1. 소규모 데이터를 이용한 모델
이번에는 모두의 딥러닝에서 제공하는 데이터를 사용하여 MRI 뇌 사진을 보고 치매 여부를 예측하는 프로젝트를 진행할 것입니다. 이번 딥러닝 모델은 이미지 분류를 위해 CNN을 활용합니다.
1.1. 데이터
주어진 데이터는 총 280장의 뇌의 단면 사진으로 구성되어 있습니다. 전체 사진 중 절반은 치매 증상을 보이는 환자의 뇌 사진이고 나머지 절만은 일반인의 뇌 사진입니다. 280개 중 160개는 학습 데이터로 사용하고 120개는 테스트 데이터로 사용합니다.
데이터 수가 적기 때문에 주어진 데이터를 이용해 변형된 이미지를 만들어 학습셋에 포함시키는 ImageDataGenerator() 함수를 사용하여 데이터 수를 늘려줍니다.
또한 Keras에서 제공하는 데이터셋이 아니므로 내 데이터를 불러오는 flow_from_directory() 함수를 따로 사용해야 합니다.
ImageDataGenerator() 세부사항
tf.keras.preprocessing.image.ImageDataGenerator(
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
zca_epsilon=1e-06,
rotation_range=0,
width_shift_range=0.0,
height_shift_range=0.0,
brightness_range=None,
shear_range=0.0,
zoom_range=0.0,
channel_shift_range=0.0,
fill_mode='nearest',
cval=0.0,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=None,
validation_split=0.0,
interpolation_order=1,
dtype=None
)
## example
train_datagen = ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
rotation_range=5,
shear_range=0.7,
zoom_range=1.2,
vertical_flip=True,
fill_mode='nearest'
)
# 테스트셋은 불필요한 데이터를 만들게 될 수 있으므로 정규화만 진행
test_datagen = ImageDataGenerator(rescale=1./255)주요 옵션
rescale: 주어진 이미지의 크기를 바꾸어 줍니다.horizontal_flip: 주어진 이미지를 수평으로 뒤집습니다.vertical_flip: 주어진 이미지를 수직으로 뒤집습니다.zoom_range: 정해진 범위 안에서 축소 또는 확대합니다.width_shift_range: 정해진 범위 안에서 그림을 수평으로 랜덤하게 평행 이동시킵니다.height_shift_range: 정해진 범위 안에서 그림을 수직으로 랜덤하게 평행 이동시킵니다.rotation_range: 정해진 각도만큼 이미지를 회전시킵니다.shear_range: 좌표 하나를 고정시키고 다른 몇 개의 좌표를 이동시키는 변환을 합니다.fill_mode: 이미지를 축소 또는 회전하거나 이동할 때 생기는 빈 공간을 어떻게 채울지 결정합니다. nearest 옵션을 선택하면 가장 비슷한 색으로 채워집니다.
flow_from_directory() 세부사항
flow_from_directory(
directory,
target_size=(256, 256),
color_mode='rgb',
classes=None,
class_mode='categorical',
batch_size=32,
shuffle=True,
seed=None,
save_to_dir=None,
save_prefix='',
save_format='png',
follow_links=False,
subset=None,
interpolation='nearest',
keep_aspect_ratio=False
)
## example
train_generator = train_datagen.flow_from_directory(
'./data-ch20/train',
target_size=(150,150),
batch_size=5,
class_mode='binary')
test_generator = test_datagen.flow_from_directory(
'./data-ch20/test'
target_size=(150,150),
batch_size=5,
class_mode='binary')주요 옵션
directory: 학습셋이 있는 폴더 위치target_size: 이미지 크기batch_size: 배치 크기class_mode: 클래스의 형식
1.2. 모델
CNN을 이용한 모델 구조
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150,150,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))모델 실행 옵션
model.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(learning_rate=0.0002), # 학습률 지정
metrics=['accuracy'])
# 학습 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = model.fit(train_generator,
epochs=100,
validation_data=test_generator,
validation_steps=10,
callbacks=[early_stopping_callback])1.4. 모델 분석
# 검증셋과 학습셋 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()1.5. 실행하기
코드
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping
from tensorflow.keras import optimizers
import numpy as np
import matplotlib.pyplot as plt
train_datagen = ImageDataGenerator(
rescale=1./255,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
)
train_generator = train_datagen.flow_from_directory(
'./data-ch20/train',
target_size=(150,150),
batch_size=5,
class_mode='binary'
)
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'./data-ch20/test'
target_size=(150,150),
batch_size=5,
class_mode='binary')
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=(150,150,3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(32, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (3, 3)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(64))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.Adam(learning_rate=0.0002), # 학습률 지정
metrics=['accuracy']
)
# 학습 자동 중단 설정
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = model.fit(
train_generator,
epochs=100,
validation_data=test_generator,
validation_steps=10,
callbacks=[early_stopping_callback]
)
# 검증셋과 학습셋 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()실행 결과
결과를 확인해보면 검증셋 정확도가 92% 정도로 학습이 진행된 것을 확인할 수 있습니다.
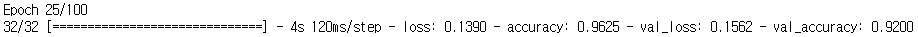
2. 전이 학습
전이학습(transfer learning)이란 데이터양이 충분하지 않을 때 기존의 많은 데이터를 학습한 정보를 가져와 내 프로젝트에 활용하는 것을 말합니다.
딥러닝 및 머신러닝 알고리즘은 학습할 때 정답을 알려주느냐에 따라 지도 학습(supervised learning)과 비지도 학습(unsupervised learning)으로 나누어집니다. GAN과 같이 정답을 예측하지 않고 주어진 데이터의 특성을 찾았으므로 비지도 학습이 되고, 나머지 진행했던 모델들은 지도 학습이라고 할 수 있습니다.
이미지넷(ImageNet)은 방대한 이미지 데이터를 가지고 있는 데이터셋입니다. 위에서 진행한 뇌사진 분류 프로젝트에 이미지넷을 활용한 전이학습을 이용하여 예측률을 극대화할 수 있습니다. 이미지넷의 엄청난 데이터는 형태를 구분하는 기본적인 학습이 되어있어 뇌 사진과 관련이 없어도 예측률에 도움을 줄 수 있습니다.
2.1. 이미지넷을 이용한 전이 학습의 적용
이미지넷을 이용하여 학습된 VGGNet(VGG16 사용) 네트워크를 앞으로 불러오고 뒤에 뇌 사진 예측 네트워크를 미세조정(fine tuning)하여 연결하여 사용합니다.
VGG16 불러오기
transfer_model = VGG16(
weights='imagenet',
include_top=False,
input_shape=(150,150,3)
)
transfer_model.trainable = False- 모델이 새로 학습하지 않도록 학습 기능을 꺼줍니다.
transfer_model.summary()summary()로 확인하면 학습 가능한 파라미터(Trainable params)가 0으로 나와야 합니다.

Fine-Tune 모델 만들기
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64))
finetune_model.add(Activation('relu'))
finetune_model.add(Dropout(0.5))
finetune_model.add(Dense(1))
finetune_model.add(Activation('sigmoid'))
finetune_model.summary()- 넘겨받은 파라미터들을 유지하고 최종 분류를 위해서만 새롭게 학습합니다.
전체 코드
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import Input, models, layers, optimizers, metrics
from tensorflow.keras.layers import Dense, Flatten, Activation, Dropout
from tensorflow.keras.applications import VGG16
from tensorflow.keras.callbacks import EarlyStopping
import numpy as np
import matplotlib.pyplot as plt
train_datagen = ImageDataGenerator(rescale=1./255,
horizontal_flip=True,
width_shift_range=0.1,
height_shift_range=0.1,
)
train_generator = train_datagen.flow_from_directory(
'./data-ch20/train',
target_size=(150,150),
batch_size=5,
class_mode='binary'
)
test_datagen = ImageDataGenerator(rescale=1./255)
test_generator = test_datagen.flow_from_directory(
'./data-ch20/test',
target_size=(150,150),
batch_size=5,
class_mode='binary')
# VGG16 모델 불러오기
transfer_model = VGG16(weights='imagenet', include_top=False, input_shape=(150,150,3))
transfer_model.trainable = False
# 목표에 맞게 미세조정한 모델 만들기
finetune_model = models.Sequential()
finetune_model.add(transfer_model)
finetune_model.add(Flatten())
finetune_model.add(Dense(64))
finetune_model.add(Activation('relu'))
finetune_model.add(Dropout(0.5))
finetune_model.add(Dense(1))
finetune_model.add(Activation('sigmoid'))
# 모델 컴파일
finetune_model.compile(loss='binary_crossentropy', optimizer=optimizers.Adam(learning_rate=0.0002), metrics=['accuracy'])
early_stopping_callback = EarlyStopping(monitor='val_loss', patience=5)
# 모델 실행
history = finetune_model.fit(
train_generator,
epochs=20,
validation_data=test_generator,
validation_steps=10,
callbacks=[early_stopping_callback]
)
# 검증셋과 학습셋 오차 저장
y_vloss = history.history['val_loss']
y_loss = history.history['loss']
# 그래프 그리기
x_len = np.arange(len(y_loss))
plt.plot(x_len, y_vloss, marker='.', c="red", label='Testset_loss')
plt.plot(x_len, y_loss, marker='.', c="blue", label='Trainset_loss')
plt.legend(loc='upper right')
plt.grid()
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()실행 결과
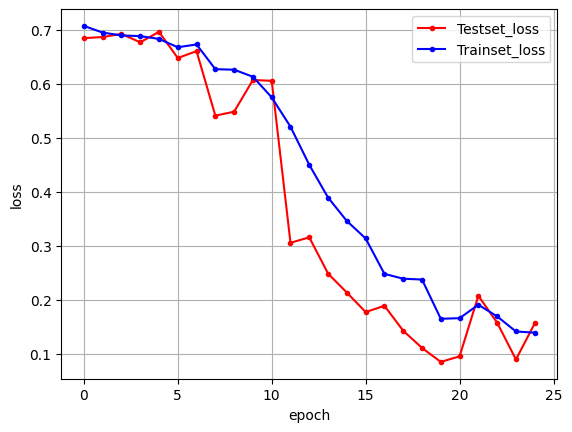
- 전이 학습 미적용
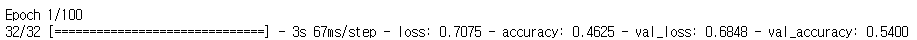
- 전이 학습 적용
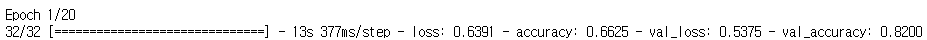
- 오차 그래프
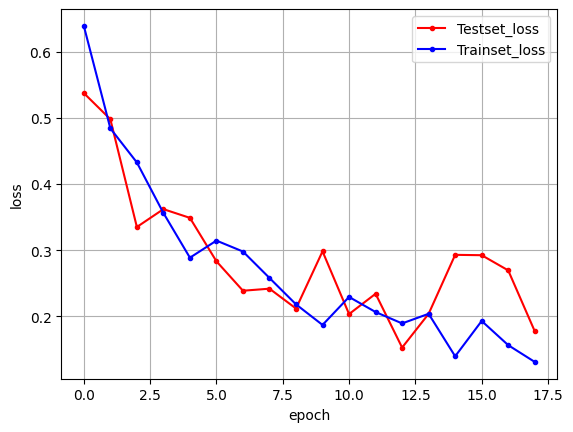
전이 학습을 이용하여 모델을 실행했을 때는 초기 에포크에서 검증셋 정확도가 82%에서 시작하는 것을 확인할 수 있습니다. 이렇게 전이 학습을 활용하면 안정적으로 모델의 성능을 향상시킬 수 있습니다.
Reference
- 해당 글은 "모두의 딥러닝" 20장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
