterrows():
item_user_matrix.loc[row['recipeId'], row['userId']] += row['timeSpent'] / visits_df['timeSpent'].max() * timeSpentWeight
for idx, row in favorites_df.iterrows():
item_user_matrix.loc[row['recipeId'], row['userId']] += 1 * favoriteWeight
for idx, row in likes_df.iterrows():
item_user_matrix.loc[row['recipeId'], row['userId']] += 1 * likeWeight
return item_user_matrix(0) 각 데이터에 대한 가중치이다. 코사인 유사도는 벡터의 크기를 고려하지 않고, 벡터의 방향만을 고려하므로 크게 영향을 줄 것 같지는 않지만 여러 항목에 대한 중요도를 어느정도 벡터의 방향에 반영할 수 있어 좀 더 정확한 추천 성능을 낼 수 있다고 한다.
(1) 여기서 각 스키마에 포함된 recipeId를 하나로 합친 이유는 하나의 행렬에 모든 레시피 id를 담기 위함이다. 이 과정을 생략했더니, 데이터 프레임을 하나로 합치는 과정에서 오류가 발생하여 이렇게 수정해주었다.
(2) 인덱스 (행)을 recipeId로, 열을 userId로 지정하여 아이템-사용자 행렬을 생성한다.
(3) DataFrame에 있는 행을 하나씩 참조하면서 사용자 채류 시간을 0~1단위로 범위를 조절해준다. 그리고 세 데이터 프레임 간의 비교를 위해 전부 0~1의 값을 가지도록 하고, 가중치를 곱해준다.
3. 유사도 측정 및 추천
recommend_recipes()
def recommend_recipes(item_user_matrix, recipeId):
# cosine_similarity = 각 행 (recipeId) 간의 코사인 유사도 구함
# (1)
cosine_similarities = cosine_similarity(item_user_matrix)
recipe_index = item_user_matrix.index.get_loc(recipeId)
# 현재 레시피와 가장 유사한 5개의 레시피를 찾음
# (2)
most_similar_recipes = cosine_similarities[recipe_index].argsort()[:-6:-1]
# 가장 유사한 5개의 레시피를 추천
recommended_recipes = item_user_matrix.iloc[most_similar_recipes].index.tolist()
return recommended_recipes(1) 코사인 유사도를 넘파이를 이용해 직접 계산할 수 있지만 scikit-learn 라이브러리에서 제공되는 코사인 유사도 함수를 사용하면 편하다. cosine_similarity 함수를 호출하면 각 아이템 (행)간의 유사도를 계산한 행렬이 반환된다. 아래는 레시피 5개를 대상으로 코사인 유사도를 측정한 행렬의 예시이다. 같은 레시피끼리는 유사도가 1인 것을 확인할 수 있다.
| 1.0 | 1.0 | 0.6788 | 0.0 | 0.0 |
| 1.0 | 1.0 | 0.67883 | 0.0 | 0.0 |
| 0.6788 | 0.6788 | 1.0 | 0.4073 | 0.3555 |
| 0.0 | 0.0 | 0.4073 | 1.0 | 0.8728 |
| 0.0 | 0.0 | 0.355 | 0.872 | 1.0 |
(2) 추천 대상이 될 recipe_index와 유사도가 높은 상위 5개의 레시피의 인덱스를 뽑는다.
(3) (2)에서 뽑은 인덱스의 recipeId를 가져와서 반환한다.
recommendation.py
item_user_matrix = create_item_user_matrix(visits_df, favorites_df, likes_df)
recommendations = recommend_recipes(item_user_matrix, recipeId)
conn.publish('recommendation_response', json.dumps(recommendations))마지막으로 추천 결과를 json으로 직렬화하여 'recommendation_response' 채널로 메시지를 전송하면, Node.js 서버에서 받아 클라이언트로 응답한다!
API 작동 테스트
아래 데이터 셋을 가진 상태에서 API 요청이 정상적으로 작동되는지 테스트 해보았다.
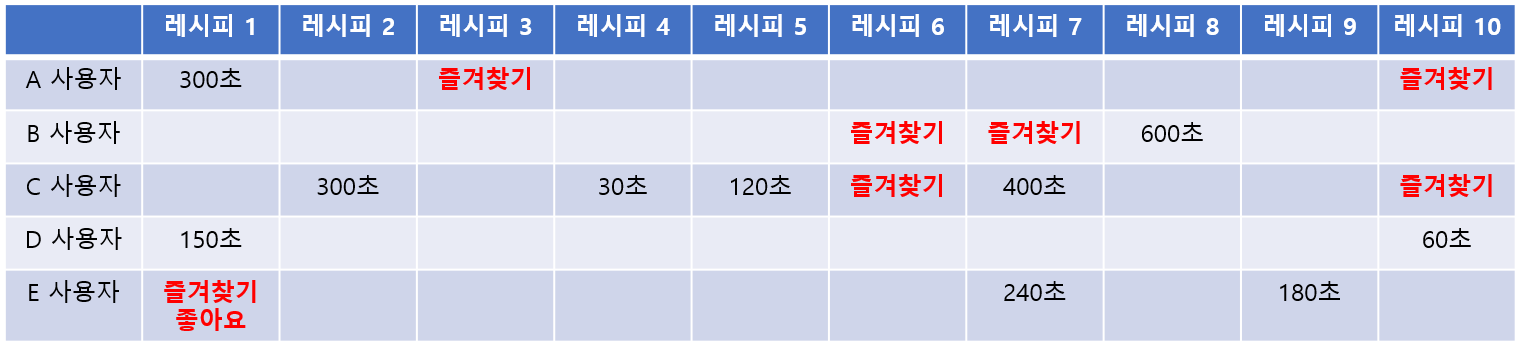
간단하게 1번 레시피를 추천 대상으로 하여 API로 요청해본 결과, 패턴이 유사한 [1, 3, 7, 9, 10] 레시피들이 정상적으로 응답됨을 확인할 수 있다.
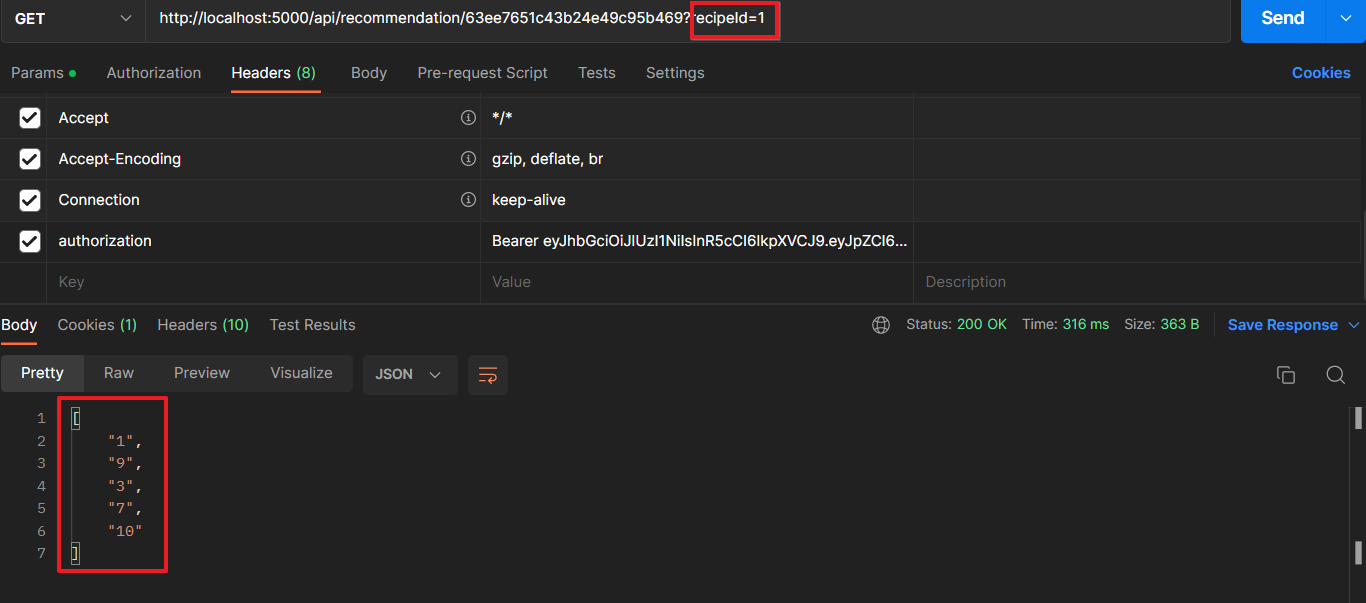
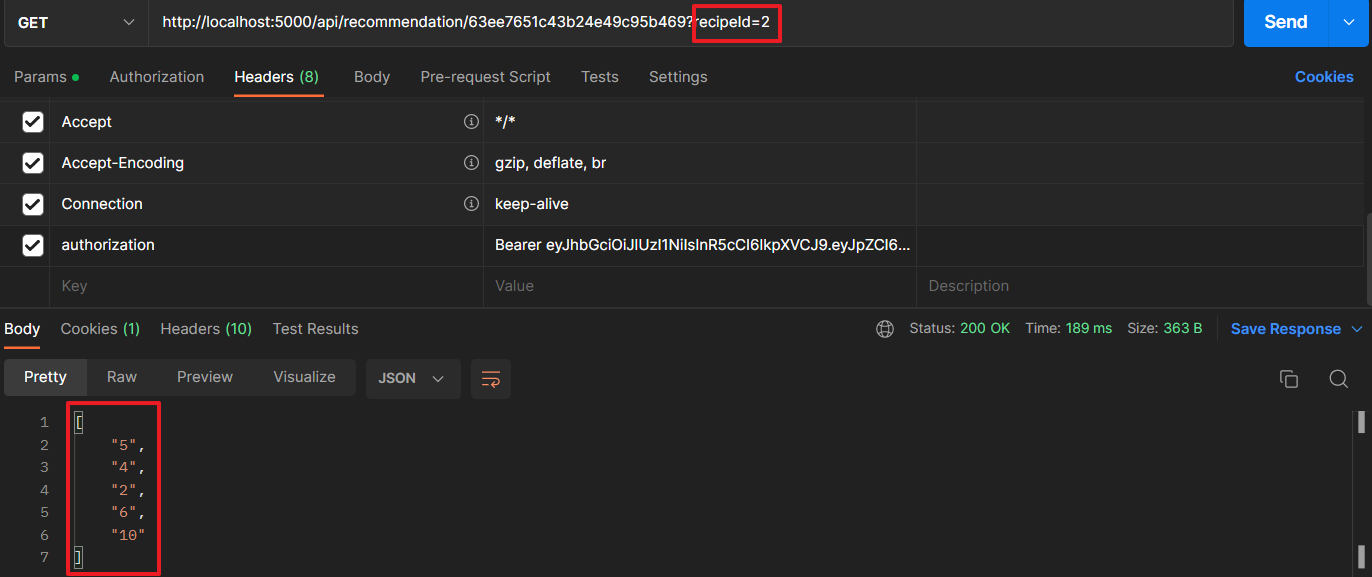
2번 레시피도 요청해보았다.
추천 시스템 성능 평가?
사실 위 테스트 가지고는 추천 시스템을 평가했다고 하기에는 민망할 정도다,, (API 작동 확인만 해본걸로..) 추천 시스템의 성능 평가 방법에는 크게 온라인 테스트와 오프라인 테스트 두 가지가 있다.
오프라인 테스트 (Offline Testing)는 이미 수집된 데이터셋을 이용해서 성능을 측정하는 방법이다. 이 방법에서는 RMSE, Recall, Precision 등의 평가 지표가 사용된다. 다만, 실제 상황이 반영되지 않기 때문에 일반적으로 오프라인 테스트로 평가한 뒤, 온라인 테스트 (Online Test)를 수행한다. 온라인 테스트는 실제 사용자를 대상으로 추천 시스템의 성능을 평가하는 방법이다.
개인적으로 오프라인 테스트를 해보고 싶은데 제대로된 데이터 셋 구성이 쉽지 않아 아쉽게도 못해본 상황이다. 또한 데이터를 분할하거나, 평가 지표에 대한 개념 이해가 부족하다. (관련된 자료를 찾아보니 주로 머신러닝에 사용되는 개념들이었다) 다음에는 실무에서 많이 사용되는 모델 기반 협업 필터링을 대규모 데이터셋 환경에서 다루어 보고 싶다.
Ref
https://ai-with-sudal-ee.tistory.com/6
https://towardsdatascience.com/item-based-collaborative-filtering-in-python-91f747200fab
