
4부 컴포넌트 원칙
SOLID 원칙이 벽과 방에 벽돌을 배치하는 방법을 알려준다면 컴포넌트 원칙은 빌딩에 방을 배치하는 방법을 설명해준다.
12장 컴포넌트
- 잘 설계된 컴포넌트라면 반드시 독립적으로 배포 가능한, 따라서 독립적으로 개발 가능한 능력을 갖춰야 한다.
컴포넌트의 간략한 역사
- 이전 시대에는 장치가 느리고 메모리는 너무 비싸서 소스코드 전체를 메모리에 상주시킬 수 없었다.
- 컴파일 시간을 단축시키기 위해 함수 라이브러리의 소스 코드를 애플리케이션 코드로부터 분리했다.
- 이때는 메모리위치도 고려해야 했었어서 주소 세그먼트로 분리했지만 프로그램이 사용하는 메모리가 늘어날수록 단편화는 계속 될 수밖에 없었다.
재배치성
해결책은 재배치가 가능한 바이너리(relocatable binary)였다. 단순히 하나씩 차례로 메모리로 로드하면서 재배치하는 작업을 처리했다.
링커
C나 또다른 고수준 언어를 사용하기 시작했고 프로그램도 이전에 비해 훨씬 커졌다. 컴파일하고 링크하는데 시간이 점점 늘어나게 됐었어서 좌절했지만 컴퓨터 메모리는 말도 안될정도로 저렴해지고 클록 속도도 증가해서 링크 시간이 줄어드는 속도가 더 빨라지기 시작했다.
결론
런타임에 플러그인 형태로 결합할 수 있는 동적 링크 파일이 이 책에서 말하는 소프트웨어 컴포넌트에 해당한다.
13장 컴포넌트 응집도
컴포넌트 응집도와 관련된 세 가지 원칙
REP: 재사용/릴리스 등가 원칙(Reuse/Release Equivalence Principle)
재사용 단위는 릴리스 단위와 같다.
- 메이븐(Maven), 라이닝언(Leiningen) RVM 같은 모듈 관리 도구가 우후죽순으로 등장한 시기고 이 기간에 재사용 가능한 컴포넌트나 컴포넌트 라이브러리가 엄청나게 많이 만들어졌기 때문이다. 우리는 이제 소프트웨어 재사용의 시대에 살고 있다.
- 릴리즈 번호가 없다면 재사용 컴포넌트 들이 서로 호환되는지 보증할 방법이 전혀 없다. 하지만 이 단순한 이유때만은 아니고 새로운 버전이 언제 출시되고 무엇이 변했는지를 소프트웨어 개발자들이 알아야 하기 때문이다.
- 이 원칙을 소프트웨어 설계와 아키텍처 관점에서 보면 단일 컴포넌트는 응집성 높은 클래스와 모듈들로 구성되어야 함을 뜻한다. 컴포넌트를 구성하는 모든 모듈은 서로 공유하는 중요한 테마나 목적이 있어야 한다.
- 하나의 컴포넌트로 묶인 클래스와 모듈은 반드시 함께 릴리스 할 수 있어야 한다.
- 하지만 이 조언은 약하다. 이 조언만으로 클래스와 모듈을 단일 컴포넌트로 묶는 방법을 제대로 설명하기 힘들기에 이 조언이 약하지만 이 원칙 자체는 중요하다.
CCP: 공통 폐쇄 원칙(Common Closure Principle)
동일한 이유로 동일한 시점에 변경되는 클래스를 같은 컴포넌트로 묶어라. 서로 다른 시점에 다른 이유로 변경되는 클래스는 다른 컴포넌트로 분리하라
- 이 원칙은 단일 책임 원칙(SRP) 컴포넌트 관점에서 다시 쓴것이다.
- 대다수의 애플리케이션에서 유지보수성(maintainability)은 재사용성보다 훨씬 중요하다. 애플리케이션에서 코드가 반드시 변경되어야 한다면 이러한 변경이 여러 컴포넌트 도처에 분산되어 발생하기 보다는 차라리 변경 모두가 단일 컴포넌트에서 발생하는 편이 낫다. 만약 변경을 단일 컴포넌트로 제할 할 수 있다면, 해당 컴포넌트만 재배포하면 된다.
- CCP는 같은 이유로 변경될 가능성이 잇는 클래스는 모두 한 곳으로 묶을 것을 권한다. 이를 통해 소프트웨어를 릴리스, 재검증, 배포하는 일과 관련된 작업량을 최소화할 수 있다.
- 이 원칙은 개방 폐쇄 원칙(OCP)와도 밀접하게 관련되어 있다. 실제로 이 둘의 C(closure)는 그 뜻이 같다.
SRP와 유사성
| CCP | SRP |
|---|---|
| 컴포넌트 수준의 SRP | |
| 서로 다른 이유로 변경되는 클래스를 서로 다른 컴포넌트로 분리 | 서로 다른 이유로 변경되는 메서드를 서로 다른 클래스로 분리 |
두 원칙은 모두 다음과 같은 교훈으로 요약할 수 있다.
- 동일한 시점에 동일한 이유로 변경되는 것들을 한데 묶어라. 서로 다른 시점에 다른 이유로 변경되는 것들은 서로 분리하라
CRP: 공통 재사용 원칙(Common Reuse Principle)
컴포넌트 사용자들을 필요하지 않는 것에 의존하게 강요하지 말라.
- 공통 재사용 원칙(CRP)도 클래스와 모듈을 어느 컴포넌트에 위치시킬지 결정할 때 도움되는 원칙이다. 같이 재사용되는 경향이 있는 클래스와 모듈들은 같은 컴포넌트에 포함해야 한다고 말한다.
- 개별 클래스가 단독으로 재사용되는 경우는 거의 없다. 대체로 재사용 가능한 클래스는 재사용 모듈의 일부로써 해당 모듈의 다른 클래스와 상호작용하는 경우가 많다. CRP에서는 이런 클래스들이 동일한 컴포넌트에 포함되어야 한다고 말한다.
- 이게 전부가 아니라 CRP는 동일한 컴포넌트로 묶어서는 안되는 클래스가 무엇인지도 말해주는데 어떤 컴포넌트가 다른 컴포넌트를 사용하면, 두 컴포넌트 사이에는 의존성이 생겨난다. 이 의존성으로 인해 사용되는 컴포넌트가 변경될 때마다 사용하는 컴포넌트도 변경해야 할 가능성이 높다.
- 한 컴포넌트에 속한 클래스들은 더 작게 그룹지을 수 없다. 즉, 그 중 일부 클래스에만 의존하고 다른 클래스와는 독립적일 수 없음을 확실하게 인지해야 한다.
- CRP는 강하게 결합되지 않은 클래스들을 동일한 컴포넌트에 위치시켜서는 안된다고 말한다.
ISP와의 관계
CRP는 인터페이스 분리 원칙(ISP)의 포괄적인 버전이다.
| CRP | ISP |
|---|---|
| 사용하지 않는 클래스를 가진 가진 컴포넌트에 의존하지 말아야 한다 | 사용하지 않는 메서드가 있는 클래스에 의존하지 말아야 한다 |
필요하지 않은 것에 의존하지 말라
컴포넌트 응집도에 대한 균형 다이어그램
- 응집도에 관한 세 원칙이 서로 상충된다
- REP와 CCP는 포함(inclusive)원칙이다: 컴포넌트를 더욱 크게 만든다
- CRP는 배제(exclusive)원칙이다: 컴포넌트를 더욱 작게 만든다.
- 뛰어난 아키텍트라면 이 원칙들이 균형을 이루는 방법을 찾아야 한다.
균형(tension)다이어그램으로, 응집도에 관한 세 원칙이 어떻게 상호작용하는지 보여준다. 다이어그램의 각 변은 반대쪽 꼭지점에 있는 원칙을 포기했을 때 감수해야 할 비용을 나타낸다.
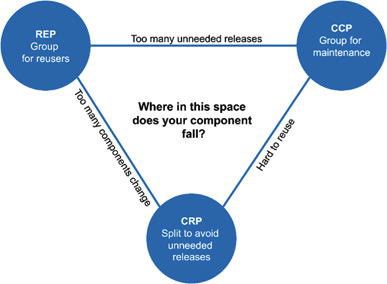
- REP와 CRP에만 중점을 두면 사소한 변경이 생겼을 때 너무 많은 컴포넌트에 영향을 미친다.
- CCP와 REP에만 과도하게 집중하면 불필요한 릴리스가 너무 빈번해진다.
- 시간이 흐르면서 개발팀이 주의를 기울이는 부분 역시 변한다는 사실도 이해하고 있어야 한다
- 예를들어 프로젝트 초기에는 CCP가 REP보다 훨씬 더 중요한데 개발가능성이 재사용성보다 더욱 중요하기 때문이다.
- 프로젝트의 컴포넌트 구조는 시간과 성숙도에 따라 변한다. 다시 말해 프로젝트가 실제로 수행하는 일 자체보다는 프로젝트가 발전되고 사용되는 방법과 관련이 더 깊다.
결론
과거에는 응집도를 모듈은 단 하나의 기능만 수행해야 한다는 속성 정도로 단순하게 이해한 적도 있다. 하지만 컴포넌트 응집도에 관한 세가지 원칙은 응집도가 가질 수 잇는 훨씬 복잡한 다향성을 설명해준다. 이들 사이에서 시간의 흐름에 따라 애플리케이션의 요구에 맞게 균형을 잡는 일은 중요하다.
14장 컴포넌트 결합
다룰 세가지 원칙은 컴포넌트 사이의 관계를 설명한다. 마찬가지로 개발 가능성과 논리적 설계 사이의 균형을 다룬다.
ADP: 의존성 비순환 원칙
컴포넌트 의존성 그래프에 순환(cycle)이 있어서는 안된다.
숙취증후군: 많은 개발자가 동일한 소스 파일을 수정하는 환경에서 발생한다. 프로젝트와 개발팀 규모가 커지면 더욱 심해진다.
해결책1: 주 단위 빌드(Weekly Build)
- 중간 규모의 프로젝트에서 흔하게 사용된다.
- 먼저 모든 개발자는 일주일의 첫 4일동안은 서로를 신경쓰지 않고 금요일이 되면 변경된 코드를 모두 통합하여 시스템을 빌드한다.
- 프로젝트가 커지면 프로젝트 통합은 금요일 하루만에 끝마치는게 불가능해진다. 이는 빌드 일정이 계속 늘어나고 팀은 빠른 피드백이 주는 장점을 잃는다
해결책2: 순환 의존성 제거하기
- 개발 환경을 릴리스 가능한 컴포넌트 단위로 분리. 이를 통해 개별 개발자 또는 단일 개발팀이 책임질 수 있는 작업 단위가 된다.
- 개발자가 해당 컴포넌트 동작하도록 만들고 해당 컴포넌트를 릴리스하여 다른 개발자가 사용할 수 있도록 만드는 방법. 따라서 어떤 팀도 다른 팀에 좌우되지 않는다.
- 이 같은 작업 절차는 단순하며 널리 사용되지만 성공하려면 컴포넌트 사이의 의존성 구조를 반드시 관리해야 한다.
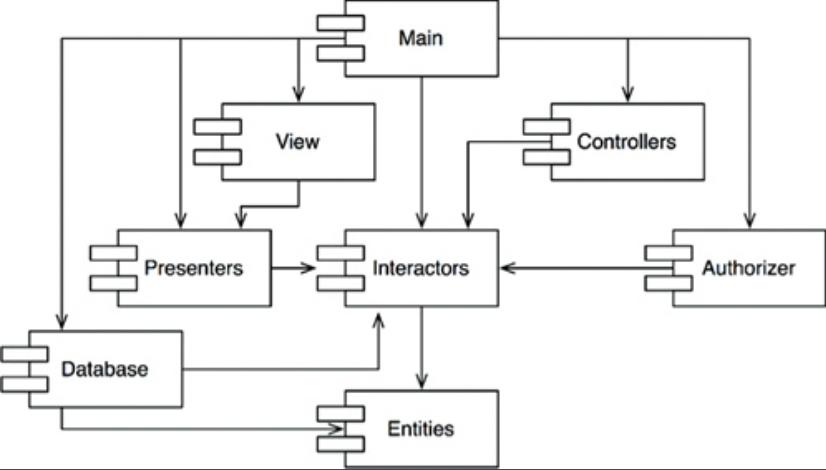
- 이 구조가 방향 그래프(directed graph)이고, 어느 컴포넌트에 시작하더라도 의존성 관계를 따라가면서 최초의 컴포넌트로 되돌아 갈 수 없다는 사실 즉 비순환 방향 그래프(Directed Acyclic Graph, DAG)이다.
- 예를 들어 Presenters가 바뀌면 View와 Main이 영향을 받게 된다. Main이 변경되면 전혀 개의치 않는다.
- Presenters 컴포넌트를 테스트하고자 한다면 단순히 현재 사용중인 버전의 Interactors와 Entities를 이용해서 Presenters 자체 버전을 빌드하면 그만이다. 나머지 컴포넌트와는 전혀 관련이 없다.
순환이 컴포넌트 의존성 그래프에 미치는 영향
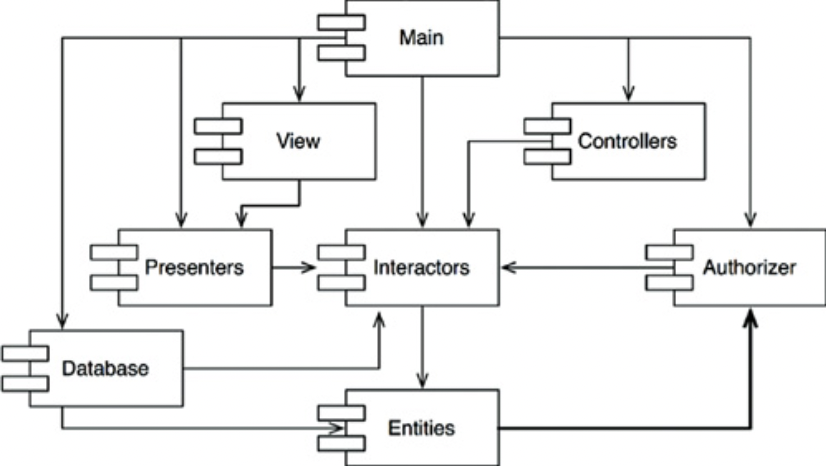
- Entities에 포함된 클래스 하나가 Authorizer에 포함된 클래스 하나를 사용하도록 변경한다면
- Interactors, Authorizer, Entities 모두 순환 의존성이 발생하며 사실상 하나의 거대한 컴포넌트가 되어 버린다.
- 또한 Entities 컴포넌트를 테스트 할 때 Authorizer와 Interactors까지도 반드시 빌드하고 통합해야 한다.
순환 끊기
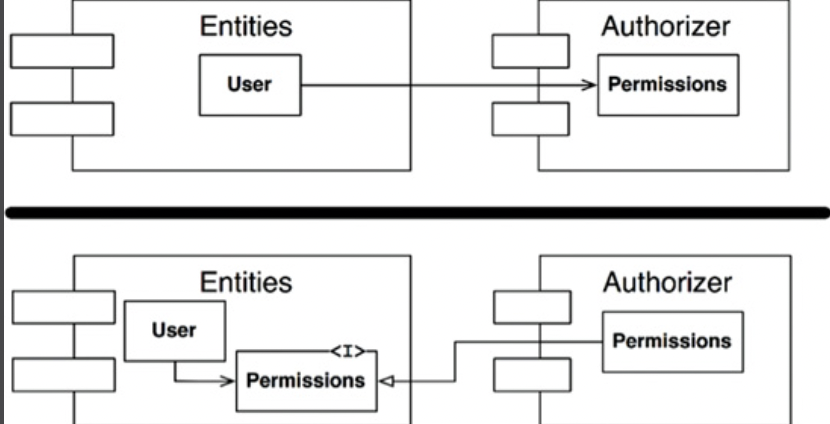
- 의존성 역전 원칙(DIP)을 적용한다.
- User가 필요로하는 메서드를 제공하는 인터페이스를 생성하고 Entities에 위치시키고 Authorizer에서는 이 인터페이스를 상속받는다.
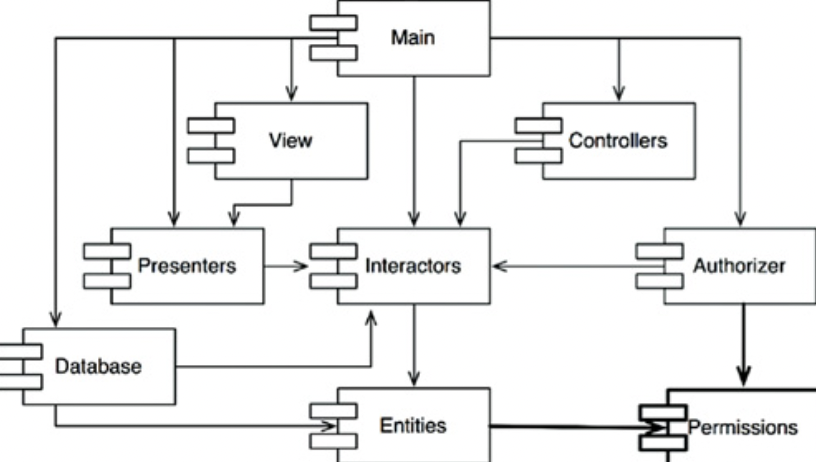
- Entities와 Authorizer가 모두 의존하는 새로운 컴포넌트를 만든다. 그리고 두 컴포넌트가 모두 의존하는 클래스들을 새로운 컴포넌트로 이동시킨다
흐트러짐(Jitters)
- 두번째 해결책에서 시사하는 바는 요구사항이 변경되면 컴포넌트 구조도 변경될 수 있다는 사실이다. 실제로 애플리케이션이 성장함에 따라 컴포넌트 의존성 구조는 서서히 흐트러지며 또 성장한다. 따라서 의존성 구조에 순환이 발생하는지를 항상 관찰해야 한다
하향식(top-down) 설계
즉 컴포넌트 구조는 하향식으로 설계될 수 없다. 컴포넌트는 시스템에서 가장 먼저 설계할 수 있는 대상이 아니며 오히려 시스템이 성장하고 변경될 때 함께 진화한다.
- 컴포넌트 의존성 다이어그램은 애플리케이션의 기능을 기술하는 일과는 거의 관련이 없다. 빌드 가능성(Buildability)과 유지보수성(maintainability)를 보여주는 지도와 같다. 이러한 이유 때문에 컴포넌트 구조는 프로젝트 초기에 설계할 수 없다.
- 아무런 클래스가 설계되지 않은 상태에서 컴포넌트 의존성 구조를 설계한다면
- 공통 폐쇄에 대해 그다지 않이 파악하지 못하고있고
- 재사용 가능한 요소도 알지 못하며
- 컴포넌트를 생성할 때 거의 확실히 순환 의존성이 발생하기 때문에 매우 어렵다.
- 모듈들이 점차 쌓이기 시작하면 의존성 관리에 대한 요구가 점차 늘어나게 된다. 이때 단일 책임원칙(SRP), 공통 폐쇄 원칙(CCP)에 관심을 갖기 시작하고 함께 변경되는 클래스는 같은 위치에 배치가된다.
- 아무런 클래스가 설계되지 않은 상태에서 컴포넌트 의존성 구조를 설계한다면
- 컴포넌트 의존성 그래프는 자주 변경되는 컴포넌트로부터 안정적이며 가치가 높은 컴포넌트를 보호하려는 아키텍트가 만들고 가다듬게 된다.
- 애플리케이션이 성장하면서 재사용 가능한 요소를 만드는 일에 관심을 가지고 공통 재사용 원칙(CRP)이 영향을 미치기 시작하고 순환이 발생하면 ADP가 적용되고 컴포넌트 의존성 그래프는 조금씩 흐트러지고 성장한다.
SDP: 안정된 의존성 원칙
안정성의 방향으로(더 안정된 쪽에) 의존하라.
- 설계는 결코 정적일 수 없다.
- 변경이 쉽지 않은 컴포넌트가 변동이 예상되는 컴포넌트에 의존하게 만들어서는 절대로 안된다. 한번 의존하게 되면 변동성이 큰 컴포넌트도 결국 변경이 어려워진다.
안정성
- 소프트웨어 컴포넌트를 변경하기 어렵게 만드는 확실한 방법 하나는 수 많은 다른 컴포넌트가 해당 컴포넌트에 의존하게 만드는 것이다.
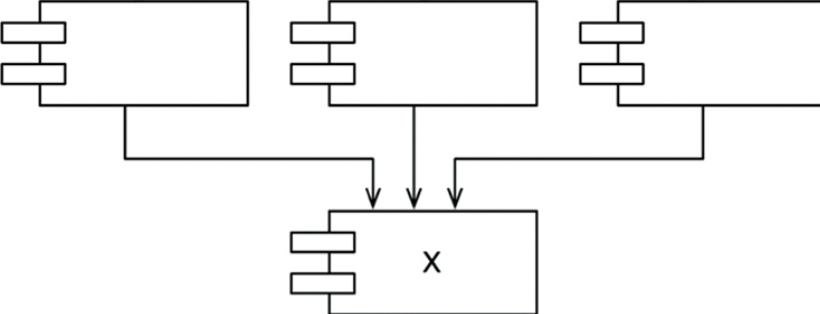
-
세 컴포넌트가 X에 의존하며 사소한 변경이라도 의존하는 모든 컴포넌트를 만족시키면서 변경하려면 상당한 노력이 들기 때문에 안정적이다.
-
X는 세 컴포넌트를 책임진다(responsible)라고 말하며 X는 어디에도 의존하지 않아 독립적이다(independent)
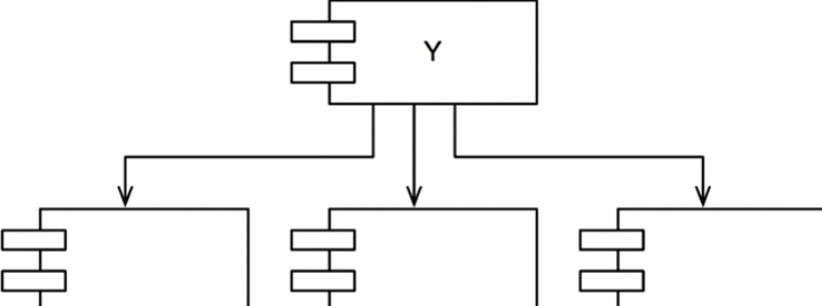
- Y는 책임성이 없다고 말할 수 있다. 세개의 컴포넌트에 의존하므로 변경이 발생하 ㄹ수 있는 외부요인이 세가지이고 의존적이라 말할 수 있다.
안정성 지표
컴포넌트로 들어오고 나가는 의존성 개수를 세어보는 방법이 있을 수 있다.
- Fan-in
- Fan-out
- I(불안정성): I = Fan-out / (Fan-in + Fan-out), I = 0이면 최고로 안정된 컴포넌트라는 뜻이다.
모든 컴포넌트가 안정적이어야 하는 것은 아니다.
모든 컴포넌트가 최고로 안정적인 시스템이라면 변경이 불가능하다. 이는 바람직한 상황이 아니다
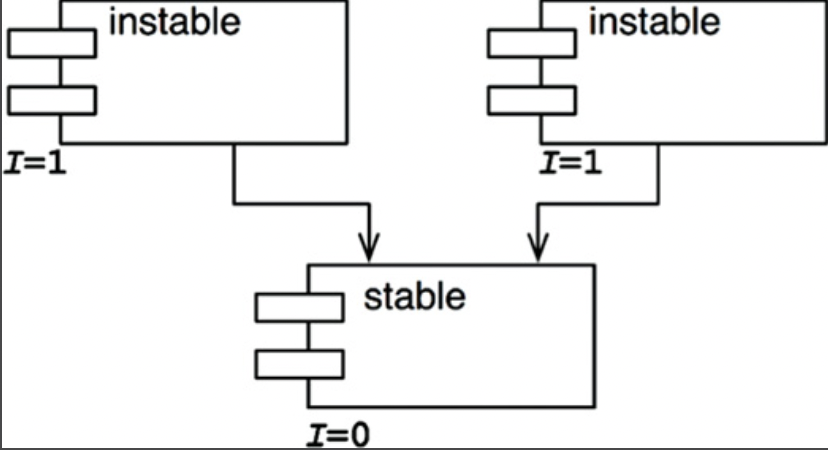
- 참고로 불안정한 컴포넌트를 관례적으로 위쪽에 두는데 위로 향하는 화살표가 잇으면 SDP를 위배하고 ADP도 위반하는 상태가 되기 때문이다.
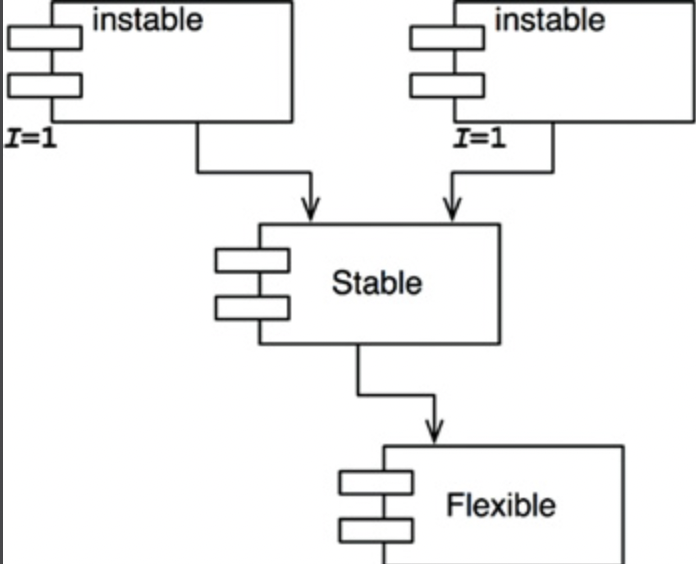
- Flexible은 변경하기 쉽도록 설계한 컴포넌트이기 때문에 불안정한 상태이기를 바라지만 I지표가 Stable보다 더 크기 때문에 위배한다.
- 이를 해결하기 위해서는
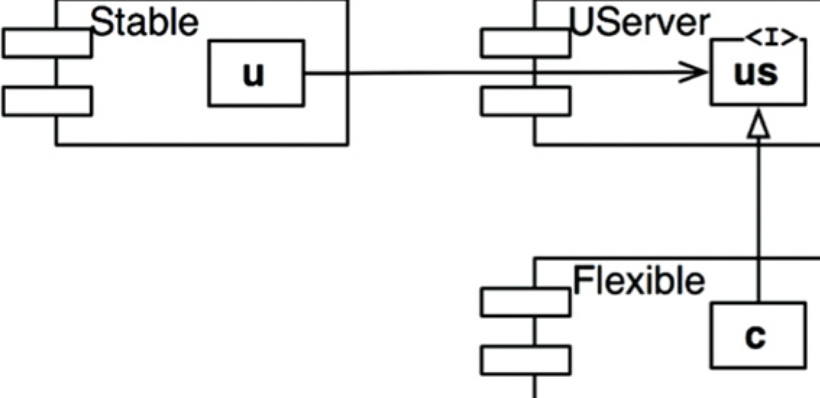
- DIP를 사용하게 되는데 Flexible은 불안정성을 1로 유지할 수 있게 만든다.
SAP: 안정된 추상화 원칙
컴포넌트는 안정된 정도만큼만 추상화 되어야 한다.
고수준 정책을 어디에 위치시켜야 하는가?
- 시스템에서는 자주 변경해서는 절대로 안되는 소프트웨어도 잇다. 따라서 시스템에서 고수준 정책을 캡슐화하는 소프트웨어는 반드시 안정된 컴포넌트(I = 0)에 위치해야 한다.
- 하지만 고수준 정책을 안정된 컴포넌트에 위치시키면 그 정책을 포함하는 소스코드는 수정하기가 어려워진다
- -> 유연성을 잃는다
- 컴포넌트가 최고로 안정된 상태이면서도 (I=0) 동시에 변경에 충분히 대응할 수 있을 정도로 유연하게 만들 수 있을까?
- -> 개방 폐쇄 원칙(OCP)
- -> 추상 클래스
- -> 개방 폐쇄 원칙(OCP)
- 하지만 고수준 정책을 안정된 컴포넌트에 위치시키면 그 정책을 포함하는 소스코드는 수정하기가 어려워진다
안정된 추상화 원칙
- 안정성Stability)과 추상화 정도(abstractness) 사이의 관계를 정의한다.
- 안정된 컴포넌트는 추상 컴포넌트여야 하며, 이를 통해 안정성이 컴포넌트를 확장하는 일을 방해해서는 안된다고 말한다.
- 안정적인 컴포넌트라면 반드시 인터페이스와 추상클래스로 구성되어 쉽게 확장할 수 있어야 하고 이를 통해 확장이 가능해지면 유연성을 얻게 되고 아키텍처를 과도하게 제약하지 않게 된다.
추상화 정도 측정하기
- Nc: 컴포넌트의 클래스 개수
- Na: 컴포넌트의 추상 클래스와 인터페이스의 개수
- A: 추상화 정도. A = Na / Nc
- A가 1이면 컴포넌트는 오로지 추상 클래스만을 포함
주계열
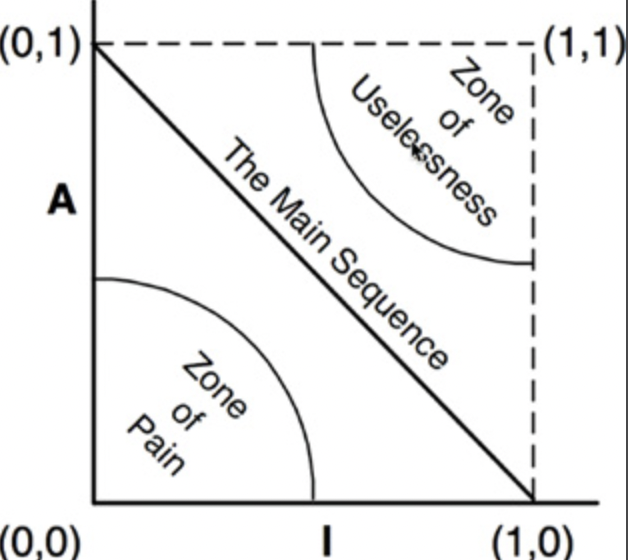
- I는 안정성, A는 추상화 정도
고통의 구역(Zone of Pain)
- 매우 안정적이며 구체적
- 추상적이지 안흐음로 확장할 수 없고 안정적이므로 변경하기도 어렵다.
- 소프트웨어 엔티티, 유틸리티 라이브러리(
String는 고통의 구역에 위치하곤 한다.
쓸모없는 구역(Zume of Uselessness)
- 최고로 추상적이지만 누구도 컴포넌트에 의존하지 않음
- 엔티티가 전혀 사용되지 않으면서 시스템의 기반 코드에 남아있는 모습
배제 구역 벗어나기
- 가능한 두 배제 구역으로부터 가능한 한 멀리 떨어뜨려야 하는데 이 궤적을 주계열(Main Sequence)이라 부른다
주계열과의 거리
- 컴포넌트가 주계열 바로 위에, 또는 가까이 있는 것이 바람직하다면, 이같은 이상적인 상태로부터 컴포넌트가 얼마나 멀리 떨어져 있는지 측정하는 지표를 만들어 볼 수 있다.
- D: 거리. D = |A + I - 1|
- 각 컴포넌트에 대해 먼저 D지표를 계산하고 D값이 0에 가깝지 않은 컴포넌트가 있다면 재검토
- 통계적으로도 분석이 가능하다(평균, 분산, 표준편차
- 각 컴포넌트의 D값을 시간에 따라 그려볼 수 있다. 이를 통해 이 컴포넌트가 주계열에서 이렇게 멀리 벗어난 원인을 알 수 있다.
결론
좋은 의존성도 있지만 좋지 않은 의존성도 있다. 여러 지표가 있지만 이 지표로부터 무언가 유용한 것을 찾는것이 중요하다.
클린 아키텍처 소프트웨어 구조와 설계의 원칙
로버트 C. 마틴 저
