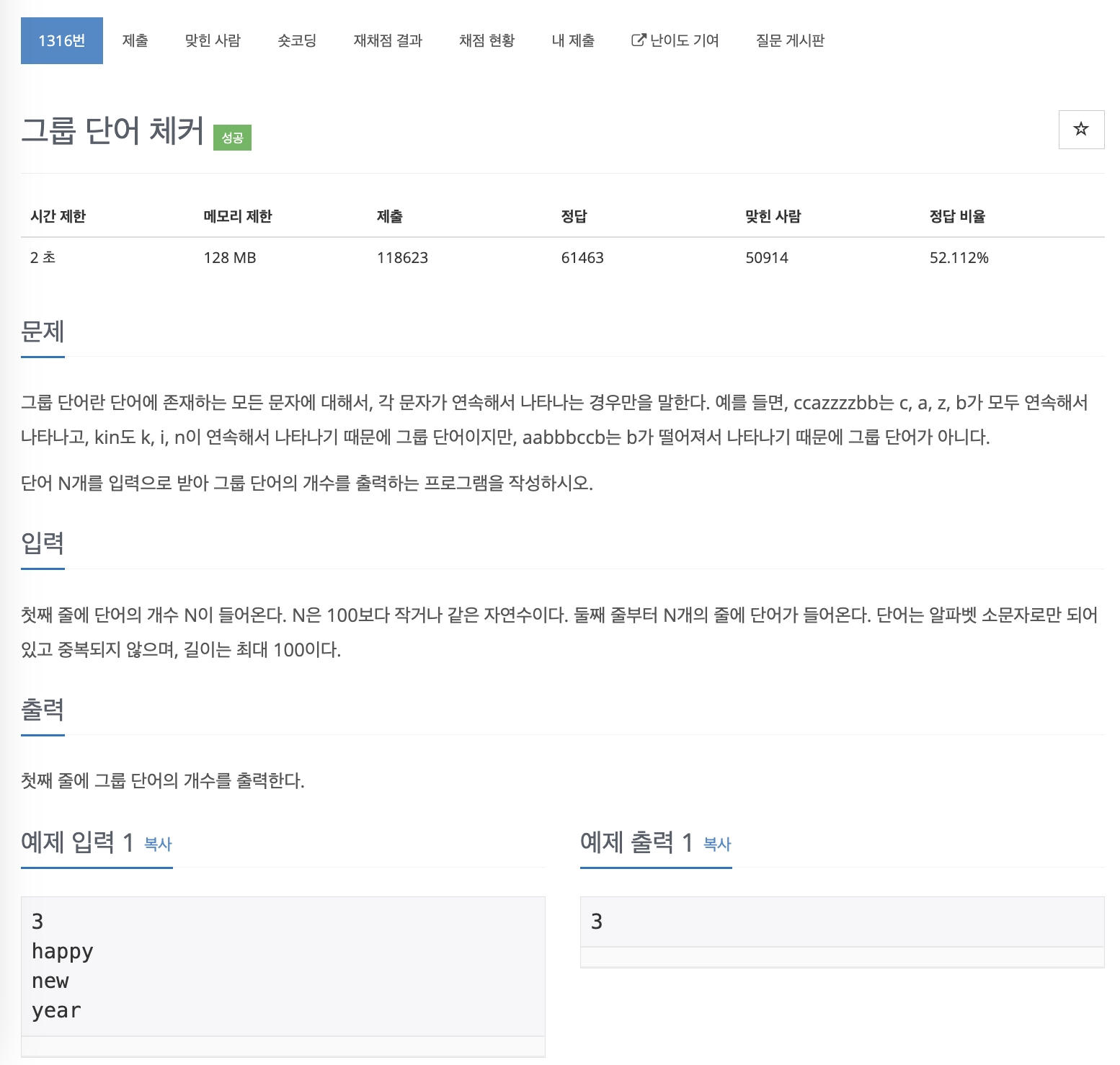
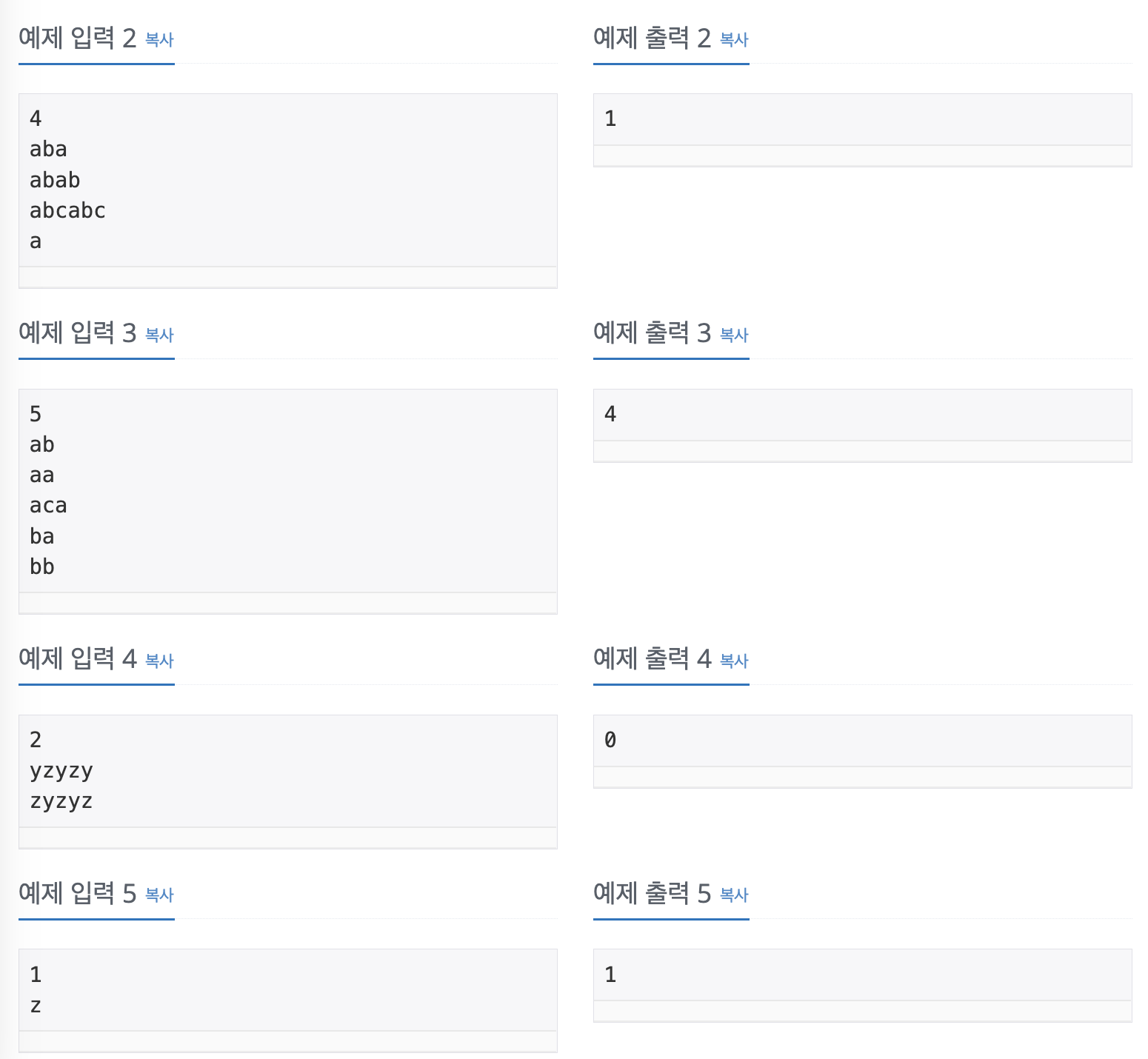
테스트 케이스는 다 맞았는데 채점에서 틀렸다고 해서 반례 찾으려고 노력한 나..
다들 나 뿐만이 아니라, 많이들 비슷한 상황에 놓여주신 덕분에 해결할 수 있었다.
문제 해결 방식은
입력받은 단어 안에 있는 알파벳의 요소들을 리스트에 저장하면서 for문을 돌려
- 인덱스에 해당하는 문자가 알파벳 요소 리스트에 있는지
- 있을 경우 :
- 연속되지 않을 경우 : 그룹단어 아님. - 없을 경우 :
- 요소 리스트에 추가
- 있을 경우 :
- 인덱스에 해당하는 문자가 알파벳 요소 리스트에 없을 경우
: 요소 리스트에 추가 - 문자열 내의 문자 인덱스를 돌리는 for문을 벗어나면 단어 개수 +1
방식으로 문제를 풀었었다.
n = int(input())
str = list(input() for _ in range(n))
result = 0
str_index = []
successed = True
for i in str:
for j in range(len(i)):
if i[j] in str_index and j!=0:
if i[j-1]!=i[j]:
successed = False
else:
str_index.append(i[j])
successed = True
if successed : result += 1
str_index = []
print(result)위 코드는 처음에 제출한 코드였는데, 틀렸다고 채점된 바로 그 코드였다.
질문 게시판에서 볼 수 있었던 대부분의 반례들은 앞에서 체크했던 알파벳을 뒤에서 체크하지 못하는 경우가 많았는데, 내 코드는 다 무난하게 정답이 나왔다.
그럼, 문제가 무엇이었나?
바로 다음과 같은 입력에서 반례를 찾을 수 있었다.
4
another
anything
are
at
>> 4
정답 : 3anything을 그룹단어로 인식하고 있었던 문제였는데,
알파벳 요소 리스트 내에 이미 포함하고 있는 'n'을 두번째로 만났을 때,
연속되지 않는 단어로 체크해놓고
for문을 나가지 않고 다음 for문으로 넘어가게 한 것
이 핵심적인 문제였다.
연속되지 않는 단어로 체크를 하자마자 for문에서 나가도 아무 상관 없기 때문에
break를 추가해 문제를 해결할 수 있었다.
n = int(input())
str = list(input() for _ in range(n))
result = 0
str_index = []
successed = True
for i in str:
for j in range(len(i)):
if i[j] in str_index and j!=0:
if i[j-1]!=i[j]:
successed = False
break
else:
str_index.append(i[j])
successed = True
if successed : result += 1
str_index = []
print(result)이렇게 오늘 문제도 끝!~~야호

tistory에 이어서 기록합니다 👉 https://i-m-okay.tistory.com/