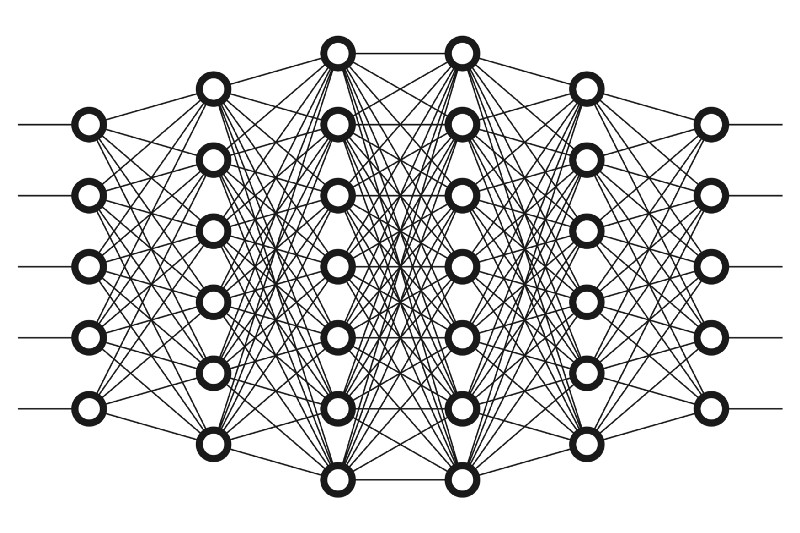
1. 예측의 원리
1.1. 일반적인 프로그래밍과 머신러닝의 차이점
-
일반적인 프로그래밍
- 미리 만들어 놓은 프로그램에 입력을 집어넣어 출력을 얻는 방식입니다.
-
머신 러닝
- 미리 만들어 놓은 모델 구조에 입력과 출력을 집어넣어 새로운 입력에 대한 결과를 예측할 수 있는 프로그램을 얻어내는 방식입니다.
1.2. 머신 러닝을 통한 예측 과정
① 기존 데이터 입력 → ② 데이터 학습 → ③ 새로운 입력에 대한 결과 예측
학습은 데이터가 입력되고 패턴이 분석되는 과정을 말합니다. 머신 러닝의 예측 정확도를 향상시키기 위해서는 학습을 어떻게 하느냐가 중요합니다. 더 정확한 패턴 분석을 위해 퍼셉트론, 아달라인, 선형 회귀 등의 알고리즘들이 등장하였고, 오늘날 딥러닝이 탄생되었습니다.
2. 딥러닝 코드 실행해 보기
Ubuntu 환경에서 실습코드를 실행해보겠습니다.
1. Ubuntu 환경에서 conda activate 후 실습을 진행할 디렉터리로 이동
-
예시코드
conda activate deep_learningcd projects
2. github에서 실습 파일 clone
- 예시코드
git clone https://github.com/taehojo/deeplearning.git
- 결과
jupyter notebook실행하여 실습 코드 실행해보기
- 여러 실습파일 중
ch02.ipynb실행
- 실행결과
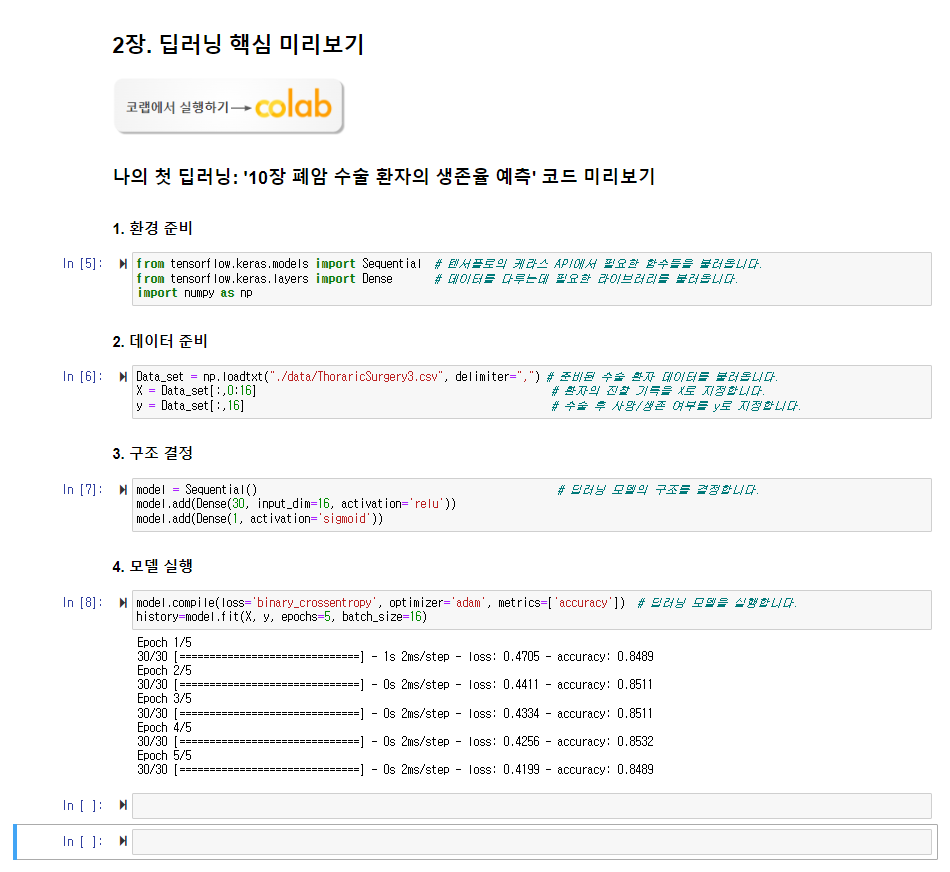
3. 딥러닝 개괄하기
jupyter 환경에서 딥러닝 실행 과정
1. 환경 준비
- 딥러닝을 구동하거나 데이터를 다루는 데 필요한 라이브러리 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
2. 데이터 준비
- 데이터를 불러와 환자 상태의 기록(속성)에 해당하는 부분을 X로, 수술 1년 후 사망/생존 여부(클래스)를 y로 지정
Data_set = np.loadtxt("./data/ThoraricSurgery3.csv", delimiter=",")
X = Data_set[:,0:16]
y = Data_set[:,16] -
데이터의 형태
-
현재 사용중인 데이터는 종양의 유형, 폐활량 등 16개의 환자 상태를 의미하는 속성 데이터와 생존, 사망 등의 정보를 나타내는 클래스 데이터를 가지고 있습니다.
-
속성(attribute) : 결과에 영향을 주는 속성 데이터
-
클래스(class) : 결과에 해당하는 데이터
-
3. 구조 결정
- 딥러닝 모델의 구조 결정
model = Sequential()
model.add(Dense(30, input_dim=16, activation='relu'))
model.add(Dense(1, activation='sigmoid'))-
현재 실습에서 딥러닝을 실행시키기 위해 딥러닝 전용 라이브러리인 텐서플로를 불러왔습니다. 텐서플로는 여러 딥러닝 작업을 할 수 있지만 어려워 케라스를 같이 이용합니다.
-
케라스의 활용
-
딥러닝은 여러 층이 쌓여 있는 구조입니다. 첫번째 작업을 진행하는 층부터 출력 결과가 나오는 출력층가지 여러 개의 층이 각자 자신이 맡은 일을 하며 정보를 주고받습니다.
-
Sequential()함수는 딥러닝의 한 층 한 층을model.add()라는 함수를 사용해 간단히 추가시켜 줍니다. -
model.add()함수 안에 있는Dense()는 각 층의 입력과 출력을 촘촘하게 모두 연결하도록 하는 함수입니다.
-
-
딥러닝을 설계한다는 것은 층을 얼마나, 어떻게 다룰 것인지 고민하는 것입니다.
4. 모델 실행
- 딥러닝 모델을 실행하여 결과를 출력
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history=model.fit(X, y, epochs=5, batch_size=16)-
model.compile()함수는 model 설정을 그대로 실행하라는 의미입니다. -
model.fit()함수는 층을 오갈 때 몇 개의 데이터를 사용할 것인지 지정하는 함수입니다.
Reference
- 해당 글은 "모두의 딥러닝" 2장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
