📚 기술로그 내용 정리
목차
Apache Cassandra 정리가이드
1. 개요
- Apache Cassandra는 대규모 분산 NoSQL 데이터베이스다.
- Facebook에서 시작되어 Apache Software Foundation에 기부된 오픈소스로 운영 중이다.
- 핵심 목표: 고가용성(High Availability), 선형 확장성(Linear Scalability), 무중단 서비스(Always On)
2. 아키텍처
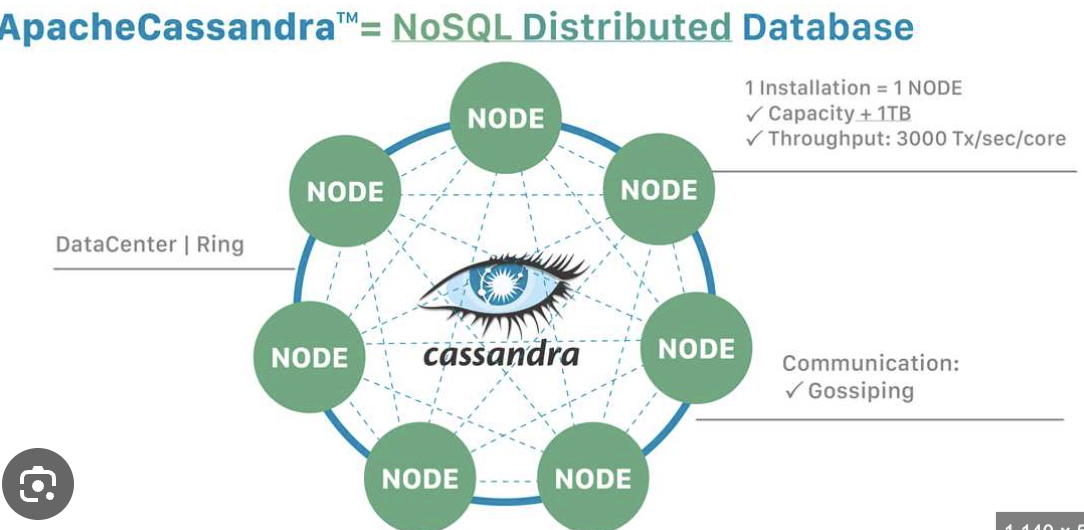
- Peer-to-Peer 구조
- 마스터/슬레이브 구조가 없고 모든 노드가 동등한 역할을 수행
- Gossip Protocol
- 노드 간 상태 정보를 교환하며 클러스터를 유지
- Partition & Replication
- 데이터를 파티션 키에 따라 분산 저장
- 복제 계수(Replication Factor)에 따라 여러 노드에 데이터 복제
- Consistency Level
- 읽기/쓰기 시 응답이 필요한 노드 수를 조절 (
ONE,QUORUM,ALL등)
- 읽기/쓰기 시 응답이 필요한 노드 수를 조절 (
3. 특징
3.1 장점
- 노드를 추가하면 선형적으로 확장 가능 (Scale-out)
- 대규모 쓰기 성능 최적화 → 로그, IoT, 센서 데이터에 강점
- 일부 노드 장애에도 서비스 지속 (Fault Tolerance)
- 멀티 데이터센터 복제를 통한 글로벌 서비스 운영 가능
3.2 단점
- 조인(Join) 불가능
- 다중 테이블 트랜잭션 한계
- 분석/애드혹 쿼리에 부적합 (Spark, Presto 연계 필요)
- 데이터 모델링은 반드시 쿼리 패턴 중심으로 설계해야 함
4. 주요 개념
- Partition Key : 데이터를 분산 배치하는 기준 키
- Replication Factor (RF) : 데이터 복제본 개수 (예: RF=3 → 3개 노드에 저장)
- Consistency Level : 읽기/쓰기 시 필요한 응답 노드 수
- SSTable & Compaction : 디스크 기반 데이터 구조와 병합 최적화 과정
5. 활용사례
- Netflix : 글로벌 사용자 스트리밍 로그, 메타데이터 저장
- Instagram : 메시징, 피드 저장소
- Spotify : 사용자 이벤트 로그, 추천 시스템
- IoT 플랫폼 : 센서 데이터 수집·저장
6. Cassandra vs 다른 DB
| 구분 | Cassandra | MongoDB | MySQL |
|---|---|---|---|
| 구조 | Column-Family | Document | RDBMS |
| 확장성 | 선형 Scale-out | 수평 확장 가능 | 주로 수직 확장 |
| 일관성 | 튜너블(ONE~ALL) | Eventual Consistency | Strong Consistency |
| 강점 | 대규모 쓰기 성능, 장애 복원력 | 유연한 Document 모델 | SQL, 복잡한 트랜잭션 |
7. 면접 질문 (주니어~미들 레벨)
- Cassandra는 RDBMS와 어떤 차이가 있는가?
- Cassandra의 튜너블 일관성(Consistency Level)은 어떻게 동작하는가?
- Cassandra에서 데이터 모델링을 할 때 왜 쿼리 패턴을 우선 고려해야 하는가?
- Cassandra는 어떤 워크로드에 적합하고, 어떤 경우 부적합한가?
- 노드 장애가 발생했을 때 Cassandra는 어떻게 데이터 정합성을 보장하는가?
8. 내부 동작 (추가 심화)
8.1 쓰기 경로 (Write Path)
- 요청 수신 → Commit Log에 먼저 기록 (Durability 보장)
- 메모리 테이블(MemTable)에 반영
- MemTable이 가득 차면 디스크에 SSTable로 플러시
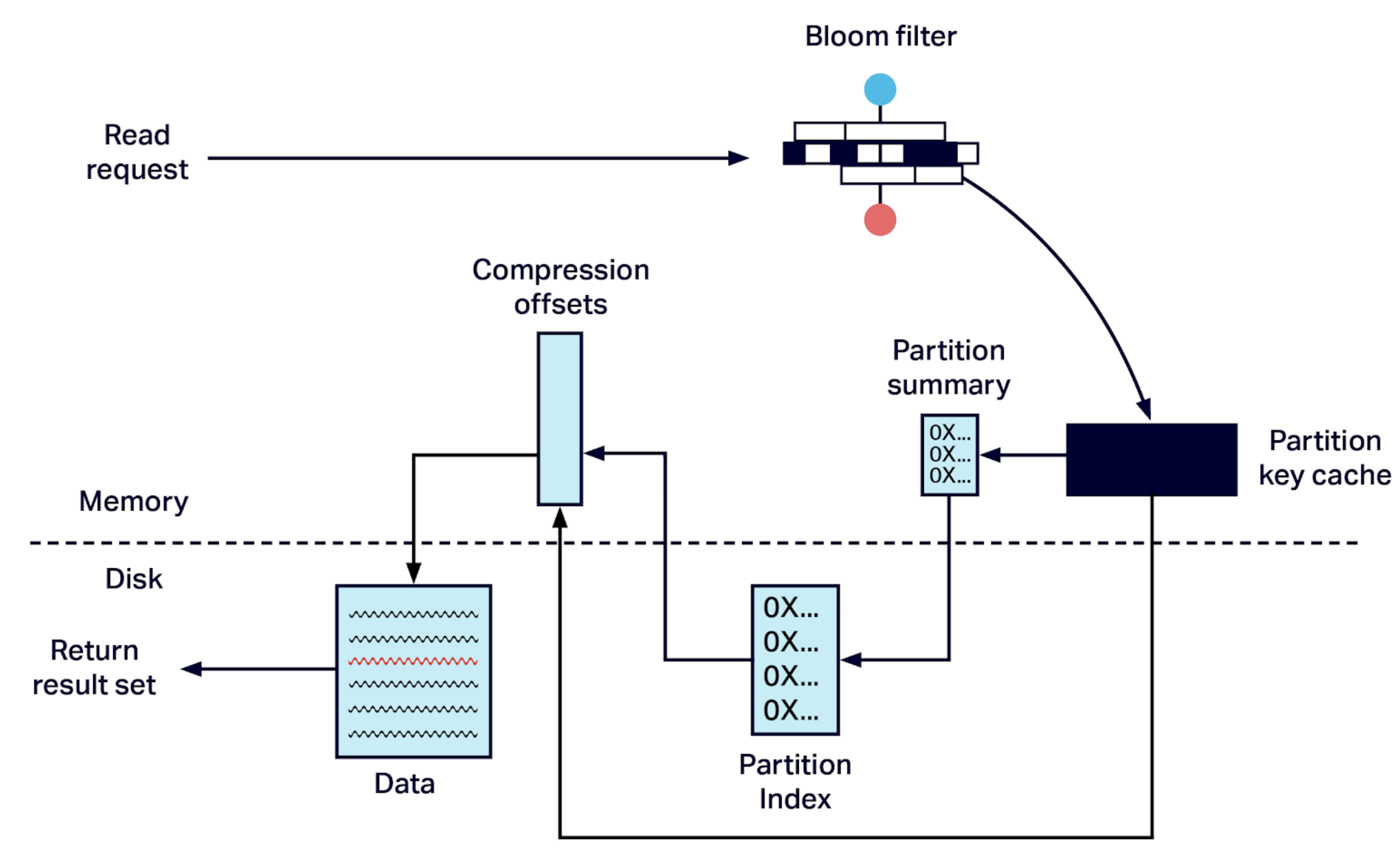
8.2 읽기 경로 (Read Path)
- 먼저 MemTable 확인
- Bloom Filter → 필요한 SSTable만 조회
- SSTable에서 데이터 읽고 Merge → 응답
8.3 Compaction
- 여러 SSTable을 병합하여 디스크 공간 최적화
- 중복 데이터/삭제된 데이터 정리
9. 분산 처리 메커니즘
- Consistent Hashing : 데이터 균등 분산 배치
- Replication Factor : 노드별 데이터 복제본 개수
- Hinted Handoff : 노드 장애 시 다른 노드가 임시로 데이터 보관 후 복구 시 전달
- Read Repair : 읽기 시 불일치 데이터 자동 정정
10. 운영/실무 포인트
- 클러스터 확장 시 자동 리밸런싱 → 노드 추가만으로 Scale-out
- 모니터링 : JMX, Prometheus + Grafana 대시보드 활용
- 장애 복구 : Consistency Level 조절로 가용성/일관성 균형 유지
- 백업/복구 전략 필요 (스냅샷 기반)
참고하면 좋은 포스팅
AWS(카산드라와 몽고 차이) https://aws.amazon.com/ko/compare/the-difference-between-cassandra-and-mongodb/
카산드라와 HBase차이점
https://aws.amazon.com/ko/compare/the-difference-between-cassandra-and-hbase/
아파치 카산드라
https://goyunji.tistory.com/95
한 번 훑기 좋음

정진, "어제보다 더 나은 오늘이 되자"