
1. 설치 및 사용자 계정 만들기
설치
- Oracle 공식 웹사이트에서 다운로드 후 설치 합니다.
11g 다운로드 링크
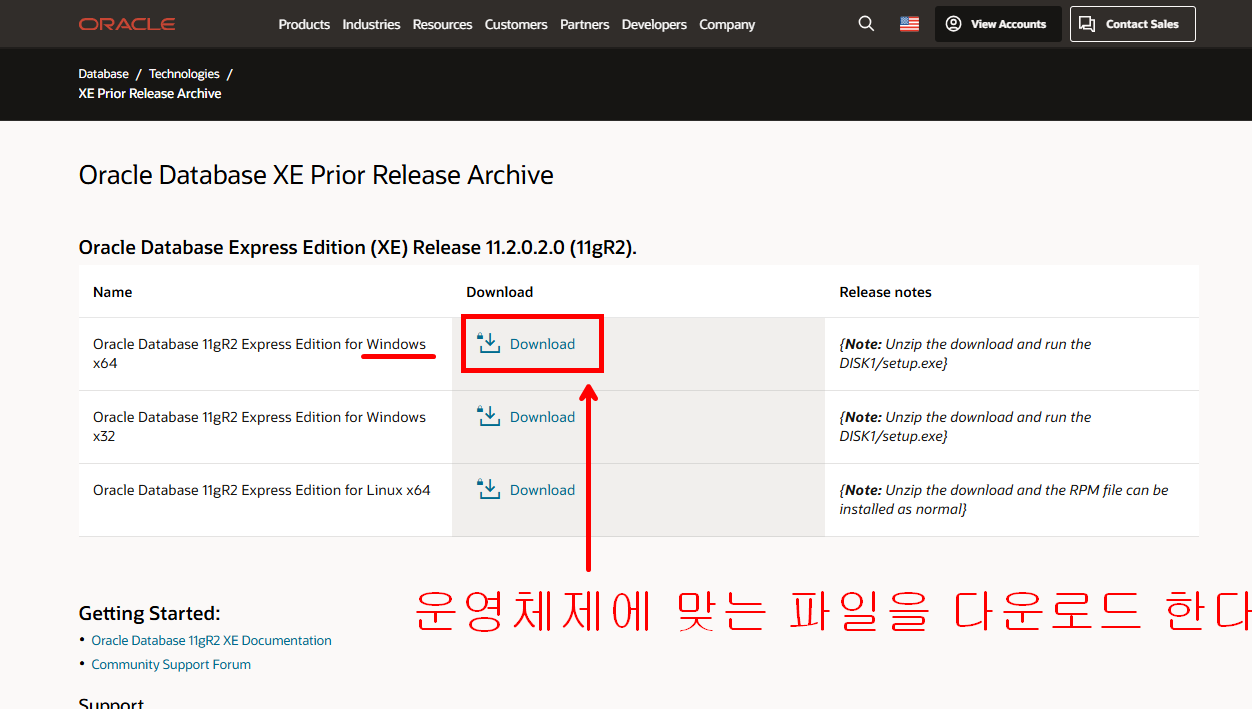
- 설치 시 암호는 system 계정의 암호로 설정됩니다.
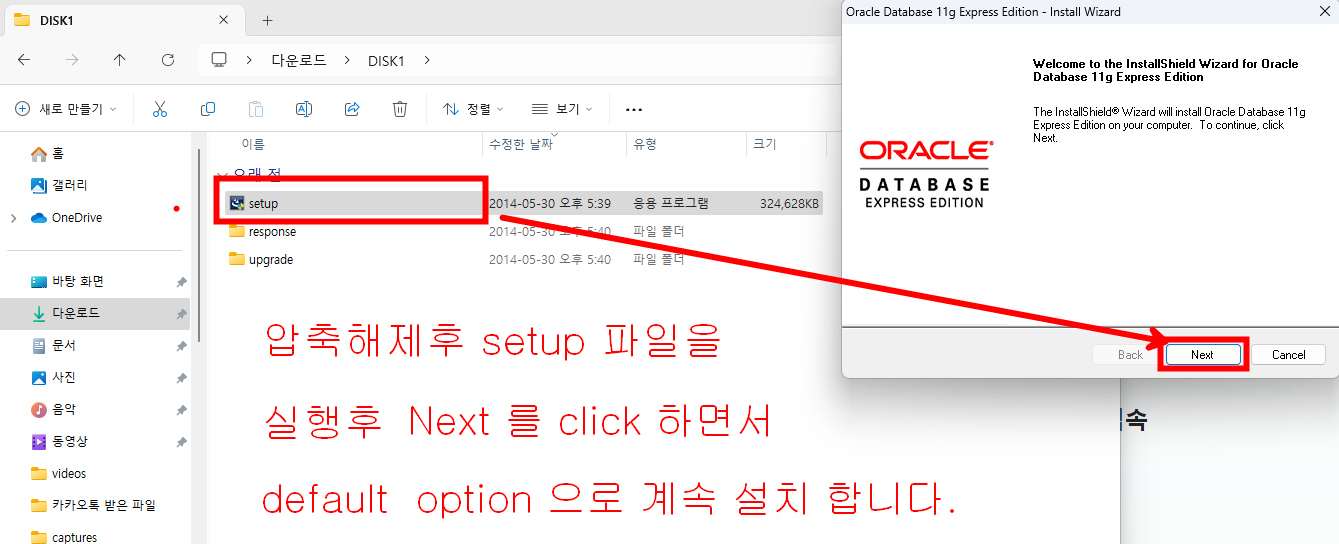
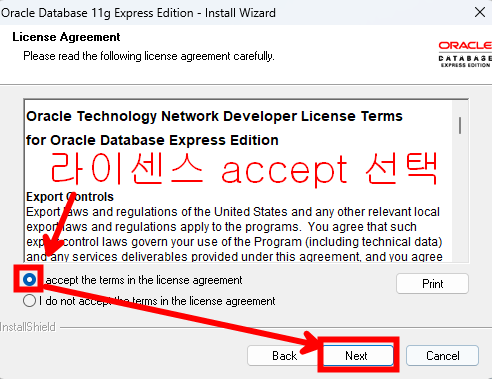
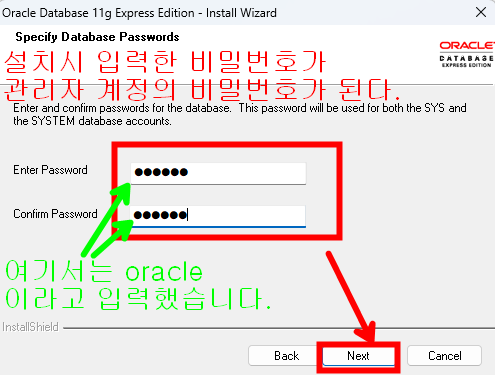
연습용 계정 만들기
1. 관리자 계정으로 접속
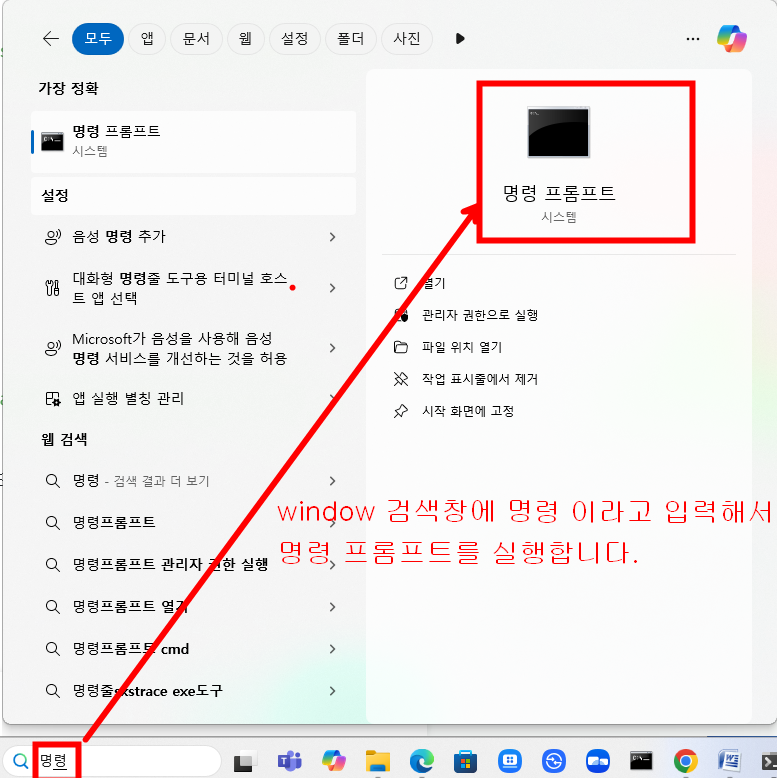
명령 프롬프트에서 sqlplus 실행
sqlplus system/oracle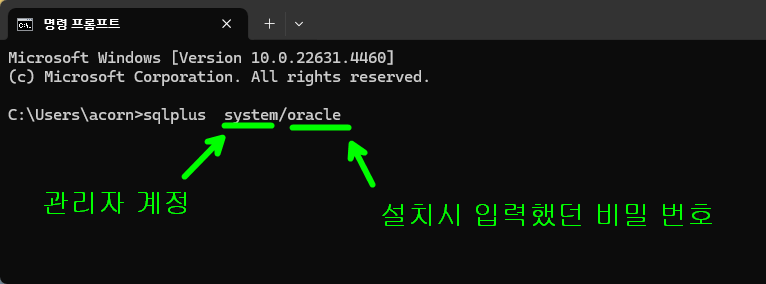
- 계정 생성및 관리를 하려면 관리자 계정으로 접속해야 합니다.
2. 사용자 생성
형식
CREATE USER 계정 IDENTIFIED BY 비밀번호;예제
CREATE USER acorn IDENTIFIED BY acorn1234;
- 계정명 : acorn, 비밀번호 acorn1234 인 계정이 만들어집니다.
- 계정명은 대소문자 상관 없지만 비밀번호는 대소문자를 가립니다.
3. 권한 부여
형식
GRANT RESOURCE, CONNECT TO 계정;예제
GRANT RESOURCE, CONNECT TO acorn;
- RESOURCE 는 객체 생성 권한 이고 CONNECT 는 접속 권한입니다.
- 여기서 객체란 TABLE, VIEW, SEQUENCE, INDEX, TRIGGER 등 입니다.
2. 테이블 생성 및 활용
새 계정으로 접속
sqlplus acorn/oracle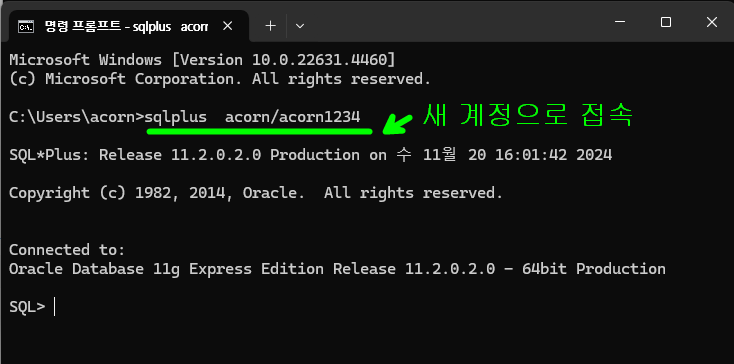
- 명령 프롬프트를 새로 열어서 새 계정으로 접속되는 것을 확인할 수 있다.
테이블 생성
형식
CREATE TABLE 테이블명 (
칼럼명 데이터타입 제약조건, ...
);예제
CREATE TABLE member (
num NUMBER PRIMARY KEY,
name VARCHAR2(10),
addr VARCHAR2(20)
);
member: 테이블명num, name, addr은 칼럼명NUMBER: 숫자VARCHAR2(10): 최대 10글자의 가변 길이 문자열PRIMARY KEY: 반드시 입력해야하고 중복을 허용하지 않음NOT NULL: 반드시 값을 입력UNIQUE: 중복 허용하지 않음
INSERT 문
INSERT문은 테이블에 새 데이터를 삽입할 때 사용됩니다.
기본 문법
INSERT INTO 테이블명 (칼럼명1, 칼럼명2, ...)
VALUES (값1, 값2, ...);예제
INSERT INTO member (num, name, addr)
VALUES (1, '김구라', '노량진');
-- num 과 addr 만 넣어보기
INSERT INTO member (num, name)
VALUES (2, '해골');
INSERT INTO member
VALUES (3, '원숭이', '상도동');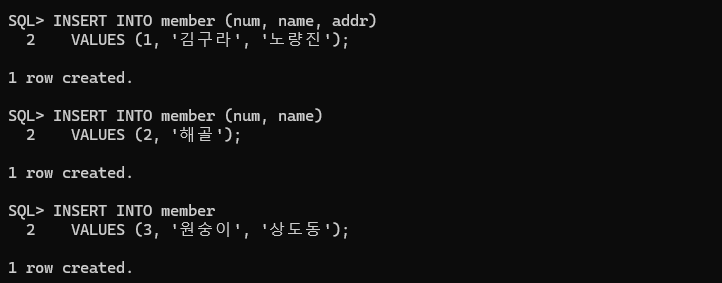
- 문자열은 single quotation 으로 감싸야 합니다.
- 특정 칼럼에만 값을 넣을수도 있습니다.
- 모든 칼럼에 데이터를 순서대로 넣을때는 칼럼명 생략 가능 합니다.
- -- 는 주석입니다.
UPDATE 문
UPDATE문은 기존 데이터를 수정할 때 사용됩니다.
기본 문법
UPDATE 테이블명
SET 칼럼명1 = 값1, 칼럼명2 = 값2, ...
WHERE 조건;예제
UPDATE member
SET name = '이정호', addr = '독산동'
WHERE num = 1;
- 1번 회원의 이름을 이정호 주소는 독산동 으로 수정합니다.
DELETE 문
DELETE문은 테이블에서 데이터를 삭제할 때 사용됩니다.
기본 문법
DELETE FROM 테이블명
WHERE 조건;예제
DELETE FROM member
WHERE num=3;
- 3번 회원의 정보를 삭제 합니다.
COMMIT과 ROLLBACK
Oracle은 트랜잭션 기반 시스템으로,
INSERT,UPDATE,DELETE는COMMIT되기 전까지 실제로 저장되지 않습니다.
COMMIT
- 데이터베이스에 변경 내용을 영구적으로 저장.
COMMIT;
ROLLBACK
- COMMIT되지 않은 변경 내용을 취소.
ROLLBACK;
간단한 데이터 조회
SELECT문은 데이터베이스에서 데이터를 조회할 때 사용하는 SQL 명령어입니다.
기본 문법
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 조건
ORDER BY 정렬칼럼 [ASC|DESC];sample 데이터 준비
DELETE FROM member;
INSERT INTO member (num, name, addr)
VALUES(1, '김구라', '노량진');
INSERT INTO member (num, name, addr)
VALUES(2, '해골', '행신동');
INSERT INTO member (num, name, addr)
VALUES(3, '원숭이', '상도동');
COMMIT;예제1
SELECT num, name, addr
FROM member
ORDER BY num DESC; 
- 번호 대해서 내림차순 정렬된 것을 알수 있다.
예제2
SELECT num, name
FROM member
ORDER BY num DESC;
- 번호와 이름만 SELECT 된것을 알수가 있다.
예제3
SELECT num, name
FROM member
WHERE num >= 2
ORDER BY num DESC;
- 번호가 2이상 인 회원 정보만 SELECT 된것을 알수가 있다.
예제4
SELECT num, name, addr
FROM member
WHERE num = 2;
- 2번 회원의 정보만 SELECT 된것을 알수가 있다.
3. Sequence 사용하기
PRIMARY KEY 로 설정된 칼럼에 자동 증가되는 숫자값을 자동으로 부여하기 위해서 사용됩니다.
1. 시퀀스 생성
시퀀스를 생성할 때 사용되는 기본 문법은 다음과 같습니다.
CREATE SEQUENCE sequence_name
START WITH start_value
INCREMENT BY increment_value
MAXVALUE max_value
NOCYCLE; -- CYCLE 옵션을 사용하면 최대값 이후 처음으로 돌아감예제
CREATE SEQUENCE my_sequence
START WITH 1
INCREMENT BY 1
MAXVALUE 1000
NOCYCLE;2. 시퀀스 값 가져오기
시퀀스에서 다음 값을 가져오려면 NEXTVAL을 사용합니다. 현재 값을 확인하려면 CURRVAL을 사용합니다.
예제
-- 다음 값 가져오기
SELECT my_sequence.NEXTVAL FROM DUAL;
-- 현재 값 가져오기
SELECT my_sequence.CURRVAL FROM DUAL;3. 시퀀스 데이터 사용
시퀀스를 활용하여 테이블에 데이터를 삽입할 수 있습니다.
예제
INSERT INTO my_table (id, name)
VALUES (my_sequence.NEXTVAL, 'John Doe');4. 시퀀스 수정
시퀀스를 수정하려면 ALTER SEQUENCE 문을 사용합니다.
예제
ALTER SEQUENCE my_sequence
INCREMENT BY 10
MAXVALUE 5000;5. 시퀀스 삭제
시퀀스를 삭제하려면 DROP SEQUENCE 문을 사용합니다.
예제
DROP SEQUENCE my_sequence;4. SQL*Plus 명령어 사용법
CLEAR SCREEN
- SQL*Plus 화면을 깨끗하게 지웁니다.
사용법
CLEAR SCREEN
SET LINESIZE
- 한 줄에 출력되는 문자 수(라인 길이)를 설정합니다. 긴 결과가 잘리지 않고 한 줄로 출력되도록 조정할 때 유용합니다.
사용법
SET LINESIZE n- n: 한 줄에 출력되는 최대 문자 수(기본값은 80).
예제
SET LINESIZE 120
SET PAGESIZE
- 한 페이지에 출력되는 줄(row) 수를 설정합니다. 출력 데이터가 페이지 구분 없이 한 번에 표시되도록 하려면 큰 값을 설정하면 됩니다.
사용법
SET PAGESIZE n- n: 한 페이지에 출력되는 줄(row) 수.
예제
SET PAGESIZE 50
SPOOL
- SQL*Plus의 결과를 파일로 저장합니다. 결과를 파일에 저장하거나 로그를 기록할 때 사용됩니다.
사용법
SPOOL filename- filename: 저장할 파일 이름(확장자 포함).
예제
- 스풀 시작:
SPOOL output.txt- 여러개의 SQL 실행:
SELECT * FROM employees ...
INSERT INTO employees ...
UPDATE employees ...- 스풀 종료:
SPOOL OFF- 파일이 생성된 위치는 SQL*Plus 실행 경로입니다.
COLUMN
- 특정 컬럼의 출력 형식을 지정합니다. 출력 시 컬럼의 길이를 조정하거나 별칭을 설정할 때 사용됩니다.
사용법
COLUMN column_name FORMAT aN- column_name: 포맷을 설정할 컬럼 이름.
- aN: 출력 문자 수를 지정. 예:
a10은 10자리 출력.
예제
COLUMN first_name FORMAT a10
COLUMN last_name FORMAT a15
SELECT first_name, last_name FROM employees;
SHOW ALL
- 현재 설정된 SQL*Plus 환경 변수를 확인합니다.
사용법
SHOW ALL요약
아래는 여러 명령어를 종합적으로 설정한 예제입니다.
CLEAR SCREEN
SET LINESIZE 120
SET PAGESIZE 50
COLUMN first_name FORMAT a10
COLUMN last_name FORMAT a20
SPOOL employee_report.txt
SELECT first_name, last_name, salary FROM employees;
.
.
SPOOL OFF이 명령어들을 조합하여 SQL*Plus 환경을 최적화하고 효율적으로 사용할 수 있습니다.
5. scott 계정 준비
1. scott 계정 생성 및 접속
system 계정으로 접속
sqlplus system/oraclescott.sql 파일 일괄실행
1) 접속후 파일 탐색기로 아래의 경로에서 scott.sql 파일을 찾는다
C:\oraclexe\app\oracle\product\11.2.0\server\rdbms\admin\scott.sql
2) @ 입력후 해당 파일을 drag and drop 한다
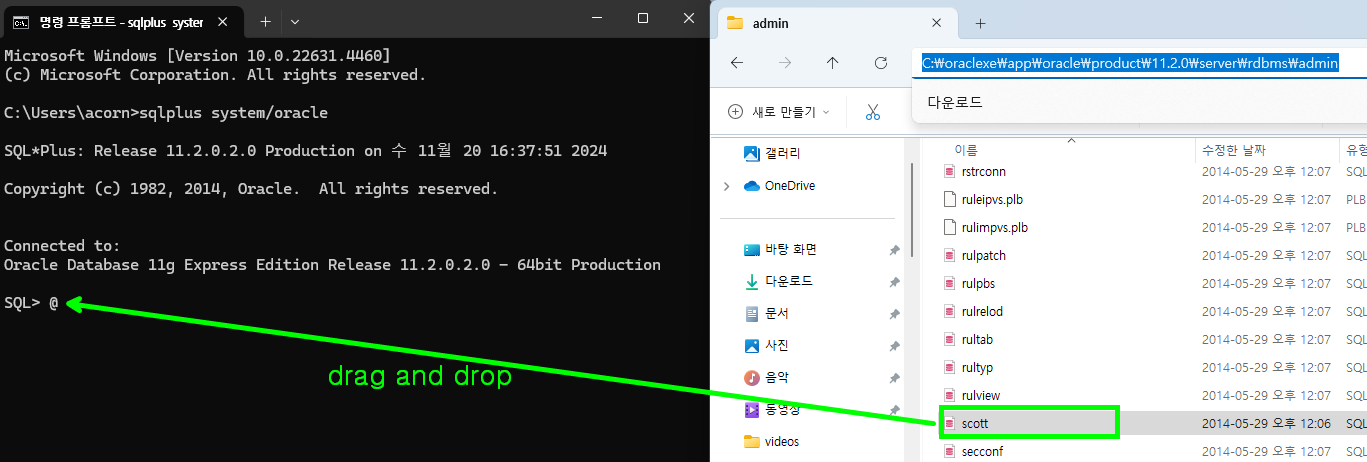
3) drop 후에 상태 확인

- 해당경로의 scott.sql 파일에 있는 sql 문을 일괄실행할 준비가 된것이다
- Enter 키를 입력하면 scott 계정이 만들어지고 연습용 테이블이 준비가된다.
- drag drop 하지 않고 위의 경로를 복사해서 직접 붙여 놓아도 된다.
scott 계정으로 접속 하기
sqlplus scott/TIGER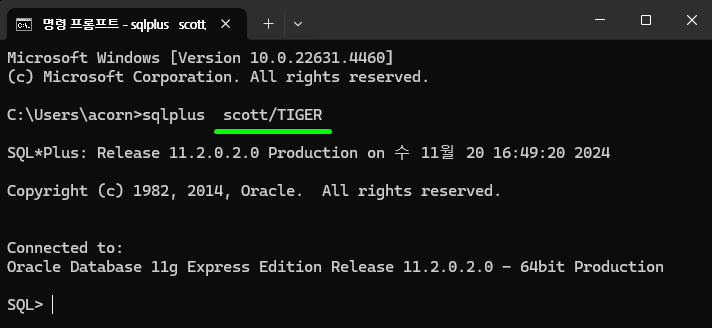
- 만들어진 scott 계정은 비밀번호가 대문자 TIGER 이다
2. Sample Table 확인
Oracle Database의 EMP 테이블은 직원(Employee) 정보를 저장하는 대표적인 예제 테이블로, 여러 연습 문제와 학습에 활용됩니다.
DEPT 테이블은 부서(Department) 정보를 저장하는 대표적인 예제 테이블입니다. 아래는 DEPT 테이블의 상세 구조입니다.
SALGRADE 테이블은 급여 등급(Salary Grade) 정보를 저장하는 데 사용됩니다. 급여 범위에 따라 등급을 매기며, 연습 및 학습에 활용됩니다.
EMP 테이블 구조
| 칼럼명 | 데이터 타입 | 설명 | 제약조건 |
|---|---|---|---|
EMPNO | NUMBER(4) | 사원 번호 (Primary Key) | PRIMARY KEY |
ENAME | VARCHAR2(10) | 사원 이름 | |
JOB | VARCHAR2(9) | 사원의 직업(직책) | |
MGR | NUMBER(4) | 매니저의 사원 번호 | SELF-REFERENCING KEY |
HIREDATE | DATE | 입사 날짜 | |
SAL | NUMBER(7, 2) | 사원의 급여 | |
COMM | NUMBER(7, 2) | 사원의 커미션(성과급) | |
DEPTNO | NUMBER(2) | 부서 번호 (DEPT 테이블 참조) | FOREIGN KEY (DEPT.DEPTNO) |
저장된 데이터 확인
SELECT * FROM EMP;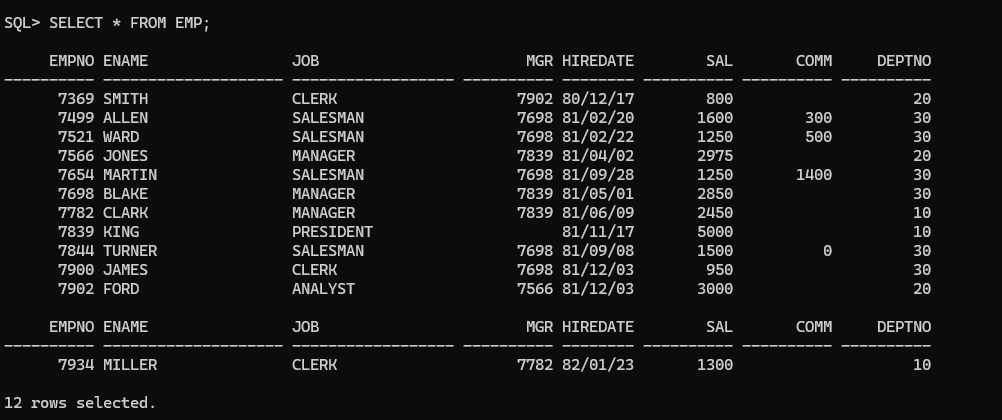
- 12 명의 사원정보가 저장되어 있습니다.
- COMM 칼럼에 값이 들어 있지 않은 사원들도 있습니다.
- KING 사원의 MGR 도 값이 들어 있지 않습니다.
DEPT 테이블 구조
| 칼럼명 | 데이터 타입 | 설명 | 제약조건 |
|---|---|---|---|
DEPTNO | NUMBER(2) | 부서 번호 (Primary Key) | PRIMARY KEY |
DNAME | VARCHAR2(14) | 부서 이름 | |
LOC | VARCHAR2(13) | 부서 위치 |
저장된 데이터 확인
SELECT * FROM DEPT;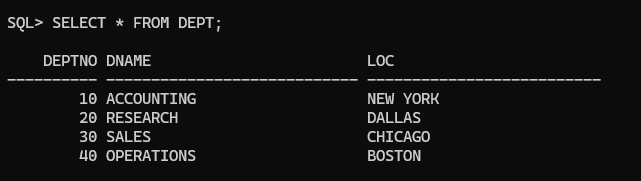
- 4 개의 부서정보가 저장되어 있습니다.
- 40 번 부서는 존재 하지만 EMP 테이블에 40 번 부서에 근무하는 사원은 존재하지 않습니다.
SALGRADE 테이블
| 칼럼명 | 데이터 타입 | 설명 | 제약조건 |
|---|---|---|---|
GRADE | NUMBER(1) | 급여 등급 | |
LOSAL | NUMBER(7, 2) | 급여의 최소 범위 | |
HISAL | NUMBER(7, 2) | 급여의 최대 범위 |
저장된 데이터 확인
SELECT * FROM SALGRADE;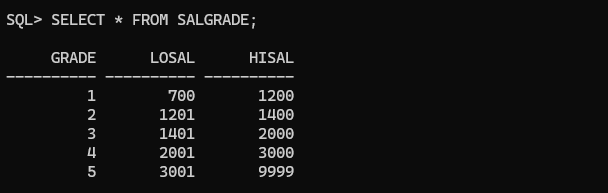
- 급여를 1000 받는 사원은 700 과 1200 사이의 범위에 속해 있기때문에 GRADE 는 1 입니다.
- 급여를 1300 받는 사원은 1201 과 1400 사이의 범위에 속해 있기때문에 GRADE 는 2 입니다.
- GRADE 는 호봉과 비슷하다고 생각하면 됩니다.
6. DQL (Data Query Language)
SELECT문은 데이터베이스에서 데이터를 조회할 때 사용하는 SQL 명령어입니다.
기본 문법
SELECT 칼럼명1, 칼럼명2, ...
FROM 테이블명
WHERE 조건
GROUP BY 그룹화칼럼
HAVING 조건
ORDER BY 정렬칼럼 [ASC|DESC];실행 순서

(1) SELECT 문 사용
- emp 테이블에서 사원번호, 사원이름, 직업을 출력해보세요
SELECT empno, ename, job FROM emp;- emp 테이블에서 사원번호,급여,부서번호를 출력하세요.
단, 급여가 많은 순서대로 출력
SELECT empno, sal, deptno
FROM emp
ORDER BY sal DESC;- emp 테이블 에서 사원번호,급여,입사일을 출력해보세요
단,급여가 적은 순서대로.
SELECT empno, sal, hiredate
FROM emp
ORDER BY sal ASC;- emp 테이블에서 직업,급여를 출력 해보세요
단,직업명으로 오름차순, 급여로 내림차순 정렬해서
SELECT job, sal
FROM emp
ORDER BY job ASC, sal DESC;(2) WHERE 절 사용하기
- 급여가 2000 이상인 사원의 사원번호,사원이름,급여 출력하기
SELECT empno, ename, sal
FROM emp
WHERE sal >= 2000 ; - emp 테이블에서 부서번호가 10번인 사원들의 모든 정보를 출력하세요.
SELECT *
FROM emp
WHERE deptno=10- emp 테이블에서 입사일이 '81/02/20'인 사원의 사원번호, 이름, 입사일을 출력해 보세요
SELECT empno, ename, hiredate
FROM emp
WHERE hiredate = '81/02/20';- emp 테이블에서 직업이 'SALESMAN'인 사람들의 이름, 직업, 급여를 출력해 보세요
단, 급여가 높은 순서대로
SELECT ename, job, sal
FROM emp
WHERE job = 'SALESMAN'
ORDER BY sal DESC;(3) 연산자
1) 산술 연산자
- 부서번호가 10번인 사원들의 급여를 출력하되 10% 인상된 금액으로 출력해 보세요
SELECT sal, sal * 1.1
FROM emp
WHERE deptno = 10;2) 비교 연산자
- 급여가 3000 이상인 사원들의 모든 정보를 출력하세요.
SELECT *
FROM emp
WHERE sal >= 3000;- 부서번호가 30번이 아닌 사람들의 이름과 부서번호를 출력해 보세요.
SELECT ename, deptno
FROM emp
WHERE deptno != 30;3) 논리 연산자
- 부서번호가 10번이고 급여가 3000 이상인 사원들의 이름과 급여를 출력하세요.
SELECT ename, sal
FROM emp
WHERE deptno = 10 AND sal >= 3000;- 직업이 SALESMAN이거나 MANAGER인 사원의 사원번호와 부서번호를 출력하세요.
SELECT empno, deptno
FROM emp
WHERE job = 'SALESMAN' OR job = 'MANAGER';4) SQL 연산자
IN 연산자 (OR 연산자와 비슷한 역활)
- 부서번호가 10번이거나 20번인 사원의 사원번호와 이름, 부서번호 출력하기
SELECT empno, ename, deptno
FROM emp
WHERE deptno = 10 OR deptno = 20;- IN 연산자를 사용한다면 ?
SELECT empno, ename, deptno
FROM emp
WHERE deptno IN(10,20) ;ANY 연산자 (조건을 비교할때 어느 하나라도 맞으면 true)
SELECT empno, sal
FROM emp
WHERE sal > ANY(1000, 2000, 3000) ;- 결과적으로 는 급여가 1000 이상인 로우를 SELECT 하게 된다.
ALL 연산자(조건을 비교할때 조건이 모두 맞느면 true)
SELECT empno, sal
FROM emp
WHERE sal > ALL(1000, 2000, 3000) ;BETWEEN A AND B ( A와 B 사이의 데이타를 얻어온다)
- 급여가 1000과 2000 사이인 사원들의 사원번호, 이름, 급여를 출력하세요.
SELECT empno, ename, sal
FROM emp
WHERE sal BETWEEN 1000 AND 2000;- 사원 이름이 'FORD'와 'SCOTT' 사이의 사원들의 사원번호, 이름을 출력해 보세요.
SELECT empno, ename
FROM emp
WHERE ename BETWEEN 'FORD' AND 'SCOTT';IS NULL (NULL 인경우 TRUE) , IS NOT NULL (NULL 이 아닌경우 TRUE)
- 커미션이 NULL인 사원의 사원이름과 커미션을 출력해 보세요.
SELECT ename, comm
FROM emp
WHERE comm IS NULL;- 커미션이 NULL이 아닌 사원의 사원이름과 커미션을 출력해 보세요.
SELECT ename, comm
FROM emp
WHERE comm IS NOT NULL;EXISTS (데이터가 존재하면 TRUE)
- 사원이름이 'FORD' 인 사원이 존재하면 사원의 이름과 커미션을 출력하기
SELECT ename, comm
FROM emp
WHERE EXISTS (SELECT ename FROM emp WHERE ename='FORD');LIKE 연산자 (문자열 비교)
- 사원이름이 'J'로 시작하는 사원의 사원이름과 부서번호를 출력하기
SELECT ename, deptno
FROM emp
WHERE ename LIKE 'J%';- 사원이름에 'J'가 포함된 사원의 이름과 부서번호를 출력하기
SELECT ename, deptno
FROM emp
WHERE ename LIKE '%J%';- 사원이름의 두 번째 글자가 'A'인 사원의 이름, 급여, 입사일을 출력하기
SELECT ename, sal, hiredate
FROM emp
WHERE ename LIKE '_A%';- 사원 이름이 'ES'로 끝나는 사원의 이름, 급여, 입사일을 출력하기
SELECT ename, sal, hiredate
FROM emp
WHERE ename LIKE '%ES';- 입사년도가 81년인 사원들의 입사일과 사원번호를 출력하기
SELECT hiredate, empno
FROM emp
WHERE hiredate LIKE '81%';결합 연산자 ( || ) =>단순히 문자열을 연결해서 하나의 데이타로 리턴한다
SELECT ename || '의 직업은' || job || ' 입니다.' FROM emp; 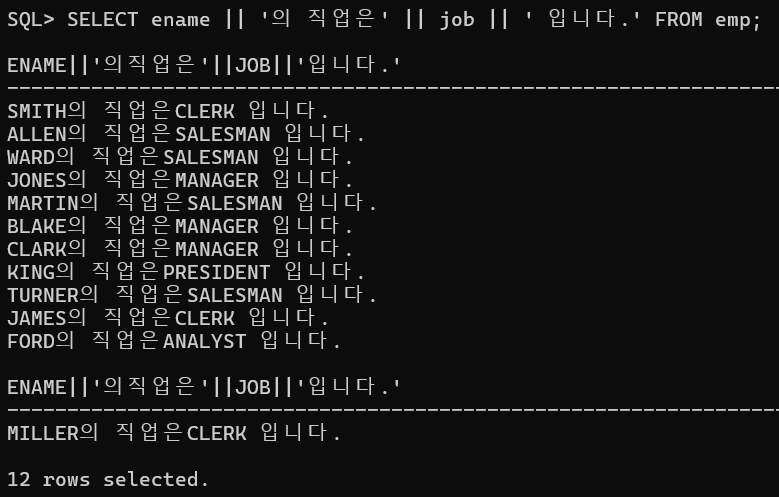
(4) 함수 (Function)
Oracle 함수는 SQL에서 데이터를 처리하거나 변환하기 위해 제공되는 기능입니다. 크게 단일행 함수(Single-Row Functions)와 복수행 함수(Multi-Row Functions)로 구분됩니다.
1. 단일행 함수
단일행 함수는 각 행에 대해 하나의 결과를 반환합니다. SELECT, WHERE, ORDER BY 등 다양한 절에서 사용됩니다. 크게 문자열 함수, 숫자 함수, 날짜 함수, 변환 함수, 일반 함수로 분류됩니다.
1) 문자열 함수 (String Functions)
문자열을 조작하거나 정보를 반환하는 함수입니다.
LOWER()
- 문자열을 소문자로 변환합니다.
SELECT LOWER('HELLO WORLD') AS result FROM DUAL;
-- 결과: hello world
UPPER()
- 문자열을 대문자로 변환합니다.
SELECT UPPER('hello world') AS result FROM DUAL;
-- 결과: HELLO WORLD
INITCAP()
- 각 단어의 첫 글자를 대문자로 변환합니다.
SELECT INITCAP('hello world') AS result FROM DUAL;
-- 결과: Hello World
LENGTH()
- 문자열의 길이를 반환합니다.
SELECT LENGTH('Oracle') AS result FROM DUAL;
-- 결과: 6
SUBSTR()
- 문자열의 일부분을 추출합니다.
SUBSTR(문자열, 시작 index, 가져올 갯수)
SELECT SUBSTR('Oracle Database', 8, 8) AS result FROM DUAL;
-- 결과: Database
INSTR()
- 특정 문자열이 위치한 인덱스를 반환합니다.
INSTR(문자열, 찾을문자열)
SELECT INSTR('Oracle Database', 'Data') AS result FROM DUAL;
-- 결과: 8
LPAD()/RPAD()
- 문자열의 왼쪽/오른쪽을 특정 문자로 채웁니다.
LPAD(문자열, 전체 자리수, 왼쪽에 채울문자)RPAD(문자열, 전체 자리수, 오른쪽에 채울문자)
SELECT LPAD('123', 5, '0') AS result FROM DUAL;
-- 결과: 00123 SELECT RPAD('123', 5, '0') AS result FROM DUAL;
-- 결과: 12300
TRIM(문자열)
- 문자열의 앞뒤에서 지정한 공백을 제거합니다.
SELECT TRIM(' Oracle ') AS result FROM DUAL;
-- 결과: Oracle
REPLACE()
- 문자열 내의 특정 문자열을 다른 문자열로 대체합니다.
REPLACE(문자열, 찾을문자열, 대체할 문자열)
SELECT REPLACE('Hello World', 'World', 'Oracle') AS result FROM DUAL;
-- 결과: Hello Oracle2) 숫자 함수 (Numeric Functions)
숫자를 처리하거나 계산하는 데 사용됩니다.
ROUND()
- 숫자를 반올림합니다.
SELECT ROUND(123.456) AS result FROM DUAL;
-- 결과: 123
ROUND(숫자, 소수점 자릿수)
- 숫자를 반올림해서 소수점 자리수 만큼만 표시 합니다.
SELECT ROUND(123.456, 2) AS result FROM DUAL;
-- 결과: 123.46
CEIL()
- 숫자를 올림합니다.
SELECT CEIL(3.1) AS result FROM DUAL;
-- 결과: 4
FLOOR()
- 숫자를 내림합니다.
SELECT FLOOR(3.9) AS result FROM DUAL;
-- 결과: 3
TRUNC()
- 소수점을 절단 합니다.
SELECT TRUNC(123.456) AS result FROM DUAL;
-- 결과: 123
TRUNC(숫자, 소수점 자릿수)
- 숫자를 절단해서 소수점 자릿수 가지만 표시 합니다.
SELECT TRUNC(123.456, 2) AS result FROM DUAL;
-- 결과: 123.45
MOD()
- 나머지를 반환합니다.
-MOD(나누어지는수, 나눌수)
SELECT MOD(10, 3) AS result FROM DUAL;
-- 결과: 1
ABS()
- 숫자의 절댓값을 반환합니다.
SELECT ABS(-123) AS result FROM DUAL;
-- 결과: 123
POWER()
- 숫자의 거듭제곱을 계산합니다.
POWER(숫자, 지수)
SELECT POWER(2, 3) AS result FROM DUAL;
-- 결과: 8
SQRT()
- 숫자의 제곱근을 반환합니다.
SELECT SQRT(16) AS result FROM DUAL;
-- 결과: 43) 날짜 함수 (Date Functions)
날짜를 조작하거나 정보를 반환하는 데 사용됩니다.
SYSDATE
- 현재 날짜와 시간을 반환합니다.
SELECT SYSDATE AS result FROM DUAL;
-- 결과: 현재 날짜와 시간
ADD_MONTHS()
- 날짜에 지정된 개월 수를 더합니다.
SELECT ADD_MONTHS(SYSDATE, 2) AS result FROM DUAL;
-- 결과: 현재 날짜에서 2개월 후의 날짜
MONTHS_BETWEEN()
- 두 날짜 사이의 개월 수를 계산합니다.
SELECT MONTHS_BETWEEN('2024-12-01', '2024-01-01') AS result FROM DUAL;
-- 결과: 11
NEXT_DAY()
- 지정한 요일의 다음 날짜를 반환합니다.
NEXT_DAY(날짜, 요일)
SELECT NEXT_DAY(SYSDATE, '월요일') AS result FROM DUAL;
-- 결과: 다음 월요일의 날짜
LAST_DAY()
- 지정한 날짜가 속한 달의 마지막 날을 반환합니다.
SELECT LAST_DAY(SYSDATE) AS result FROM DUAL;
-- 결과: 현재 달의 마지막 날짜
EXTRACT()
- 날짜의 특정 부분(연도, 월, 일)을 추출합니다.
SELECT EXTRACT(YEAR FROM SYSDATE) AS year,
EXTRACT(MONTH FROM SYSDATE) AS month,
EXTRACT(DAY FROM SYSDATE) AS day
FROM DUAL;
-- 결과: 현재 연도, 월, 일4) 변환 함수 (Conversion Functions)
데이터 타입을 변환하는 데 사용됩니다.
TO_CHAR()
- 숫자나 날짜를 문자열로 변환합니다.
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') AS result FROM DUAL;
-- 결과: 현재 날짜를 'YYYY-MM-DD' 형식으로 변환1. 기본 날짜 포맷
1.1 YYYY-MM-DD 형식
SELECT TO_CHAR(SYSDATE, 'YYYY-MM-DD') AS formatted_date
FROM DUAL;- 결과:
2024-11-22 - 연도(4자리), 월, 일을 하이픈(
-)으로 구분하여 출력.
1.2 YYYY:MM:DD 형식
SELECT TO_CHAR(SYSDATE, 'YYYY:MM:DD') AS formatted_date
FROM DUAL;- 결과:
2024:11:22 - 날짜를 콜론(
:)으로 구분하여 출력.
1.3 YYYY.MM.DD 형식
SELECT TO_CHAR(SYSDATE, 'YYYY.MM.DD') AS formatted_date
FROM DUAL;- 결과:
2024.11.22 - 날짜를 마침표(
.)로 구분하여 출력.
2. 연도를 2자리로 출력
2.1 YY.MM.DD 형식
SELECT TO_CHAR(SYSDATE, 'YY.MM.DD') AS formatted_date
FROM DUAL;- 결과:
24.11.22 - 연도를 2자리로 출력.
3. 한글과 함께 날짜 출력
3.1 YY" 년 "MM" 월 "DD" 일 " 형식
SELECT TO_CHAR(SYSDATE, 'YY" 년 "MM" 월 "DD" 일 "') AS formatted_date
FROM DUAL;- 결과:
24 년 11 월 22 일 - 원하는 텍스트(예: "년", "월", "일")를 포함해 날짜를 포맷.
4. 시간 포맷
4.1 12시간 형식 (HH:MI:SS)
SELECT TO_CHAR(SYSDATE, 'HH:MI:SS') AS formatted_time
FROM DUAL;- 결과:
03:45:30 - 12시간 형식으로 출력하며, 분(
MI)과 초(SS)를 포함.
4.2 오전/오후 구분 (AM HH:MI:SS)
SELECT TO_CHAR(SYSDATE, 'AM HH:MI:SS') AS formatted_time
FROM DUAL;- 결과:
AM 03:45:30 - 12시간 형식과 함께
AM/PM으로 오전, 오후를 표시.
4.3 오후 표시 (PM HH:MI:SS)
SELECT TO_CHAR(SYSDATE, 'PM HH:MI:SS') AS formatted_time
FROM DUAL;- 결과:
PM 03:45:30 - 오후 시간은
PM으로 표시.
5. 24시간 형식
5.1 HH24:MI:SS
SELECT TO_CHAR(SYSDATE, 'HH24:MI:SS') AS formatted_time
FROM DUAL;- 결과:
15:45:30 - 24시간 형식으로 시간을 표시.
5.2 텍스트 포함 (HH24" 시 "MI" 분 "SS" 초 ")
SELECT TO_CHAR(SYSDATE, 'HH24" 시 "MI" 분 "SS" 초 "') AS formatted_time
FROM DUAL;- 결과:
15 시 45 분 30 초 - 원하는 텍스트를 포함해 24시간 형식으로 표시.
6. 날짜와 시간 결합
6.1 날짜와 시간을 모두 포함 (YY" 년 "MM" 월 "DD" 일 " HH24" 시 "MI" 분 "SS" 초 ")
SELECT TO_CHAR(SYSDATE, 'YY" 년 "MM" 월 "DD" 일 " HH24" 시 "MI" 분 "SS" 초 "') AS formatted_datetime
FROM DUAL;- 결과:
24 년 11 월 22 일 15 시 45 분 30 초 - 한글 텍스트를 포함한 날짜와 시간 결합.
7. 요일 표시
7.1 요일 전체 이름 (MM.DD DAY)
SELECT TO_CHAR(SYSDATE, 'MM.DD DAY') AS formatted_date
FROM DUAL;- 결과:
11.22 FRIDAY - 요일을 영어 전체 이름으로 표시하며 오른쪽 정렬.
7.2 요일 약어 (MM.DD DY)
SELECT TO_CHAR(SYSDATE, 'MM.DD DY') AS formatted_date
FROM DUAL;- 결과:
11.22 FRI - 요일을 영어 약어로 표시.
7.3 요일 숫자 (MM.DD D)
SELECT TO_CHAR(SYSDATE, 'MM.DD D') AS formatted_date
FROM DUAL;- 결과:
11.22 6 - 요일을 숫자로 표시 (1: 일요일, 2: 월요일, ..., 7: 토요일).
TO_DATE()
- 문자열을 날짜로 변환합니다.
SELECT TO_DATE('2024-11-22', 'YYYY-MM-DD') AS result FROM DUAL;
-- 결과: 날짜 형식으로 변환된 값1. 기본 사용 예제
1.1 문자열을 날짜로 변환 (YYYY-MM-DD)
SELECT TO_DATE('2024-11-22', 'YYYY-MM-DD') AS converted_date
FROM DUAL;- 결과: 2024-11-22 00:00:00
- 문자열 형식이
YYYY-MM-DD와 정확히 일치해야 변환 가능.
1.2 시간 포함 문자열 변환 (YYYY-MM-DD HH24:MI:SS)
SELECT TO_DATE('2024-11-22 15:45:30', 'YYYY-MM-DD HH24:MI:SS') AS converted_date
FROM DUAL;- 결과: 2024-11-22 15:45:30
- 날짜와 시간 모두 변환.
2. 포맷 모델 사용 예제
2.1 다양한 날짜 포맷
YYYY/MM/DD
SELECT TO_DATE('2024/11/22', 'YYYY/MM/DD') AS converted_date
FROM DUAL;- 결과: 2024-11-22 00:00:00
YY/MM/DD
SELECT TO_DATE('24/11/22', 'YY/MM/DD') AS converted_date
FROM DUAL;- 결과: 2024-11-22 00:00:00
- 2자리 연도는 2000년대로 간주 (예:
24→2024).
2.2 시간 포맷 포함
12시간 형식 (HH:MI:SS AM)
SELECT TO_DATE('2024-11-22 03:45:30 PM', 'YYYY-MM-DD HH:MI:SS AM') AS converted_date
FROM DUAL;- 결과: 2024-11-22 15:45:30
24시간 형식 (HH24:MI:SS)
SELECT TO_DATE('2024-11-22 15:45:30', 'YYYY-MM-DD HH24:MI:SS') AS converted_date
FROM DUAL;- 결과: 2024-11-22 15:45:30
2.3 텍스트 포함
SELECT TO_DATE('2024 년 11 월 22 일', 'YYYY" 년 "MM" 월 "DD" 일 "') AS converted_date
FROM DUAL;- 결과: 2024-11-22 00:00:00
- 포맷 문자열에 사용자 정의 텍스트를 포함할 수 있습니다.
3. 날짜 연산 및 비교 예제
3.1 문자열로 날짜 비교
SELECT ename, hiredate
FROM emp
WHERE hiredate = TO_DATE('2024-11-22', 'YYYY-MM-DD');- 결과: hiredate가
2024-11-22인 사원 정보.
3.2 현재 날짜 이전 데이터 조회
SELECT ename, hiredate
FROM emp
WHERE hiredate < SYSDATE- 결과: 입사일이
2024-11-22이전인 사원 목록.
주요 포맷 모델 옵션
| 포맷 | 설명 | 예시 입력 값 |
|---|---|---|
YYYY | 4자리 연도 | 2024 |
YY | 2자리 연도 | 24 (→ 2024) |
MM | 월 (숫자) | 11 |
DD | 일 | 22 |
HH24 | 24시간 형식의 시간 | 15 |
HH | 12시간 형식의 시간 | 03 |
MI | 분 | 45 |
SS | 초 | 30 |
AM / PM | 오전/오후 구분 | AM, PM |
"텍스트" | 포맷 내 사용자 지정 텍스트 포함 | 년, 월, 일 |
4. TO_DATE의 주의사항
- 포맷 모델과 문자열의 일치:
- 입력 문자열이
format_model과 정확히 일치하지 않으면 변환에 실패합니다. - 예:
- 입력 문자열이
SELECT TO_DATE('2024-11-22', 'DD-MM-YYYY') AS converted_date
FROM DUAL;
-- 오류: ORA-01843: not a valid month-
NLS_DATE_LANGUAGE와 일치:
- 언어 설정에 따라 월 이름이나 요일이 다르게 해석될 수 있습니다.
-
시간 부분 생략 시 기본값:
- 시간 정보가 없는 경우 기본값은
00:00:00입니다.
- 시간 정보가 없는 경우 기본값은
TO_NUMBER()
- 문자열을 숫자로 변환합니다.
SELECT TO_NUMBER('12345') AS result FROM DUAL;
-- 결과: 123455) 일반 함수 (General Functions)
특정 논리적 작업을 수행하는 함수입니다.
NVL()
- NULL 값을 다른 값으로 대체합니다.
SELECT NVL(comm, 0) AS commision
FROM emp;
-- 결과: NULL 값을 0으로 대체
NVL2()
- 값이 NULL인지 여부에 따라 다른 값을 반환합니다.
SELECT NVL2(comm, 'HAS COMMISSION', 'NO COMMISSION') AS result
FROM emp;
DECODE()
- 조건에 따라 값을 반환합니다 (CASE 문의 간단한 형태).
SELECT DECODE(job, 'MANAGER', 'HIGH', 'LOW') AS result
FROM emp;
-- 결과: job이 'MANAGER'이면 'HIGH', 아니면 'LOW'2. 복수행 함수
COUNT()
- 데이터 행의 개수를 반환합니다.
- NULL 값을 제외한 행의 개수를 구하려면
COUNT(column_name)을 사용.- 전체 행의 개수를 포함하려면
COUNT(*)을 사용.
-- NULL 값을 제외한 개수
SELECT COUNT(column_name) AS non_null_count
FROM table_name;
-- 전체 행의 개수
SELECT COUNT(*) AS total_count
FROM table_name;
SUM()
- 지정된 열의 값들의 총합을 반환합니다.
- NULL 값은 계산에서 제외됩니다.
-- 특정 열의 합
SELECT SUM(salary) AS total_salary
FROM employees;
AVG()
- 지정된 열의 값들의 평균을 반환합니다.
- NULL 값은 계산에서 제외됩니다.
-- 특정 열의 평균
SELECT AVG(salary) AS average_salary
FROM employees;
MAX()
- 지정된 열에서 가장 큰 값을 반환합니다.
- NULL 값은 반환하지 않습니다.
-- 특정 열의 최대값
SELECT MAX(salary) AS max_salary
FROM employees;MIN()
- 지정된 열에서 가장 작은 값을 반환합니다.
- NULL 값은 반환하지 않습니다.
-- 특정 열의 최소값
SELECT MIN(salary) AS min_salary
FROM employees;NULL 값 처리
- 집계 함수는 기본적으로 NULL 값을 제외하고 계산합니다.
- NULL 값을 포함하여 계산하려면
NVL함수를 사용하여 NULL 값을 대체합니다.
-- NULL 값을 0으로 대체 후 합계 계산
SELECT SUM(NVL(salary, 0)) AS including_nulls
FROM employees;요약
Oracle의 COUNT, SUM, AVG, MAX, MIN 함수는 데이터를 요약하거나 통계를 분석하는 데 필수적인 도구입니다. 데이터의 특성과 분석 목적에 따라 적절히 NULL 값을 처리하여 원하는 결과를 도출할 수 있습니다.
(5) GROUP By 절
GROUP BY절은 데이터를 특정 열 또는 열 조합으로 그룹화하여 집계 함수(Aggregate Functions)와 함께 사용하기 위해 데이터를 분류하는 데 사용됩니다. 그룹화된 각 그룹은 하나의 결과 행으로 요약됩니다.
1. GROUP BY 절의 주요 특징
-
집계 함수와 함께 사용:
COUNT,SUM,AVG,MAX,MIN등의 집계 함수와 함께 그룹별 결과를 계산합니다.
-
NULL 값 처리:
GROUP BY는 NULL 값을 하나의 그룹으로 간주합니다.
-
복수 열 그룹화:
- 여러 열을 기준으로 그룹화할 수 있습니다.
-
그룹화 후 조건 추가:
HAVING절을 사용하여 그룹화된 결과에 조건을 추가할 수 있습니다.
2. GROUP BY 절 사용법
기본 문법
SELECT column1, column2, AGGREGATE_FUNCTION(column3)
FROM table_name
GROUP BY column1, column2;예제
- 부서별 급여의 총합을 출력하라.
SELECT deptno,SUM(sal)
FROM emp
GROUP BY deptno - 부서별 평균 급여를 구해보세요.
SELECT deptno, AVG(sal)
FROM emp
GROUP BY deptno- 부서별 평균 급여를 구해보세요 (반올림해서 소수 첫째 자리까지만)
SELECT deptno, ROUND(AVG(sal), 1)
FROM emp
GROUP BY deptno- 직업별 최대 급여를 구해보세요.
SELECT job, MAX(sal)
FROM emp
GROUP BY job;- 급여가 1000 이상인 사원들의 부서별 평균 급여의 반올림 값을 부서번호로 내림차순 정렬해서 출력해 보세요.
SELECT deptno, ROUND(AVG(sal))
FROM emp
WHERE sal >= 1000
GROUP BY deptno
ORDER BY deptno DESC;- 급여가 2000 이상인 사원들의 부서별 평균 급여의 반올림 값을 평균 급여의 반올림 값으로 오름차순 정렬해서 출력해 보세요.
SELECT deptno, ROUND(AVG(sal))
FROM emp
WHERE sal >= 2000
GROUP BY deptno
ORDER BY ROUND(AVG(sal)) ASC;- 각 부서별 같은 업무(job)를 하는 사람의 인원수를 구해서 부서번호, 업무(job), 인원수를 부서번호에 대해서 오름차순 정렬해서 출력해 보세요.
SELECT deptno, job, COUNT(*)
FROM emp
GROUP BY deptno, job
ORDER BY deptno ASC;- 급여가 1000 이상인 사원들의 부서별 평균 급여를 출력해보세요.
단, 부서별 평균 급여가 2000 이상인 부서만 출력하세요.
SELECT deptno, AVG(sal)
FROM emp
WHERE sal >= 1000
GROUP BY deptno
HAVING AVG(sal) >= 2000;(6) JOIN
SQL의
JOIN은 여러 테이블을 결합하여 데이터를 조합하는 데 사용됩니다. ANSI 표준의JOIN표현식과 기존의 일반JOIN표현식을 모두 사용할 수 있습니다.
1. JOIN의 종류
1.1 INNER JOIN (내부 조인)
- ANSI JOIN 표현식:
- 두 테이블에서 조건을 만족하는 행만 반환.
- 일반 JOIN 표현식:
- 테이블을 나열하고,
WHERE절에서 조건을 명시.
- 테이블을 나열하고,
문법:
-- ANSI JOIN 표현식
SELECT column1, column2, ...
FROM table1
INNER JOIN table2
ON table1.column = table2.column; --JOIN 조건
-- 일반 JOIN 표현식
SELECT column1, column2, ...
FROM table1, table2
WHERE table1.column = table2.column; --JOIN 조건1.2 LEFT (OUTER) JOIN (왼쪽 외부 조인)
- ANSI JOIN 표현식:
- 왼쪽 테이블의 모든 행과 오른쪽 테이블의 일치하는 행을 반환하며, 일치하지 않는 오른쪽 테이블의 열은 NULL로 채워짐.
- 일반 JOIN 표현식:
+기호를 사용하여 NULL을 처리.
문법:
-- ANSI JOIN 표현식
SELECT column1, column2, ...
FROM table1
LEFT JOIN table2
ON table1.column = table2.column;
-- 일반 JOIN 표현식
SELECT column1, column2, ...
FROM table1, table2
WHERE table1.column = table2.column(+);1.3 RIGHT (OUTER) JOIN (오른쪽 외부 조인)
- ANSI JOIN 표현식:
- 오른쪽 테이블의 모든 행과 왼쪽 테이블의 일치하는 행을 반환하며, 일치하지 않는 왼쪽 테이블의 열은 NULL로 채워짐.
- 일반 JOIN 표현식:
+기호를 사용하여 NULL을 처리.
문법:
-- ANSI JOIN 표현식
SELECT column1, column2, ...
FROM table1
RIGHT JOIN table2
ON table1.column = table2.column;
-- 일반 JOIN 표현식
SELECT column1, column2, ...
FROM table1, table2
WHERE table1.column(+) = table2.column;1.4 FULL (OUTER) JOIN (전체 외부 조인)
- ANSI JOIN 표현식:
- 두 테이블의 모든 행을 반환하며, 일치하지 않는 부분은 NULL로 채워짐.
- 일반 JOIN 표현식:
- Oracle에서는 FULL OUTER JOIN은 ANSI 구문으로만 지원됩니다.
문법:
-- ANSI JOIN 표현식
SELECT column1, column2, ...
FROM table1
FULL OUTER JOIN table2
ON table1.column = table2.column;1.5 CROSS JOIN (교차 조인)
- ANSI JOIN 표현식:
- 두 테이블의 모든 행을 조합하여 데카르트 곱(Cartesian Product)을 생성.
- 일반 JOIN 표현식:
WHERE절 없이 두 테이블을 나열.
문법:
-- ANSI JOIN 표현식
SELECT column1, column2, ...
FROM table1
CROSS JOIN table2;
-- 일반 JOIN 표현식
SELECT column1, column2, ...
FROM table1, table2;1.6 SELF JOIN (자기 조인)
- ANSI JOIN 표현식:
- 테이블 자기 자신을 다른 테이블처럼 참조하여 조인.
- 일반 JOIN 표현식:
- 동일한 테이블을 두 번 나열하여 조인.
문법:
-- ANSI JOIN 표현식
SELECT a.column1, b.column2
FROM table_name a
INNER JOIN table_name b
ON a.common_column = b.common_column;
-- 일반 JOIN 표현식
SELECT a.column1, b.column2
FROM table_name a, table_name b
WHERE a.common_column = b.common_column;2. EMP 테이블을 활용한 JOIN
2.1 INNER JOIN
- 부서 이름과 사원의 급여를 출력.
-- ANSI JOIN 표현식
SELECT e.ename, e.sal, d.dname
FROM emp e
INNER JOIN dept d
ON e.deptno = d.deptno;
-- 일반 JOIN 표현식
SELECT e.ename, e.sal, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno;2.2 LEFT JOIN
- 모든 사원 정보를 출력하되, 소속된 부서가 없는 사원 정보도 출력
-- ANSI JOIN 표현식
SELECT e.ename, e.sal, d.dname
FROM emp e
LEFT JOIN dept d
ON e.deptno = d.deptno;
-- 일반 JOIN 표현식
SELECT e.ename, e.sal, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno(+);2.3 FULL OUTER JOIN
- 사원의 이름, 급여, 부서명을 출력하되 근무하는 사원이 없는 부서정보도 출력
-- ANSI JOIN 표현식
SELECT e.ename, e.sal, d.dname
FROM emp e
FULL OUTER JOIN dept d
ON e.deptno = d.deptno;2.4 SELF JOIN
- 사원의 이름과 해당사원의 메니저를 출력 하기
-- ANSI JOIN 표현식
SELECT e1.ename AS Employee, e2.ename AS Manager
FROM emp e1
INNER JOIN emp e2
ON e1.mgr = e2.empno;
-- 일반 JOIN 표현식
SELECT e1.ename AS Employee, e2.ename AS Manager
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno;3. 주의 사항
- 일반 JOIN의 비표준성: 일반 JOIN 표현식은 간단하지만, ANSI 표준과 호환되지 않아 사용할수 없는 DBMS 도 있습니다.
- ANSI JOIN 권장: ANSI JOIN은 가독성이 좋고 표준 SQL을 준수하므로 더 권장됩니다.
4. 예제
- 부서명이 'ACCOUNTING'인 사원의 이름, 입사일, 부서번호, 부서명을 출력해 보세요.
ANSI JOIN:
SELECT ename, hiredate, deptno, dname
FROM emp
INNER JOIN dept USING(deptno)
WHERE dname = 'ACCOUNTING';일반 JOIN:
SELECT ename, hiredate, e.deptno, d.dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND d.dname = 'ACCOUNTING';- 커미션이 NULL이 아닌 사원의 이름, 입사일, 부서명을 출력해 보세요.
ANSI JOIN:
SELECT ename, hiredate, dname
FROM emp e
INNER JOIN dept d ON e.deptno = d.deptno
WHERE comm IS NOT NULL;일반 JOIN:
SELECT ename, hiredate, dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND comm IS NOT NULL;- emp 테이블과 dept 테이블을 조인하여 부서번호, 부서명, 이름, 급여를 출력해 보세요.
ANSI JOIN:
SELECT e.deptno, dname, ename, sal
FROM emp e
INNER JOIN dept d ON e.deptno = d.deptno;일반 JOIN:
SELECT e.deptno, d.dname, e.ename, e.sal
FROM emp e, dept d
WHERE e.deptno = d.deptno;- 사원의 이름이 'ALLEN'인 사원의 부서명을 출력해 보세요.
ANSI JOIN:
SELECT ename, dname
FROM emp e
INNER JOIN dept d ON e.deptno = d.deptno
WHERE ename = 'ALLEN';일반 JOIN:
SELECT ename, dname
FROM emp e, dept d
WHERE e.deptno = d.deptno
AND ename = 'ALLEN';- 모든 사원의 이름, 급여, 부서번호, 부서명을 출력하세요.
단, emp 테이블에 없는 부서도 출력해보세요.
ANSI JOIN:
SELECT e.ename, e.sal, e.deptno, d.dname
FROM emp e
RIGHT OUTER JOIN dept d ON e.deptno = d.deptno;일반 JOIN:
SELECT e.ename, e.deptno, d.dname, e.sal
FROM emp e, dept d
WHERE e.deptno(+) = d.deptno;- 다음과 같이 모든 사원의 매니저를 출력해보세요.
ANSI JOIN:
SELECT e1.ename || ' 의 매니저는 ' || e2.ename || ' 입니다'
FROM emp e1
INNER JOIN emp e2 ON e1.mgr = e2.empno;일반 JOIN:
SELECT e1.ename || ' 의 매니저는 ' || e2.ename || ' 입니다'
FROM emp e1, emp e2
WHERE e1.mgr = e2.empno;- 사원의 이름과 급여, 급여의 등급을 출력해 보세요.
ANSI JOIN:
SELECT e.ename, e.sal, s.grade
FROM emp e
INNER JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal;일반 JOIN:
SELECT e.ename, e.sal, s.grade
FROM emp e, salgrade s
WHERE e.sal BETWEEN s.losal AND s.hisal;- 사원의 이름과, 부서명, 급여의 등급을 출력해 보세요.
ANSI JOIN:
SELECT e.ename, d.dname, s.grade
FROM emp e
INNER JOIN dept d ON e.deptno = d.deptno
INNER JOIN salgrade s ON e.sal BETWEEN s.losal AND s.hisal;일반 JOIN:
SELECT e.ename, d.dname, s.grade
FROM emp e, dept d, salgrade s
WHERE e.deptno = d.deptno
AND e.sal BETWEEN s.losal AND s.hisal;결론
ANSI JOIN과 일반 JOIN은 동일한 결과를 제공할 수 있지만, ANSI JOIN은 표준을 준수하며 가독성이 뛰어납니다. 실습을 통해 JOIN의 동작을 익혀 보세요!
(7) 서브쿼리
Oracle에서 서브쿼리는 하나의 SQL 문 안에 포함된 또 다른 쿼리를 의미합니다. 서브쿼리는 메인 쿼리에서 사용할 데이터를 제공하거나 특정 조건을 설정하는 데 사용됩니다. 서브쿼리는
SELECT,INSERT,UPDATE,DELETE문 안에서 다양한 형태로 활용됩니다.
특징
- 소괄호
( )안에 작성됩니다. - 메인 쿼리와 서브쿼리는 독립적으로 실행될 수 있습니다.
- 서브쿼리는 단일 값 또는 다중 값을 반환할 수 있습니다.
WHERE,HAVING,FROM,SELECT절에서 사용할 수 있습니다.
서브쿼리의 유형
1. 단일 행 서브쿼리
- 단일 값을 반환하는 서브쿼리입니다.
- 주로
=또는 비교 연산자와 함께 사용됩니다.
SELECT empno, ename, job
FROM emp
WHERE deptno = (
SELECT deptno
FROM dept
WHERE dname = 'SALES'
);2. 다중 행 서브쿼리
- 여러 행을 반환하는 서브쿼리입니다.
- 주로
IN,ANY,ALL연산자와 함께 사용됩니다.
SELECT empno, ename, sal
FROM emp
WHERE sal IN (
SELECT sal
FROM emp
WHERE job = 'CLERK'
);3. 상관 서브쿼리 (Correlated Subquery)
- 서브쿼리가 메인 쿼리의 각 행에 의존적으로 실행됩니다.
- 메인 쿼리와 서브쿼리 간에 참조 관계가 있습니다.
SELECT empno, ename, sal
FROM emp e
WHERE sal > (
SELECT AVG(sal)
FROM emp
WHERE deptno = e.deptno
);4. FROM 절에서의 서브쿼리
- 서브쿼리가 임시 테이블처럼 작동하여 데이터를 제공합니다.
SELECT d.dname, sub.avg_sal
FROM (
SELECT deptno, AVG(sal) AS avg_sal
FROM emp
GROUP BY deptno
) sub, dept d
WHERE sub.deptno = d.deptno;단일행 서브쿼리 예제
- SMITH가 근무하는 부서명을 출력
SELECT dname
FROM dept
WHERE deptno = (SELECT deptno FROM emp WHERE ename = 'SMITH');- ALLEN과 같은 부서에서 근무하는 사원의 이름과 부서 번호 출력
SELECT ename, deptno
FROM emp
WHERE deptno = (SELECT deptno FROM emp WHERE ename = 'ALLEN');- ALLEN과 동일한 직책을 가진 사원의 사번, 이름, 직책 출력
SELECT empno, ename, job
FROM emp
WHERE job = (SELECT job FROM emp WHERE ename = 'ALLEN');- ALLEN의 급여와 동일하거나 더 많이 받는 사원의 이름과 급여 출력
SELECT ename, sal
FROM emp
WHERE sal >= (SELECT sal FROM emp WHERE ename = 'ALLEN');- DALLAS에서 근무하는 사원의 이름과 부서 번호 출력
SELECT ename, deptno
FROM emp
WHERE deptno = (SELECT deptno FROM dept WHERE loc = 'DALLAS');- SALES 부서에서 근무하는 모든 사원의 이름과 급여 출력
SELECT ename, sal
FROM emp
WHERE deptno = (SELECT deptno FROM dept WHERE dname = 'SALES');- 자신의 직속 상관이 'KING' 인 사원의 이름과 급여를 출력해 보세요.
SELECT ename,sal
FROM emp
WHERE mgr = (SELECT empno FROM emp WHERE ename='KING')다중행 서브쿼리 예제
- 급여를 3000 이상받는 사원이 소속된 부서와 동일한 부서에서 근무하는 사원들의 이름과 급여, 부서번호를 출력해 보세요.
SELECT ename, sal, deptno
FROM emp
WHERE deptno IN (
SELECT deptno
FROM emp
WHERE sal >= 3000
);- IN 연산자를 이용하여 부서별로 가장 급여를 많이 받는 사원의 사원번호, 급여, 부서번호를 출력해보세요.
SELECT empno, sal, deptno
FROM emp
WHERE sal IN (
SELECT MAX(sal)
FROM emp
GROUP BY deptno
);- 직책이 MANAGER 인 사원이 속한 부서의 부서번호와 부서명과 부서의 위치를 출력해보세요.
SELECT deptno, dname, loc
FROM dept
WHERE deptno IN (
SELECT deptno
FROM emp
WHERE job = 'MANAGER'
);- 30번 부서의 사원 중에서 급여를 가장 많이 받는 사원보다 더 많은 급여를 받는 사원의 이름과 급여를 출력해보세요. (단일 행 서브쿼리)
SELECT ename, sal
FROM emp
WHERE sal > (
SELECT MAX(sal)
FROM emp
WHERE deptno = 30
);- 30번 부서의 사원 중에서 급여를 가장 많이 받는 사원보다 더 많은 급여를 받는 사원의 이름과 급여를 출력해보세요. (다중 행 서브쿼리)
SELECT ename, sal
FROM emp
WHERE sal > ALL (
SELECT sal
FROM emp
WHERE deptno = 30
);- 직책이 'SALESMAN'보다 급여를 많이 받는 사원들의 이름과 급여를 출력하라. (ANY 연산자 이용)
SELECT ename, sal
FROM emp
WHERE sal > ANY (
SELECT sal
FROM emp
WHERE job = 'SALESMAN'
);(8) Data Definition Language
DDL (Data Definition Language)는 데이터베이스의 구조(스키마)를 정의하거나 수정하는 데 사용되는 SQL 명령어 집합입니다.
테이블, 인덱스, 뷰, 제약조건 등 데이터베이스 객체를 생성, 변경, 삭제하는 작업이 포함됩니다.
1) DDL의 주요 특징
-
데이터베이스 객체 정의
- DDL은 데이터베이스의 물리적 구조와 논리적 구조를 정의합니다.
- 테이블, 뷰, 인덱스, 시퀀스, 스키마 등.
-
자동 COMMIT
- 모든 DDL 명령은 실행되면 자동으로 COMMIT됩니다.
- 따라서 트랜잭션으로 롤백할 수 없습니다.
-
영구적인 변경
- DDL 명령어로 수행된 작업은 데이터베이스의 구조에 영구적으로 반영됩니다.
-
트랜잭션과 독립적
- 트랜잭션 내에서 DDL 명령어가 실행되면, 트랜잭션이 자동 종료됩니다.
2) CREATE: 객체 생성
- 데이터베이스 객체를 생성합니다.
테이블 생성
CREATE TABLE emp (
empno NUMBER PRIMARY KEY,
ename VARCHAR2(50) NOT NULL,
job VARCHAR2(30),
sal NUMBER(10,2),
deptno NUMBER REFERENCES dept(deptno)
);뷰 생성
CREATE VIEW emp_view AS
SELECT ename, sal, deptno
FROM emp
WHERE sal > 3000;시퀀스 생성
CREATE SEQUENCE MY_SEQ
START WITH 10
INCREMENT BY 10;3) ALTER: 객체 변경
ALTER 명령어는 데이터베이스 객체(테이블, 제약조건 등)의 구조를 수정하는 데 사용됩니다.
테이블 생성 및 기본 작업
테이블 생성
-- 테이블 생성
CREATE TABLE test(
num NUMBER
);컬럼 추가
-- name 컬럼 추가
ALTER TABLE test
ADD(name VARCHAR2(10));컬럼 수정
-- name 컬럼의 데이터 타입 수정
ALTER TABLE test
MODIFY(name VARCHAR2(20));컬럼 이름 변경
-- name 컬럼의 이름을 myname으로 변경
ALTER TABLE test
RENAME COLUMN name TO myname;컬럼 삭제
-- myname 컬럼 삭제
ALTER TABLE test
DROP COLUMN myname;제약조건 관리
테이블 생성
-- dept2 테이블 생성
CREATE TABLE dept2(
deptno NUMBER(2),
dname VARCHAR2(10),
loc VARCHAR2(10)
);일반 제약조건 추가
-- deptno 컬럼에 PRIMARY KEY 추가
ALTER TABLE dept2
ADD(CONSTRAINT dept2_deptno_pk PRIMARY KEY(deptno));NOT NULL 제약조건 추가
-- dname 컬럼에 NOT NULL 제약조건 추가
ALTER TABLE dept2
MODIFY dname CONSTRAINT dept2_dname_nn NOT NULL;제약조건 비활성화
-- dept2_deptno_pk 제약조건 비활성화
ALTER TABLE dept2
DISABLE CONSTRAINT dept2_deptno_pk제약조건 활성화
-- dept2_deptno_pk 제약조건 활성화
ALTER TABLE dept2
ENABLE CONSTRAINT dept2_deptno_pk제약조건 삭제
-- PRIMARY KEY 제약조건 삭제
ALTER TABLE dept2
DROP CONSTRAINT dept2_deptno_pk;종함 예제
-- 테이블 생성
CREATE TABLE employee(
empno NUMBER PRIMARY KEY,
ename VARCHAR2(50),
sal NUMBER,
deptno NUMBER
);
-- 컬럼 추가
ALTER TABLE employee
ADD(hire_date DATE DEFAULT SYSDATE);
-- 컬럼 수정
ALTER TABLE employee
MODIFY sal NUMBER(12,2);
-- 컬럼 이름 변경
ALTER TABLE employee
RENAME COLUMN ename TO emp_name;
-- 컬럼 삭제
ALTER TABLE employee
DROP COLUMN hire_date; -- PRIMARY KEY 추가
ALTER TABLE employee
ADD CONSTRAINT employee_empno_pk PRIMARY KEY(empno);
-- FOREIGN KEY 추가
ALTER TABLE employee
ADD CONSTRAINT employee_dept_fk FOREIGN KEY(deptno) REFERENCES dept(deptno);
-- CHECK 제약조건 추가
ALTER TABLE employee
ADD CONSTRAINT employee_sal_ck CHECK(sal > 0);
-- 제약조건 삭제
ALTER TABLE employee
DROP CONSTRAINT employee_sal_ck;제약조건 관리 명령어 요약
| 작업 | 명령어 |
|---|---|
| PRIMARY KEY 추가 | ALTER TABLE 테이블명 ADD(CONSTRAINT 이름 PRIMARY KEY(컬럼명)); |
| UNIQUE 제약조건 추가 | ALTER TABLE 테이블명 ADD(CONSTRAINT 이름 UNIQUE(컬럼명)); |
| FOREIGN KEY 추가 | ALTER TABLE 테이블명 ADD(CONSTRAINT 이름 FOREIGN KEY(컬럼명) REFERENCES 테이블(컬럼명)); |
| CHECK 제약조건 추가 | ALTER TABLE 테이블명 ADD(CONSTRAINT 이름 CHECK(조건)); |
| NOT NULL 제약조건 추가 | ALTER TABLE 테이블명 MODIFY 컬럼명 CONSTRAINT 이름 NOT NULL; |
| 제약조건 삭제 | ALTER TABLE 테이블명 DROP CONSTRAINT 이름; |
4) DROP: 객체 삭제
테이블 삭제
DROP TABLE emp;시퀀스 삭제
DROP SEQUENCE MY_SEQ;뷰 삭제
DROP VIEW emp_view;5) RENAME: 객체 이름 변경
RENAME emp TO employee;DDL 사용 시 주의사항
-
자동 COMMIT
- DDL 명령어는 실행 후 자동으로 COMMIT됩니다. 따라서 롤백이 불가능하므로 신중히 사용해야 합니다.
-
트랜잭션 중 사용 제한
- DDL 명령어를 트랜잭션 내에서 실행하면 트랜잭션이 강제로 종료됩니다.
-
데이터 손실 가능성
DROP이나TRUNCATE명령은 데이터 및 구조를 삭제하므로, 잘못 사용하면 복구가 어렵습니다.
DDL은 데이터베이스의 구조를 정의하고 변경하는 데 필수적이며, 테이블과 같은 주요 객체를 관리하는 기본적인 작업입니다.
하지만 DDL은 자동으로 COMMIT되기 때문에 데이터 삭제(DROP,TRUNCATE)나 변경(ALTER) 작업 시 주의가 필요합니다.
(9) View
뷰(View)는 하나 이상의 테이블에서 데이터를 조회하는 SQL 쿼리를 기반으로 생성되는 가상 테이블입니다.
뷰는 물리적으로 데이터를 저장하지 않으며, 쿼리 실행 시 실제 테이블에서 데이터를 가져옵니다.
1) 뷰의 특징
-
가상 테이블:
- 데이터가 물리적으로 저장되지 않고, 기본 테이블의 데이터를 참조하여 동작.
-
보안 강화:
- 테이블의 특정 컬럼이나 데이터를 제한하여 사용자가 접근할 수 있도록 설정 가능.
-
재사용성:
- 복잡한 쿼리를 단순화하고, 여러 사용자나 프로그램에서 재사용 가능.
-
실시간 데이터 반영:
- 뷰는 항상 기본 테이블의 최신 데이터를 반영합니다.
3) 뷰의 장점
-
데이터 보안:
- 사용자가 직접 테이블에 접근하지 않아도 특정 데이터를 제한적으로 노출 가능.
-
데이터 관리 단순화:
- 복잡한 JOIN, 집계 쿼리를 캡슐화하여 간단한 뷰로 제공.
-
논리적 독립성 제공:
- 기본 테이블 구조가 변경되어도, 뷰를 통해 접근하는 사용자나 애플리케이션은 영향을 받지 않음.
-
일관성 보장:
- 뷰를 통해 일관된 데이터를 제공하여 사용자 간 데이터 차이를 방지.
3) 뷰의 종류
1. 단순 뷰(Simple View)
- 단일 테이블에서 데이터를 가져오며, 집계 함수가 포함되지 않음.
CREATE VIEW simple_view AS
SELECT empno, ename, sal
FROM emp;2. 복합 뷰(Complex View)
- 여러 테이블을 JOIN하거나, 집계 함수, GROUP BY 등을 포함.
CREATE VIEW complex_view AS
SELECT d.deptno, d.dname, COUNT(e.empno) AS emp_count
FROM dept d
LEFT JOIN emp e ON d.deptno = e.deptno
GROUP BY d.deptno, d.dname;4. 읽기 전용 뷰(Read-Only View)
- 데이터 수정이 불가능한 뷰. 복합 뷰는 기본적으로 읽기 전용.
4) 뷰의 생성 및 관리
1. 뷰 생성
-- 단순 뷰 생성
CREATE VIEW emp_view AS
SELECT empno, ename, sal, deptno
FROM emp;
-- 복합 뷰 생성
CREATE VIEW dept_summary AS
SELECT d.deptno, d.dname, COUNT(e.empno) AS emp_count, AVG(e.sal) AS avg_sal
FROM dept d
JOIN emp e ON d.deptno = e.deptno
GROUP BY d.deptno, d.dname;2. 뷰 조회
-- 뷰 데이터 조회
SELECT * FROM emp_view;
-- 조건부 조회
SELECT ename, sal FROM emp_view WHERE sal > 3000;3. 뷰 갱신
-- 기존 뷰 재정의
CREATE OR REPLACE VIEW emp_view AS
SELECT empno, ename, sal
FROM emp
WHERE sal > 2000;4. 뷰 삭제
-- 뷰 삭제
DROP VIEW emp_view;5. 뷰 변경 불가
뷰는 물리적으로 데이터를 저장하지 않기 때문에, 일부 뷰는 데이터를 수정할 수 없습니다.
수정 가능한 뷰를 만들기 위해서는 INSTEAD OF 트리거를 사용해야 합니다.
5) 뷰의 데이터 수정 가능 여부
1. 수정 가능한 뷰
- 단순 뷰는 기본적으로 데이터를 수정할 수 있습니다.
UPDATE emp_view
SET sal = sal + 500
WHERE empno = 101;2. 수정 불가능한 뷰
- 다음 조건을 포함하는 뷰는 데이터를 수정할 수 없습니다:
- GROUP BY 또는 집계 함수 사용.
- DISTINCT 사용.
- UNION, JOIN, 또는 서브쿼리 사용.
- 읽기 전용 뷰로 생성.
6) 뷰의 활용 사례
-
데이터 보안:
- 관리자만 급여 정보에 접근하도록 설정:
CREATE VIEW emp_secure AS SELECT empno, ename, deptno FROM emp; -
복잡한 쿼리 단순화:
- 부서별 직원 수와 평균 급여 조회:
CREATE VIEW dept_summary AS SELECT deptno, COUNT(empno) AS emp_count, AVG(sal) AS avg_sal FROM emp GROUP BY deptno; -
논리적 데이터 분리:
- 기본 테이블을 변경하더라도, 뷰를 통해 일관된 데이터를 제공.
7) 뷰 관련 참고사항
-
실시간 반영:
- 뷰는 기본 테이블의 데이터를 참조하므로, 기본 테이블 변경 시 뷰도 즉시 반영됩니다.
-
성능:
- 뷰는 항상 쿼리를 실행하므로, 복잡한 뷰는 성능에 영향을 줄 수 있습니다.
-
제약조건:
- 뷰 자체에 제약조건을 설정할 수 없습니다. 대신 기본 테이블에 제약조건을 설정해야 합니다.
