
N+1
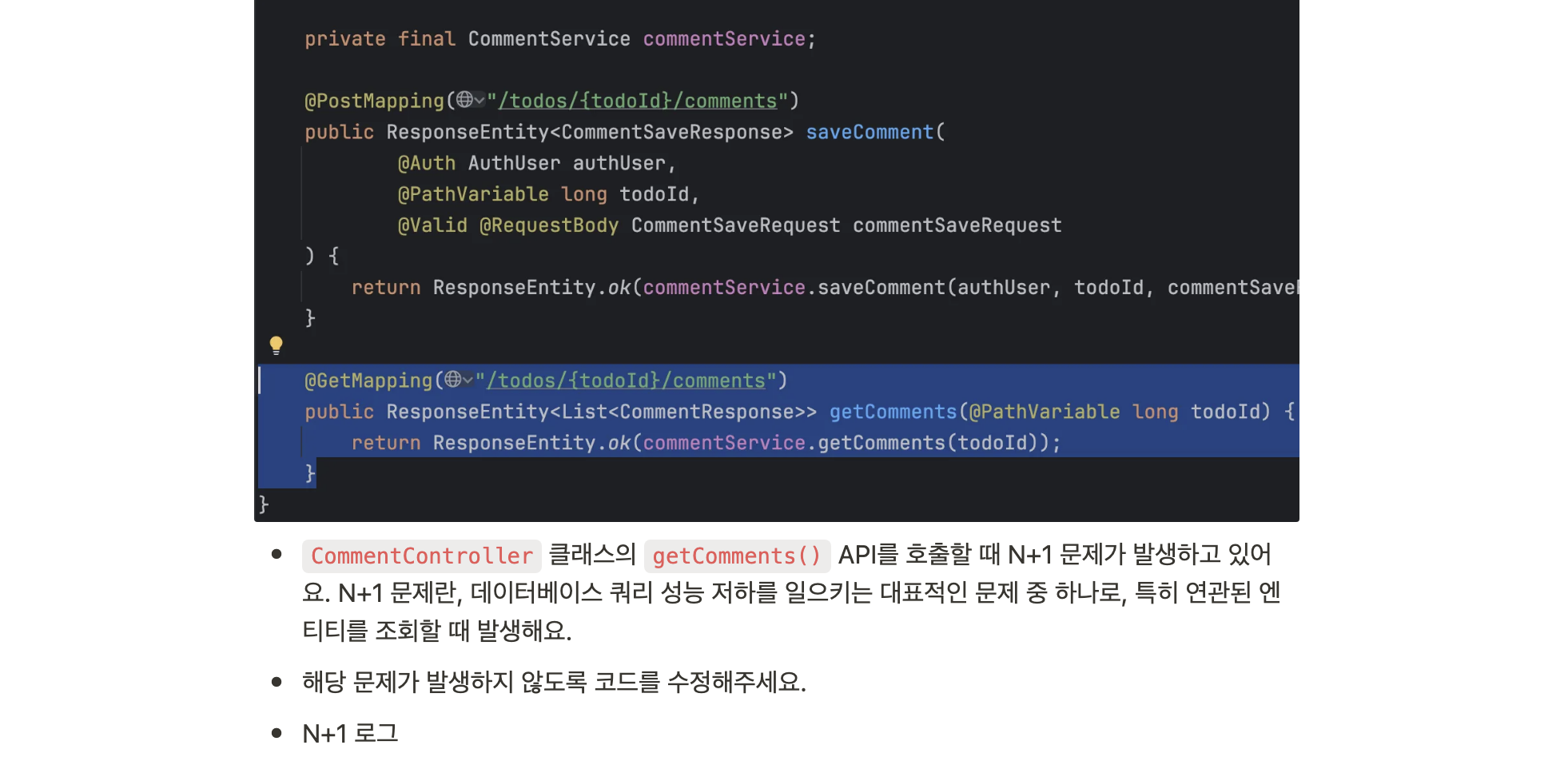

일단 이번에도 역시, 해당 과제를 수행하기에 앞서 필요한 개념을 먼저 정리하고 시작하도록 하겠습니다.
1. N+1 문제란?
- N+1 문제는 JPA의 기본적인 지연 로딩(LAZY Loading) 설정으로 인해 발생하는 성능 저하 문제입니다.
📌 그렇다면, 발생하는 원인은 ?
- 연관된 엔티티를 조회할 때 LAZY 로딩이 기본값으로 설정됨
- 부모 엔티티(댓글 리스트)를 가져온 후, 각 자식 엔티티(댓글의 User)를 개별적으로 추가 조회
- 결과적으로 N번 추가 쿼리가 발생하여 비효율적인 데이터 조회가 이루어짐
N+1 문제 발생 흐름
// Comment 테이블에서 특정 todoId에 해당하는 데이터 조회 (1개)
Hibernate: SELECT * FROM comments WHERE todo_id = ?
// User 테이블에서 각 댓글의 user 조회 (N번 반복)
Hibernate: SELECT * FROM users WHERE id = ?
Hibernate: SELECT * FROM users WHERE id = ?
Hibernate: SELECT * FROM users WHERE id = ?
...- 기본적으로 1개의 쿼리로 comment를 조회한 후, 각 comment에 연관된 User를 조회하는데 추가로 N번 쿼리가 발생하는 것이라고 보시면 됩니다.
- 이렇게 되면 성능 저하가 아주아주아주아주아주우주VERY하게 심각해집니다. ㅎㅎ
- 오죽하면, N+1 문제가 발생할 것 같은 코드를 구현하지 말자.
- N+1 문제를 해결하는 것도 좋지만 애초에 그럴 일을 만들지 말자는 말이 많이 나오기도 합니다 ㅎㅎ
2. 해결 방법
- JPQL FETCH JOIN을 사용하여 한 번의 쿼리로 모든 데이터를 가져오기
- Spring Data JPA의 @EntityGraph 활용하여 쿼리 최적화
- Batch Size 설정 (@BatchSize or application.yml 설정)
참고로, 저는 FETCH JOIN을 활용하는 방식으로 해결하겠습니다!
(추가로, @EntityGraph도 언급할 예정)
3. 개념 정리 (기 -> 필 -> 심)
그렇다면, 필요한 개념들은 무엇들이 추가적으로 있을까 ?
1) 기본 개념
JPA 연관관계 (@ManyToOne, @OneToMany)
→ 연관된 엔티티를 조회할 때 어떻게 동작하는지 이해해야 함
지연 로딩(LAZY)와 즉시 로딩ㅁ의 차이
→ 기본적으로 @ManyToOne(fetch = FetchType.LAZY) 설정이 되어 있음
쿼리 실행 흐름 분석
→ Hibernate가 어떻게 SQL을 실행하는지 이해 필요 (SHOW_SQL=true 설정)
2) 필수 개념
JPQL & FETCH JOIN 사용법
- SQL의 JOIN과 비슷하지만, JPA 엔티티를 활용하여 연관된 엔티티를 한 번에 조회 가능
- 해결 방법: FETCH JOIN을 사용하면 추가적인 쿼리 없이 한 번에 데이터 조회 가능!
Spring Data JPA @EntityGraph 활용
- @EntityGraph(attributePaths = {"user"})을 사용하면 N+1 문제 해결 가능
3) 심화 개념
Batch Size 설정
application.yml에서spring.jpa.properties.hibernate.default_batch_fetch_size=100설정 가능- 배치 크기를 설정하면 한 번에 여러 개의 엔티티를 조회하는 방식으로 N+1 문제를 완화 가능
QueryDSL 활용하여 최적화된 동적 쿼리 적용

이제 본격적으로 코드 수정 해보겠습니다.
첫 번째로 CommentRepository를 수정해야합니다. (JPQL FETCH JOIN 적용)
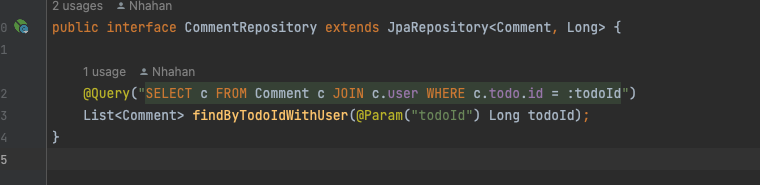
FETCH JOIN 추가함으로써 N+1 문제 해결했습니다.
(JOIN FETCH)로 수정
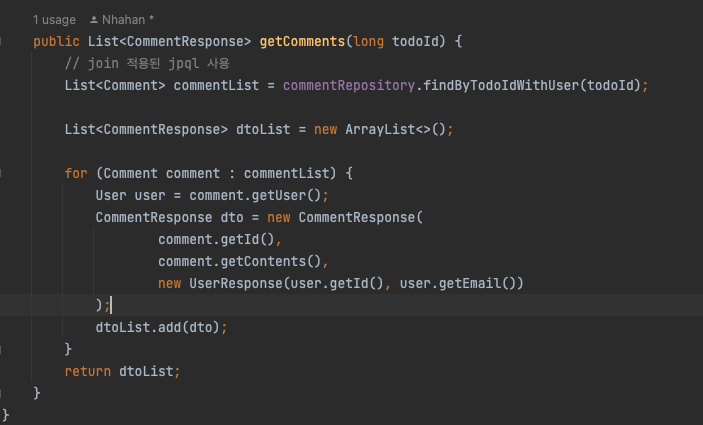
를 아래와 같이 수정.
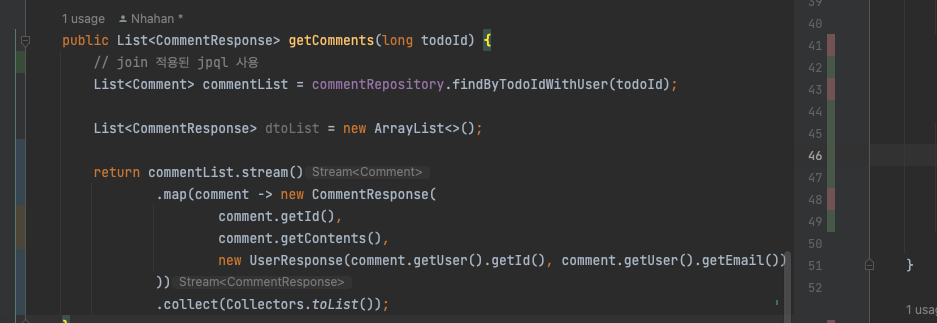
스트림 api를 활용하면 좀 더 좋은 코드가 될 것 같아 수정햿으며(참고 1, 2, 3-> 주로 3에서 학습함), 코드에 대해 일부 설명 하자면, List<Comment>를 List<CommentResponse>로 변환하였습니다.
순서대로 쉽게 설명해보겠습니다.
-
기존 코드는 향상 for문입니다. iter를 써서 생성한다음에 작성했습니다.
직관적이고 정말 좋은 코드라고 생각합니다. 그러나, 보통 향상된 for문을 쓰면 stream으로 좀 더 간결하게 가독성 좋은 코드로 리팩토링 할 수 있습니다.
이에 반해 저도 한 번 써봤습니다. -
스트림api를 쓰면서 이 전에 사용하던 for문을 한 줄로 변환 했으며,
.map()을 활용해서 commnet객체를 commentResponse로 변환했습니다. -
그리고 .collect(Collectors.toList())를 사용하여
List<CommentResponse>로 변환했습니다.
혹시 몰라 Stream API를 단계별로 쉽게 설명해보겠습니다.
1. stream() 시작
commentList.stream()
- commentList를 Stream(데이터 흐름)으로 변환
- for문과 비슷한 역할
2. .map() 사용
.map(comment -> new CommentResponse(
comment.getId(),
comment.getContents(),
new UserResponse(comment.getUser().getId(), comment.getUser().getEmail())
))
.map()은 Stream 내 요소를 변환하는 메서드- comment 객체를 CommentResponse 객체로 변환
기존의 for문에서 new CommentResponse(...)를 생성하는 부분을 .map()으로 표현한 것으로 보면 됩니다 !!!
3. .collect(Collectors.toList())
Stream을 List<CommentResponse>로 변환하는 역할
즉, List<CommentResponse>가 최종적으로 반환되게 됩니다.
Stream API 변환을 쉽게 이해하는 예제가 있습니다.
// 기존 for문 방식
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> squaredNumbers = new ArrayList<>();
for (Integer num : numbers) {
squaredNumbers.add(num * num);
}
System.out.println(squaredNumbers); // [1, 4, 9, 16, 25]
⬇⬇⬇ Stream API 변환
List<Integer> squaredNumbers = numbers.stream()
.map(num -> num * num)
.collect(Collectors.toList());
System.out.println(squaredNumbers); // [1, 4, 9, 16, 25]
즉, Stream API는 반복문을 간결하게 표현하기 위한 도구일 뿐입니다.
이해가 어렵다면 기존 for문 방식으로 작성해보고 Stream API로 변환해보는 연습을 하면 됩니다.
