Process란?
- 프로세스(Process)는 실행중에 있는 프로그램을 말한다.
- 스케줄링이 되는 대상이 되는 작업(task)와 같은 의미로 쓰인다.
- 프로세스 내부에는 최소 하나의 스레드(thread)를 가지고 있는데 실제로는 스레드 단위로 스케줄링을 하게 된다.
Context Switch(문맥교환)을 통해 작업중인 프로세스에 할당한 CPU를 할당 / 회수 할 수 있다. - 하드디스크에 있는 프로그램을 실행하면, 실행을 위해 메모리 할당이 이루어지고, 할당된 메모리 공간으로 바이너리 코드가 올라가게 된다. 이 순간부터 프로세스라 불린다.
Process의 메모리 구조
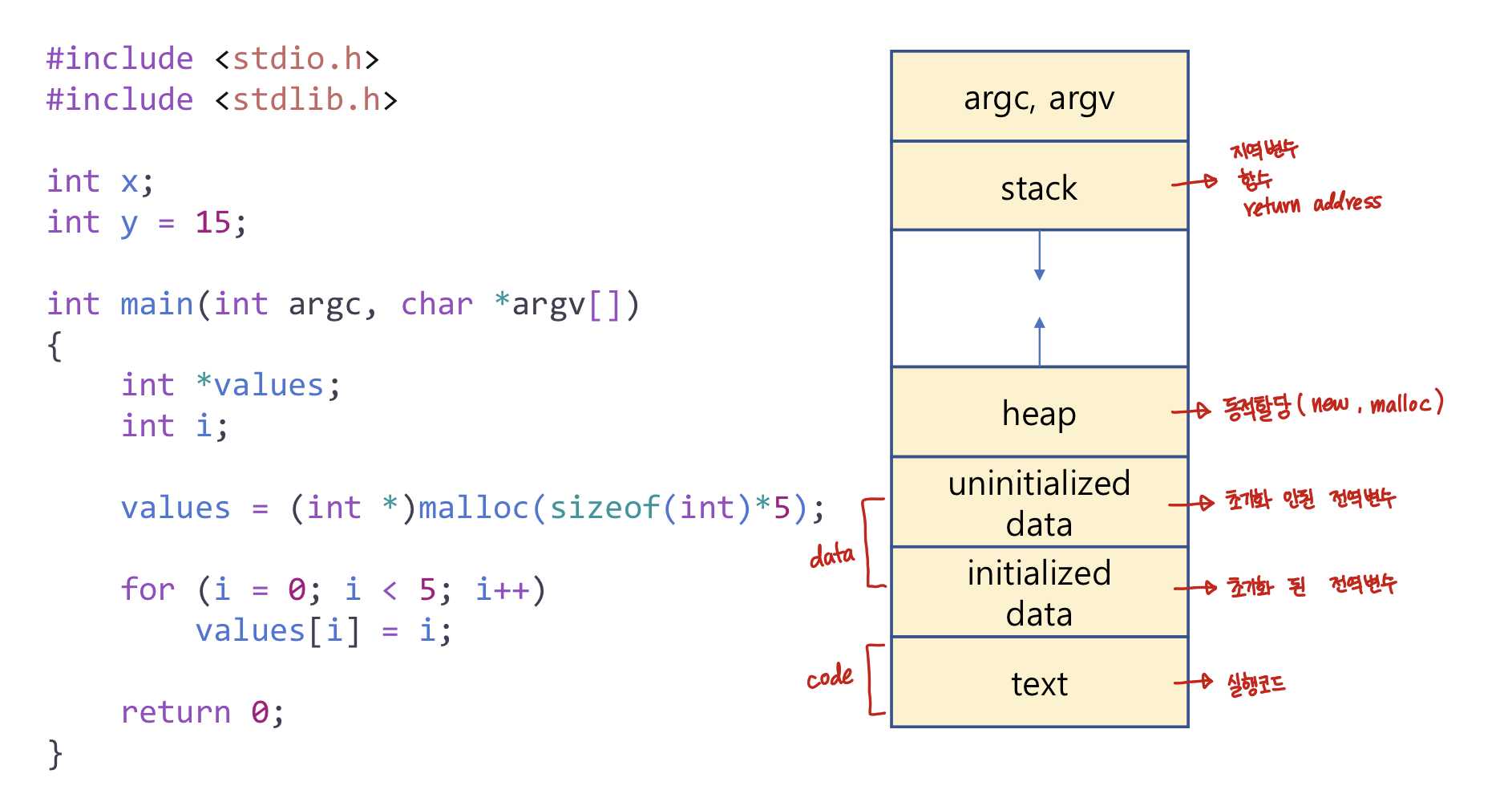
- code : 프로그램을 실행시키는 실행파일 내의 명령어들(소스코드)
- data : 전역변수, static 변수
- stack : 지역변수, 함수, 반환 주소가 런타임에 할당된다.
- heap : 동적 할당을 위한 메모리 영역이다.(ex. java: new ,C++: malloc)
PCB(Process Controll Block)
PCB는 Process마다 가지고 있는 메모리 공간을 의미한다.
PCB는 프로세스의 중요한 정보를 포함하고 있기 때문에 일반 사용자가 접근하지 못하도록 보호된 메모리 영역 안에 남는다.
운영체제에 따라 PCB에 포함되는 항목이 다를 수는 있지만 일반적으로는 다음과 같은 정보가 포함되어있다.
- CPU registers(IR, DR, PC 등)
- PID, PPID, priority, process group, process state(new, nun, wait,ready, terminal)
- CPU Scheduling information(우선순위, 최종 실행시각, CPU점유시간 등)
- Memory management information(해당 프로세스의 주소공간 등)
- Accounting information(페이지 테이블, 스케쥴링 큐 포인터, 소유자, 부모 등)
- I/O status information(프로세스에 할당된 입출력 장치 목록, 열린 파일 목록 등)
Process API(System Call)
- Create(new process)
fork() : child 프로세스 생성(child는 자신의 주소공간, 레지스터, PC를 갖는다) - Destroy(프로세스를 강제로 제거)
exit() : 종료 상태를 parent에게 알려준다.
abort() : 강제로 자원을 회수한다.(오랫동안 자원을 낭비하거나, 자원이 필요하지 않은 상황) - Wait(프로세스가 끝날 때까지 기다려 줌)
wait() : parent 프로세스는 child 프로세스가 끝날 때까지 return을 하지 않는다. - Status(프로세스의 상태정보)
프로그램 실행 과정
- 운영체제는 응용 프로그램과 하드웨어 사이의 인터페이스 역할을 한다. 프로그램을 실행하면 운영체제가 프로세스를 만든다. 커널은 메모리와 다른 자원을 할당하여 프로세스를 만들며, 멀티 태스킹 환경에서 프로세스에 대한 우선순위를 확립하고 메모리에 프로그램 코드를 적재하며 프로그램을 실행한다.

Cpu가 하나의 프로세싱을 실행하는 방법은 다음과 같다.
- create PCB
- program에 메모리 할당
- 프로그램 code와 static data를 메모리 / 프로세스에 탑재한다.
- argc / argv 스택에 적재
- 레지스터 초기화
- main 함수 호출 (프로그램 시작과 동시에 entry point(main())로 CPU를 할당한다.)
main함수 실행 후 return 하면 CPU가 자원을 회수 - Process 메모리 해제 후 제거
인터럽트(interrupt)
인터럽트는 CPU가 프로그램을 실행하고 있을 때, 입출력장치 등 하드웨어에 의해 예외상황이 발생하여 처리가 필요할 경우에 CPU에게 알려 처리할 수 있도록 하는 것을 말한다.
CPU는 인터럽트를 감지하면 지금 실행중인 기계어 코드를 중단하고 해당 인터럽트를 위한 처리 프로그램으로 점프하여 해당일을 수행한다.
인터럽트 처리를 위한 루틴을 인터럽트 서비스 루틴(ISR : Interrupt Servive Routine)이라고 한다.
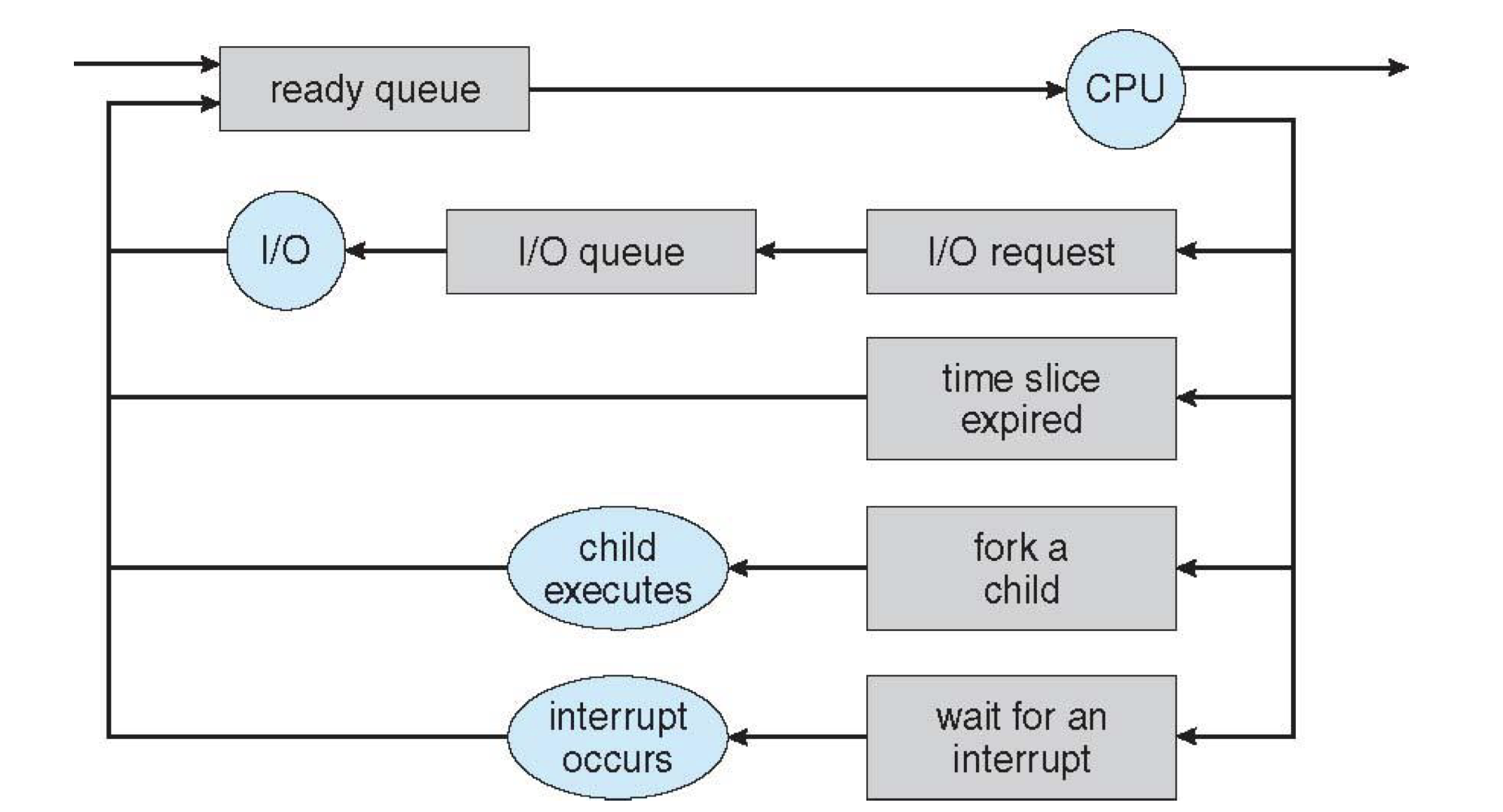
인터럽트 처리 절차
인터럽트 원천인 하드웨어에서 또는 예외상황이 발생하거나 소프트웨어 인터럽트가 걸리면:
- 현재 진행 중인 기계어 코드를 완료한다.
- CPU의 특수레지스터 중, 하이로인터럽트 마스크 비트를 보고 마스크 되면 인터럽트 무시 한다.
- 인터럽트 벡터를 읽고
- ISR 주소값을 얻는다.
- ISR로 점프 한다. 이때 PC(Program Counter, IP) 값은 자동 대피 저장된다.
- 현재 진행중인 프로그램의 레지스터를 대피한다.
- 해당 코드를 실행한다.
- 해당 일을 다 처리하면, 대피시킨 레지스터를 복원한다.
- ISR의 끝에 IRET 명령어에 의해 인터럽트가 해제 된다.
- IRET 명령어가 실행되면, 대피시킨 PC 값을 복원하여 이전 실행 위치로 복원한다.
인터럽트 핸들러
CPU가 인터럽트를 감지하면 해당 인터럽트 핸들러의 코드 위치를 찾고 실행에 옮긴다. 이 때 이전 상태의 CPU상태를 보존하기 위해 레지스터와 프로그램 카운터(PC)를 저장한다. 인터럽트가 핸들링이 완료되면 이전의 상태로 복귀한다.
프로세스 상태와 정의
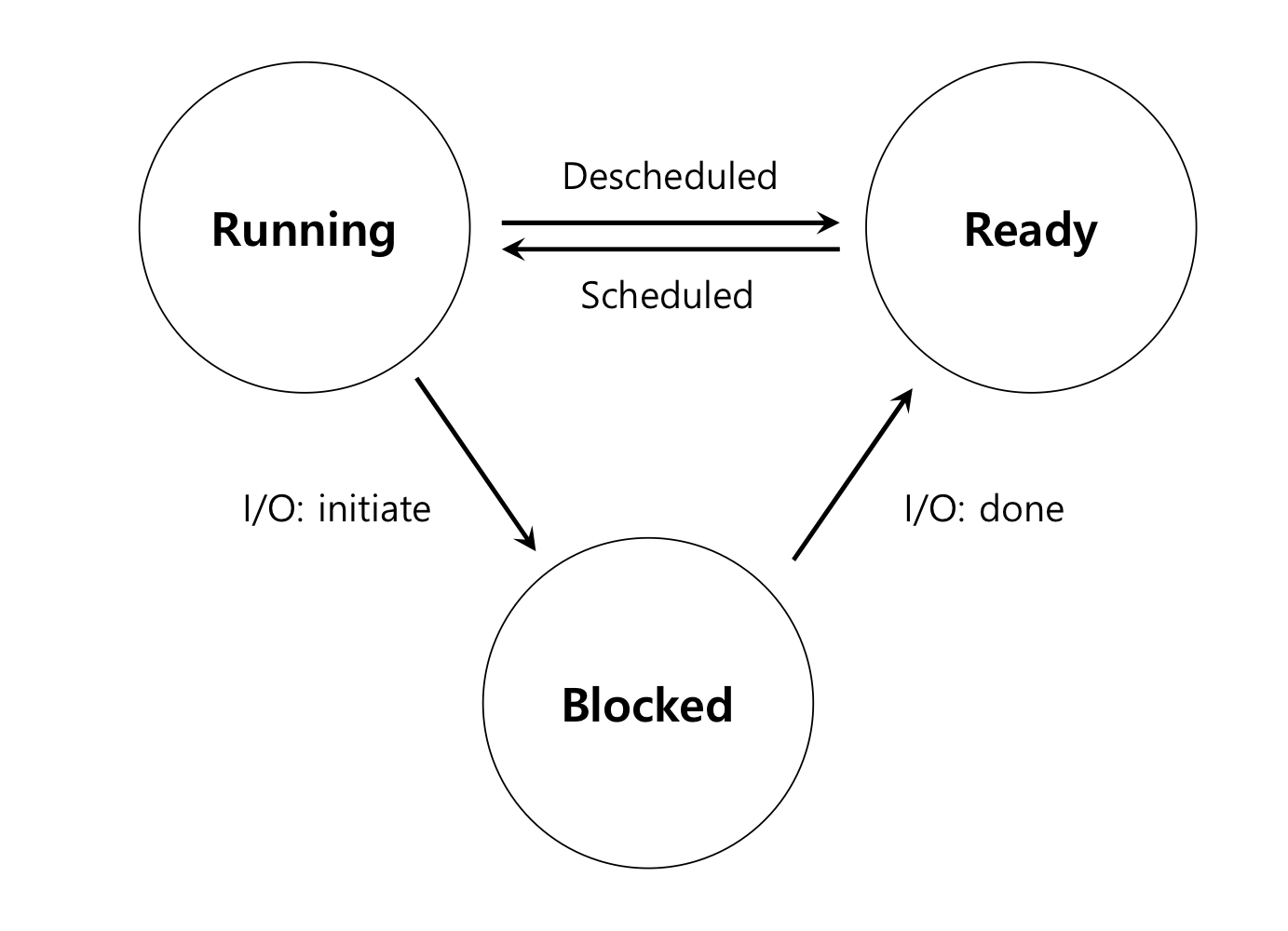
- Running: CPU를 할당받아 코드를 실행중인 상태
- Ready: CPU를 받기 위해 대기중인 상태
- Block: CPU자원이 필요 없는 상태(입출력 연산 중, wait/sleep)

입출력 연산시에는 CPU자원이 필요 없기 때문에 Block 상태로 진입하고, 대기중이었던 프로세스가 CPU를 선점한다.
문맥 교환이란?
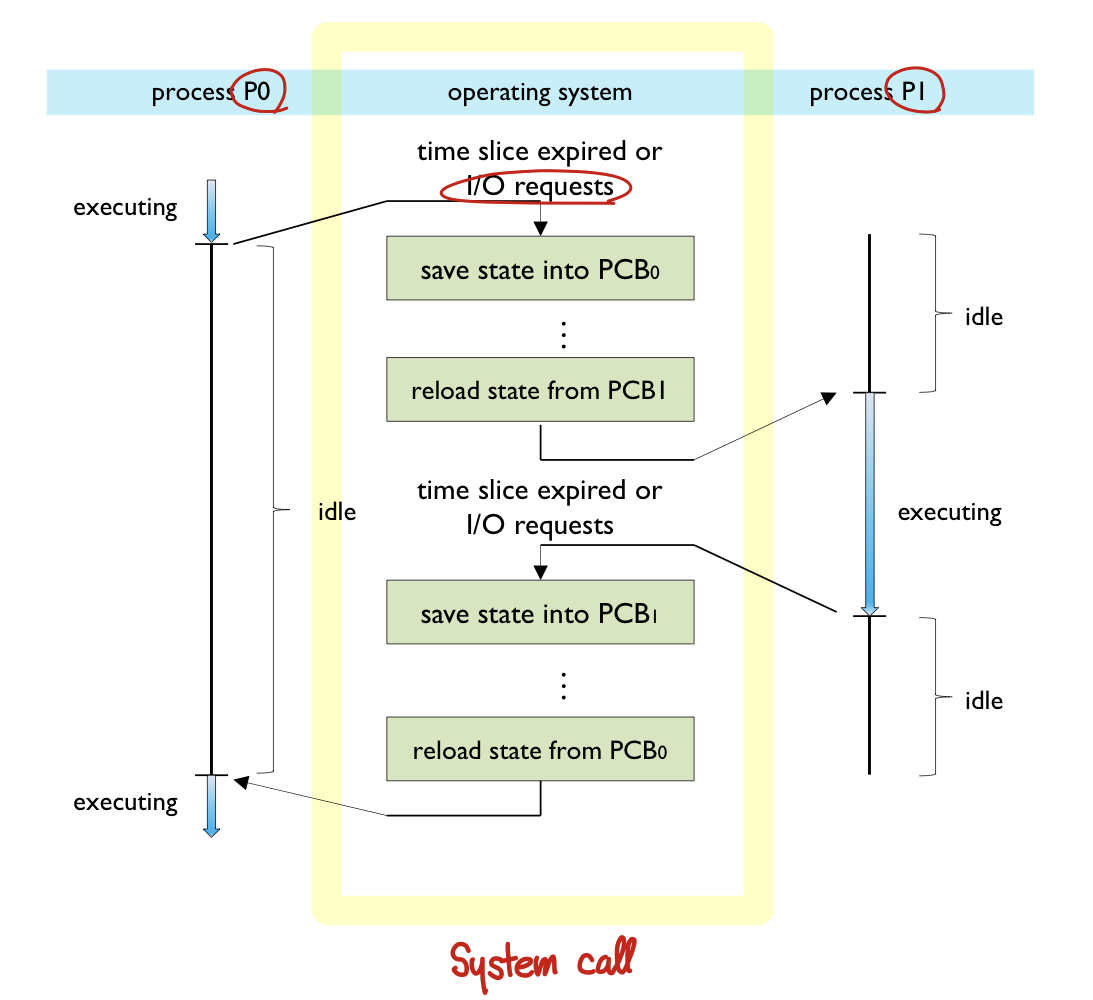
Context Switch(문맥 교환)은 프로세스가 선점 되었을 때 프로세스의 마지막 상태를 기억한다.
- Context save: 메모리에 있는 PCB에 CPU register를 담는 것을 말합니다.
- Context restore: CPU register들에 PCB를 로딩하는 것을 말합니다.
- switching하는 동안은 유용한 일을 못하는 overhead가 발생합니다.
교환 시점으로는 멀티태스킹, 인터럽트 핸들링, 사용자 모드와 커널 모드 간 전환에서 일어납니다.
CPU Scheduling
CPU를 가상화 하기 위해서 운영체제는 여러 작업들이 동시에 실행되는 것처럼 보이도록 물리적인 CPU를 공유한다.
운영체제는 효율적으로 CPU가상화를 구현하기 위해 time Sharing(시분할 시스템)을 이용한다.
운영체제는 효율적인 방식으로 CPU를 가상화하지만 시스템에 대한 제어를 잃지는 않아야 한다.
CPU Scheduling이란 여러 프로세스가 CPU자원을 동시에 요구할 때 제한된 자원들을 어떻게 나눠줄 것인지에 대한 정책을 말한다.
CPU 하나는 동시에 여러개의 프로세스를 처리할 수 없기 때문에, 한 순간에 어떤 프로세스가 CPU를 사용할 수 있게 하는지 결정하는 정책이 도입되었다.
Time Sharing
프로세서들이 자원을 공유할 수 있도록 하는 시스템.
CPU를 가상화하는 테크닉으로 프로세스가 CPU를 독점하는 것 같이 보여주기 위해 CPU의 시간을 작게 분할해 여러 작업을 돌아가면서 수행한다.
time slice(time quantum)
time quantum은 한 사이클 동안 한 프로세스에세 할당되는 최대 CPU시간이다.
각 큐에서 프로세스는 각기 다른 time quantum이 분배되고 프로세스는 자신의 time quantum을 모두 소비하게 되면 다른 프로세스에게 CPU를 넘기고 우선순위가 낮은 큐에 분배가 된다.
time quantum을 정할 때에는 trade off 관계를 고려해야한다.
time quantum이 작은 경우 응답시간이 좋다는 장점이 있지만 문맥 교환을 하게 되는 갱신비용이 크다.
time quantum이 긴 경우 문맥 교환에 쓰이는 시간을 줄일 수 있지만 응답시간이 늘어나게 된다.
이는 아래에서 설명할 CPU스케줄링 평가기준에서 response time 과 turn arround time이 trade off 관계임을 증명해주는 척도이다.
Limit Direct Excution
직접 실행 프로토콜(Direct Excution)은 운영체제에 제한을 두어 Library의 역할만 하는 경우이다.
그러나 이 접근법은 몇가지 문제점을 일으킨다.
- 프로그램이 운영체제가 원치 않는 일을 하지 않을 것이라는 것을 보장할 수 없다.
- 프로세스 실행 시, 한 프로그램이 CPU메모리를 과도하게 사용할 수 있다.

이러한 문제를 해결하기 위해 운영체제는 os가 CPU를 제어할 수 있게 하고, 시스템콜(System Call API)을 제공해 사용자가 사용할 수 있도록 도와준다.
System Call API
운영체제와 사용자는 컴퓨터 시스템의 하드웨어와 소프트웨어 자원을 공유하기 때문에 사용자가 현재 실행되고 있는 프로그램에서 오류가 생겼을 때 다른 프로그램에 영향을 미치지 않게 해야한다.
운영체제에는 유저모드, 커널모드 두가지 모드가 존재한다.
- user mode(사용자 모드)에서 응용 프로그램은 하드웨어 자원에 대한 접근 권한이 일부 제한되어있다.
- kernel mode(커널 모드)에서는 운영체제가 컴퓨터의 제어를 얻을 때 진입한다
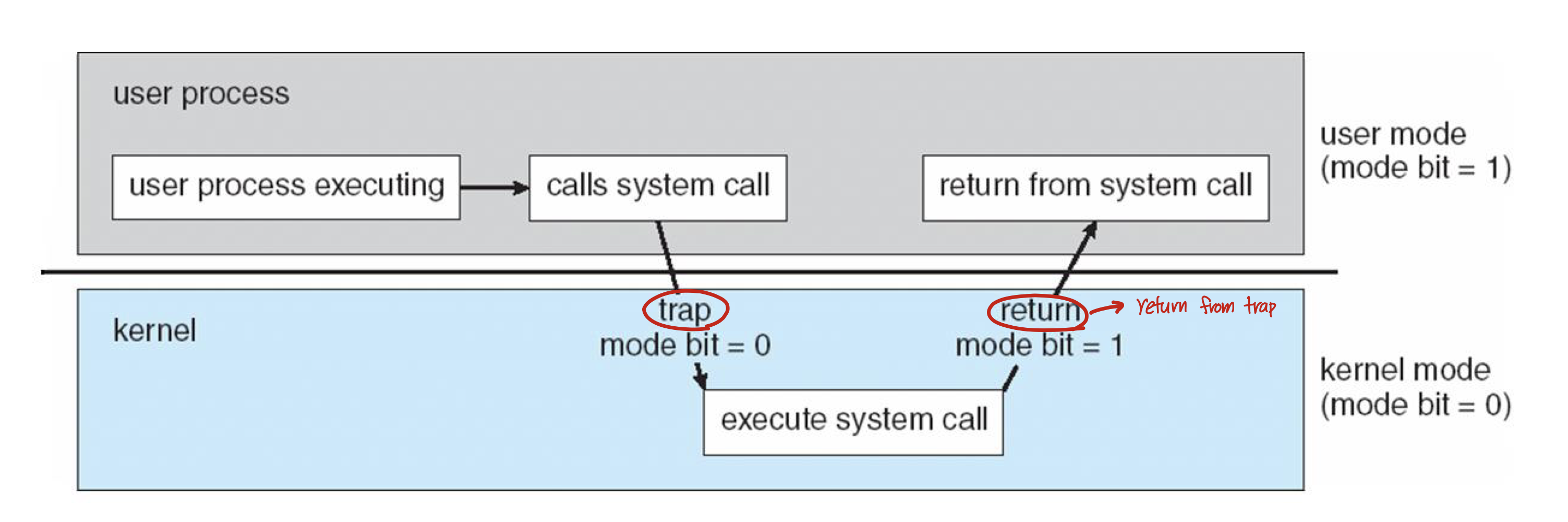
- 프로세스는 유저모드에서 실행되다가 특별한 요청이 필요할 때 호출한 프로세스의 레지스터를 저장한 후 system call을 이용하여 커널에 요청을 한다.(trap)
- system call 요청을 받은 커널이 그 요청에 대한 일을 하고 결과값을 system call의 return값으로 돌려준다. 시스템은 사용자 프로그램으로 제어를 넘기기 전에 사용자 모드로 전환한다.(return-from-trap)
hardware interrupt
: 호출한 프로세스는 분기할 주소를 명시할 수 없다. 주소를 명시한다는 것은 커널 내부에 원하는 지점을 접근할 수 있다는 것이기 때문에 위험하다. kernel에서 호출한 프로세스의 분기할 주소를 명시하기 위해 hardware에 저장한다.
- 커널은 부팅시에 트랩 테이블(trap table)을 만들고 이를 이용하여 시스템을 통제한다.
- 또한 특정 명령어를 사용하여 하드웨어에게 트랩핸들러(trap handler)의 위치를 알려준다.
Timer interrupt
:Process가 비협조적(Non-cooperative)일 때 os가 CPU 제어권을 뺏어오기 위한 방법으로 타이머 인터럽트를 사용한다.
타이머 장치는 수 밀리 초마다 인터럽트를 발생시키도록 프로그램이 가능하기 때문에 일정시간(time quantum)이 지나면 인터럽트를 발생시킨다. 인터럽트가 발생하면 현재 수행중인 프로세스는 중단되고 미리 구성된 운영체제의 인터럽트 핸들러(interrupt handler)가 실행된다.
-> timer interrupt는 context switch 과정에서 time scheduling이 가능하다.
이 매커니즘을 요약해서 나타내면 아래의 그림과 같다.

System call이 할 수 있는 일은 다음과 같다.
- file System에 접근
- Process 생성과 파괴
- Process 간의 소통(sharing)
- 프로세스에 더 많은 메모리를 할당
System call의 함수는 다음과 같다.
- 프로세스 제어: fork(), exit(), wait(),
- 파일 관리: open(), read(), write(), close()
- 장치 관리: ioctl(), read(), write()
- 정보 유지: getpid(), alarm(), sleep()
- 보안(Protection): chmod(),umask(), chown()
CPU Scheduling 방법
- CPU-I/O Burst Cycle
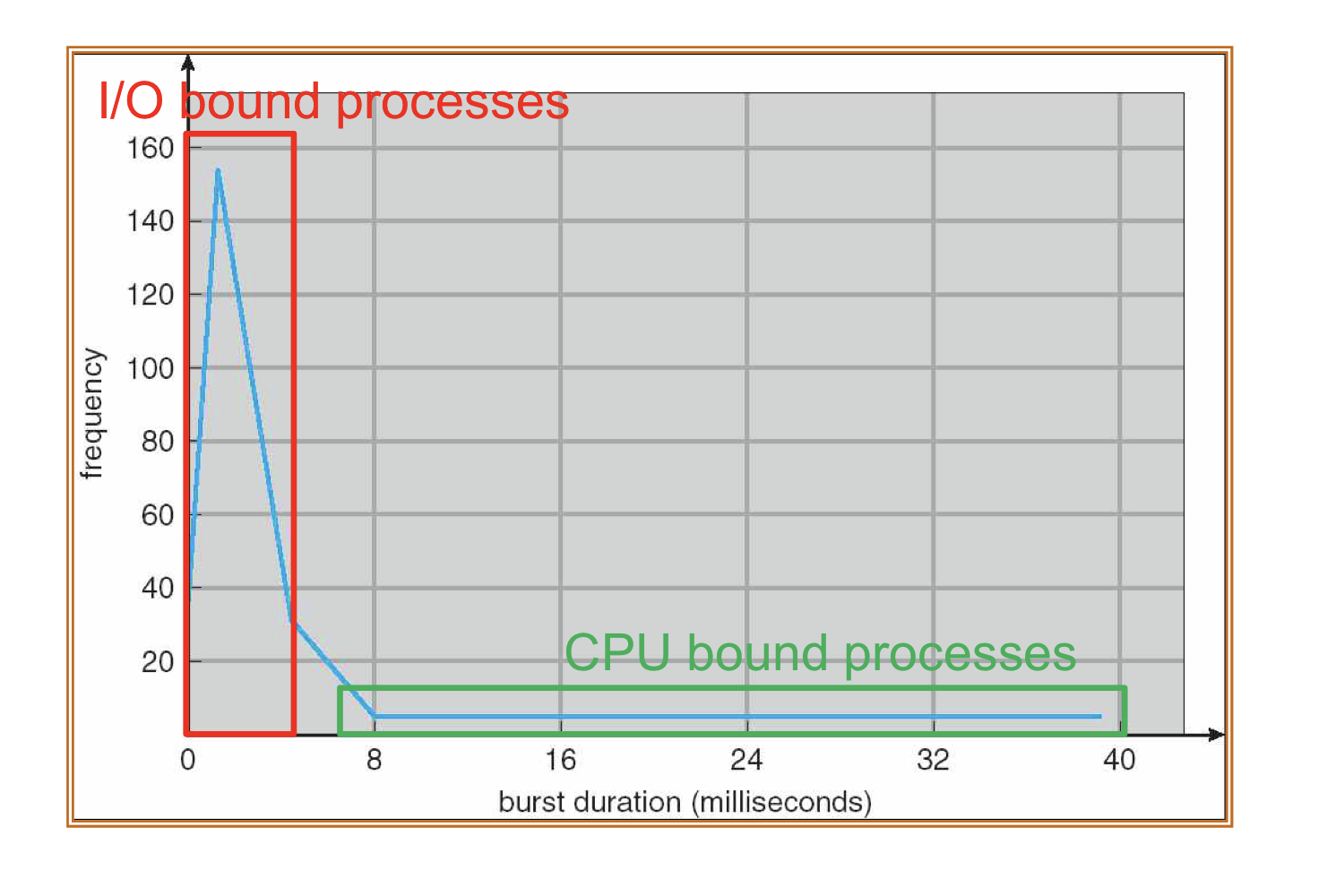
프로세스들이 cpu를 선점하는 빈도수와 시간을 나타내는 표로 CPU processing 할 때 필요한 정보를 나타낸다.
I/O bound process
CPU를 차지하는 시간은 짧고 선점하는 빈도수가 높은 Process이다.
CPU가 할당되는 시간이 짧기 때문에 우선순위가 높다.
우선순위가 높은 프로세스는 CPU 스케줄링을 할 때 높은 순위로 처리가 되지만, time quantum이 짧게 분배가 된다.
CPU bound process
한번의 Processing에 CPU를 차지하는 시간이 많고 선점하는 빈도수는 낮은 Process이다.
CPU가 할당되는 시간이 길기 때문에 우선순위가 낮다.
우선순위가 낮은 프로세스는 CPU스케줄링을 할 때 낮은 순위로 처리가 되지만, time quantum이 길게 분배가 된다.
etc..
cache를 이용하여 CPU성능을 높일 수 있다.

cache는 main memory보다 용량은 작지만 자주 사용하는 주요 데이터들을 모아둔 작고 빠른 저장장치이다.
cache를 이용함으로써 CPU와 Memory간의 다소 느린 속도를 보완할 수 있다.
Scheduling 평가 기준
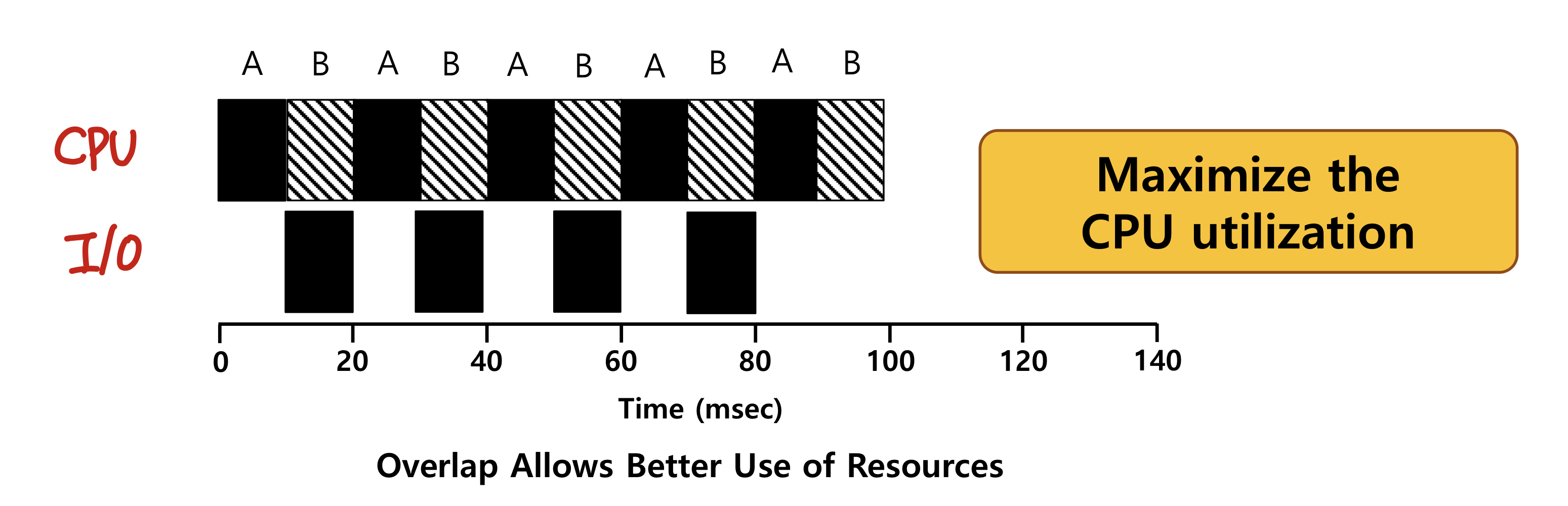
- CPU utilization(maximize)
cpu를 얼마나 바쁘게 사용하는가?
-
프로세스가 입출력 연산을 하는 동안에는 Block 상태이므로 CPU자원이 필요한 상태가 아니다.
CPU입출력이 끝나기를 기다리는 동안 다른 프로세스에게 CPU를 양보해주는 과정으로 CPU의 활용성을 높일 수 있다. -
Troughput(maximize)
단위 시간 당 처리한 process의 개수 -
Turn arround Time(minimize)
하나의 프로세스가 수행하는 시간(프로세스 종료시 까지 걸리는 시간) => 성능 평가의 기준

-
Waiting Time(minimize)
프로세스가 ready Queue에서 기다리는 시간 -
Response Time(minimize)
Process의 첫번째 요청이 수행되는 시점 => 공정성 평가의 기준

Turn arround Time과 Response Time은 Trade off 관계이다.
Response Time을 최소화 하기 위해 평균과 편차를 고려해야한다.
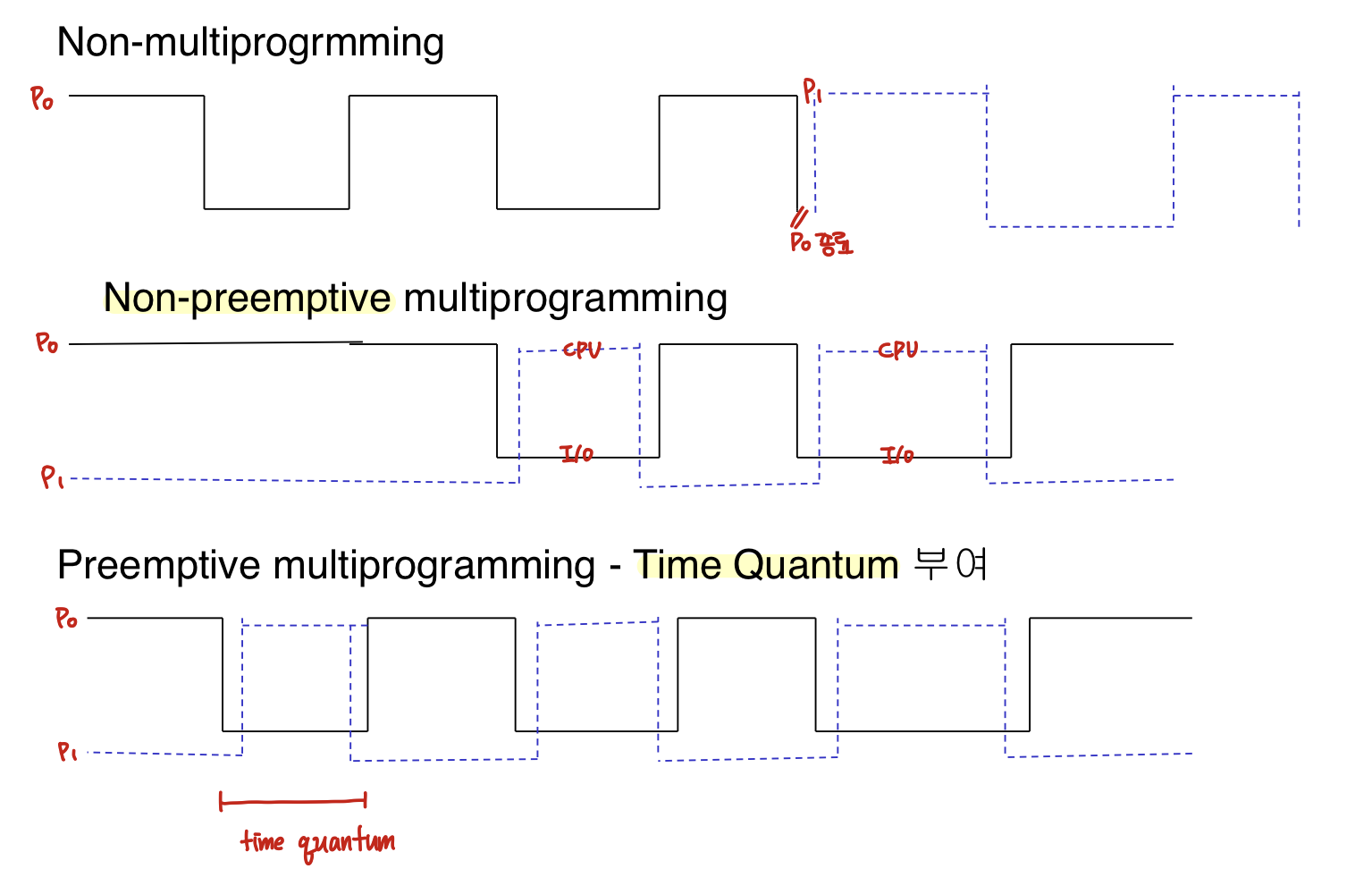
Scheduling의 종류
Non-Preemptive Scheduling(비선점형 스케줄링)
: 프로세스가 한번 스케줄 되면 그 프로세스가 끝날 때까지 다른 프로세스가 끼어들 수 없는 스케줄링 방식
-
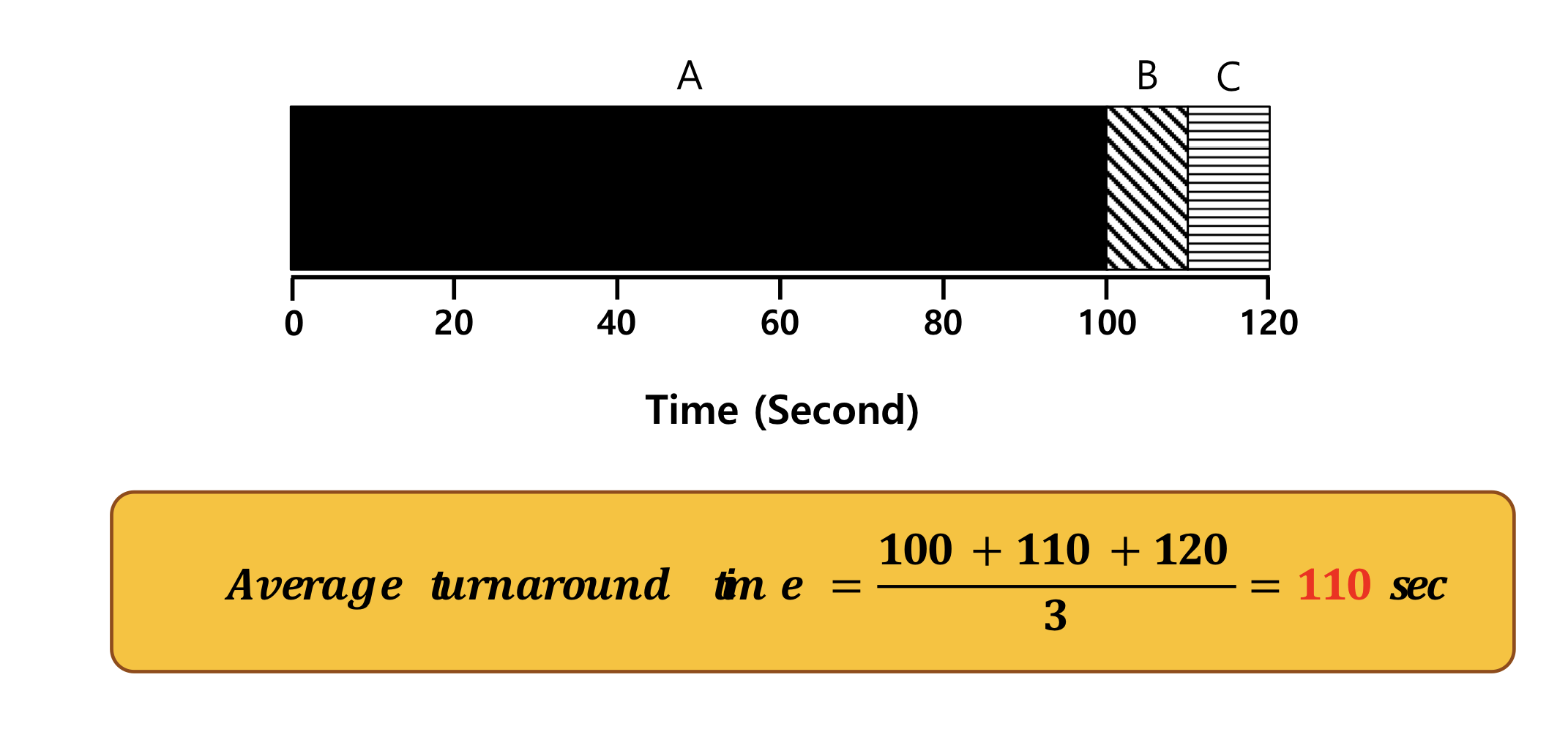
FIFO(First In, First Out): 먼저 들어온 프로세스를 먼저 스케줄.
모든 프로세스의 시간이 같을 때 최적의 스케줄링이다.
but, Convoy effect : CPU time이 긴 프로세스가 먼저 실행 시 다른 프로세스들도 지체가 된다.
-
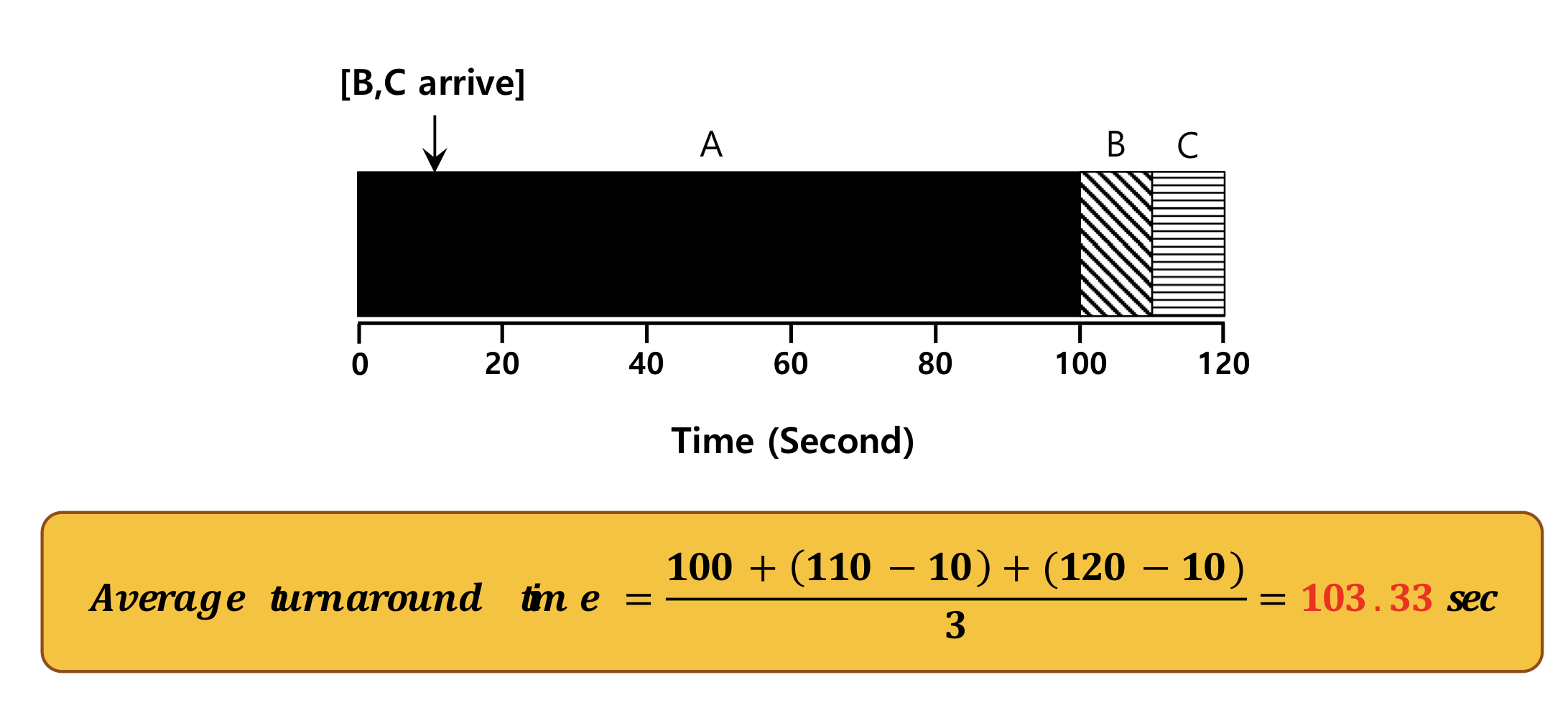
SJF(Shortest Job First): 들어온 프로세스 중 가장 짧은 프로세스를 먼저 스케줄링 한다.
모든 프로세스가 동시에 도착했을 때 최적의 스케줄링
but, CPU를 뺏을 수 없어 같은 arrive time 이 아닌 경우 최적이 아니다.
-
HRN(Highest Response Ration Next) : SJF의 약점을 보완한 기법으로 수행시간이 긴 프로세스가 오랫동안 CPU를 획득하지 못하는 문제점을 보완한 기법이다. 수행시간 과 대기시간을 계산하여 우선순위 에 반영하여 오랫동안 CPU를 획득하지 못하는 문제점을 어느 정도는 보완한 기법이다.
Preemptive Scheduling(선점형 스케줄링)
: os가 프로세스를 중간에 멈추고 다른 프로세스에게 CPU를 할당한다. / Context Switch가 요구된다.
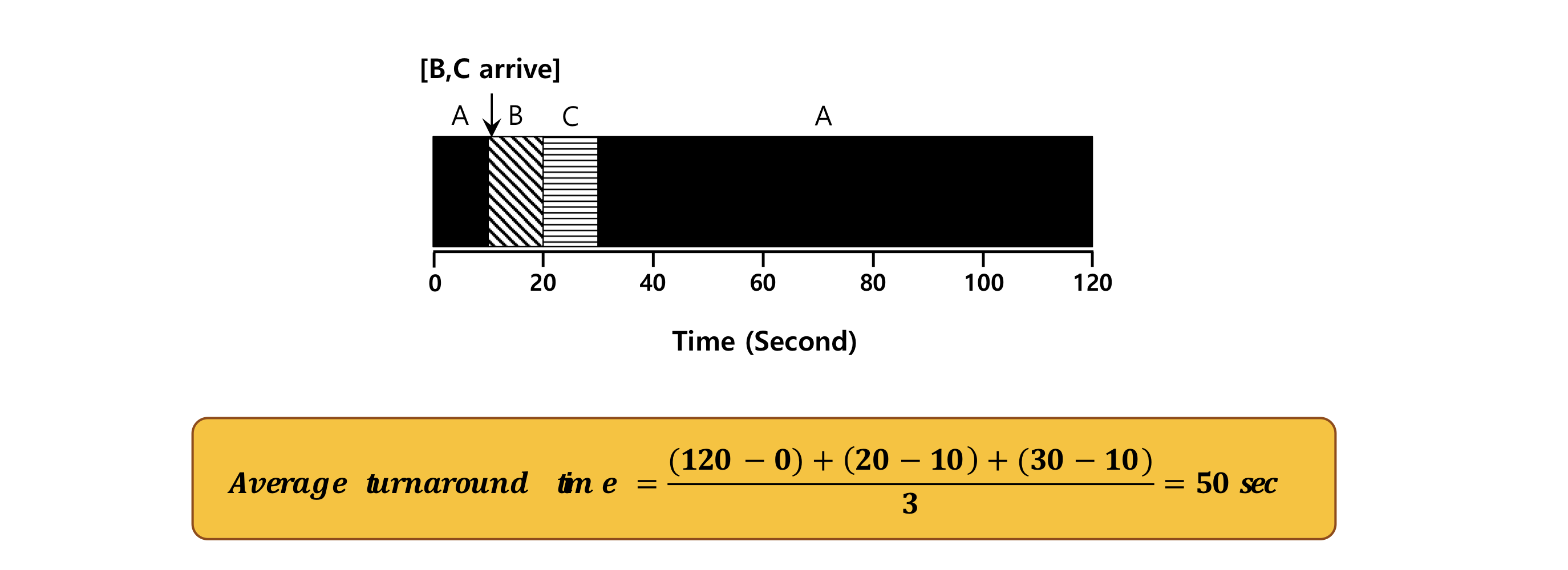
STCF(Shortest Time to Completion First): SJF + Preemptive
Process의 비교를 통해 짧은 프로세스 우선 실행
- RR(Round Robin): Response Time을 최소화 하기 위해 time quantum 만큼 돌아가며 스케줄.
프로세스 사이에 우선순위를 두지 않고 순서대로 time quantum만큼 돌아가며 CPU를 할당한다.
Round Robin은 모든 프로세스가 ready queue에서 기다리는 시간을 공평하게 분배하는가를 판단하는 기준이지만 최악의 경우 RR스케줄링은 FIFO보다 성능이 느리다.
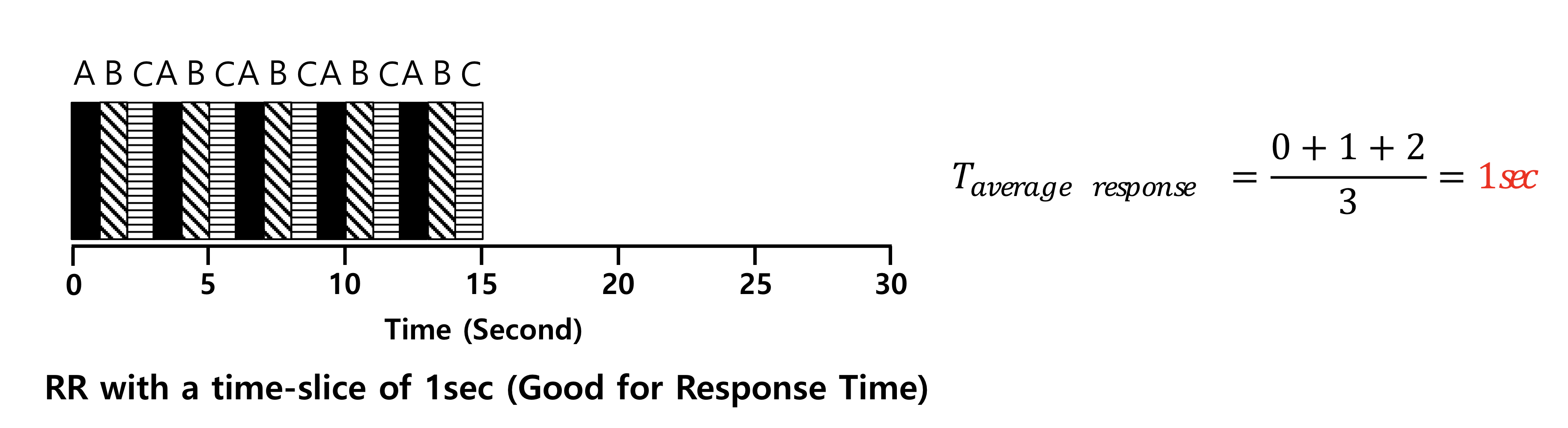
위의 그림처럼 프로세스가 ready queue에 도착한 후 처음으로 수행되는 시간을 계산할 수 있다.
응답시간은 보통 성능 평가 기준인 turn arround time과 trade off의 관계를 가진다.
- MFQ(Multilevel Feedback Queue)
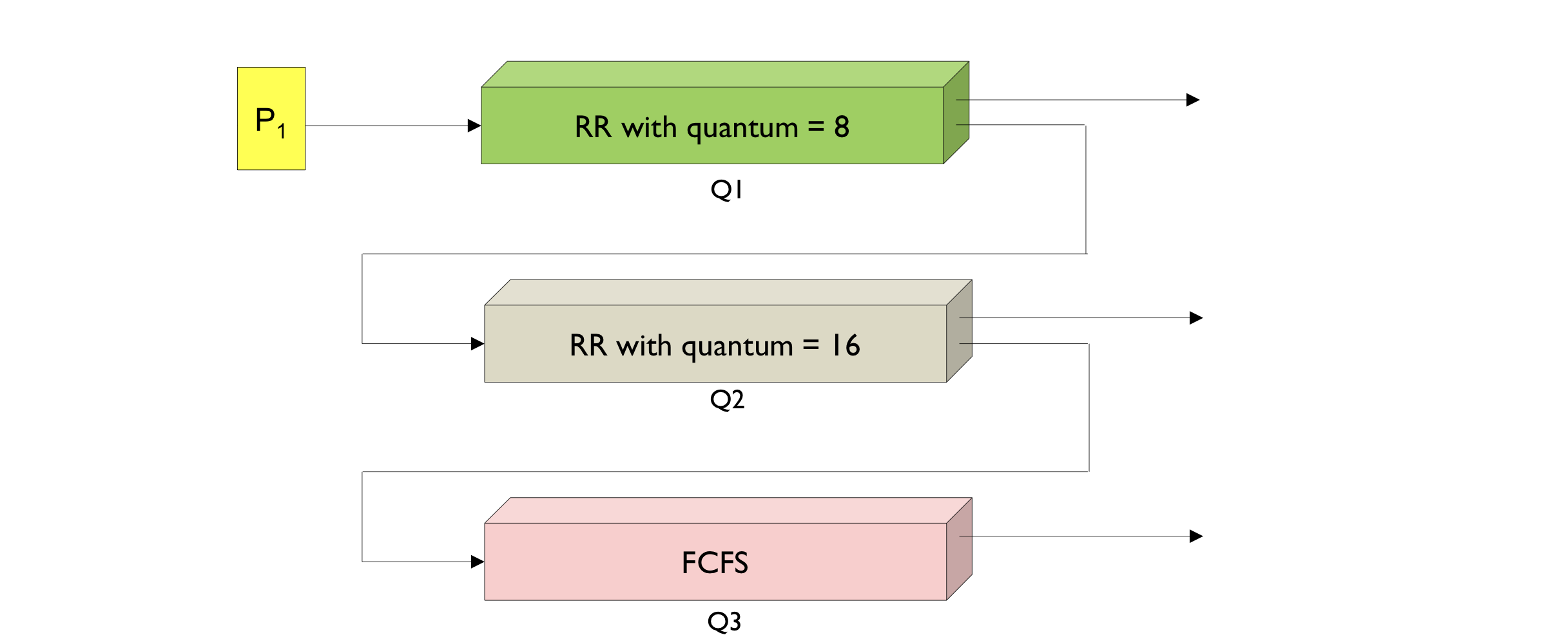
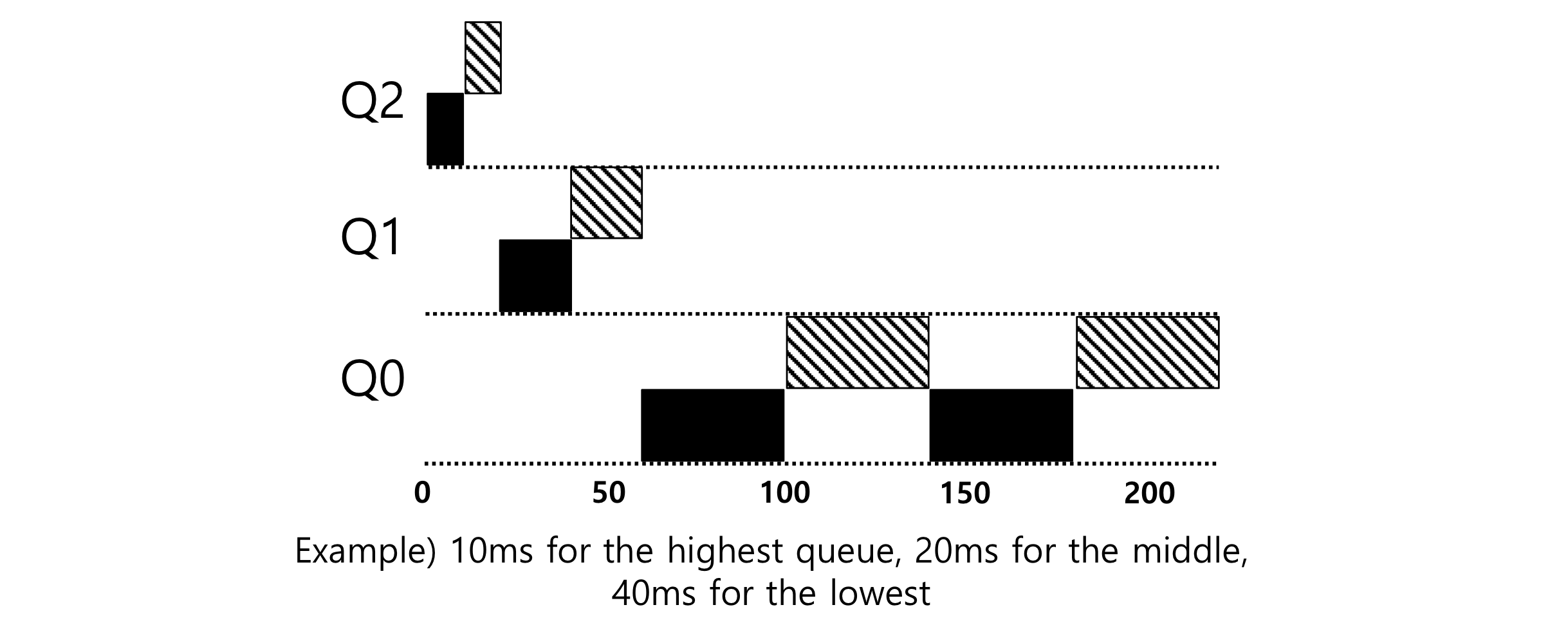
: 여러 개의 ready queue를 사용해서, queue마다 priority(우선순위) 와 time quantum을 할당하고 프로세스가 들어오면 가장 상위 queue에 넣었다가, time quantum이 지나면 하위의 queue로 끌어내리는 스케줄링 방식이다. 가장 하위의 queue에서는 RR방식으로 스케줄링한다. 일정 시간동안 수행되지 못하고 남아있는 프로세스는 다시 상위 큐로 끌어올려준다.
MFQ는 arround time과 response time의 효율성을 극대화 한 방법이다.
- Lottery: 각각의 프로세스에 티켓을 부여하고, 매번 투표를 해 승자를 스케줄링하는 방식이다. MFQ의 단점인 기아상태를 해결할 수 있다.
- Stride: 비결정적인(Non-deterministic) Lottery에 반해서 결정적인(deterministic)스케줄링 방식. 티켓 수에 역수를 취한 값을 stride라 하고, stride 값에 따라 pass 값을 갱신하고 pass 값에 따라 스케줄링 하는 방식.
MultiProcessor Scheduling
앞서 설명한 스케줄링 방법은 single core CPU를 기준으로 설명하였다.
MuptiProcessor는 말그대로 듀얼 코어 이상의 CPU를 가진 컴퓨터이다.
프로세스를 처리하기 위해 CPU를 할당할 때 고려해야하는 기준을 살펴보자
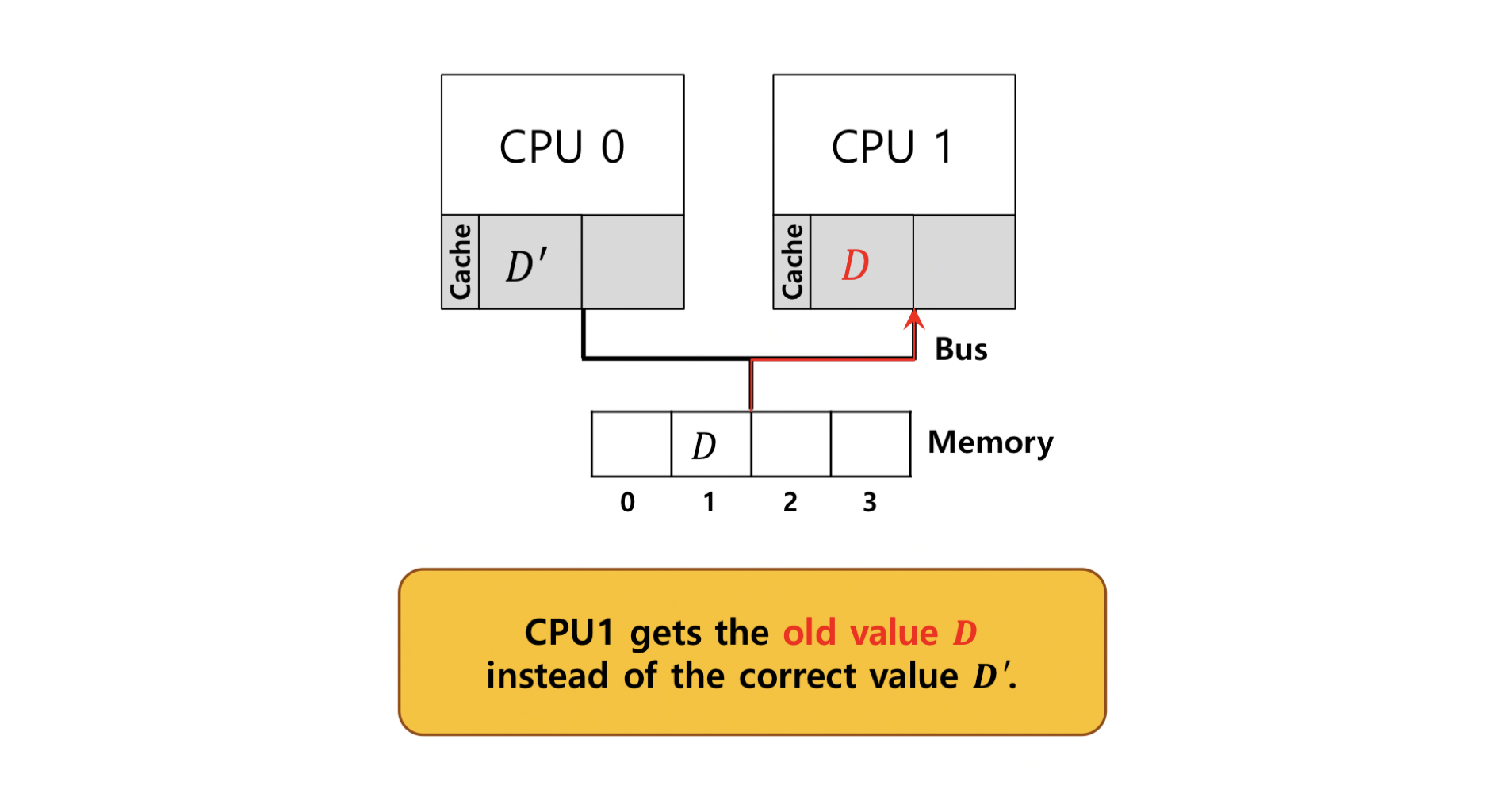
- Cache Coherence : CPU가 동일한 데이터에 접근할 때 데이터의 최신상태를 유지해야한다.
- Synchronization : process의 최신상태를 유지하기 위해 동기화가 필요한데 update를 할 때 동시에 두 CPU가 동시에 업데이트를 할 수 도 있다. 이 경우 Process가 충돌을 일으켜 인터럽트가 발생한다.
- Cache Affinity : Process를 같은 CPU에 할당한다.
CPU에서 실행될 떄 프로세스는 해당 CPU 캐시와 TLB에 상당한 양의 상태 정보를 올려놓게 된다. 해당 CPU에 Process에 관한 정보가 탑재되어있는 경우에는 동일한 CPU에서 작업을 하는것이 성능면에서 유리하다.
스케줄링 종류
- SQMS(Single Queue Multiprocessor Scheduling)
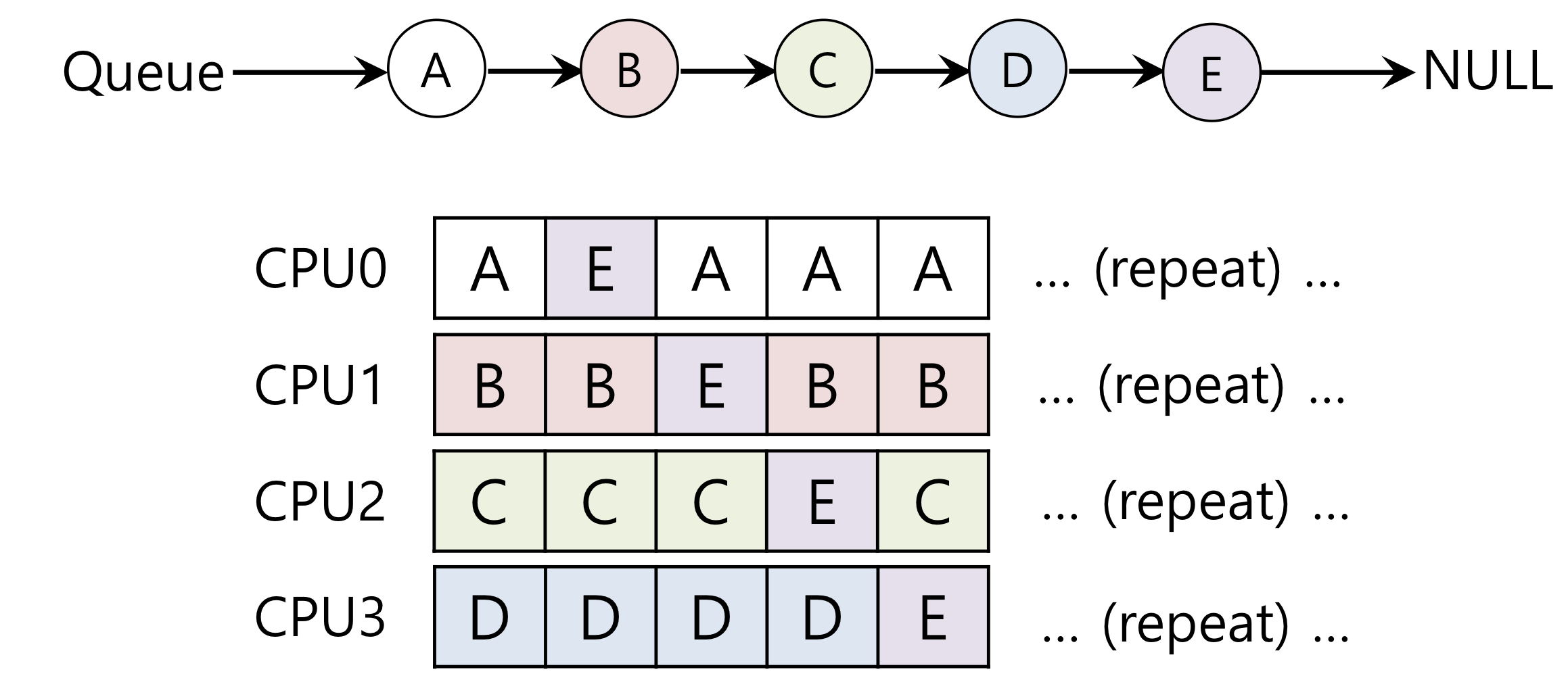
- CPU마다 하나의 Queue를 두고 n개의 코어로 작업하는 방법으로 프로세스가 동일한 CPU에서 재실행 될 수 있도록 시도한다. 단일 큐 방식 (SQMS)은 구현이 용이하고 워크로드의 균형을 맞추기 용이하지만 많은 개수의 프로세서에 대한 확장성과 캐시 친화성이 좋지 못하다.
- MQMS(Multi Queue Multiprocessor Scheduling)
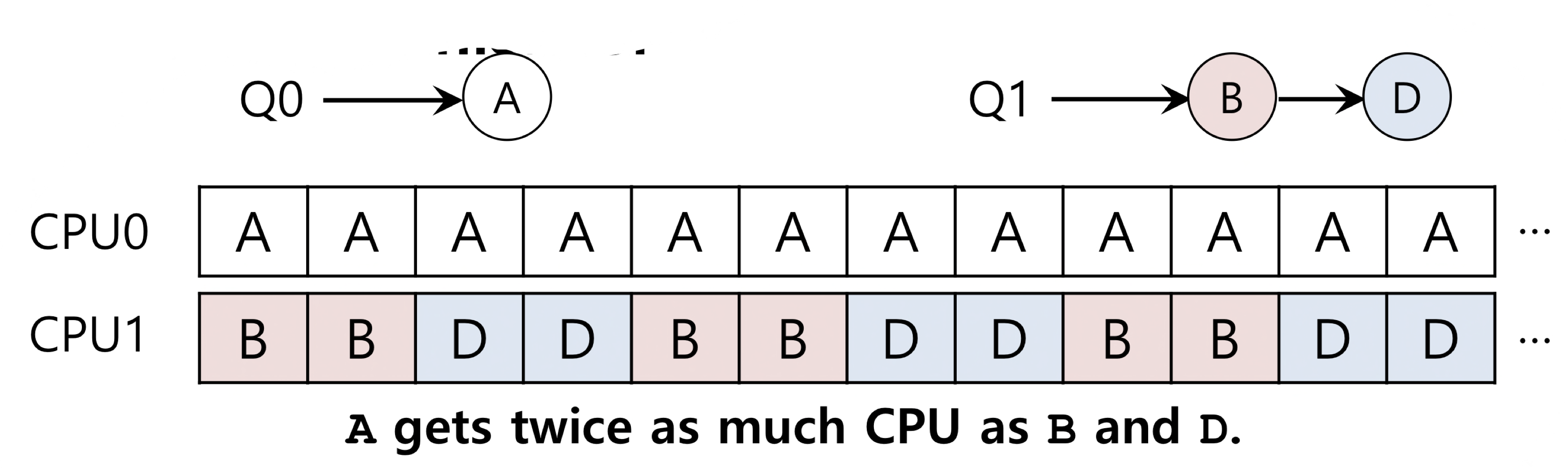
- 멀티 큐 방식 (MQMS)은 확장성이 좋고 캐시 친화성을 잘 처리하지만 워크로드 불균형에 문제가 있고 구현이 복잡하다. #work stealing : 워크로드 불균형을 해결하기 위한 방법중 하나
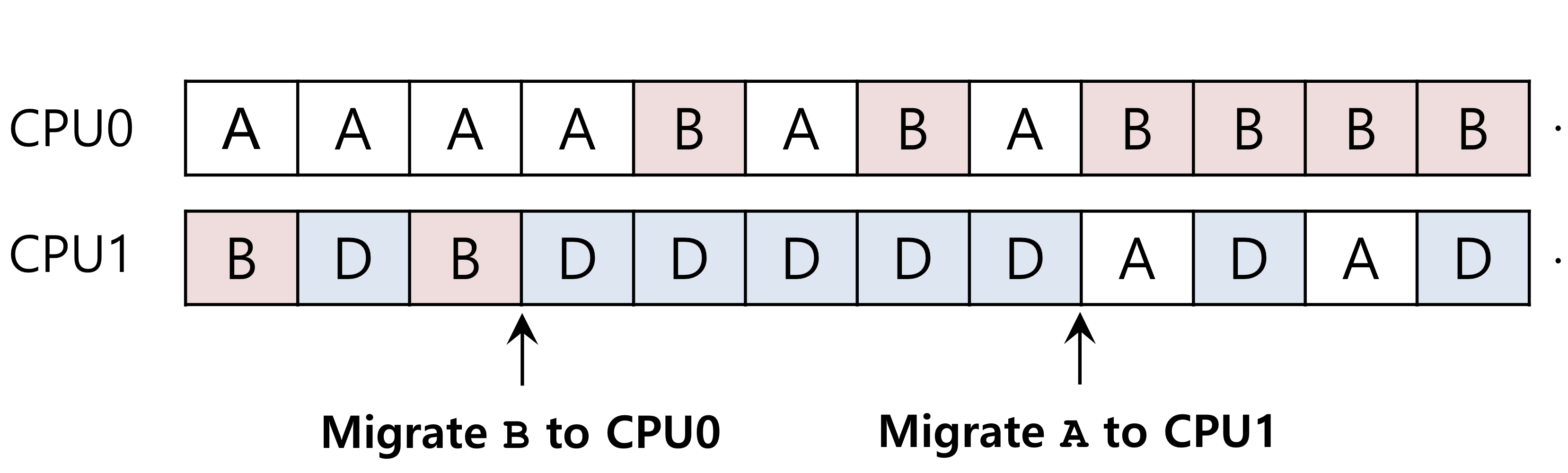
- 위의 그림에서처럼 각 큐를 검사해보고 작업의 개수가 많은 CPU1의 큐에서 작업을 빼앗아 CPU0에 할당한다. but, 처리 해야할 일의 양이 많을 때는 이런 방식을 도입하는것도 힘들 수 있다.
[참고문헌]
- operating systems : three easy pieces
