개발 도중 알고리즘을 써본 경혐이 있어 따로 정리하기 위함과 문제 상황과 해결 과정, 개선 효과를 효율적으로 정리하기 위해 작성했습니다.
먼저, 이 글에서 사용된 모든 코드와 데이터는 실제 구현 과정과 구조를 설명하기 위해 수정된 예시입니다.
문제 상황: 카테고리 관리의 복잡성
우리 팀은 약사 - 제약사를 연결하는 플랫폼을 개발하고 있었습니다. 이 플랫폼에서는 약품 관련 상품들을 테이블 형태로 보여주는데, 각 상품은 세부적인 카테고리 정보를 가지고 있습니다.
초기에는 카테고리 관리를 단순하게 접근했습니다. 모든 카테고리 정보를 클라이언트 내부의 constants 폴더에 저장해두고, 카테고리 코드를 사람이 읽기 쉬운 이름으로 변환하는 방식을 사용했습니다.
// 초기 카테고리 관리 방식 예시
const CATEGORY = {
Z201: {
name: '일반의약품'
// ... 그 외 카테고리 데이터
},
// ... 기타 카테고리
};예를 들어, 코드 CATEGORY.Z201.name을 '일반의약품'으로 변환하는 식이었습니다.
여기서 상품 리스트의 API 불러오는데 응답 후 가공해야되는 데이터들 중 각각의 카테고리들이 있습니다.

저 categoryN을 변환하는 식이었죠. 하지만 프로덕트가 고도화되고, 클라이언트 분들에게 추가적인 요구사항을 수용하며 두 가지 큰 문제가 발생했습니다.
- 카테고리의 폭발적 증가
- 추가 요구사항에 따라 카테고리가 1차, 2차, 3차로 세분화되면서 150개 이상으로 늘어남
- 이렇게 많은 카테고리를 클라이언트 코드에서 상수로 관리하는 것이 매우 까다로움
- 데이터 동기화 문제
- 카테고리 정보가 수정될 때마다 클라이언트 코드를 업데이트/배포 필요
- 서버 - 클라이언트 데이터가 일시적으로 불일치하는 문제 발생
이러한 문제들을 해결하기 위해, 카테고리 관리 방식을 변경하기로 했습니다. 모든 카테고리 데이터를 서버에서 관리하고, 클라이언트는 필요할 때마다 서버에서 카테고리 정보를 가져오는 방식으로 전환하기로 했습니다.
이는 더 유연하고 확장 가능한 해결책이 될 것으로 기대했지만, 곧 새로운 도전과제를 마주하게 됐습니다
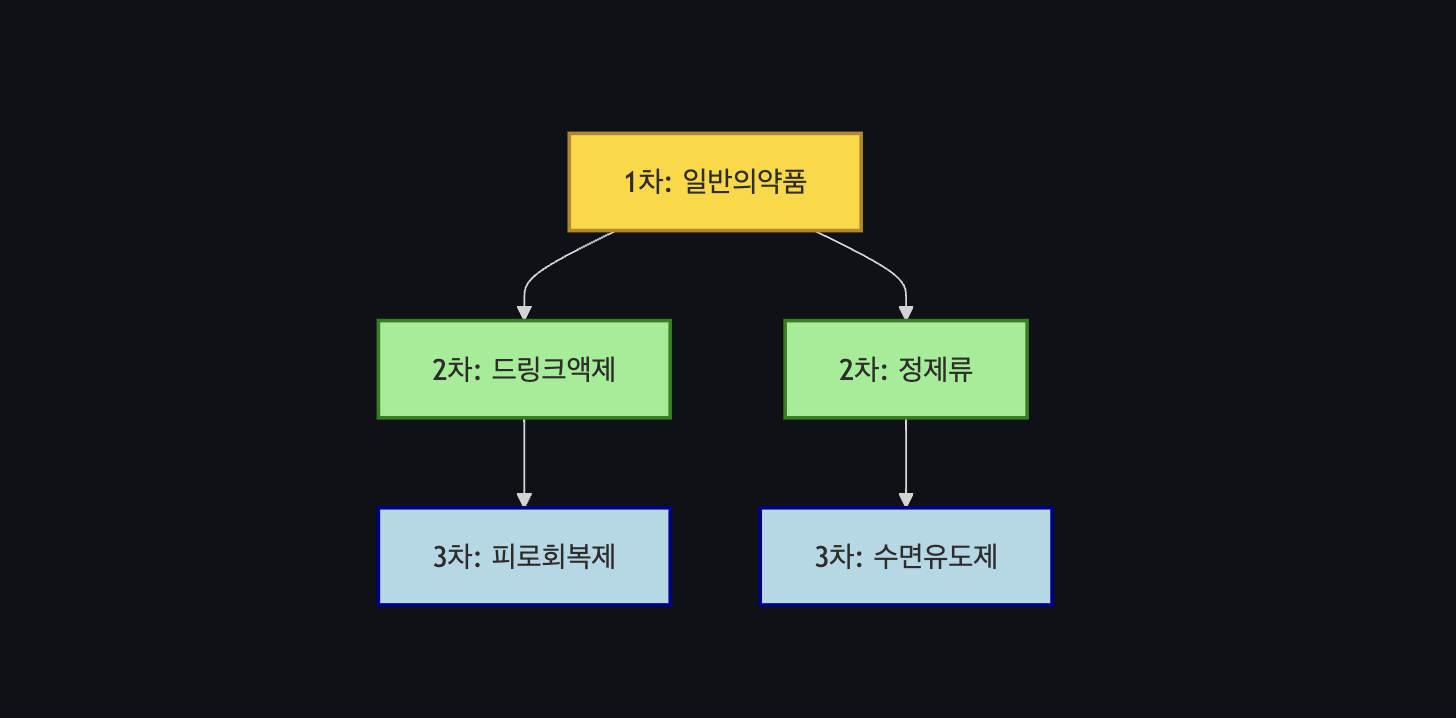
서버에서 변경된 API: 계층형 카테고리 구조
카테고리 API는 카테고리를 서버 내에서 계층적으로 관리하도록 설계되었습니다. 이 구조는 1차 카테고리에서 시작해 2차, 3차로 세분화됩니다. 트리 구조처럼, 종속적으로 연결된 상태로 말이죠.
각 1차 카테고리는 최소 5개의 2차 카테고리를 가지고 있으며, 각 2차 카테고리는 다시 여러 개의 3차 카테고리로 이어집니다.
서버에서 카테고리 정보를 가져오는 방식을 예시 코드로 살펴보겠습니다.
내부 데이터는 유출 위험이 있어서 API 주소 및 Props 키/값은 따로 가공했습니다.
// API 응답 예시 (실제 데이터와는 다름)
// 1차 카테고리 조회: /example/api/category?category=Z2
{
"category": "Z201", // 현재 카테고리 코드
"parent_category": "Z2", // 상위 카테고리 코드
"name": "부모 카테고리 1", // 실제 표시될 이름
"created_at": "2099-99-08T03:23:53.665Z",
"updated_at": "2099-99-08T03:23:53.6652"
}
// 2차 카테고리 조회: /example/api/category?category=Z201
{
"category": "Z10204", // 현재 카테고리 코드
"parent_category": "Z201", // 상위 카테고리 코드
"name": "자식 카테고리 4", // 실제 표시될 이름
"created_at": "2099-99-08T03:23:53.665Z",
"updated_at": "2099-99-08T03:23:53.6652"
}즉, 카테고리를 변환하는 과정은 아래와 같습니다.
- API 엔드포인트(
/example/api/category)에 상위 카테고리 코드를 쿼리 파라미터로 전달 - 서버는 해당 카테고리의 카테고리 정보 반환
- 받아온 코드들은 클라이언트에서 '일반의약품', '드링크액제', '수면유도제'와 같은 실제 표시 이름으로 변환
구현 중 마주친 문제: 카테고리 요청의 폭발적 증가
상품 리스트의 API의 응답 데이터에는 상품 아이템 당 3개 씩의 카테고리가 있습니다.
여기서 문제는 저 상품 리스트의 아이템들이 최소 몇십개가 된다는 것입니다.
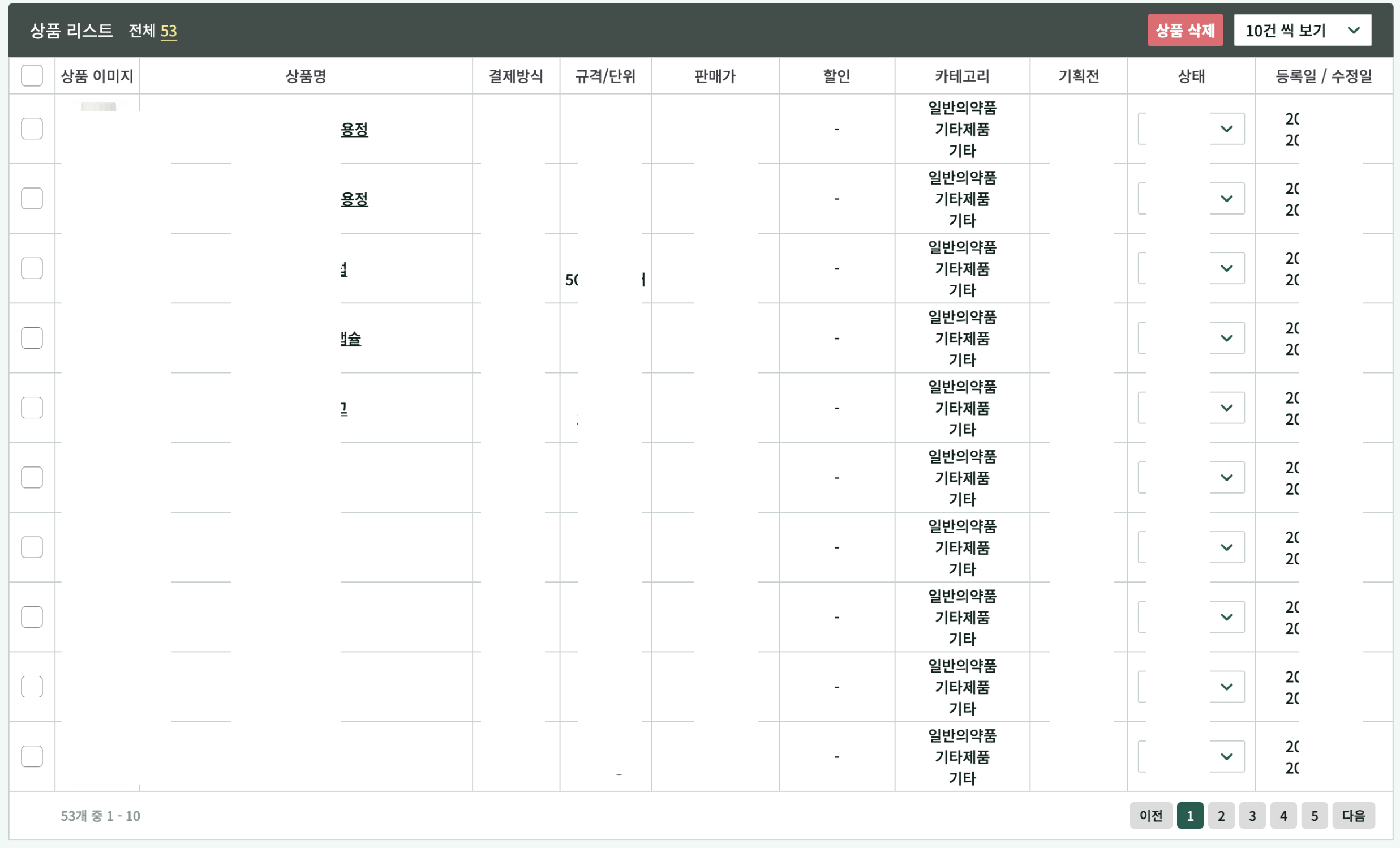
다시 말해, 단순한 카테고리 표시를 위해 너무 많은 API 요청이 발생한다는 점이었습니다.
저 카테고리 항목이 나오기까지 과정을 다시 살펴보면
- 상품의 기본 정보 데이터 가져오기
- 각 상품의 카테고리 코드 인식 후 카테고리 정보를 알기 위해 카테고리 API 요청
- 1차, 2차, 3차 카테고리 데이터를 가져오기 위해 각 상품마다 API를 요청(!)
- 해당 상품에 가져온 카테고리 데이터 중 하나인 이름을 가져와 UI에 적용
이 과정이 모든 상품에 대해 반복됩니다. 만약 한 페이지에 50개의 상품이 있다면
50개 상품 × 3번의 카테고리 요청 = 총 150번의 API 요청!!!!!!!무서워서 다시 통신은 못하지만은 처음 API 요청 수를 확인했을 때의 충격이 아직도 가시질 않았습니다. 만일 이대로 두게 된다면
- 서버 비용/부하 증가 : 수많은 사용자가 동시에 접속할 경우, 인당 최대 150번의 API 호출, 서버 운영 비용도 증가
- 응답 속도 저하 : 많은 요청으로 인해 사용자는 화면이 표시될 때까지 오래 기다려야함
- 50개의 상품 아이템이 존재하는 리스트를 불러오는데 최대 3.2초 정도 로딩 시간 소요
- 중복 데이터 전송 : 같은 카테고리 정보를 여러 번 요청하는 것은 네트워크 자원의 낭비
라는 문제가 생길 것입니다.
사실 제 생각은, 이 설계가 최적의 선택이었을까 하는 의문입니다. 상품 데이터를 반환하는 API에 카테고리 이름을 포함한 데이터를 같이 응답해주는게 더 효율적일 수 있었을 것 같습니다.
하지만 팀 내에서, 현재 프로젝트 상 이렇게 해야 효율적이라는 말씀과 함께 카테고리 API를 별도로 구현한 상황이었습니다.이런 상황 속에서 저는 주어진 API를 최대한 효율적으로 활용하는 방안을 고민해야 했습니다.
첫 시도 실패: 리액트 쿼리
그래서 리액트 쿼리로 캐싱 로직을 이용해 만들려고 했습니다. 해당 쿼리 키가 존재한다면, 캐싱된 데이터를 그대로 가져오는 리액트 쿼리의 고유 기능을 사용하려고 했습니다.
하지만 중복 요청 문제가 그대로임을 확인할 수 있었습니다. 핵심적인 문제는 컴포넌트 구조와 리액트 쿼리의 동작 방식 사이의 불일치에 있었습니다.
당시 구현했던 코드를 간단하게 살펴보면
// 상품 목록을 렌더링하는 부분
{productListData?.map((product) => (
<ProductItem
key={product.id}
product={product}
/>
))}
// ProductItem 컴포넌트
function ProductItem({ product }) {
// 각 상품 컴포넌트에서 개별적으로 카테고리 정보를 요청
const { data: category1 } = useCmnCode(product.category1);
const { data: category2 } = useCmnCode(product.category2);
const { data: category3 } = useCmnCode(product.category3);
return (
<tr>
<td>{category1?.name}</td>
<td>{category2?.name}</td>
<td>{category3?.name}</td>
</tr>
);
}이 구조에서 아래와 같은 문제가 발생했습니다.
1. 컴포넌트 격리로 인한 중복 요청
- 각
ProductItem컴포넌트는 독립적인 환경에서 실행돼 같은 카테고리 코드를 가진 상품이더라도 리액트 쿼리는 이를 별개의 요청으로 처리 - 예를 들어, 10개의 상품이 같은 '일반의약품' 카테고리를 가지고 있더라도 10번의 개별 요청이 발생
// 이런 상황이 발생 // t+0ms: ProductRow1이 'B501' 데이터 요청 시작 // t+1ms: ProductRow2가 'B501' 데이터 요청 시작 // t+2ms: ProductRow3가 'B501' 데이터 요청 시작 // ... 첫 번째 응답이 돌아오기도 전에 모든 요청이 이미 시작됨
2. 캐싱 메커니즘의 비효율
- 리액트 쿼리의 캐싱은 쿼리 키를 기반으로 작동하지만, 컴포넌트 수준에서의 독립적인 실행으로 인해 효과적인 캐싱 실패
- 추측컨데, 리액트의 렌더링 사이클과 쿼리의 실행 타이밍이 맞지 않아 캐싱 실패
한마디로, 동시다발적 요청 및 캐싱 타이밍 이슈 발생 가능성이 발생해 최대 150건의 요청이 그대로 가는 겁니다. 결국 초기 문제를 해결하지 못했습니다.
머리를 쥐어뜯다가 결국 현재 프로젝트에 맞는 메모이제이션 알고리즘 개념을 활용해 커스텀한 기능을 구현하자는 방향으로 이어졌습니다.
메모이제이션이란?
Memoization
동일한 계산을 반복해야 할 경우 한 번 계산한 결과를 메모리에 저장해 두었다가 꺼내 씀으로써 중복 계산을 방지할 수 있게 하는 기법'Memo'에서 유래했는데, 이는 우리가 중요한 정보를 메모장에 적어두는 것과 같은 원리입니다. 프로그래밍에서는 이 개념을 활용하여 동일한 계산이나 데이터 요청을 반복하지 않도록 합니다.
현재 카테고리 시스템에서 이 개념이 특히 유용한 이유는 데이터의 특성 때문입니다. 예를 들어, '일반의약품' 카테고리에 속한 상품이 여러 개 있다면, 이 카테고리 정보를 매번 서버에 요청하는 것은 비효율적입니다.
대신 아래와 같은 프로세스를 구현할 수 있습니다. 사실 리액트 쿼리의 캐싱 로직과 다를 건 없습니다.
- 처음 불러온 카테고리가 있다면 네트워크 호출
- 그 데이터를 저장
- 중복된 요청 값이 있다면 저장된 데이터에서 재사용
예시로는
- 첫 번째 상품: "비타민 C 1000mg"
- 서버에 카테고리 요청: "일반의약품" ✓ (메모장에 기록)
- 다음 상품으로 이동
- 두 번째 상품: "종합비타민"
- 카테고리 확인: "일반의약품"
- 메모장 확인: "있네!" → 서버 요청 없이 바로 사용
이러한 로직을 짜야겠다고 생각했습니다. 리액트가 렌더링 하는 시점에 맞춰서 말이죠!
구현 과정: 메모이제이션을 활용한 카테고리 시스템
카테고리 시스템 구현은 효율적인 데이터 관리와 사용자 경험 최적화를 목표로 합니다. 이를 위해 우선 1차 카테고리를 기본 데이터로 설정했습니다.
1차 카테고리는 상품의 가장 기본적인 분류 기준이 돼 시스템 시작 시점에 parent_category가 상품 카테고리-Z1인 카테고리 데이터를 미리 불러오도록 설계했습니다.
설계
1. 데이터 상태 관리 전략
상태 관리의 핵심은 각 상품의 카테고리 정보를 효율적으로 저장하고 관리하는 것입니다. 이를 위해 두 가지 주요 메커니즘을 활용할 겁니다.
- 카테고리 상태 정의 :
cateOfList라는 상태 객체를 통해 각 상품의 전체 카테고리 계층(1차, 2차, 3차) 관리 - 리액트 쿼리 : 공통 코드를 가져올 때 리액트 쿼리의
useCmnCode훅을 사용해 캐싱된 데이터를 활용.
2. 계층적 캐싱 구조
카테고리 데이터는 마치 나무의 가지처럼 계층적으로 구성됩니다.
- 2차 카테고리 캐싱 : 1차 카테고리 코드를 기반으로 2차 카테고리를 캐싱(메모)
- 3차 카테고리 캐싱 : 2차 카테고리 코드를 기반으로 3차 카테고리를 캐싱(메모)
예를 들어, '일반의약품'이라는 1차 카테고리 아래의 모든 2차 카테고리를 한 번에 저장합니다.
3. 카테고리 데이터 검증 및 로딩 프로세스
각 상품의 카테고리 데이터가 이미 캐싱된 경우 이를 즉시 활용하고, 캐싱되지 않은 경우에만 API를 호출하여 데이터를 가져오는 방식으로 최적화하는 방식을 취할겁니다.
- 1차 카테고리 확인 : 가장 먼저 기본 분류를 확인, 이미
cateOfList에 있는지 확인 - 2차 카테고리 검증 : 이미 저장된 데이터가 있는지 확인하고, 없을 때만 새로 서버에 요청
- 3차 카테고리 검증 : 2번과 동일
데이터를 불러오는 과정은 마치 도서관에서 책을 찾는 것과 같은 단계적 접근을 사용합니다.
4. 사용자 인터페이스 연동
최종적으로, 수집된 모든 카테고리 정보는 사용자에게 의미를 전달 가능한 방식으로 표시됩니다.
- 각 상품별로 완전한 카테고리 경로 치환(예: 일반의약품 > 드링크제 > 피로회복제)
- 리액트 생명 주기를 건드려줄
cateOfList상태 사용, 실시간으로 UI를 업데이트
데이터 담을 상태 선언
이제 메모를 하기 위한 상태를 선언해 거기에 담아줄 것입니다. 메모이제이션을 구현하기 위해서는 먼저 데이터를 효율적으로 저장할 구조가 필요합니다.
// 각 상품의 완성된 카테고리 정보를 저장하는 상태
const [cateOfList, setCateOfList] = useState<{
[productId: string]: string[];
}>({});이 cateOfList 상태는 각 상품(productId)별로 세 단계의 카테고리 이름을 배열로 저장합니다. 서버에서 받은 코드 값(category)이 아닌, 실제 표시될 이름(name)을 저장한다는 점이 중요한 특징입니다.
예를 들어, 코드 Z201이 아닌 '일반의약품'이라는 실제 이름을 저장하는 것입니다.
다음으로, 1차 카테고리 정보를 가져오기 위한 커스텀 훅을 사용합니다.
// 1차 카테고리 데이터 불러오기
const { data: cmnCode1 } = useCmnCode('Z2');이 useCmnCode 훅은 모든 상품의 기본이 되는 1차 카테고리 정보를 가져옵니다. Z2는 모든 상품이 공유하는 최상위 카테고리 코드이므로, 이를 미리 불러와 cmnCode1이라는 이름으로 저장해둡니다.
마지막으로, 2차와 3차 카테고리 정보를 캐싱할 객체들을 선언합니다.
// 2차와 3차 카테고리 정보를 위한 캐시 저장소
const cmnCode2s: {
[parentCode1: string]: CmnCodeItem[];
} = {};
const cmnCode3s: {
[parentCode2: string]: CmnCodeItem[];
} = {};이 두 객체는 메모이제이션의 핵심이 되는 캐시 저장소입니다. cmnCode2s는 1차 카테고리 코드를 키로 사용하여 해당하는 2차 카테고리 정보들을 저장하고, cmnCode3s는 2차 카테고리 코드를 키로 사용하여 관련된 3차 카테고리 정보들을 저장합니다.
각각 2차 카테고리는 1차의 코드인 Key(Z1)로 받고 있고 3차는 2차를 Key로 받고 있습니다. CmnCodeItem 타입은 카테고리 데이터를 정의한 타입입니다.
이렇게 설계된 데이터 구조는 우리가 다음 단계에서 구현할 메모이제이션 로직의 기반이 되며, 카테고리 정보를 효율적으로 저장하고 재사용할 수 있게 해줍니다.
카테고리 데이터 검증 후 캐싱된 데이터 불러오기
가장 핵심적인 부분입니다. 조건에 따라 데이터를 검증하고 메모이제이션을 실행하거나 불러오는 로직을 구현했습니다.
// 컴포넌트가 렌더링될 때마다 실행, 메모이제이션 이용
useEffect(() => {
const fetchData = async () => {
if (productListData && cmnCode1) {
// 초기 제품별 카테고리 정보 객체, cateOfList 상태에 조합해 set
const initialCateOfList: { [productId: string]: string[] } = {};
// 각각의 제품에 대해 순회
for (const item of productListData) {
if (item?.category1) {
// 2단계 카테고리 코드를 가져오기 위한 조건 확인 및 처리
if (!cmnCode2s[item.category1]) {
// fetch 및 정보 가공
const response2 = await fetch(`${카테고리 API 주소}?category=${item.category1}`, REQ_OPTIONS);
const cmnCode2Res: CmnCodeResponse = await response2.json();
const cmnCode2: CmnCodeItem[] = cmnCode2Res.payload.items.flat();
// 객체에 Parent Code로 할당
cmnCode2s[item.category1] = cmnCode2;
}
// 3단계 카테고리 코드를 가져오기 위한 조건 확인 및 처리
if (item?.category3 && !cmnCode3s[item.category2]) {
// fetch 및 정보 가공
const response3 = await fetch(`${카테고리 API 주소}?code=${item.category2}`, REQ_OPTIONS);
const cmnCode3Res: CmnCodeResponse = await response3.json();
const cmnCode3: CmnCodeItem[] = cmnCode3Res?.payload.items.flat();
// 객체에 Parent Code로 할당
cmnCode3s[item.category2] = cmnCode3;
}
// 각 카테고리 이름을 가져오기
const category1Name = getNameByCode(cmnCode1, item.category1) || '';
const category2Name = getNameByCode(cmnCode2s[item.category1], item.category2) || '';
const category3Name = getNameByCode(cmnCode3s[item.category2], item.category3) || '';
initialCateOfList[item.productId] = [category1Name, category2Name, category3Name];
}
}
setCateOfList(initialCateOfList);
}
};
fetchData();
}, [productListData, cmnCode1]);-
useEffect훅: 컴포넌트가 렌더링될 때마다 실행되는useEffect훅을 사용함. 이 훅 안에서fetchData함수가 호출 -
fetchData함수: 제품 목록 및 1단계 카테고리 코드(cmnCode1)가 존재하는 경우에만 데이터를 가져오는 로직이 포함
굳이 함수로 뺀 이유는fetch를 사용하기에 비동기적으로 처리(async)하기 위해 따로 뺌 -
제품 목록 순회:
for...of루프를 사용해 제품 목록을 순회하면서 각 제품에 대한 카테고리 정보를 가져옴 -
2단계 카테고리 코드 가져오기: 해당 2단계 카테고리 코드가 아직 캐시(저장)돼 있지 않은 경우에만 해당 코드를 가져와서
cmnCode2s객체에 1을 Key로, 불러온 값을 Value로 저장 -
3단계 카테고리 코드 가져오기: 해당 3단계 카테고리 코드가 아직 캐시(저장)돼 있지 않은 경우에만 해당 코드를 가져와서
cmnCode3s객체에 2을 Key로, Value로 불러온 값을 저장 -
각 카테고리 이름 가져오기:
getNameByCode함수를 사용해 각 카테고리의 이름을 가져옴
getNameByCode함수는 API 응답 객체에서 카테고리 코드로name을 찾는 유틸 함수다 -
초기 카테고리 정보 설정:
initialCateOfList객체에 각 상품에 대한 1, 2, 3 카테고리 이름을 저장 -
setCateOfList: 최종적으로productId를 Key로, Value로initialCateOfList를setCateOfList함수를 사용해 상태를 업데이트
이 코드의 핵심은 "한 번 가져온 데이터는 다시 가져오지 않는다"는 것입니다.
예를 들어, '일반의약품' 카테고리 정보를 한 번 가져왔다면, 다른 상품에서 같은 정보가 필요할 때는 저장된 데이터를 재사용합니다.
화면 리렌더링
데이터를 가져왔으니 이제 화면에 표시하면 끝입니다!!
return (
// UI 코드...
cateOfList[product?.productId]?.map((cate, idx) => <p key={idx}>{cate}</p>);
// ...
}이제 리액트 생명주기에 맞게 cateOfList 상태가 변한다면 자연스레 리렌더링 될 것이다.
최적화 결과
네트워크 요청 수가 극적으로 감소했습니다!
- 변경 전: 50개 상품 × 3개 카테고리 = 150번의 API 요청
- 변경 후: 5~15번의 API 요청으로 감소
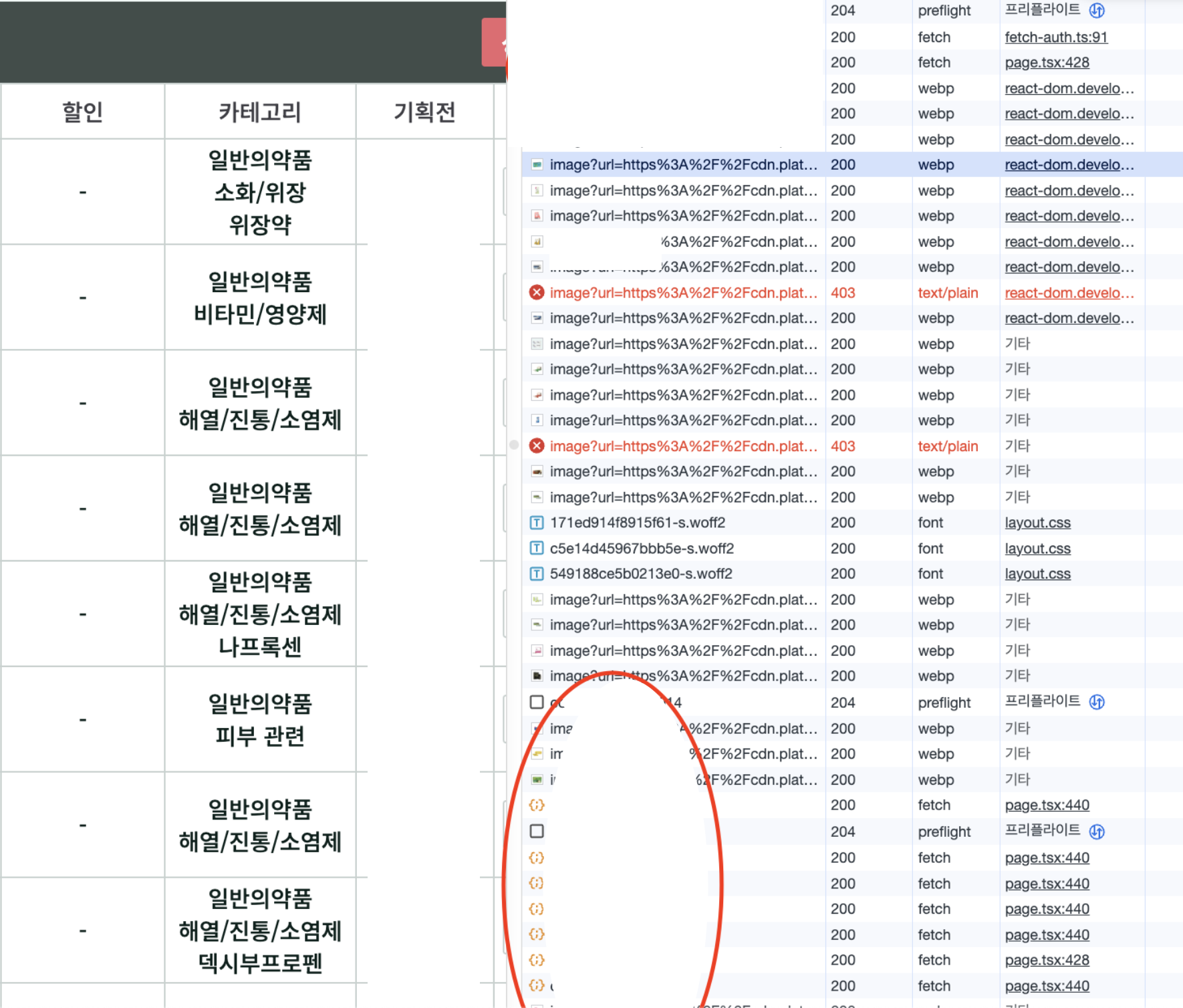
50건 씩 보기로 데이터를 불러왔습니다.
동그라미 친 부분이 카테고리 API 호출 부분입니다. 이러한 최적화를 통해 서버 부하가 크게 감소했습니다.
또한, 리스트 로딩 시간이 기존 1~2초에서 0.2초로 줄어들었습니다.
마무리
이번 챌린지에서 간단하면서도 효과적인 해결책으로 useState를 활용한 메모이제이션을 구현했습니다. 하지만 모든 솔루션이 그렇듯, 이 접근 방식에도 몇 가지 한계가 존재합니다.
현재 구현의 한계점
-
데이터의 휘발성
- 브라우저를 새로고침하거나 닫으면 캐시된 데이터가 모두 사라짐
- 사용자가 다시 접속할 때 처음부터 다시 데이터를 불러와야 함
-
서버 부하
- 여전히 초기 로딩 시에는 여러 번의 API 호출이 필요
- 다른 일반적인 리스트 API들에 비해 상대적으로 높은 서버 비용 발생
가능한 개선 방안
더 나은 성능을 위해 고려해볼 수 있는 방안들
-
전용 DB 구축
- 카테고리 전용 DB를 구축해 서버 부하 분산
- 효율적인 쿼리 처리로 서버 비용 절감
-
로컬스토리지 활용
- 브라우저의 로컬스토리지에 데이터 저장
- 서버와의 동기화 로직 구현으로 데이터 일관성 유지
소감
이번 경험은 힘들었지만, 실제 업무에서 알고리즘의 중요성을 깨닫게 해준 좋은 계기였습니다,, 보통 개발할 때는 단순한 반복문이나 조건문 정도만 사용하곤 했는데, 이번에는 마치 코딩 테스트에서나 볼 법한 메모이제이션 알고리즘을 실제 문제 해결에 적용해볼 수 있었습니다.
이를 통해 알고리즘 학습을 '왜'하는지에 대해 조금을 알 수 있었습니다. 알고리즘은 단순히 면접을 위한 것이 아니라, 실제 개발 현장에서 마주치는 문제들을 효율적으로 해결하는 데 큰 도움이 된다는 것을 직접 경험했습니다. 앞으로도 알고리즘 공부를 게을리하지 말아야겠다는 좋은 동기부여가 될 수 있을 것 같습니다 ㅎㅎ


저도 오늘 알고리즘에 대해 필요성을 느꼈는데..ㅠㅠ
데이터를 어떻게 관리하느냐가 가 정말 중요한 것 같아요 그런 의미에서 usememo도 큰 역할을 하는 것 같구요! 잘 읽고 갑니당