[Paper Review] The COT COLLECTION: Improving Zero-shot and Few-shot Learning of Language Models via Chain-of-Thought Fine-Tuning
0
Papers
목록 보기
5/7


Introduction
- Large text corpora로부터 pretrained된 LM와 CoT를 이용하여 근거를 찾아내고 그걸 바탕으로 최종 예측을 하는 LLM들이 많아지고 있음.
- LM에서 수행하는 CoT 같은 경우 LLM인지 아닌지에 따라 성능이 극명하게 갈림
- 특히, 100B 이상부터는 추론의 결과가 나쁘지 않지만, 100B(100 billion) 아래의 LM 모델들은 CoT 추론 능력이 너무나도 저조함
- 허나 우리는 LM에 대해서도 LLM에서 추론하는 것과 비슷한 결과를 이끌어내고 싶고, 그러기 위해서는 추가적인 Fine-tuning이 필요
- LLM에서 Instruction tuning을 위하여 9개의 대주제로 만든 dataset이 있으나, 우리가 target으로 한 LM 모델은 이 9개의 데이터만을 이용하여 fine-tuning하였을 때 unseen task를 처리하기가 힘듦
- ( 단순히 single task를 해결하는 것이 곧 전체를 잘 푼다고 보장할 수 없기 때문)
- 저자는 task를 총 1827개로 나누었는데, 9개만을 finetuning하였다고 이 task들에 대해 poor performance를 냈음
- 이 Generalization 문제를 해결하기 위하여 저자는 fine-tuning하는 dataset으로 FLAN collection의 1060 task들로부터 184만개의 근거가 있는 을 제안하였으며, 실제로 Flan-T5에 이를 fine-tune한 모델을 CoT-T5라고 칭한다.
- 이 두 모델을 zero-shot scenario와 few-shot scenario에 놓았을 때 모두 결과가 일반 Flan-T5의 결과보다 좋았음을 알 수 있음
- 제거 실험 상황에서는 와 5개의 다른 언어로 구성되어 있는 인스턴스들로 training을 진행을 하면 적은 computing으로도 나쁘지 않은 성능을 뽑아낼 수 있었음
Related Works
해당 부분은 과거 연구들을 요약해놓은 부분이라 작성하지 않는다.
The CoT Collection
- CoT에 대한 fine-tuning을 진행하더라도, 우리가 하고 싶은 "근거를 토대로 하는 추론"에 대한 데이터는 굉장히 부족함
- 이걸 보완하기 위해 일반적으로 9개의 공개된 데이터셋을 사용하는데, 이걸 보완하기 위해 해당 논문에서 제안하는 것이 임.
- 해당 section에서는 이 dataset을 어떻게 구축했는지에 대해 설명함
Broad Overview
- 우리는 "LM에서는 어느 정도의 CoT를 잘 수행하고 근거를 잘 가져온다"라는 강한 convention을 가지고, LM으로부터 근거 을 얻어내는 task를 수행
- 즉, Input을 , 이때 는 Instruction, 는 instance, 그리고 이러한 input 에 대응하는 를 이용하여 LM에 in-context learning을 수행하여 근거 을 얻어낸다.
- Incontext Learning: Zero(or Few)Shot learning을 의미
- 이때 기존 연구에서는 전부 를 생성하는 것에 초점을 맞추었다면, 우리는 가 아니라 그걸 이용해서 새로운 근거인 을 생성해내는 것이 목표
Source Dataset Selection
- 위의 방법을 통해서 대략적인 방법론을 제시했으니, 이제 본격적인 에 해당하는 부분을 모을 예정
- Introudction에 소개한대로 Flan Collection에서 1836개의 테스크 대분류를 얻어내고, 그 이후 학습과정에서나 데이터셋 자체적으로 문제가 있는 그런 task들을 제외하여 최종적으로 1060개의 task 대분류를 얻어냄
Creating Demonstrations for ICL
- In-context learning을 하기 위해서는 prompting을 진행해야함
- 각 task 에 대한 prompting을 demonstration 로 정의하면, 우리는 1060개의 모든 에 대해 demonstration set이 필요
- 하지만 각 task 당 한개씩만 만들어낸다고 해도 총 1060개의 사람이 만든 demonstration이 필요하고, 이건 task의 숫자가 늘어나면 늘어날수록 더 많아짐 사실상 이렇게 하는것은 쉽지 않은 일
- 이때 Task들은 대부분 비슷한 타입으로 묶을 수 있음.
- Closed book에 대해 QA를 수행하거나 여러 개를 고르는 QA를 선택하거나 등과 같은거는 "QA"라는 하나의 카테고리로 묶을 수 있음
- 이렇게 큰 Task로 묶어서 이 Task들에 대해 같은 Demonstration을 사용하면 각 task별로 사용하는거에 비해 정확도는 떨어질 수 있지만, 보다 적은 노력으로 최대의 효율을 뽑을 수 있음
- 이렇게 묶은 task type을 으로 총 개로 분류하였으며, 각 task 마다 에 속하게 되는 가 존재한다.
- 이후 FLAN Collection에서 임의로 개의 instance를 샘플링, 그거에 대한 근거를 "사람이 직접" 작성하여 few-shot learning의 context를 생성한다.
- 각 task당 demonstration 은 6개에서 8개의 설명으로 구성되어 있으며, 이는 A/B Test를 통하여 직접 제작한다.
Rationale Augmentation
- 마지막으로 위에서 생성한 rationale와 openAI의 Codex를 이용하여 rationale를 증강하는 작업을 수행한다.
- Task 에 대한 번째 input 이 주어지면 우리는 이에 맞는 를 생성하는 것이 목표이고, 앞서 ICL을 위한 demonstration 를 생성하였으므로 이를 이용한다.
- task 가 에 속한다고 하고, 정답 라벨 와 demonstration 를 이어 붙여서 prompot를 생성하게 된다.
- 이렇게 하면 결과가 더 잘나온다고 claim하였는데, 그 이유는 정답 라벨을 앞에 적어놓으면 모델 입장에서는 단순히 근거만 생각하면 되기 때문이라고 저자들은 생각
- 개인적인 생각으로는, 단순히 근거만 생각하는 것 외에도 정답-설명으로 모든 쌍이 묶여있기 때문에 모델들은 정답을 보고 "이 정답이 어떻게 해야 나올 것인가?" 에 대해 집중을 하게 되고, 그렇게 해서 더 좋은 근거가 나오는 것이 아닐까라고 생각
- 이후 Codex를 이용하여 근거를 증강
- 이때 Arithmetic한 연산들에 대해서는 rationale이 생각보다 좋은 퀄리티로 생성이 되지 않음을 발견
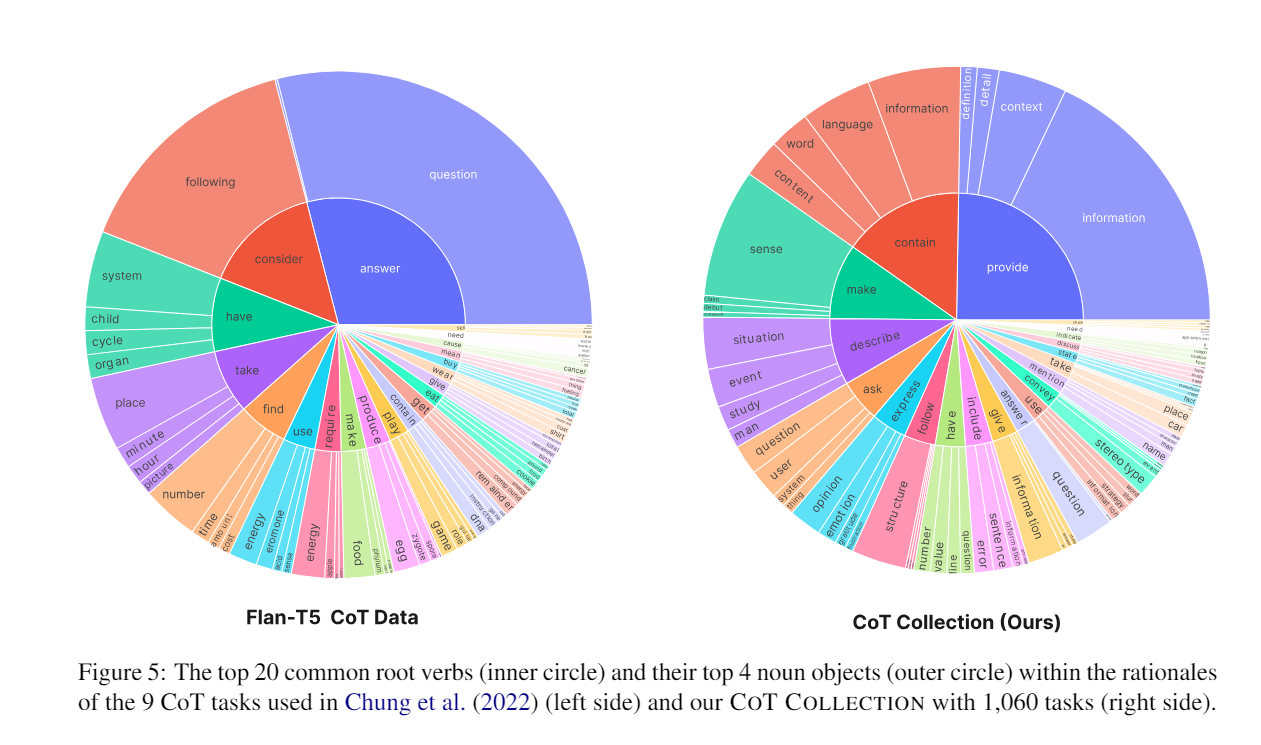
Analysis I. Diversity of Rationales
- 이 얼마나 다양하게 근거를 표현하고 있는지 (다양한 단어, 패턴 등)을 분석하기 위하여 Berkeley Neural Parser를 사용하여 근거를 Parsing
- 이후 가장 널리 사용되고 있는 9개의 CoT Dataset과 이를 비교를 수행, 그 결과 9개의 CoT보다 더 높은 다양성 format을 포함함을 알 수 있음.
Analysis II. Quality of Rationales
- 이 생성한 근거가 얼마나 퀄리티가 높은지 평가지표 ROSCOE를 사용하여 사람이 생성한 근거와 실제로 평가를 실시
- 사람이 생성한것과 비교하였을 때 근소하게 높은 퀄리티를 보였으며, 이를 바탕으로 생성된 근거들도 충분히 데이터셋을 사용할 수 있음을 알 수 있음
- 이때 Codex로 생성된 근거들은 문장들에 대한 통일성(일관성)이 부족하고 너무 다양하게 표현함을 알 수 있었는데, 이는 언어들이 너무 다양한 format을 가지게 되면 해석을 하는 과정에서 다음 예측을 진행할 때 너무 많은 경우(High perplexity)를 고려하게 되기 때문이라고 저자들은 추측함
Experiment
- FLan-T5를 base model로 하여 Fine-tuning을 진행하였고, Evaluation으로는 총 2개를 사용(Direct Evaluation, CoT Evaluation)
- 주목한 부분은 Zero Shot과 Few Shot Learning에 대한 부분이며, Abelian experiment로는 중요한 것만 모은 와 Multilingual한 Adaption을 적용한 것이다.
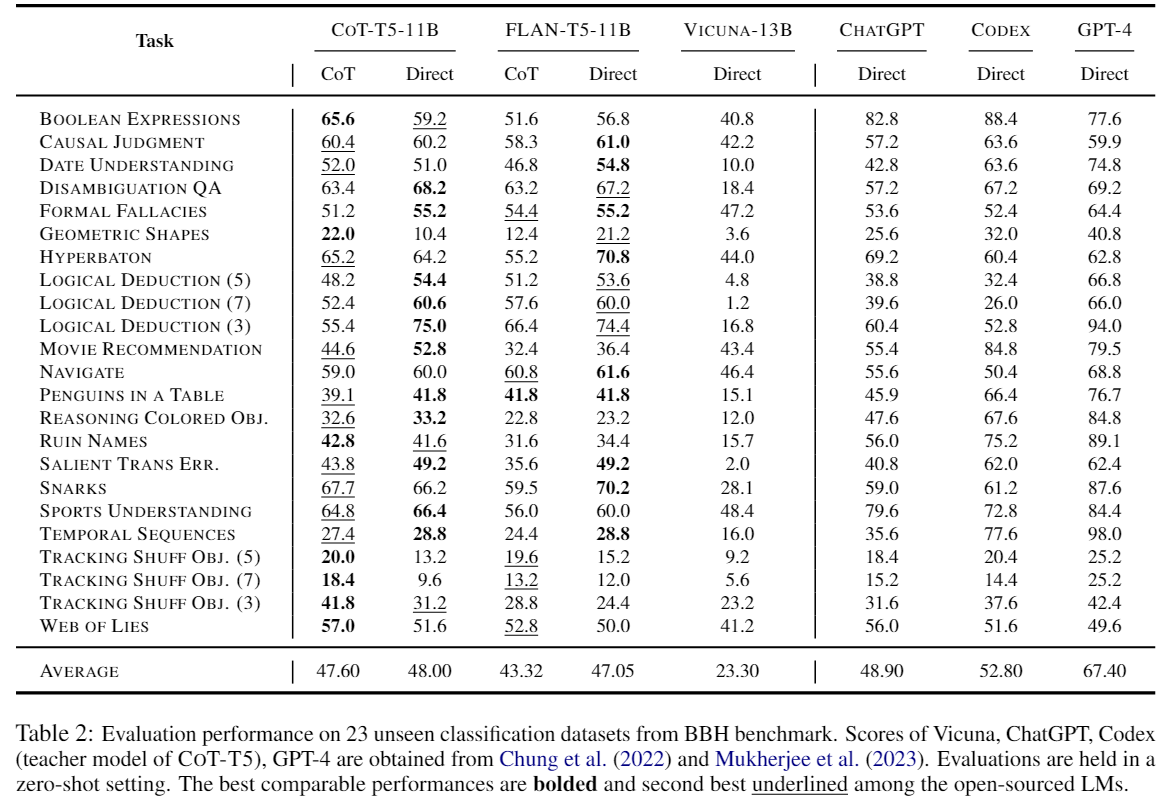
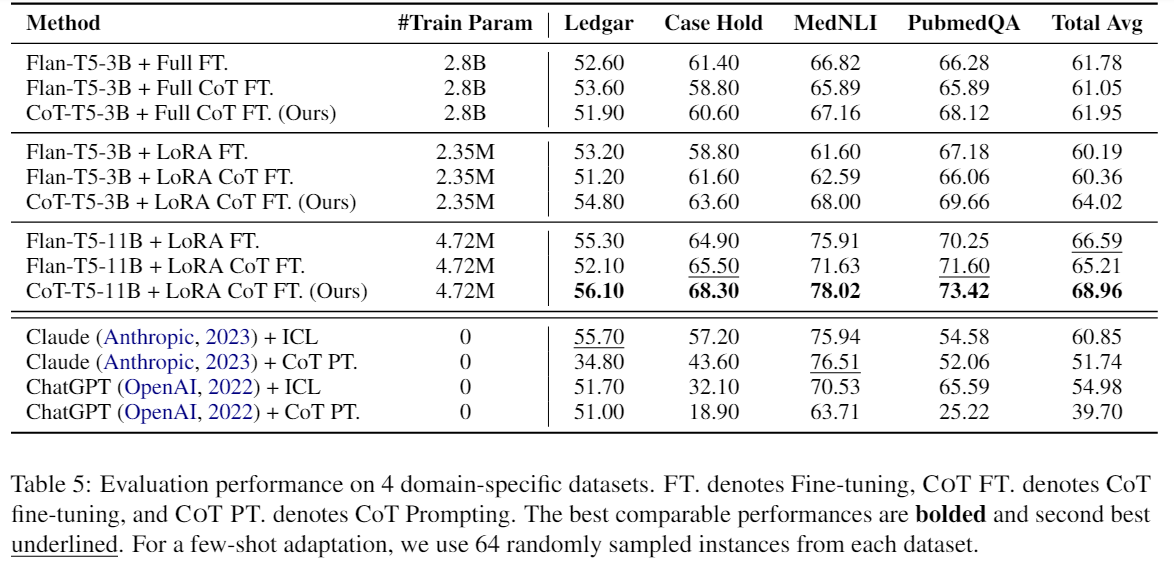
- 주목할만한 점으로 Flan T5에서는 LoRA setting으로 훈련한 것보다 그렇지 않은 것이 더 좋은 output을 냈다는 것이고, 허나 CoT-T5에서는 LoRA setting으로 훈련한것이 압도적으로 높은 perofrmance를 냈다는 점
Analysis of CoT Fine-tuning
- 저자들은 총 개의 질문에 대한 답을 하려고 하였음
- (Trade-off) 과연 실제 상황의 관점에서 보았을 때, CoT의 Task를 세분화하면서 각각마다 데이터를 모으는 것이 중요할지, 아니면 CoT의 Task의 수는 고정시키고 각 Type의 instance를 더 많이 확보하는 것이 중요한가요?
- CoT Fine-tuning을 진행하는동안 LM은 in-domain에서 급격한 성능 저하없이 일반화된 성능으로 fine-tuning이 되나요?
1. Trade-off, scaling the number of tasks & Instances
- 첫 번째 질문에 대한 답은 전자로, Task의 수를 너무 많이 늘리는건 비효율적이여도 Task 고정에 많은 instance들을 모으는거보단 적절하게 Task들을 묶어서 Task의 수를 더 늘리는 것이 효율적이다라는 결론을 이끌어 냄
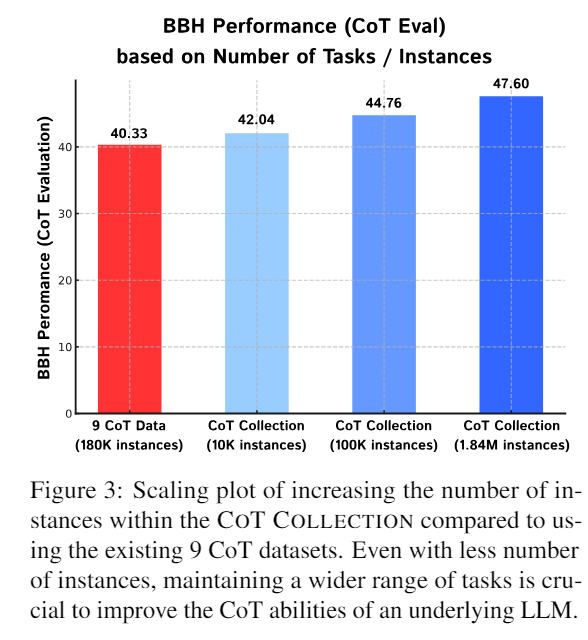
- 이 표에서, 빨간색이 개로 CoT를 고정하고 instance들을 많이 모은 것이고 바로 뒤의 하늘색이 현재의 CoT Collection처럼 개로 세분화하여 훈련을 진행하였을 때 훨씬 적은 instance의 수로도 더 높은 성능을 이끌어낼 수 있음
- 근데 중간에 CoT Collection을 모으는 과정에서는 rational들을 생성하는, 개의 CoT에서 바로 간 것이 아닌데 과연 이렇게 비교하는 것이 맞는지에 대한 의문은 듦
2. In-domain Task Accuracy of CoT-T5
- 두 번째 질문에 대한 답은 "현재로서 우리가 실험했을 때는 유지가 되었으나, 일반적인 상황에서는 모르겠다"임
- 실제로 in-domain task에 대한 정확률을 계산해보면 모든 방면에서 CoT-T5가 높게 나오는 것을 볼 수 있음
- 허나 이 과정에서 저자들은 해당 task들은 모두 CoT-T5와 Flan-T5가 학습할 때 사용한 작업들이기 때문에 이러한 결과가 나온 것이며, 관찰되지 않은 unseen task들에 대해 정확도를 비교하면 더 낮은 결과가 나올 수도 있다는 문제점을 제기하였다.
- 이는 추후 연구 주제 중 하나일 것으로 저자들은 고려중이다.
Conclusion & Limitation
1. Conclusion
- 해당 논문에서는 LLM을 이용하여 rationale를 생성한 을 제안하였고, 이를 이용하여 실제 Fine-tuning을 진행하였을 때 적은 파라미터의 LM으로도 눈에 띄는 성능 향상을 이루어냈다고 볼 수 있음
- 이 CoT Collection이 가지고 있는 의미는 Flan-T5를 tuning하였을 때 더 좋은 결과가 나왔다가 아닌, 적은 수의 parameter를 가지는 LM과 LLM간의 간극을 줄일 때 사용하는 데이터셋임에 있다.
2. Limitation
- CoT-T5 모델에서 문제를 찾으면, 우리가 가지고 있는 CoT-T5는 conversational(대화형)으로 훈련한 것이 아닌 단순히 Input-output으로 훈련이 된 모델임
- 즉, 최근 각광받고 있는 chat-gpt나 Bard 같은 채팅형 application에는 적용했을 때 생각한만큼 성능이 나온다는 보장이 없음
- 앞의 data와 chat data를 모두 융합하여 훈련을 진행할 수는 없을까?에 대한 주제가 향후 연구로 진행될 예정이라고 함
- 또한 multilingual이 지원되지 않음.
- 마지막으로 파라미터 수가 적은 LM에서는 산술 연산(수학 문제를 해결하는 task)에서 굉장히 저조한 결과를 보임. 이번의 Fine-tuning으로 그나마 괜찮아 졌긴 했지만, 그걸 감안해서라도 LLM들에 비해 확실히 많이 차이가 나는 분야임
- 이걸 극복하기 위해서는 수학 문제를 푸는 과정에서는 뭔가 다른 전략이 필요할 것으로 보임
- 개인적인 생각으로는 수학 문제 같은 경우 근거를 조금 다르게 적용하는 것이 중요할 것 같은데, 관련하여 paper 1, paper 2를 읽고 참조할 예정

Hello World!