
알고리즘 개요
프림 알고리즘이란?
프림(Prim) 알고리즘은 최소 신장 트리(Minimum Spanning Tree)를 찾는 알고리즘 중 하나입니다.
이 알고리즘은 그리디 알고리즘의 일종으로, 그래프에서 임의의 정점을 선택한 후, 해당 정점과 인접한 정점들 중 최소 가중치를 가진 간선을 선택하면서 트리를 확장해 나가는 방식으로 동작합니다.
최소 신장 트리(Minimum Spanning Tree, MST): 모든 정점을 포함하면서, 사이클을 형성하지 않으면서 그래프 상의 간선들의 가중치 합이 최소인 트리
알고리즘 동작 과정
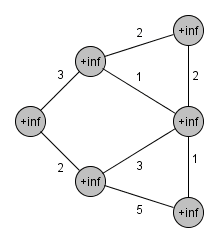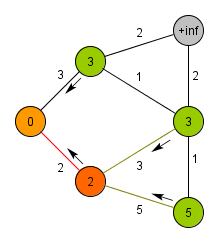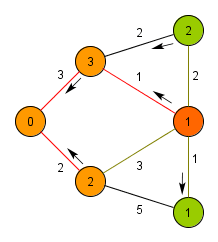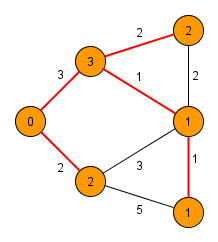
알고리즘 구현 방법
- 그래프에서 임의의 시작 정점을 선택합니다.
- 선택한 정점과 연결된 간선들을 우선순위 큐에 추가합니다. 우선순위 큐는 간선의 가중치를 기준으로 오름차순으로 정렬됩니다.
- 우선순위 큐에서 가장 작은 가중치를 가진 간선을 꺼냅니다.
- 꺼낸 간선의 양 끝점 중 하나가 이미 트리에 포함되어 있는 정점이면, 다른 끝점을 새로운 정점으로 추가합니다. 이때 새로 추가된 정점과 연결된 간선들을 우선순위 큐에 추가합니다.
- 모든 정점이 트리에 포함될 때까지 3~4번 과정을 반복합니다.
우선순위 큐(Priority queue): 들어간 순서에 상관없이 우선순위가 높은 데이터가 먼저 나오는 형태의 자료구조
알고리즘 코드 예시
Python
import heapq # 우선순위 큐 구현을 위한 라이브러리
def prim(graph, start):
visited = set([start])
edges = graph[start]
heapq.heapify(edges)
mst_cost = 0
while edges:
cost, u, v = heapq.heappop(edges)
if v not in visited:
visited.add(v)
mst_cost += cost
for edge in graph[v]:
if edge[2] not in visited:
heapq.heappush(edges, edge)
return mst_cost
graph는 그래프를 나타내는 인접 리스트이고, start는 시작 정점입니다.
visited는 이미 방문한 정점의 집합을 나타내며, edges는 우선순위 큐입니다. 각 간선은 (cost, u, v)의 형태로 저장되어 있습니다. 반환값은 최소 신장 트리의 가중치 합입니다.
알고리즘의 시간 복잡도
일반적으로, 인접 리스트(Adjacency List)를 이용한 그래프에서 프림 알고리즘을 수행하는 경우 시간 복잡도는 O(E log V)입니다.
이는 각 정점마다 인접한 간선들을 우선순위 큐에 추가하고, 간선을 추출하며 해당 간선의 양 끝점이 이미 방문한 정점인지 확인하기 때문입니다. 이때, 우선순위 큐에서 간선을 꺼낼 때 log V의 시간이 걸리므로, 총 시간 복잡도는 O(E log V)입니다.
알고리즘의 한계와 개선 방법
한계
프림 알고리즘은 그래프의 정점과 간선 수에 따라 효율적인 최소 신장 트리(Minimum Spanning Tree, MST)를 찾을 수 있지만, 그래프가 밀집한 경우(즉, 간선의 수가 매우 많은 경우)에는 시간 복잡도가 높아지는 단점이 있습니다.
개선 방법
-
피보나치 힙(Fibonacci Heap) 사용
프림 알고리즘에서 우선순위 큐를 사용하면서 최소값을 추출하기 위해 힙(Heap)을 사용합니다. 일반적으로는 이진 힙(Binary Heap)을 사용하는데, 이는 시간 복잡도가 O(log V)입니다. 하지만, 피보나치 힙을 사용하면 시간 복잡도를 O(1)로 줄일 수 있습니다.피보나치 힙(Fibonacci Heap): 우선순위 큐를 구현하는 데 사용되는 자료구조 중 하나로, 최소값과 그 외 값들을 추출하는 데에 높은 효율성을 가지고 있습니다.
하지만, 피보나치 힙은 구현이 복잡하고, 상수항이 크기 때문에 작은 크기의 우선순위 큐에서는 이진 힙보다 성능이 떨어질 수 있습니다. 대신, 큰 크기의 우선순위 큐에서는 높은 성능을 보이기 때문에, 대용량 데이터를 처리하는 데에 매우 유용합니다. -
국소 최소 신장 트리(Local Minimum Spanning Tree) 구하기
그래프를 여러 개의 작은 부분 그래프(Subgraph)로 나누고, 각 부분 그래프에서 국소 최소 신장 트리를 구한 뒤, 이들을 합쳐 전체 최소 신장 트리를 구하는 방법입니다.
