X, Y : 각각 Input value와 Output value의 Space (x(i),y(i)) : Training example로, x(i)은 Feature, y(i)은 target(or output)을 의미. {(x(i),y(i)}i=1n: Sample이 총 n개인 Training dataset h:X→Y: Feature x∈X에 대한 output 값을 도출해내는 가설(hypothesis) H: Hypothesis h가 가질 수 있는 space (추후 PAC Learning때 소개)
들어가기 앞서
아래의 내용들은 최대한 CS229 Lecture Note, Spring '23의 표기 및 내용을 따라갑니다.
간혹 수학적인 내용들이 나오게 되는데, 그런 경우엔 최대한 보충 설명을 넣거나 Lecture Note보다는 자세하게 쓸 예정입니다.
기초적인 확률적 지식이나 선형 대수적 지식은 가지고 있으셔야 보기 편합니다.
Linear Regression
Motivation
집 가격 예측 문제를 생각하자. 다음은 면적과 방의 수, 그리고 그 집의 가격을 표로 나타낸 것이다.
Living area (feet2)210416002400⋮#Bedrooms333⋮Price (1000$s)400330369⋮
즉, 우리가 하고 싶은 일은 집의 면적과 방의 수가 들어왔을 때, 그 집의 가격이 대략 얼마인지를 유추하고 싶은 것이다.
위의 내용을 일반적으로 표현하면, input vector x=[x1x2]⊤∈R2이 들어왔을 때 올바른 output y를 찾는 함수 f(혹은 hypothesis h)를 찾는 문제이다.
그러한 h 중 복잡한 형태도 많을 것이고 단순한 형태도 많을 것인데 그 중에서 가장 단순한 형태라고 할 수 있는 Linear 모델을 생각하자.
즉, h(x)=θ0+θ1x1+θ2x2라 표현하자. 이때, θi들은 parameter라 하고 이들은 Input x∈X를 output space Y로 mapping하는 역할을 한다. 위의 사항을 일반화하자. X=Rn에 대해 x∈X라 하고 parameter 벡터 θ에 대해 선형 모델 h:X→Y는 다음과 같이 정의된다.
h(x)=i=0∑nθixi=θ⊤x+
이때 x+=[x0(=1)x1⋯xn]⊤을 의미한다.
그러면, 이제 우리가 주목해야할 부분은 "저 parameter θ를 어떻게 얻어낼 수 있을까?"가 된다. 뭐 방법은 모르겠지만, 우리가 예측한 값과 output 간의 정답 간의 차이가 작아야 한다는 것은 확실히 알 수 있다. 즉, 우리는 ∣h(x)−y∣를 최소화하는 것을 목표로 잡을 수 있다. (흔히들 L1/MAE 라 함)
허나, 이렇게 잡아버리면 중심에서 미분이 불가능하고, 추후 사용할 Gradient Descent에서 Gradient가 고정이 되기 때문에 변화량이 값의 차이를 반영하지 못한다는 단점이 있다.
이 단점을 해결하기 위하여, 에러의 값을 제곱하여 합하는 것이 있고, 이를 MSE라고 한다.
미분가능성과 대칭성, Gradient의 값이 현재의 값을 반영한다는 점에서 자주 쓰이며, 추후 CS229에서도 딱히 말이 없으면 해당 Loss를 사용하는 것으로 간주한다. 표기의 편함을 위해, cost function J(θ)를 다음과 같이 정의하자.
J(θ)=21i=1∑n(hθ(x(i))−y(i))2
Gradient Descent
최종 목표는 J(θ)를 최소화하는 θ를 고르는 것이 목표이고, 가장 쉽고 잘 알려져 있는 방법은 Gradient Descent이다.
Gradient Descent는 현재 θ의 값에서 최솟값까지 가는 가장 빠른 방향이(값 X) 현재 θ에서의 Gradient임을 이용하여 θ를 변화시키는 방법이다.
Update Formula로는 다음과 같다.
θt+1←θt−α∇θtJ(θt)
Gradient를 구하기 위해 J(θ)를 θ에 대한 미분값이 필요하고, 합은 각각 분리할 수 있으므로 θ에 대한 21(hθ(xi)−y(i))2의 Gradient를 알아야한다. 일반성을 잃지않고, J(θ)=21(hθ(x)−y)2라 하자.
이 Gradient를 Learning rate(=α)와 계속 곱해나가면서 최적점을 찾아나가는 것이 Gradient Descent이다.
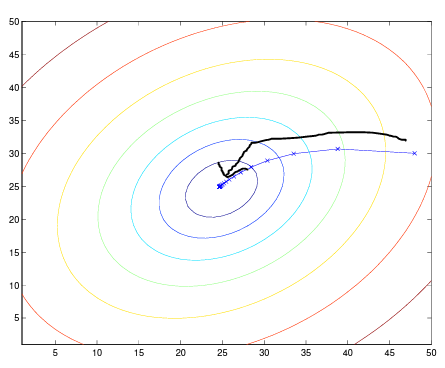
위 사진이 Gradient Descent의 실제 진행 모습. Initial state에서 점점 최적으로 다가감을 알 수 있다.
이 때 전체에 대해 저 Loss를 다 모은 다음 Gradient Descent를 진행하지 않고, 하나의 데이터에 대해 Gradient Descent를 수행하는 것을 Stochastic Gradient Descent, n개의 mini-batch를 만든 후 그 Batch마다 수행하는 것을 Mini-batch Gradient Descent라 한다. 아~주 뒤에 수학적으로 다룰 예정
Probabilistic interpretation
위의 Linear Model을 생각하자. 위에서 표현하는 오차까지 하나의 식에 넣어버리면, y=θ⊤x+ε으로 적을 수 있을 것이다. 이때, ε은 Feature x에 해당되지 않아서 모델이 고려하지 못하는 요소들을 말하며, 오차로도 볼 수 있다.
이때, 한 가지 강력한 가정을 들고오자. ε∼N(0,σ2), 즉 오차가 평균이 0이고 분산이 σ2인 i.i.d 정규분포를 따른다고 가정하자.
정규분포 N(0,σ2)의 pdf p(x)=2πσ1exp(−2σ2x2)이므로
p(ε)=2πσ1exp(−2σ2ε2)
이때 ε=y−θ⊤x이므로
p(y∣x;θ)=2πσ1exp(−2σ2(y−θ⊤x)2)
우리가 구하고 싶은 것은 데이터셋 {(x(i),y(i)}i=1n 에 대해서 p(y∣x;θ)를 최대화시키는 θ가 필요이다.
즉, x가 주어져있다는 상황에서 θ를 정했을 때의 확률 y를 구하고, 이를 최대화하는 θ를 미분으로 구하면 된다.
이를 Maximum Lieklihood Estimation (최대우도법)이라고 한다.
이를 기반으로 θ에 대한 Likelihood function을 구하면