1. 딥러닝과 데이터
머신 러닝에서 데이터는 프로젝트의 성공과 실패에 큰 영향을 주는 중요한 부분입니다. 성공적인 모델을 만들기 위해 좋은 데이터를 가지고 머신 러닝을 시작해야 합니다. 좋은 데이터라는 것은 다음과 같은 요소들 충족함을 의미합니다.
- 한쪽으로 치우치지 않음
- 불필요한 정보가 대량으로 포함되어 있지 않음
- 왜곡되지 않음
머신 러닝, 딥러닝을 잘 사용하기 위해서는 데이터를 분석할 수 있는 능력이 필요합니다.
파이썬에서 이터 분석에서 가장 많이 사용하는 라이브러리는 pandas, matplotlib 등이 있습니다.
2. 데이터 분석해보기
실제 데이터를 분석 해보겠습니다. 데이터 분석은 jupyter notebook를 이용하여 진행합니다. Ubuntu 환경에서 다음과 같이 jupyter notebook을 실행합니다.
# 실습을 진행할 conda 환경 활성화
(base) ~$ conda activate deep_learning
# 실습을 진행할 디렉토리 만들기
(deep_learning) ~$ mkdir ./projects/deep_learning/chapter11
# 실습 디렉토리로 이동
(deep_learning) ~$ cd ./projects/deep_learning/chapter11
# jupyter notebook 실행
(deep_learning) ~/projects/deep_learning/chapter11$ jupyter notebook2.1. 실습 데이터
이 장에서 진행할 실습에서 사용되는 데이터는 피마 인디언 데이터입니다. 피마 인디언의 여러 의학적 정보와 당뇨 여부를 포함하고 있는 데이터입니다. 사용할 데이터를 들여다보면 다음과 같습니다.
-
샘플 수: 768
-
속성: 8
- 정보 1: 과거 임신 횟수
- 정보 2: 포도당 부하 검사 2시간 후 공복 혈당 농도
- 정보 3: 확장기 혈압
- 정보 4: 심두근 피부 주름 두께
- 정보 5: 혈청 인슐린
- 정보 6: 체질량 지수
- 정보 7: 당뇨병 가족력
- 정보 8: 나이 -
클래스: 당뇨(1), 당뇨 아님(0)
2.2. Pandas를 활용한 데이터 조사
Pandas 라이브러리를 활용하면 데이터를 시각화할 수 있습니다. 이 실습을 진행하기 위해서는 pandas와 seaborn 라이브러리가 필요합니다. 다음과 같이 터미널에 코드를 입력하여 라이브러리를 설치할 수 있습니다.
- 라이브러리 설치
pip install pandaspip install seaborn
2.2.1. 데이터 분석
1) 데이터 가져오기
실습 데이터 폴더를 복사하지 않았다면 github에서 실습에 필요한 데이터를 가져옵니다. Ubuntu 터미널에서 다음과 같이 입력하여 데이터를 가져올 수 있습니다.
git clone https://github.com/taehojo/data.git
2) 파이썬에서 데이터 준비
다음과 같이 df라는 이름의 데이터 프레임에 csv 파일을 볼러와 저장합니다. csv 파일의 첫번째 줄은 헤더로 데이터를 설명하는 부분입니다.
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('./data/pima-indians-diabetes3.csv')
3) 함수를 이용한 데이터 분석
head()
-
데이터를 줄 단위로 불러오는 함수입니다. 정수 인수를 입력하여 첫번째 줄부터 입력한 수 만큼의 줄을 불러옵니다.
-
실행결과
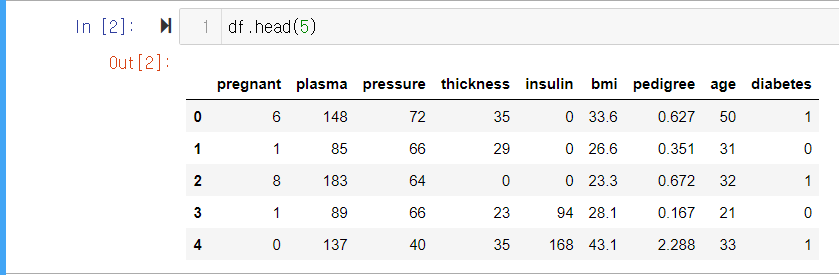
- 인수로 5를 입력하여 0번째 줄부터 4번째 줄까지 총 5줄의 데이터를 표시합니다.
df["column_name"].value_counts()
-
칼럼명에 해당하는 열의 데이터 값이 각각 몇 개씩 있는지 알려 줍니다.
-
실행결과
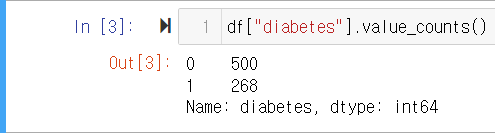 * 정상이 500명, 당뇨환자가 268명이 있음을 확인할 수 있습니다.
* 정상이 500명, 당뇨환자가 268명이 있음을 확인할 수 있습니다.
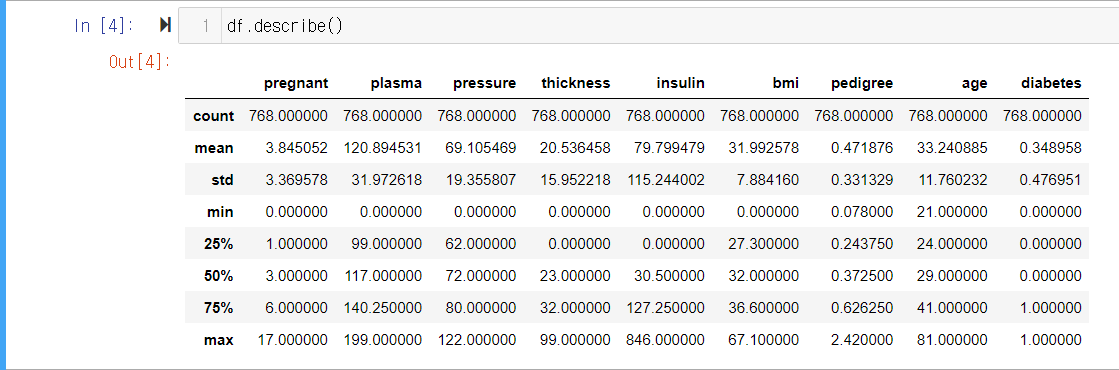
df.describe()
-
정보별 자세한 특징을 출력하는 함수입니다. 사용 시 정보별 샘플 수 (count), 평균(mean), 표준편차(std), 최솟값(min), 제3사분위수(25%), 제2사분위수(50%), 제1사분위수(75%), 최댓값(max)이 정리되어 표시됩니다.
-
실행결과
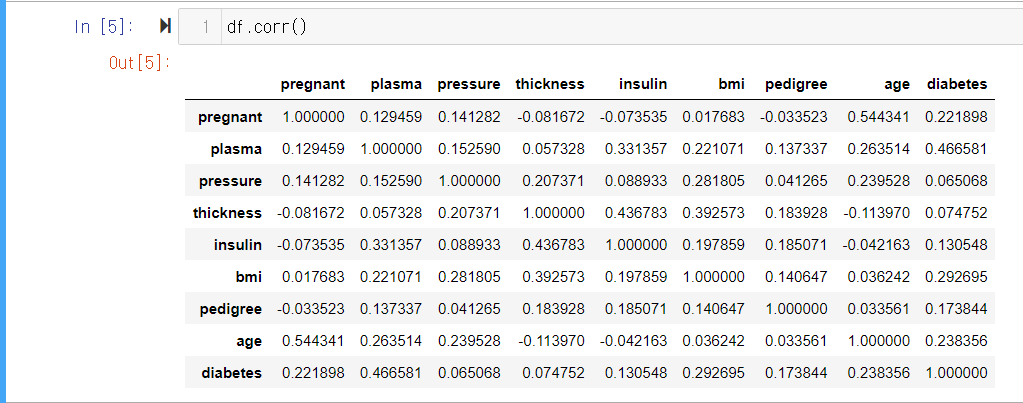
df.corr()
-
각 항목의 상관관계의 정도를 0에서 1사이의 값으로 출력하는 함수입니다.
-
실행결과
4) 데이터 시각화
matplotlib과 seaborn을 이용하여 다양하게 그래프를 그릴 수 있습니다. matplotlib을 이용하여 그래프의 색상과 크기를 정하고 seaborn 라이브러리의 heatmap() 함수를 이용하여 상관관계를 그래프로 나타낼 수 있습니다. heatmap() 함수는 각 항목의 변화를 비교하여 비슷한 패턴일 수록 1에 가까워지고 반대의 경우에는 0에 가까운 값을 반환합니다.
- 코드
colormap = plt.cm.gist_heat
plt.figure(figsize=(12,12))
sns.heatmap(df.corr(), linewidths=0.1, vmax=0.5, cmap=colormap,
linecolor='white', annot=True)
plt.show() -
실행결과
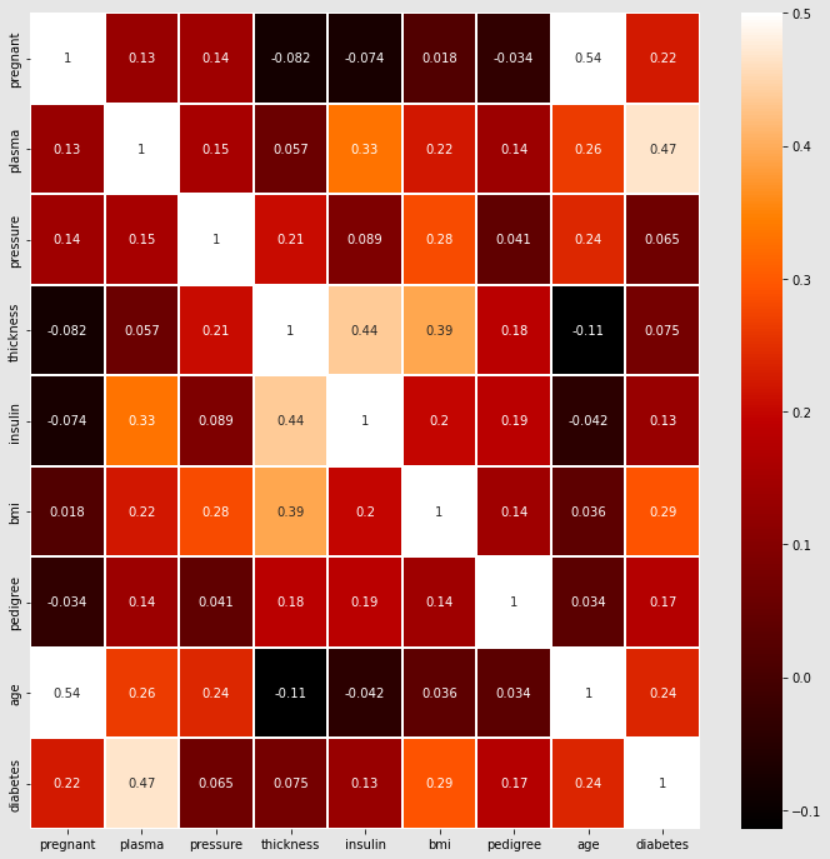
- plasma(공복 혈당 농도), bmi(체질량 지수) 등의 속성이 diabetes와 상관관계가 있는 것으로 보이는 것을 확인할 수 있습니다.
2.3. 중요한 데이터 추출하기
앞서 다룬 그래프를 보면 plasma(공복 혈당 농도), BMI(체질량 지수)가 당뇨와 상관관계가 높다는 것을 알 수 있습니다. 중요한 두 데이터를 따로 떼어 내여 당뇨의 발병 여부와 어떤 관계가 있는지 확인해보겠습니다.
Plasma
plasma 속성에 대한 diabetes의 히스토그램을 다음과 같이 코드를 작성하여 확인할 수 있습니다.
-
코드
plt.hist(x=[df.plasma[df.diabetes==0], df.plasma[df.diabetes==1]], bins=30, histtype='barstacked', label=['normal', 'diabetes']) plt.legend()x는 x축을 지정하는 부분입니다. 코드를 보면 plasma 속성 중 정상과 당뇨를 구분하여 x축으로 불러오도록 한 것을 확인할 수 있습니다.bins는 x축을 몇 개의 막대로 쪼개어 나타낼 지 지정하는 부분입니다. 여기서는 30개의 막대로 나타내는 것을 확인할 수 있습니다. plasma 속성의 최댓값인 199를 30으로 나눈 약 6.63 단위로 개수를 세어 히스토그램으로 나타냅니다.
-
실행결과
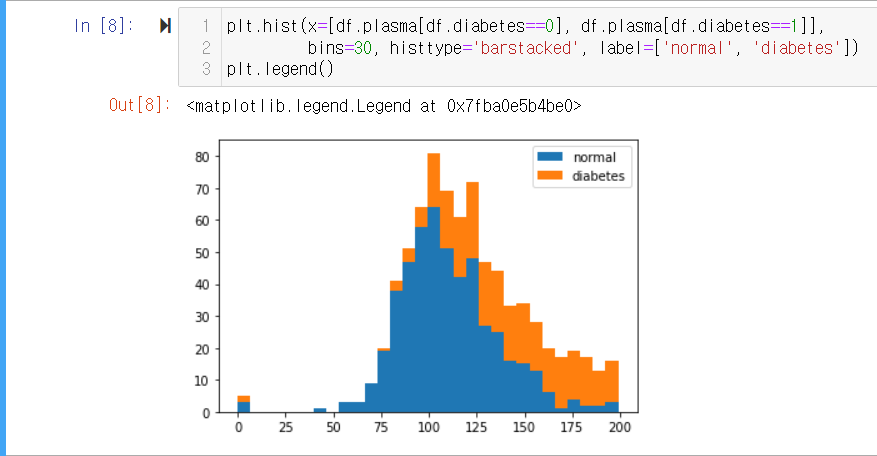
- plasma 수치가 높아질수록 당뇨를 앓는 환자가 많아지는 것을 확인할 수 있습니다.
BMI
-
다음으로 bmi 속성에 대해서 같은 방법으로 히스토그램으로 나타내보겠습니다.
-
코드
plt.hist(x=[df.bmi[df.diabetes==0], df.bmi[df.diabetes==1]], bins=30, histtype='barstacked', label=['normal', 'diabetes']) plt.legend() -
실행결과
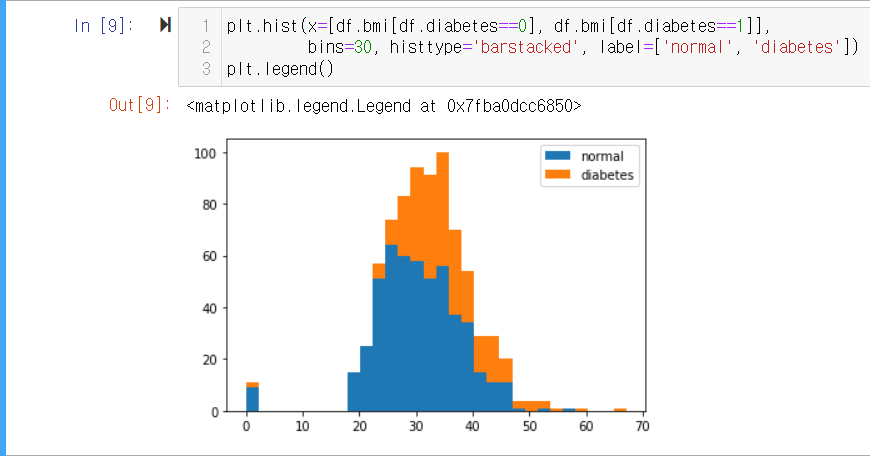
- 마찬가지로 BMI가 높아질 수록 당뇨의 발병률도 함께 증가하는 것을 확인할 수 있습니다.
결과에 미치는 영향이 큰 속성을 찾아내는 것이 데이터 전처리 과정 중 하나입니다. 데이터에 빠진 값이 있다면 평균이나 중앙값으로 대치하거나, 아웃라이어를 제거하는 과정 등이 데이터 전처리에 포함될 수 있습니다. 일반적인 머신러닝에서는 데이터 전처리 과정이 성능 향상에 중요한 역할을 합니다.
2.4. 예측 실행해보기
Tensorflow의 keras를 이용하여 예측을 실행하고자 합니다. Pandas 라이브러리를 사용하기 때문에 iloc[]함수를 사용하여 x와 y를 각각 저장합니다. iloc[] 함수는 데이터 프레임에서 대괄호 안에 정한 범위만큼 데이터를 가져와 저장하도록 하는 함수입니다.
실행 코드
- 필요한 라이브러리 불러오기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns- 데이터셋 불러오기
df = pd.read_csv('../data/pima-indians-diabetes3.csv')
X = df.iloc[:, 0:8]
y = df.iloc[:, 8]- 모델 구조 설정하기
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu', name='Dense_1'))
model.add(Dense(8, activation='relu', name='Dense_2'))
model.add(Dense(1, activation='sigmoid', name='Dense_3'))
model.summary()-
model.summary()은 만든 모델의 구조에 대한 정보를 표시합니다. -
실행하면 다음과 같이 표시됩니다.
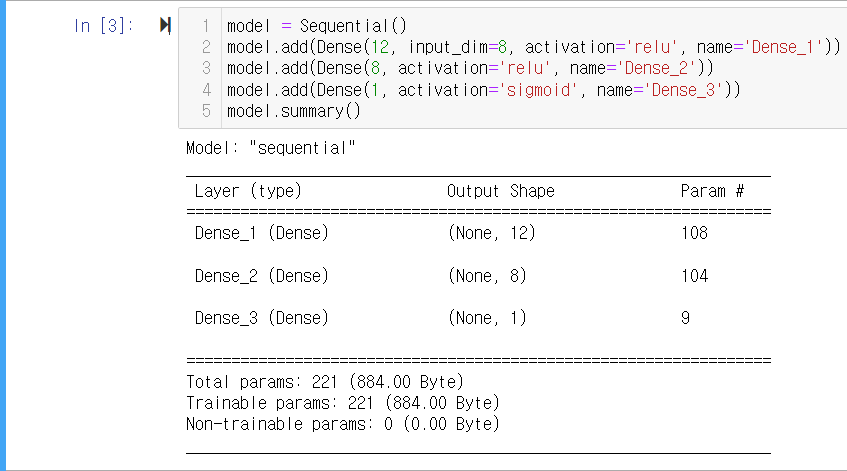
-
Layer 부분은 추가한 층의 이름과 유형을 나타냅니다.
-
Output Shape 부분은 각 층의 출력 수를 알려줍니다. 쉼표(,)를 기준으로 앞은 행(샘플)의 수, 뒤는 열(속성)의 수를 의미합니다.
-
Param # 부분은 가중치와 편향 수의 합을 알려줍니다. 예를 들어, Dense_1에서는 8개의 입력이 12개의 노드로 분산되기 때문에 가중치와 편향의 합이 96(8*12+12)이 됩니다.
-
표 아래에 표시된 부분은 전체 파라미터를 합산한 값입니다. Trainable params는 학습 시 업데이트가 되는 파라미터들의 수이고, Non-trainable params는 업데이트가 되지 않은 파라미터 수를 나타냅니다.
-
- 모델 컴파일 및 실행
- 코드
model.compile(loss='binary_crossentropy', optimizer='adam',
metrics=['accuracy'])
history = model.fit(X, y, epochs=100, batch_size=5)-
실행 결과
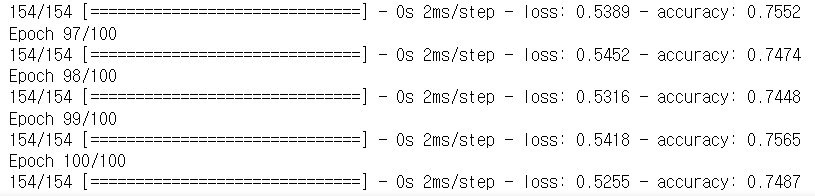
- 100 반복 후 예측 정확도가 74.87%로 나타나는 것을 확인할 수 있습니다.
Reference
- 해당 글은 "모두의 딥러닝" 11장을 기반으로 작성되었습니다.
- 조태호. 모두의 딥러닝 (개정3판). 길벗(2022)
