
동포청년, JpaRepository를 쓰겠다고?
JPA를 사용하는 이상 Spring Data JPA를 사용하지 않는 사람은 거의 없을 것이고, Spring Data JPA를 사용하는데 JpaRepository 인터페이스를 사용하지 않는 사람도 거의 없을 것입니다. save, findById, findAll 같은 기본적인 CRUD 명세를 제공해주고, 해당 명세들에 대한 구현체를 제공해주기까지 하며(SimpleJpaRepository) 쿼리 메서드 기능이라는 강력한 기능까지 제공해주기 때문입니다.
하지만, 이런 의문을 가져보신 적이 없으십니까?
아, 나는 단 건 조회만 쓰고 findAll은 안쓸 것 같은데...
이 테이블은 soft delete를 구현할거라 삭제 기능이 필요하지 않은데...
아 구현체를 직접 만들려고 하니까 정의된 메서드가 왜이리 많은거야?
이 모든게 여러분이 JpaRepository를 상속하기 때문에 발생하는 일입니다.
JpaRepository를 상속하지 말아야 하는 이유
1. 불필요한 기능을 제공한다
잠시 JpaRepository의 상속 구조를 살펴보겠습니다.
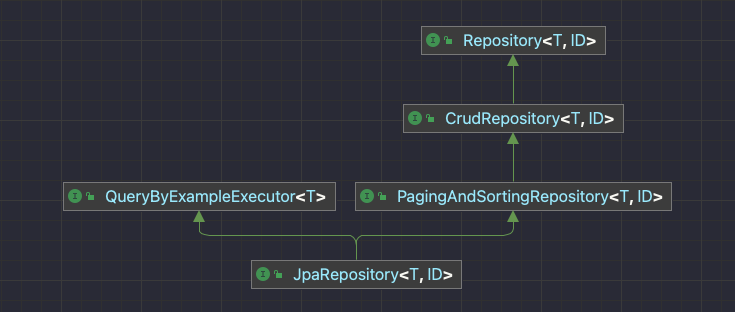
맨 위의 Repository 인터페이스를 시작으로 CrudRepository, PagingAndSortingRepository로 내려오며, JpaRepository는 PagingAndSortingRepository를 상속합니다. 그리고 추가로 QueryByExampleExecutor를 상속합니다.
JpaRepository는 Spring Data가 제공하는 인터페이스들을 하나씩 상속하며 내려오면서 편의 메서드들을 계속 상속하게 됩니다. 간단한 CRUD부터 배치 처리를 도와주는 메서드, 페이징 처리를 해주는 메서드, 영속성 컨텍스트를 초기화 시켜주는 메서드, 프록시 객체를 조회하는 메서드 등이 그것들입니다. 이런 기능들이 과연 필요할까요? 보통의 상황에서는 필요하지 않습니다.

기본적으로 좋은 코드를 만들기 위해서는 꼭 필요한 기능만 코드로 정의하는 것이 필요합니다. 사용하기 않을 기능을 정의하고 구현한다면 이는 오용의 대상이 될 수 있기 때문입니다. 예를 들어, soft delete(실제로 데이터를 삭제하지 않고 삭제 여부를 알 수 있는 컬럼을 두어 데이터베이스 상에서는 데이터를 유지하고 삭제된 데이터라고 처리하는 방식) 방식으로 데이터를 관리하려고 한다면 데이터를 데이터베이스에서 직접 삭제하는 기능은 필요하지 않습니다. 하지만 JpaRepository를 상속한다면 사용자의 실수로 데이터를 실제로 삭제하는 코드를 작성할 수 있게 됩니다.
2. 테스트 더블을 만들기 힘들다
repository 객체를 사용하는 서비스 객체들을 테스트 할 때, 데이터베이스에 직접 연결해서 테스트 하는 것은 굉장히 큰 비용입니다. 때문에 테스트 더블을 활용하여 데이터베이스와 격리된 테스트를 진행하는 경우가 많습니다. Map 등의 자료구조로 데이터베이스를 대체한 in-memory repository, 즉 fake 객체를 만들어서 테스트 하는 것입니다.
이 경우, Spring Data JPA를 사용하지 않은 순수한 단위 테스트를 진행해야 하기에 fake 객체를 기존 repository 인터페이스의 구현체로 만들어야 합니다. 모두 아시다시피, 인터페이스의 구현체는 인터페이스에 정의된 모든 메서드를 오버라이딩 해야 합니다.
때문에 앞서 말했듯 불필요한 기능이 많이 정의되어 있는 JpaRepository의 상속본을 가짜 객체로 구현하려면 굉장히 많은 메서드를 전부 오버라이딩 해야 하고, 이는 테스트 더블을 만드는데에 대한 피로로 이어집니다.
그래서 이런 방법을 쓰기도 합니다
예를 들어 User라는 엔티티가 있다고 하겠습니다. 위 두 가지 문제를 해결하는 기막힌 방법이 있습니다.
public interface UserRepository {
...
}
public interface UserJpaRepository extends UserRepository, JpaRepository<User, Long> {
...
}실제로 프로덕션에서 사용하는 타입은 UserRepository로 합니다. 그리고 (infra 패키지 같은 곳에) UserJpaRepository를 만들어 UserRepository와 JpaRepository를 상속합니다. 이러면 UserJpaRepository는 JpaRepository를 상속하므로 SimpleJpaRepository 구현체도 만들어지고, UserRepository의 상속이기도 하기 때문에 UserRepository 타입의 구현체로 사용하는 것이 가능합니다.
그런데... 꼭 이렇게 불필요한 타입까지 만들어가면서 해야 할까요? 아니요. 다른 방법이 존재합니다.
Repository 타입으로 대체하자
repository로서의 기능을 할 수 있는 구현체를 제공하는 역할은 어떤 인터페이스가 할까요? 많은 분들이 JpaRepository라고 생각하시겠지만, 정답은 Repository 인터페이스만 상속하고 있으면 된다 입니다.
Repository 인터페이스의 javadoc을 보면 다음과 같이 작성되어 있습니다.
Central repository marker interface. Captures the domain type to manage as well as the domain type's id type. General purpose is to hold type information as well as being able to discover interfaces that extend this one during classpath scanning for easy Spring bean creation.
핵심은 마지막의 클래스패스 스캐닝을 할 때 스프링 빈을 쉽게 만들어줄 수 있도록 한다 부분입니다. 즉, Repository 인터페이스만 상속하고 있으면 해당 인터페이스에 대한 구현체를 Spring Data JPA가 만들어준다는 이야기입니다.
실제로 Spring Data JPA의 공식 문서를 보면 기본 예제로는 JpaRepository가 아닌 CrudRepository(Repository 인터페이스에 간단한 CRUD 메서드를 확장한 것)를 상속하는 예제가 나와 있고, CRUD 메서드를 선택 노출하는 방법으로 Repository 인터페이스를 상속하는 예제가 나와 있습니다.
@NoRepositoryBean
interface MyBaseRepository<T, ID> extends Repository<T, ID> {
Optional<T> findById(ID id);
<S extends T> S save(S entity);
}
interface UserRepository extends MyBaseRepository<User, Long> {
User findByEmailAddress(EmailAddress emailAddress);
}그런데 Repository 인터페이스에는 어떠한 메서드도 정의되어 있지 않습니다. 마커 인터페이스일 뿐입니다. 때문에 Repository를 상속하면 불필요한 메서드를 정의할 필요도, 구현할 필요도 없습니다.
그러면 CrudRepository에 정의된 CRUD 기능은 어케 하냐는 물음이 있을 수 있겠죠? 쿼리 메서드 규칙대로 메서드 시그니처를 정의하기만 하면 됩니다. 구현체의 구현은 Spring Data JPA가 알아서 다 해주기 때문이죠. 이렇게 Repository를 사용하면 모든 문제를 다 해결하면서도 불필요한 인터페이스를 만들지 않을 수 있습니다.
참고 자료



크으.. 역시 JPA 장인이시네요 오찌님
잘부탁드립니다(?) 🙇🏻♂️🙇🏻♂️