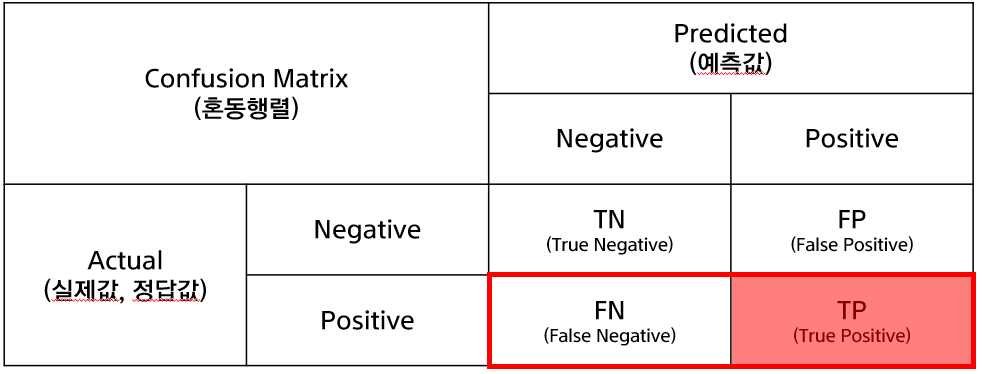
혼동행렬; Confusion Matrix
Comment :
항상 헷갈리는 Confusion Matrix의 개념과 여러개의 (이진분류모델의 measure) 성능평가 지표를 메모
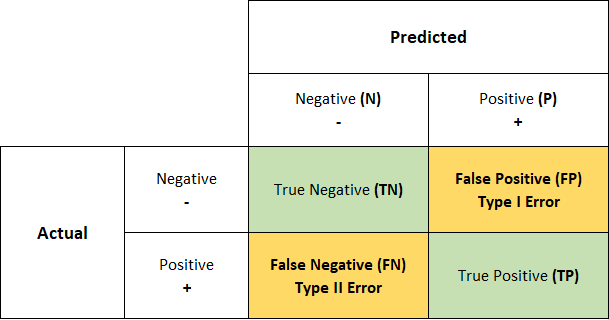
Confusion Matrix
Confusion Matrix, 혼동행렬이라고 하고 이진분류 (Binary Classification) 모델의 성능을 평가하는데에 사용된다. (이진분류 외의 다중분류에서도 사용됨)
- Binary Classification이므로 정답값( 라벨, Actual, Truth, 실제값 등)은 0 or 1로 나타난다.
- Binary Classification Model의 예측값( Predicted)은 0 or 1로 나타난다.
[!]뭐 어떤 함수를 쓰느냐에 따라 다르지만 probability, 즉 0과 1사이의 확률값이 Cutoff, Threshold를 거쳐 0 또는 1의 예측값이 된다
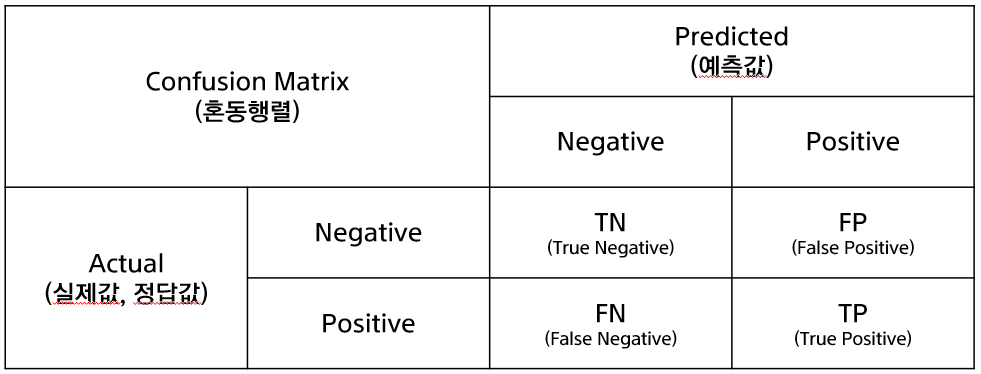
- TN (True Negative) : 예측은 0을 했는데 맞았음, 즉 실제도 0인 경우
- FP (False Positive) : 예측은 1을 했는데 틀렸음, 즉 실제는 0인 경우
- FN (False Negative) : 예측은 0을 했는데 틀렸음, 즉 실제는 1인 경우
- TP (True Positive) : 예측은 1을 했는데 맞았음, 즉 실제도 1인 경우
평가지표
(Confusion Matrix를 통해 나온) 여러가지 평가지표; Evaluation Matrices, measure를 배워보자
1. Accuracy
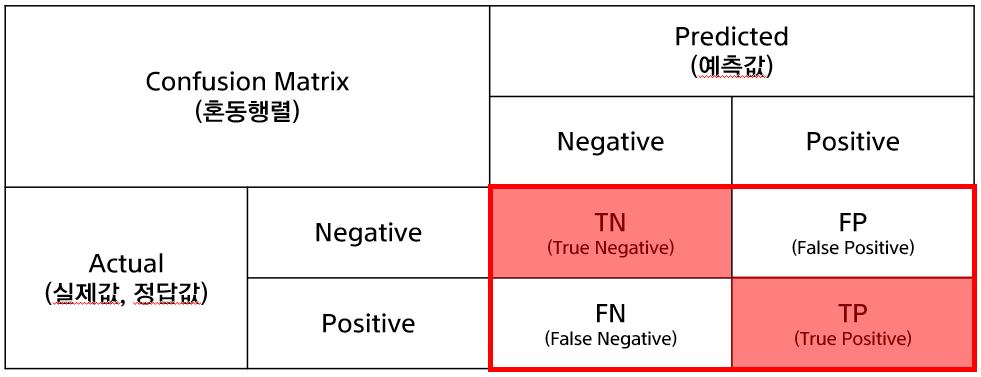
Accuracy, 정확도라고 한다. 단순하다. 전체 중에 정답을 맞춘, 즉 True의 비율이다.
얼마나 많이, 잘 0을 0, 1을 1이라고 예측하였는가
2. Precision
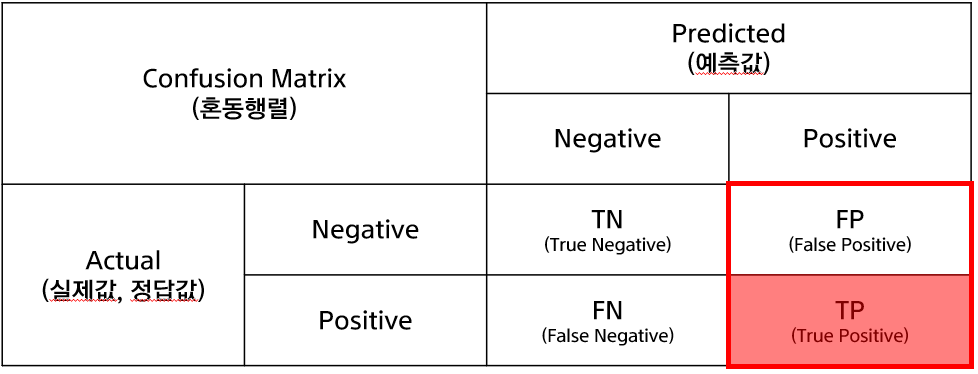
Precision, 정밀도라고 한다. 모델이 1로 예측한 것 중에 실제 1인 비율
1로 예측한 것들이 얼마나 많이 맞았나, 실속있냐 이런 느낌
모델 관점에서 생각한다
3. Sensitivity
Sensitivity, 재현율, Recall 등 이름이 많다. 실제 1인것들 중 모델이 1로 예측한 비율
실제 1인 것들 중 모델이 1로 얼마나 많이 예측하였는가
실제값 관점에서 생각한다.
Precision vs Sensitivity
- ex1) 환자의 암을 양성 Positive=1인지 음성 Negative=0인지 예측
- ex2) 스팸메일 검출, 스팸메일이면 Positive=1, 일반메일이면 Negative=0으로 예측
위 두가지 케이스를 생각해보자.
[!]아래의 글이 정답은 아니다. 이는 Domain과 모델 제작자의 결정에 달린 것이다암을 판단하는 모델의 경우 Sensitivity, 즉 실제 암환자 중 모델이 얼마나 많이 암환자로 예측했느냐가 중요하다.
스팸메일을 검출하는 모델의 경우 Precision, 즉 모델이 스팸메일이라고 예측한 것 중 얼마나 많이 실제 스팸메일인지가 중요하다.
이와 같이 Precision과 Sensitivity는 어떤 Task를 예측하느냐에 따라 중요도가 달리 해석될 수 있다.
Cut-off
- 🤪모델 A : 야 조금만 의심되면 그냥 무조건 1이라고 예측해!
- 😠모델 B : 우리는 진짜 완벽하게 1로 판단되지 않는 이상, 앵간해서는 1이라고 예측 안할거임
우리의 이진분류 모델은 output으로 '1'일 확률(probability)을 내놓는다.
일반적으로는 이 확률값이 0.5 이상일 경우 1로 예측하고, 이하일 경우 0으로 예측하는 것!위의 0.5가 바로 Cut-off(=Threshold)라고 하는 값이다
예를 들어서 모델의 Cut-off value가 0.1일 경우, 🤪모델 A와 같이 모델의 예측값 대부분이 1일 것이고 / 모델의 Cut-off value가 0.9일 경우, 😠모델 B와 같이 모델의 예측값의 극수소만 1일 것이다.
4. F1-Score
F1-Score는 Precision과 Sensitivity의 조화평균으로 두 개의 값이 가장 비슷할때 가장 큰값으로 나온다.
[!] 데이터의 클래스 분포가 불균형할때(0값이 매우 많고, 1값이 매우 적은 그런 케이스) 분류모델의 Accuracy만 볼 경우, 잘못된 성능 해석이 가능하므로 F1-Score를 사용한다.
