Definition
Digital Signature란?
디지털 문서의 진정성(authenticity)과 무결성(integrity)을 암호학적으로 보장하기 위한 기술
→ Private Key Encprytion(Symmetric-key Cryptography)에서는 MAC을 통해서 authenticity과integrity를 보장(송신자와 수신자만 공유된 비밀키를 가지고 있고, 이를 통해서 MAC을 생성 ⇒ 자연스럽게 authentication과 integrity 보장가능)
→ Public Key Encryption(Asymmetric-key Cryptograph)에서는 Digital Signature를 통해서 authenticity과 integrity를 보장(Public key encryption의 경우에는 공개키가 누구에게나 공개되어 있기 때문에, 송신자의 신원을 바로 보장할 수 없음 ⇒ 따라서 identification+signature)
Digital Signature의 과정

그림처럼 두 당사자가 있을 때, 발신자가 pk를 공개된 저장소에 올려서 누구나 접근할 수 있게 한다. 발신자와 통신하고 싶은 사람은 누구나 pk를 얻을 수 있다. 발신자가 수신자에게 메시지 m을 보내려고 할 때, 발신자는 본인이 해당 m을 만들었다는 것을 증명하기 위해 를 함께 보낸다. Bob은 σ에 대해서 알고리즘을 통해 발신자 Alice로부터 왔고 중간에 변조되지 않았음을 검증할 수 있다.
Digital Signature의 활용
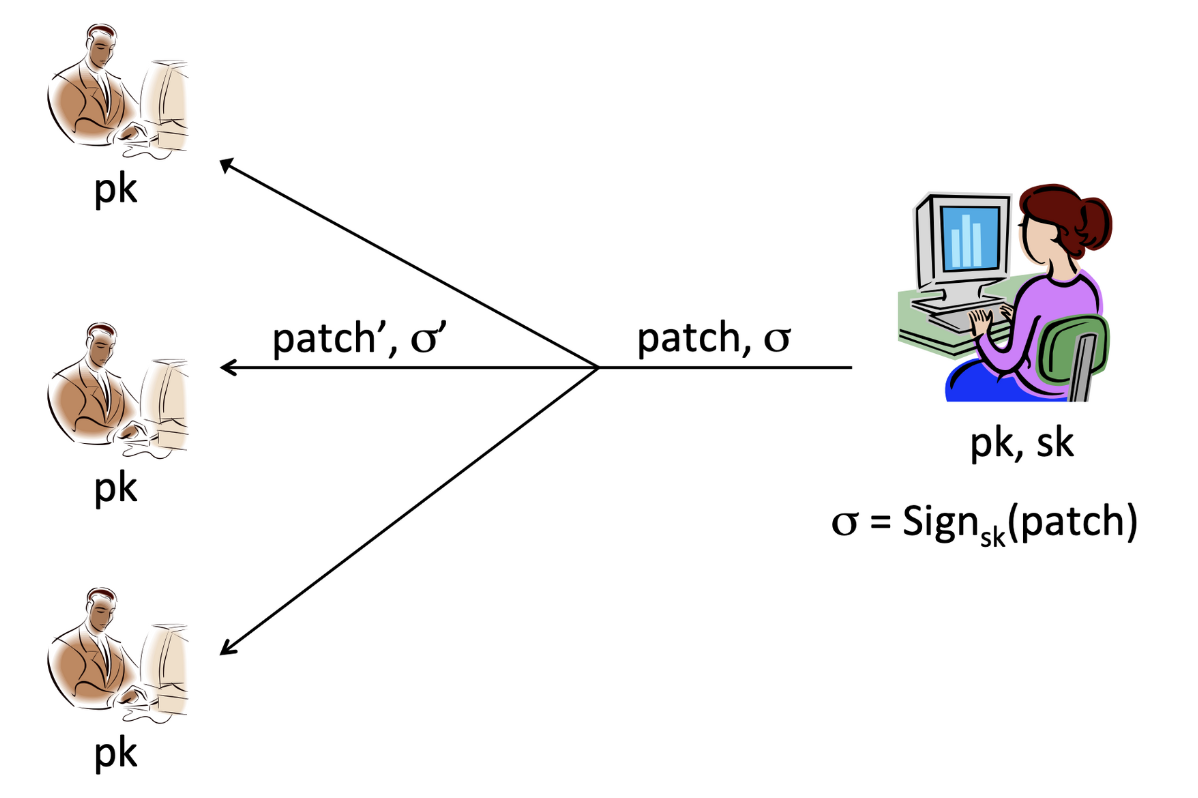
Digital signatures(전자서명) 프로토타입을 소프트웨어 프로그램에 적용해자. 위 그림에서 Alice는 소프트웨어를 배포하려는 entity이고, Bob은 소프트웨어의 pk를 알고 있는 client이다. Alice는 프로그램을 개선할 때마다 업데이트를 위한 패치를 유저에게 발행하는데, 중간에 패치가 공격자에 의해 위조되지 않도록 와 patch를 함께 전송한다. Bob은 signature를 통해 전송받은 패치가 Alice로부터 온 것인지 확인한다.
Comparison to MACs?
Digital signatures(전자서명)의 방법은 MACs(메시지 인증 코드)의 운용방식과 매우 유사해보인다. 그렇다면 둘의 차이점은 무엇일까? Digital signatures(전자서명) 대신 MACs의 알고리즘을 이용하여 σ를 생성해보자.
| Method 1 : 동일한 키를 모두 공유하는 경우
→ 모든 사용자들이 key를 가지므로 임의의 사용자가 patch와 t를 생성할 수 있다.
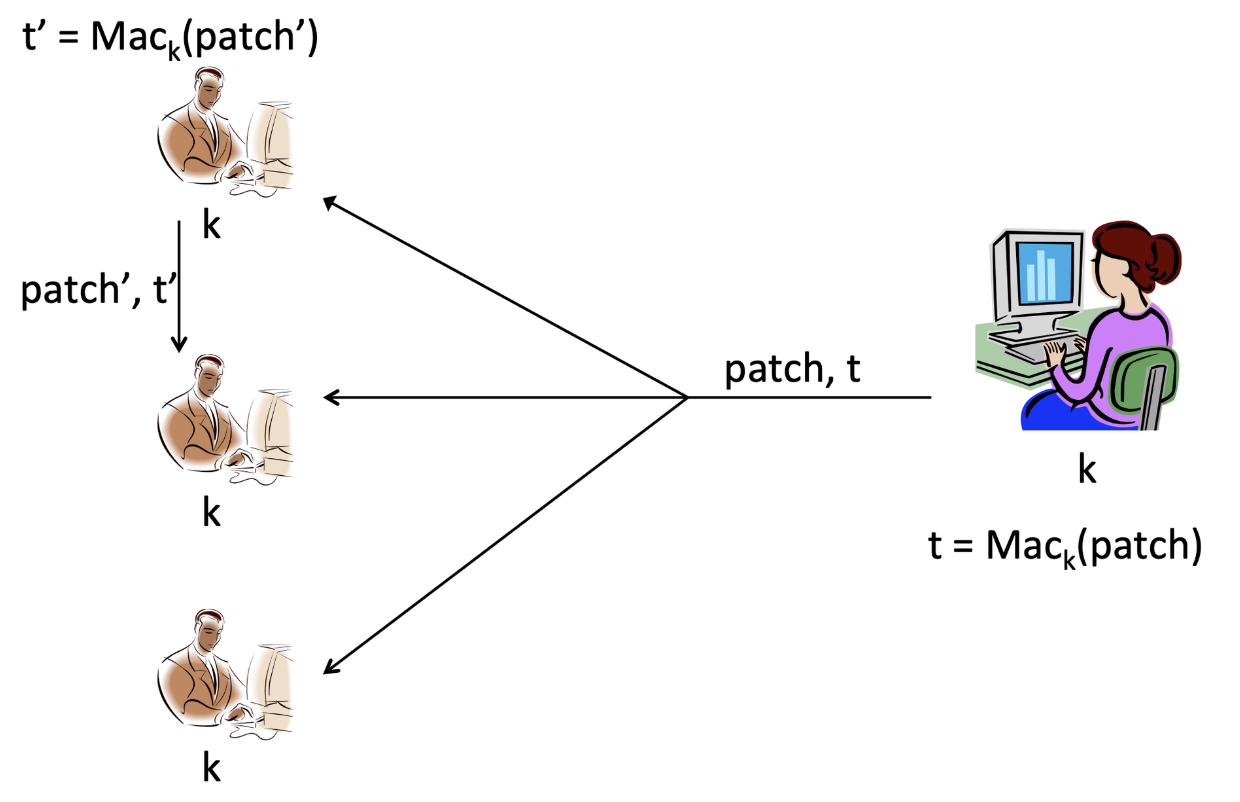
위 그림에서 모든 사람들은 동일한 키 k를 공유한다. 발신자 Alice는 를 이용하여 key k에 대한 tag를 생성하여 Bob에게 전달한다.
그러나 위 방법은 결함이 있다. 위처럼 수신자 Bob은 key k를 알고 있기 때문에, 를 통해 새로운 tag를 만들어낼 수 있다. 만약 수신자들 중 한 명이 악의적인 목적으로 이상한 패치 patch′와 이에 해당하는 tag t′를 전송한다면, 이를 전송받은 수신자는 이상한 tag t′를 올바른 패치로 인식할 수 있다.
| Method 2 : 각각 다른 키를 공유하고, 이를 통해서 MAC을 보내는 경우
→ 수신자가 많아질수록 많은 키를 배포하고 관리해야 한다는 문제
위 방법은 모든 수신자가 동일한 key k를 공유하고 있기 때문에 문제가 생겼다. 이를 해결하고자 이번엔 수신자마다 서로 다른 key들을 Alice와 공유하도록 해보자.
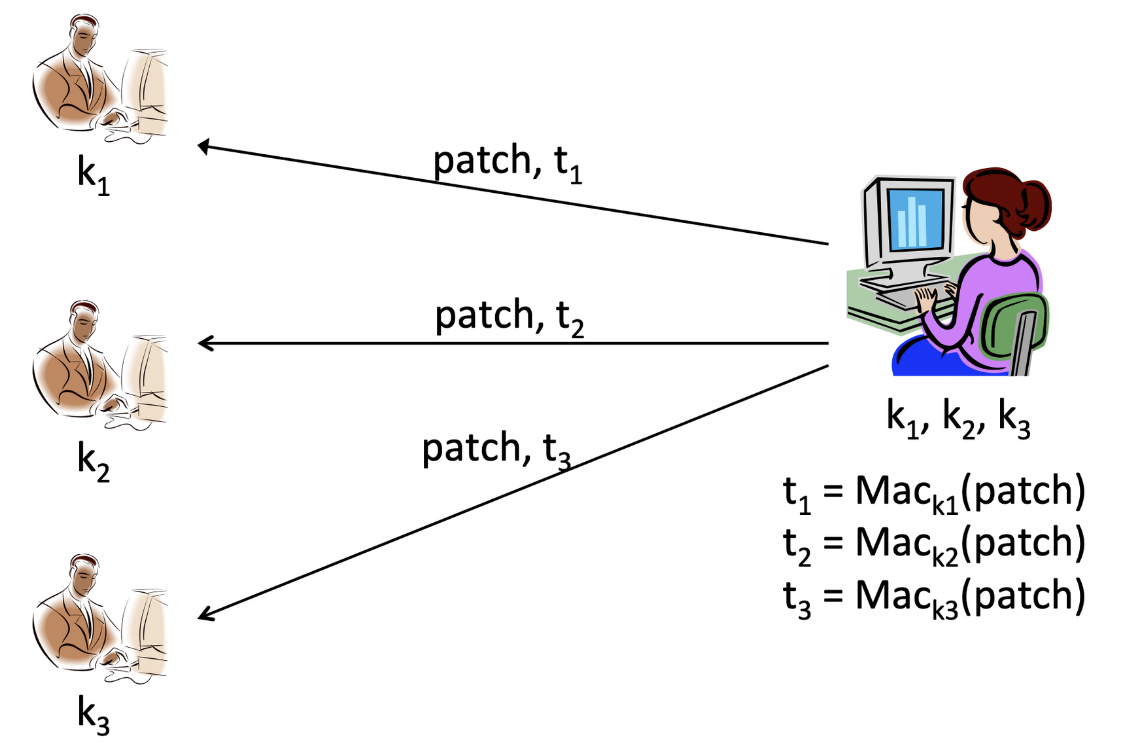
위 그림처럼 tag를 생성하여 전송하면, 수신자들 간에 악의적인 공격을 충분히 막아낼 수 있다. 하지만 Alice 입장에선 수신자들마다 서로 다른 key를 이용하여 tag를 만들어야하기 때문에, 수신자가 많아질수록 많은 키를 배포하고 관리해야 한다는 문제가 생긴다.
Digital Signature는 공개키 암호화(Public-key Cryptography) 방식을 사용하며, MAC이 해결하지 못하는 중요한 보안 속성들을 제공한다.
- Public verifiability(공개검증가능성): 누구나 서명을 검증(verify)할 수 있어야 한다. → MAC은 키를 공유하지 않는 제3자는 MAC의 유효성을 확인할 수 없다.
- Transferability(양도가능성): 다른 사람에게 서명을 양도할 수 있다. → 물론 MAC도 그냥 중간에서 사람이 넘길 수 있긴하지만 키를 공유하지 않는 제3자는 MAC의 유효성을 독립적으로 검증할 수단이 없다. 그런데 signature는 가능하다!
- Non-repudiation(부인방지성): 송신자는 수신자에게 보낸 정보를 부인할 수 없다. MAC과 non-repuditation에 대한 성질을 비교해보면, MAC은 key에 대한 엑세스 권한이 없으면 tag의 진위여부를 확인할 수 없으므로 부인방지까지는 보장할 수 없다. Key는 해당 송신자만 지니고 있기 때문에, 그 key가 정확한지 검증할 방법이 없기 때문이다. (MAC의 경우에는 key가 옳은지 아닌지 알 수 없다.(개인만 가지고 있기 때문에) 그러나 PK는 DB에 저장되어 있으므로 판단할 수 있다)
Signature schemes
Digital signature의 signature scheme을 정의해보면, Signature scheme은 세 개의 PPT 알고리즘으로 구성되어 있다.
- : output pk, sk (키 생성)(input : , output : pk,sk)
- σ← : output σ (서명 생성) (input : sk, m output : σ)
- : output 1 or 0 (증명) (input : pk, m, σ output : 1 or 0)
이때 모든 메시지 m과 Gen 알고리즘을 거친 키 pk,sk에 대하여, 아래 식을 만족한다.
Security(MAC의 security와 유사)
| Threat model
위 signature scheme에서의 공격자는 Adaptive chosen-message attack이라는 공격모델을 사용한다. 위 공격은 공격자가 선택한 메시지에 대한 sign을 얻을 수 있는 방식이다.(공격자가 보낸사람으로 하여금 공격자가 선택한 메시지에 서명하도록 유도할 수 있다.)
| Security goal
공격자는 송신자에 의해 sign이 완료되지 않은 어떤 메시지에 대해서도 유효한 signature를 위조할 수 없어야 한다. 이때 공격자는 송신자의 public key를 알고 있는 상태이다. 이는 완전히 위조가 불가능하다는 점에서 Existential unforgeability를 만족해야 security goal에 도달한다는 말이다. → 유효한 서명을 생성할 수 없다!
Formal definition
위에서 정의한 security에 따라 scheme을 정의해보자.
Scheme: / Attacker: A
Forge :
(새로운 메시지에 대해 유효한 서명을 도출하면 1)
Signature에 대한 security는 아래와 같다.

Replay attacks
위 정의로 replay attack까지 막을 수 있는 것은 아니다. 가령, Alice가 Bob에게 새로운 소프트웨어 패치를 보내는 과정에서 공격자가 작년에 Alice가 보냈던 패치와 서명을 그대로 보낸다면, 유효한 서명이므로 Bob 입장에서는 이를 걸러낼 방법이 없다. → 서명만으로는 replay attack을 막을 수 없고, 더 높은 매커니즘을 사용해 처리해야 한다.(예를 들면 날짜)
Hash-and-sign paradigm
MAC을 공부할 때 Hash and MAC을 공부했었는데, Digital Signature도 Hash and sign이 존재한다. 이 방식은 메시지에 대한 서명을 바로 만드는 것이 아니라 메시지를 해시함수에 넣은 다이제스트 H(m)을 이용해 서명을 만드는 기법이다. 지금까지는 특정 길이 n에 대해서 알아봤다면(짧은 길이의 메시지 인 경우), 이를 좀 더 확장할 수 있다.
Hash-and-sign paradigm
인 해시함수에 대하여 위와 같이 정의한다. 달라진 것은 메시지 m에 대하여 해시함수를 넣은 다이제스트를 서명 알고리즘에 대입하는 것이다. 위 방식처럼 해시함수를 이용하여 서명을 만든다면, HMAC처럼 임의의 길이의 메시지에 대해서도 signature를 만들 수 있다. 따라서 굳이 메시지 입력의 길이를 맞출 필요가 없다.
(그 전에는 짧은 길이의 메시지만 가능했었다. 그런데 더 긴 길이의 메시지를 hash해서 길이를 n으로 맞춘 다음에 이거에 서명을 한다.)
Security
그럼 위 알고리즘의 안전성을 살펴보자. 안전성을 증명하는 방식은 HMAC에서와 동일하게 진행된다.
Theorem
만약 가 안전하고 해시함수 H가 collision-resistant라면, 도 안전하다.
Proof
송신자가 에 대하여 메시지 인증을 하려고 한다.
이때 공격자는 위조한 (m,σ)를 만드는데, 위조하려는 message는 그 어떤 mi와 같은 값이면 안됩니다. 이 때 두 가지 경우가 생긴다.
첫 번째는 공격자가 위조로 만든 해시가 mi의 어떤 해시값과 같을 때이다. 즉, collision이 일어났을 때이다. 하지만 앞서 전제에서 해시함수가 collision-resistance라고 가정했으므로, m과 mi의 해시가 같은 쌍을 찾는 것은 불가능하다.
두 번째는 m의 해시 다이제스트가 모든 i에 대해 와 같지 않은 경우이다. 즉 공격자가 만들어낸 위조문이 유효하다면, 이전에 송신자로부터 받은 h에서 어떠한 단서를 찾았다는 것이다. 하지만 이는 서명 알고리즘이 안전하다는 가정이 전제되었기 때문에 h로부터 유효한 단서를 얻는 것은 실현 불가능하다.
Hash-and-sign은 hybrid와 유사하다. 긴 메시지를 서명한다면, 긴 메시지를 해시하는데 걸리는 시간에 영향을 받는다. → 속도(cost)는 symmetric-key encryption과 비슷한데, key management는 public key encryption을 따름
Identification scheme
디지털 서명의 기반이 되는 중요한 개념인 식별 체계(Identification Scheme)에 대해 알아보자.
Digital Signature는 메시지의 무결성과 서명자의 신원 인증을 보장하는 암호학적 기법이다. 이러한 디지털 서명의 기저에는 '자신만이 아는 비밀 정보(예: 개인키)를 소유하고 있음을 증명하는' 원리가 깔려 있으며, 바로 이 '비밀 정보 소유 증명' 과정을 상호작용적으로 다루는 것이 Identification Scheme이다.
Identification Scheme은 '나는 이 비밀 정보를 알고 있다는 것을 상대방에게 보여주고 싶지만, 그 비밀 정보 자체는 노출하고 싶지 않을 때' 사용하는 상호작용적인 프로토콜이다.
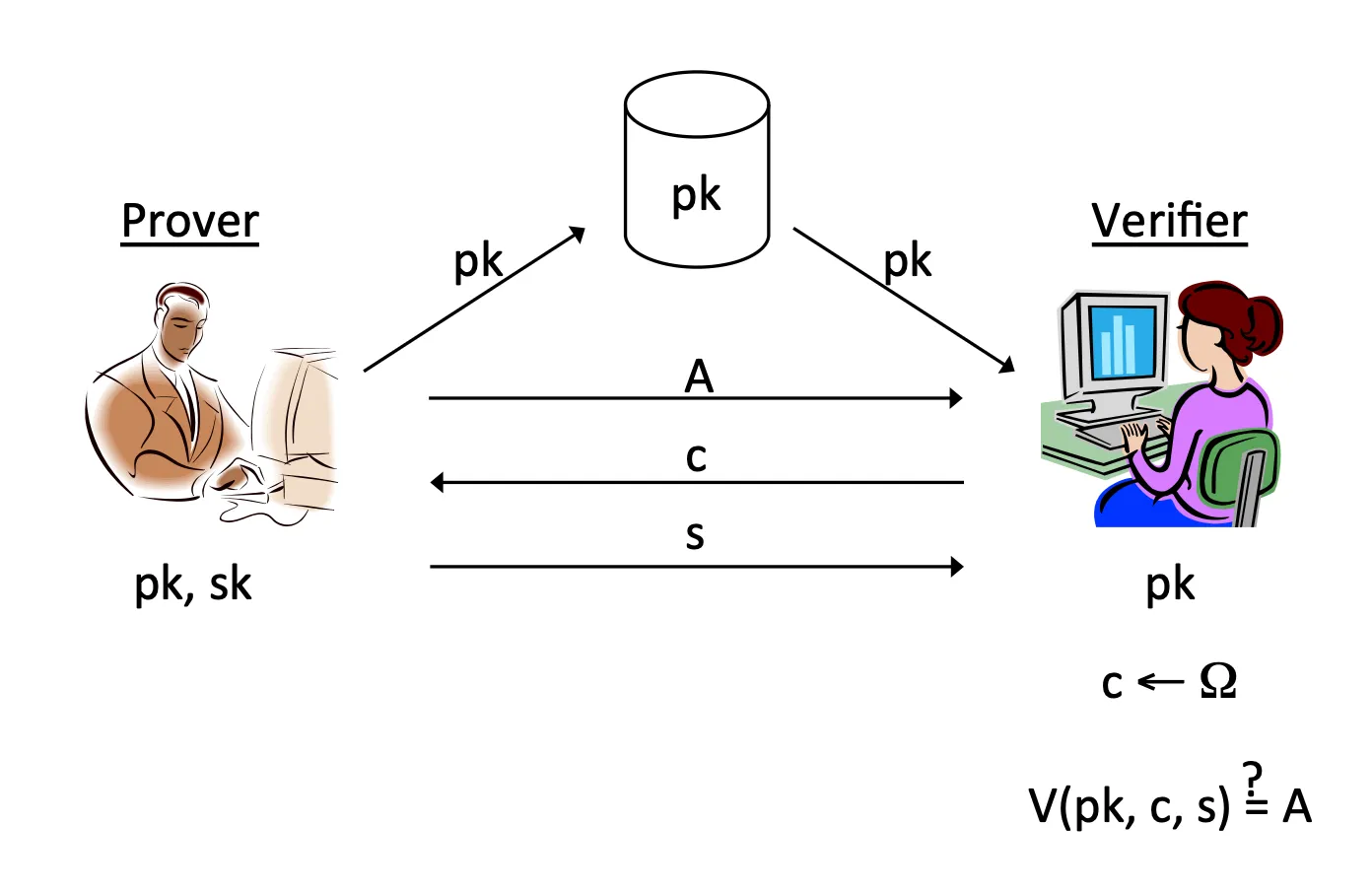
과정
Key 공유
- prover가 pk,sk인 key pair를 생성하고, 자신의 pk를 공개적으로 배포하거나 접근 가능하게 한다
- verifier는 prover의 pk에 접근한다.
Identification
- Prover가 A라는 commitment 메시지를 생성하고 Verifier에게 보낸다.
- verifier는 임의의 challnege를 생성하고 이를 prover에게 보낸다.
- prover는 A와 sk를 기반으로 s를 만들고 verifier에게 보낸다.
- verifier는 pk, c, s를 이용해서 검증한다.
Fiat-Shamir transform
Identification scheme이 상호작용적이라고 했는데, 디지털 서명은 보통 "비상호작용적(Non-Interactive)"이어야 한다. 즉, 서명자가 서명을 만들어서 보내면 검증자가 혼자서 검증할 수 있어야 한다는 것이다.. 그렇다면 어떻게 상호작용적인 식별 체계를 비상호작용적인 서명으로 만들 수 있을까? 바로 이때 등장하는 것이 Fiat-Shamir Transform이다.
Fiat-Shamir Transform은 상호작용적인 식별 체계를 비상호작용적인 디지털 서명 스킴으로 변환하는 일반적인 방법이다.
방법은 다음과 같다. 원래 상호작용적인 식별 체계에서는 Verifier가 무작위 'Challenge'을 생성하여 Prover에게 보내야 한다. 하지만 Fiat-Shamir Transform은 이 Challenge를 암호학적 해시 함수를 사용하여 생성하도록 한다.
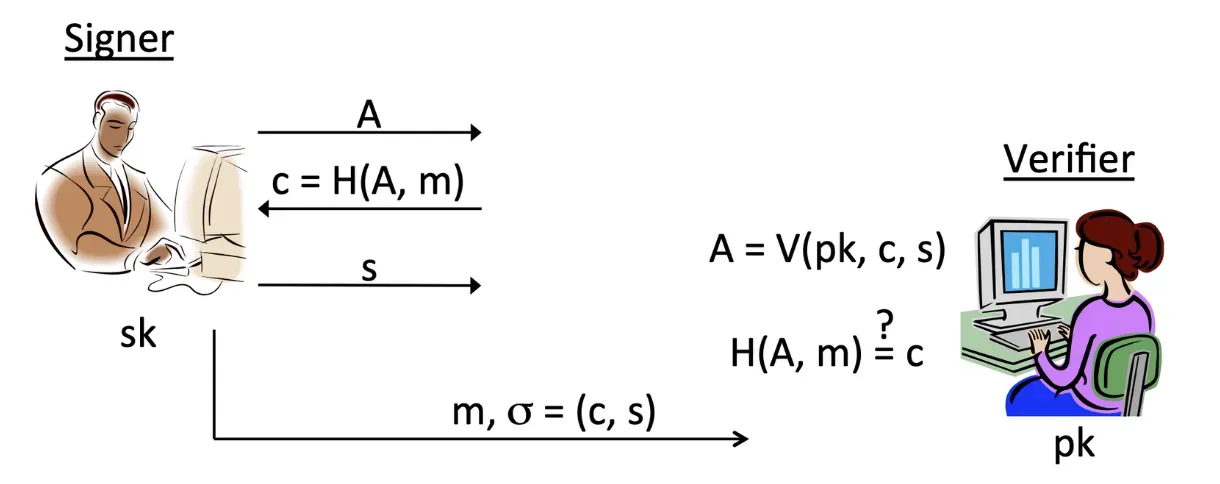
다시 말해, Prover가 서명할 메시지와 커밋먼트를 해시 함수에 넣어 스스로 질문을 만들고, 그 질문에 대한 응답을 계산하여 서명으로 제출하는 방식이다. 이렇게 하면 검증자가 직접 질문을 보낼 필요가 없어지므로, 한 번의 전송으로 서명과 검증이 모두 가능해진다.(커밋먼트가 랜덤하게 생성되므로 challenge도 랜덤!)
이렇게 Fiat-Shamir Transform을 통해서 Identification을 하면서 Digital Signature가 가능해졌다.
Security
만약 passive attack 에 대하여 identification scheme이 안전하고 해시함수 H가 랜덤 함수처럼 모델링되어있다면, 여기에서 파생된 signature scheme 또한 안전하다.
Schnorr Signature
Schnorr identification scheme은 앞선 identification scheme에서 DLog가 hard problem임에 착안해 만든 프로토콜이다.
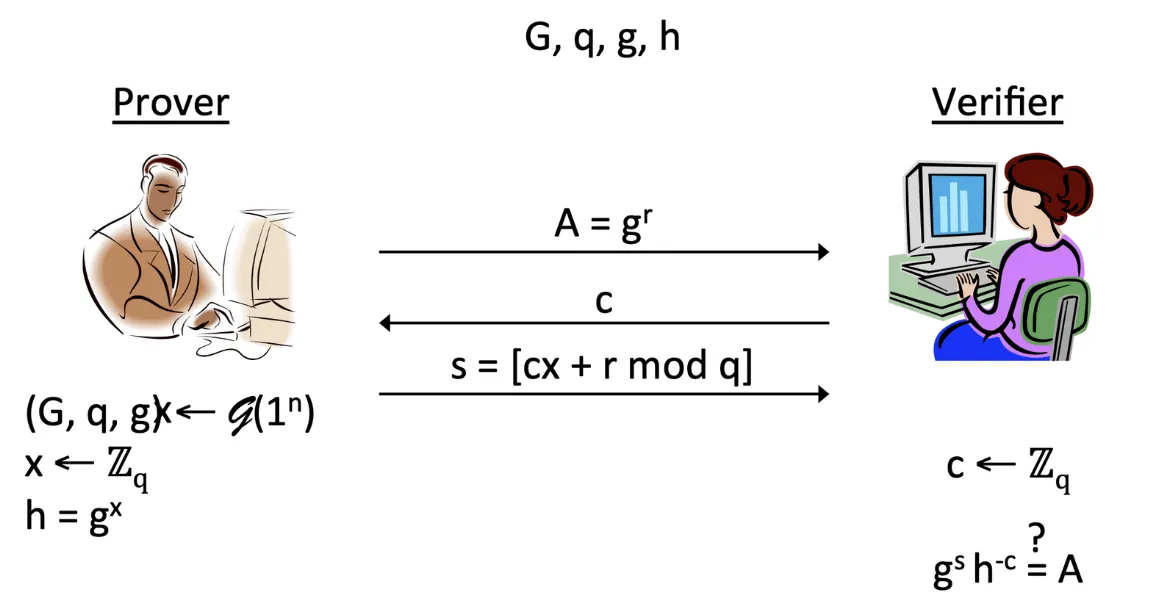
과정
- 먼저 prover가 Group-generation 알고리즘을 이용해 G와 q, 그리고 generator g를 생성한다. 그룹 내에 랜덤한 값 x를 뽑아 자신의 private key로 세팅한다. 그리고 h를 gx로 만들어, G, q, g, h를 public key로 만든다.
- 이제 interaction proof protocol을 본격적으로 진행한다. Verifier에게 (r은 랜덤한 값)을 전달한다.
- Verifier가 public key를 이용해 c를 랜덤하게 뽑고 prover에게 전송한다.
- 이를 받은 prover는 c와 자신의 private key, 그리고 메시지에 대한 정보 r을 이용해 서명 s를 만든다. 이때 s는 를 만족한다.
- s를 전송받은 verifier는 public key에 존재하는 g와 자신이 랜덤하게 준 값 c, 그리고 서명 s를 이용해 인증이 됐는지 확인한다. 이때 아래 식에 의해 가 성립해야 한다.
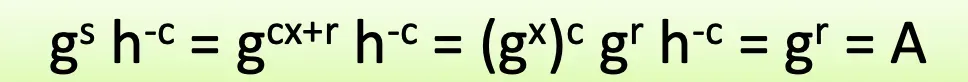
이제 해당 scheme을 Prover와 Verifier가 malicious한 경우를 가정해서 안정성을 증명해보겠습니다.
Prover가 malicious한 경우
이 그림은 증명자가 만약 비밀키 x를 모른 채로도 두 번의 서명 시도(Fiat-Shamir 변환에서 c와 c’ 두 가지 challenge에 대한 s와 s응답)를 통해 검증을 통과한다면, 이는 이산 로그 문제(DLP)를 풀 수 있음을 의미한다.
만약 악의적인 증명자가 와 라는 두 가지 유효한 등식을 만들어낼 수 있다면, 이 두 등식을 결합하여 이라는 관계가 성립하게 된다. 이 관계를 조작하면 결국 x를 알아낼 수 있는 수식이 도출된다. 따라서 만약 악의적인 Prover가 비밀키 x를 모르면서 검증을 통과한다면, 그들은 DLP라는 매우 어려운 암호학적 문제를 풀 수 있다는 것을 의미한다.
이는 현재까지 알려진 효율적인 방법이 없기 때문에, 이러한 상황은 발생하기 어렵다고 가정하며, 이는 곧 “증명자가 실제로 비밀키 x를 알고 있어야만 이 증명 과정을 성공시킬 수 있다”는 soundness(건전성)를 강력하게 뒷받침한다.
Verifier가 malicious한 경우
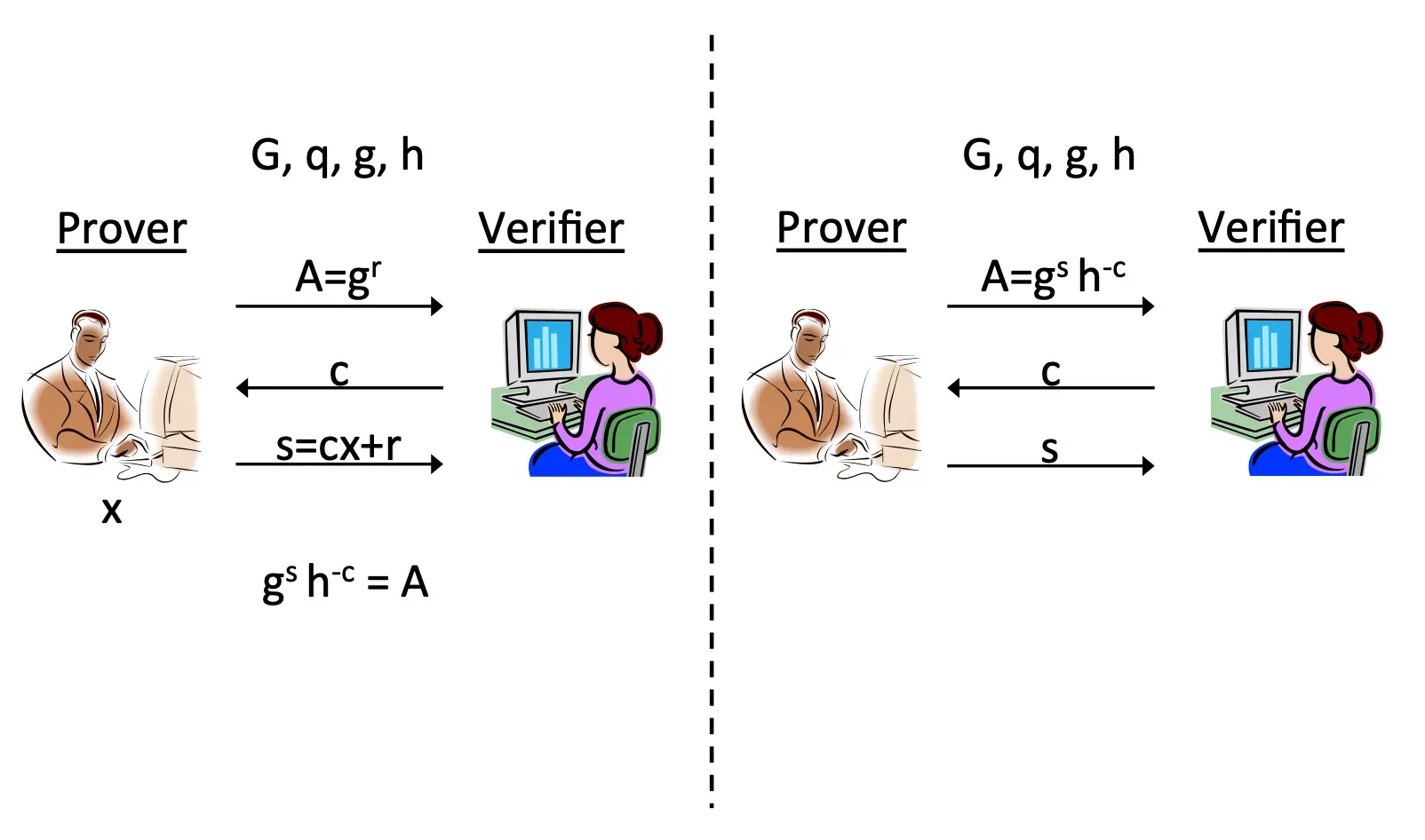
그림의 왼쪽은 정직한 증명자(Prover)와 정직한 검증자(Verifier) 간의 실제 프로토콜 상호작용을 나타낸다.
- 증명자는 자신의 비밀키 x와 랜덤 값 r을 사용하여 첫 메시지 를 계산하여 검증자에게 보낸디.
- 검증자는 이에 대한 무작위 도전값(Challenge) c를 생성하여 증명자에게 보낸다.
- 증명자는 이 c와 자신의 비밀키 x, 그리고 r을 사용하여 응답 를 계산하여 보낸다.
- 검증자는 최종적으로 가 성립하는지 확인한다 (여기서 는 증명자의 공개키이다).
이제 그림의 오른쪽은 공격자(악의적인 검증자)가 증명자의 비밀키 x를 전혀 모르는 상태에서 transcript를 스스로 시뮬레이션하는 과정을 보여준다. 여기서 중요한 점은, 공격자는 x를 모른 채로도 다음 순서로 값을 생성한다.
- 먼저, 공격자는 도전값 c를 에서 균등하게 선택하고, 응답 값 s 또한 에서 균등하게 선택한다.
- 그런 다음, 이 두 값을 사용하여 프로토콜의 첫 메시지 A를 로 역으로 계산한다.
오른쪽에서 공격자가 임의로 만들어낸 (A,c,s) 세 값의 transcript는 왼쪽에서 정직한 증명자와 검증자가 실제로 상호작용한 (A,c,s) transcript와 동일한 분포를 가진다.
- 도전값 c: 왼쪽과 오른쪽 모두에서 Zq에서 균등하게 분포하는 무작위 값
- 응답 s
- 오른쪽에서는 s를 직접 에서 균등하게 선택
- 왼쪽에서는 인데, r (첫 메시지 A를 만들 때 사용한 랜덤 값)이 에서 균등 분포를 따르는 무작위 값이므로, 결과적으로 s 또한 에서 균등 분포를 따르게 됨 (이산 로그 그룹에서 랜덤 값을 더하거나 곱해도 균등 분포는 유지됩니다.)
- 첫 메시지 A: c와 s의 분포가 같으므로, 이들로부터 계산되는 A의 분포도 결국 동일
이 결론이 의미하는 바는 매우 중요하다.
만약 공격자가 비밀키 x를 전혀 모르는 상태에서 정직한 프로토콜과 구별할 수 없는 성공적인 transcript를 스스로 생성할 수 있다면, 이는 공격자가 프로토콜의 정직한 실행을 관찰하거나 수동적으로 도청하더라도 비밀키 x에 대한 어떠한 정보도 추가적으로 얻을 수 없다는 것을 의미한다. 검증자는 프로토콜을 관찰함으로써 얻는 정보가, 자신이 x 없이 임의로 생성할 수 있는 정보와 동일하기 때문이다.
따라서 이 그림은 Schnorr Identification이 zero knowledge(영지식성)이라는 강력한 보안 속성을 가지고 있음을 증명하는 핵심적인 개념이며, 이는 비밀 정보를 노출하지 않고도 신원을 증명할 수 있게 해주는 기초가 된다.
이러한 Schnorr Identification scheme에 Fiat-Shamir transform을 적용하면 Schnorr Signature scheme이 된다.
Security
이 내용을 바탕으로 security를 정의하면
- 만약 이산 로그 가정(DLP)이 성립한다면, Schnorr 식별 스킴은 수동적 공격에 대해 안전하다.
그리고 해당 scheme에 Fiat-Shamir 변환을 적용하면(identification을 signature로 변환)
- 만약 이산 로그 가정이 성립하고, H가 랜덤 함수로 모델링된다면, Schnorr 서명 스킴은 안전하다.
