[스터디/세미나] Java의 미래 Virtual Thread

이번 글에서는 Java의 21 부터 (19부터 preview feature)로 추가된 Virtual Thread에 대해서 알아보겠다.

최신 언어들은 Goroutine 이나 Conroutine 같은 경량 쓰레드 모델을 제공해서, 같은 쓰레드 상황에서 더 높은 처리량을 지원하고 잇다.

자바도 Virtual Thread라는 이름으로 공식 출시가 되었다.
개발 초창기에는 Fiber이라는 이름과 Virtual Thread라는 이름 중에 무엇으로 할지 고민이 있었던것 같다.
왜 Fiber일까? Thread는 영어로 하면 "실"이다. 아마 Thread 자체가 경량 process 느낌으로 태어났기 때문에 더 얇은 "실"로 이름을 지었을 것이다. Virtual Thread가 이 Thread보다 더 가벼운 경량 쓰레드로 설계가 되었기 때문에, 실보다 더 얇은 "섬유"라고 이름 지으려고 하지 않았나 싶다.

뭐가 좋은지 한번 보자
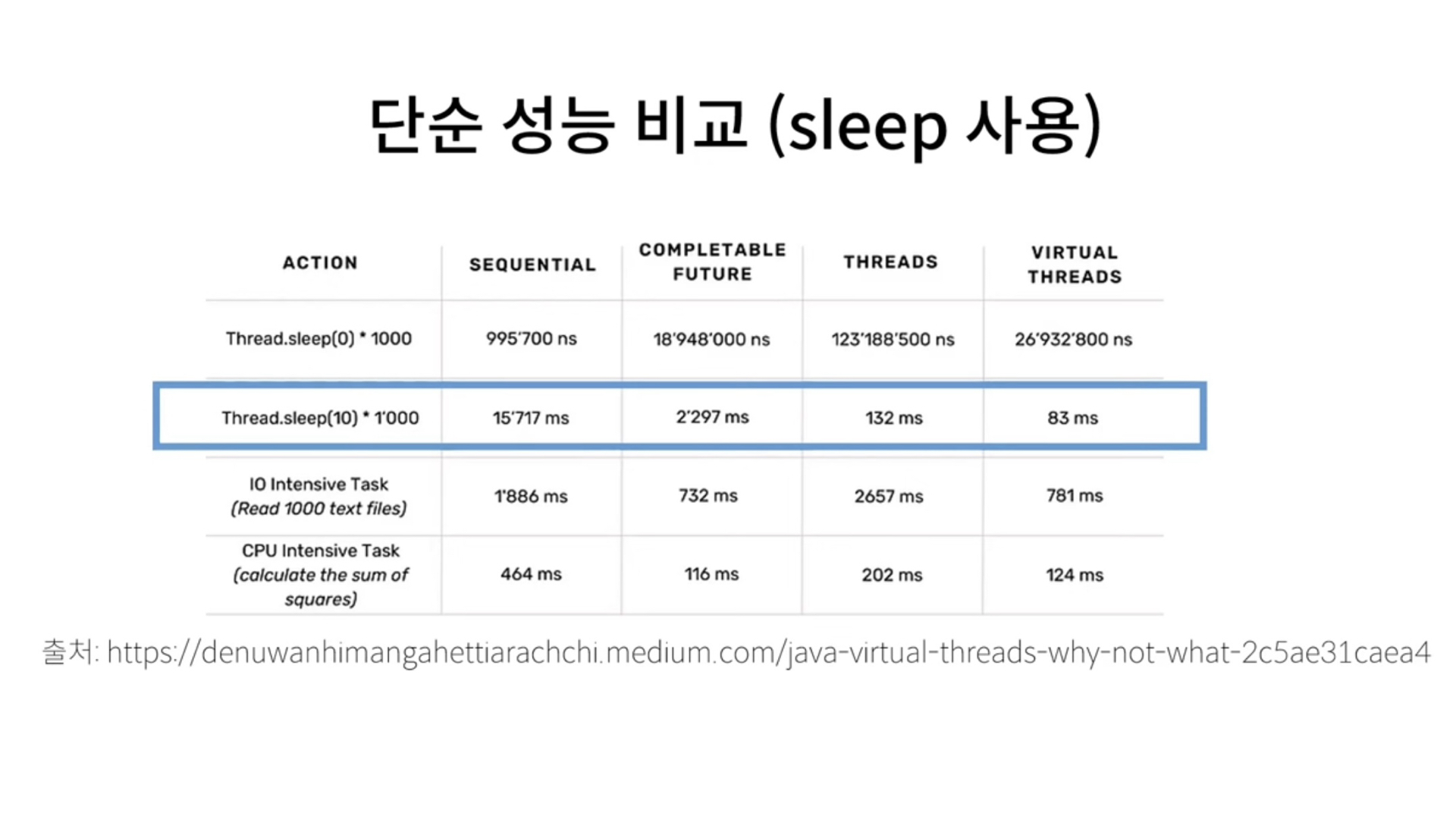
이 표를 보면, Thread Sleep 작업에 대해 여러가지 상황에서 실행한 결과를 보여주고 있다. 보면 알겠지만 Virtual Thread가 압도적으로 성능이 높다.
중요한 것은 같은 작업을 같은 머신에서 돌리는데, 성능이 이렇게 차이 난다는 것이다.
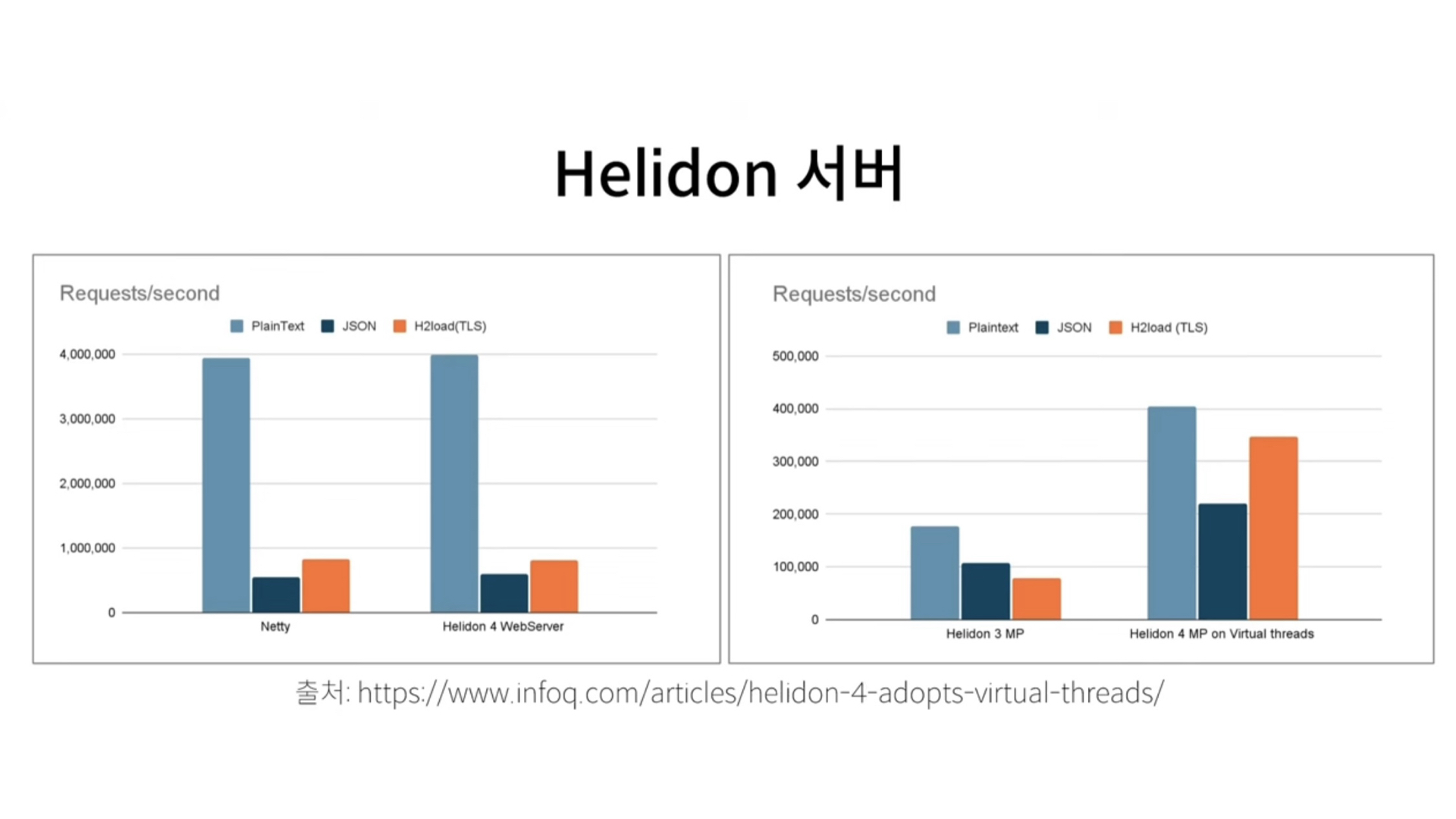
오른쪽 차트를 보면, Virtual Thread를 사용한 것이 거의 두배 정도 처리량이 높은 것을 볼 수 있다.
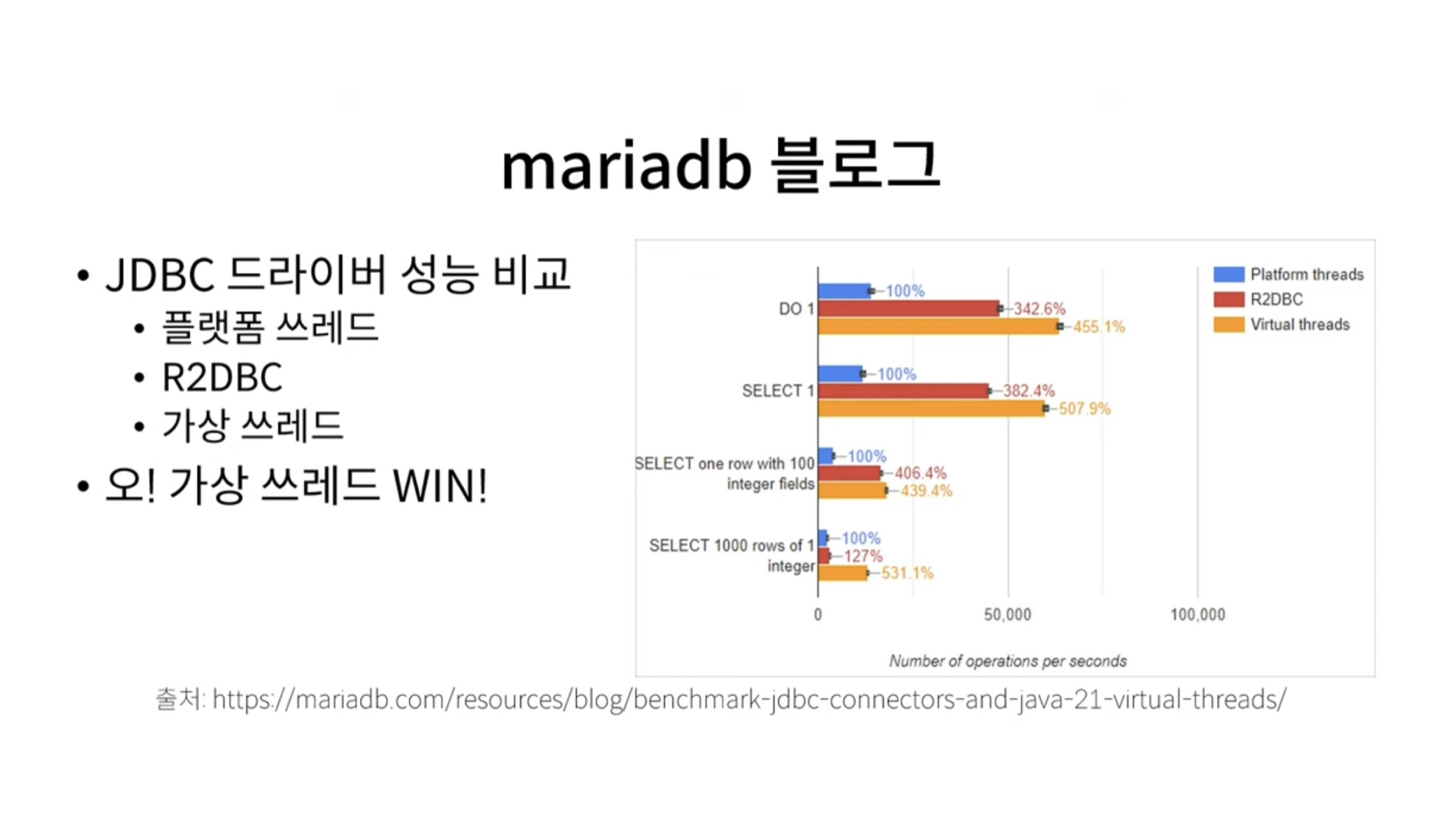
또 데이터베이스 접근도 r2dbc 보다 훨씬 좋은 성능을 보여주고 있다.

조금 이따 말하겠지만, io작업이 적은 cpu위주의 작업의 경우 효과가 없다고 알려져 있지만, 가상쓰레드를 사용한 경우 platform thread(운영체제 쓰레드)의 수가 훨씬적게 생성된 것을 볼 수 있다.
쓰레드의 경우 메모리가 많이 드니(상대적으로) 어느정도는 Cpu 위주의 작업에도 효과가 있다고 볼 수 있지 않을까 싶다.

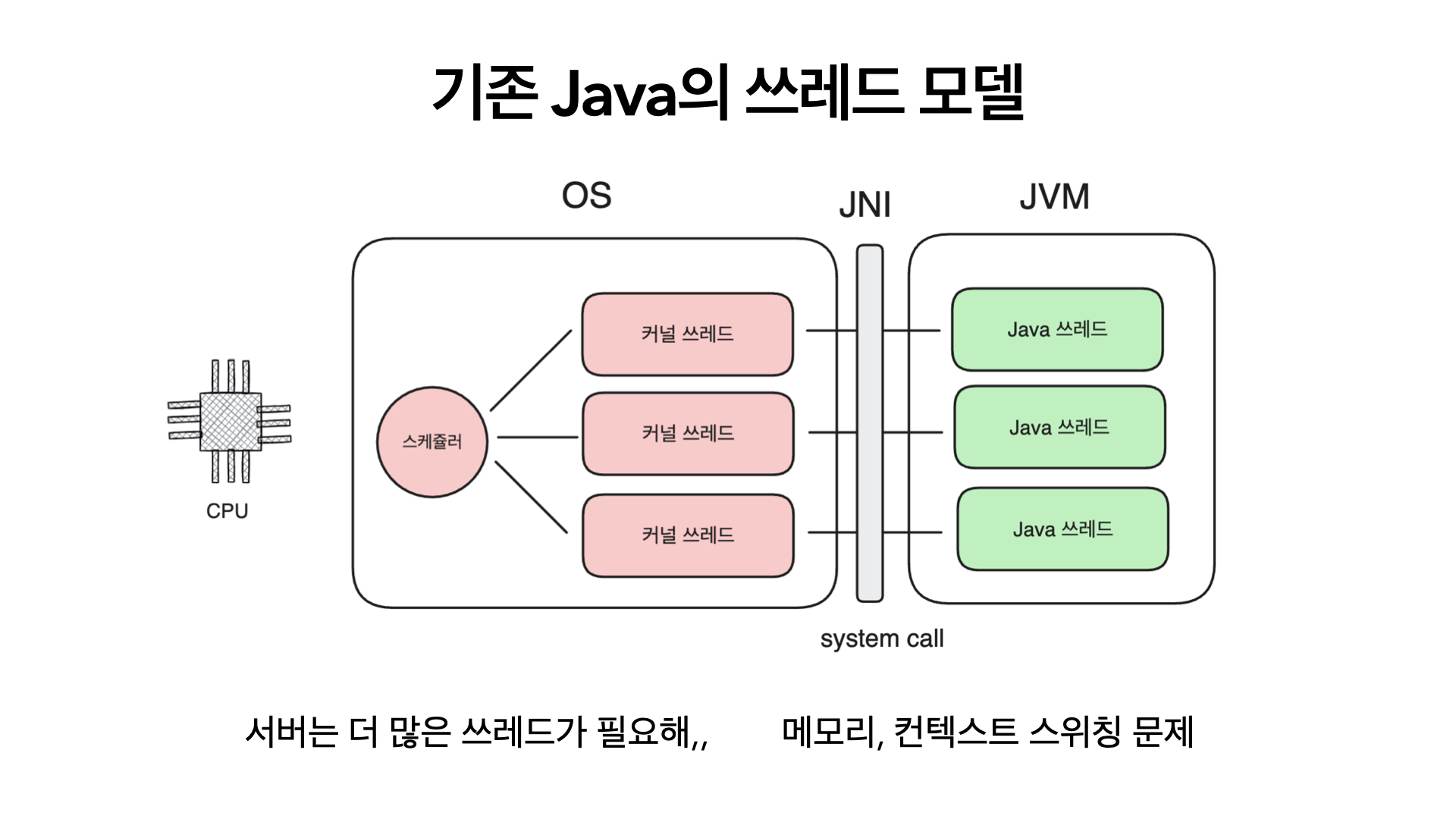
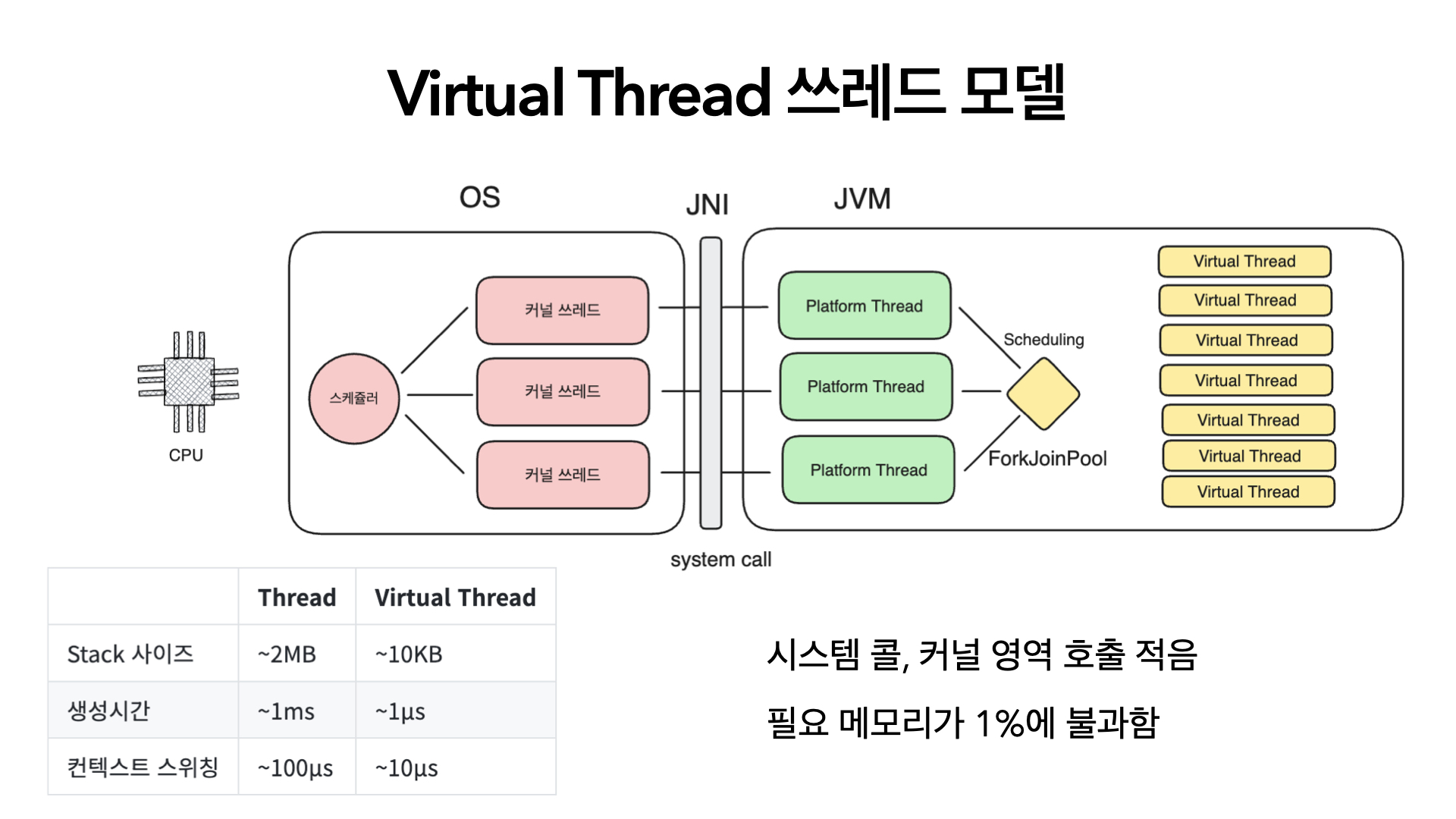
기존의 자바 쓰레드 모델이다. Java Thread와 시스템 쓰레드가 1 대 1 로 매핑된 것을 볼 수 있다. 즉 Java Thread는 시스템 쓰레드를 매핑하는 매핑 객체인 것이다.
그리고 이 쓰레드의 스케쥴링은 운영체제의 스케쥴러가 담당하고 있다.
당연히 운영체제의 스케쥴링은 시스템콜과 인터럽트 등의 작업을 포함하므로, context switching 비용이 들게된다.
가상 쓰레드를 사용할 때는 어떻게 될까?
우선 가상 쓰레드는 시스템 쓰레드에 1대1로 매핑 되지 않는다. 그러면 어떻게 할까?
바로 ForkJoinPool 과 같은 스케쥴러가 스케쥴링을 하는 것이다.
위 그림에서 초록색으로 된 쓰레드 매퍼(이해가 쉽게 이렇게 표현)에 어떤 virtual Thread를 매핑할지를 JVM 내부의 스케쥴러가 스케쥴링하게 된다.
핵심은 뭘까?
- virtual thread의 수가 많아도 운영체제 쪽의 쓰레드를 많이 생성할 필요가 없다
- 스케쥴링을 JVM 내부에서 처리한다.(물론 커널 쓰레드간, 프로세스간 스케쥴링은 존재하며 운영체제가 담당한다)
이 두개의 특징으로 인해 가상 쓰레드는 스택 사이즈나 생성시간, 컨텍스트 스위칭 등의 비용이 압도적으로 낮다.
만약 쓰레드를 8개 까지만 생성할 수 있는 컴퓨터라고 해도 가상 쓰레드는 이론상 무한대(메모리만 받쳐준다면)로 만들 수 있다.

실제로 디버깅을 해보면, Virtual Thread안에는
- 스케쥴러에 대한 참조
- 실제로 실행할 람다식
- 현재 배정된 쓰레드 매퍼(본인표현)
상태를 가지고 잇다.
어떻게 처리될까?
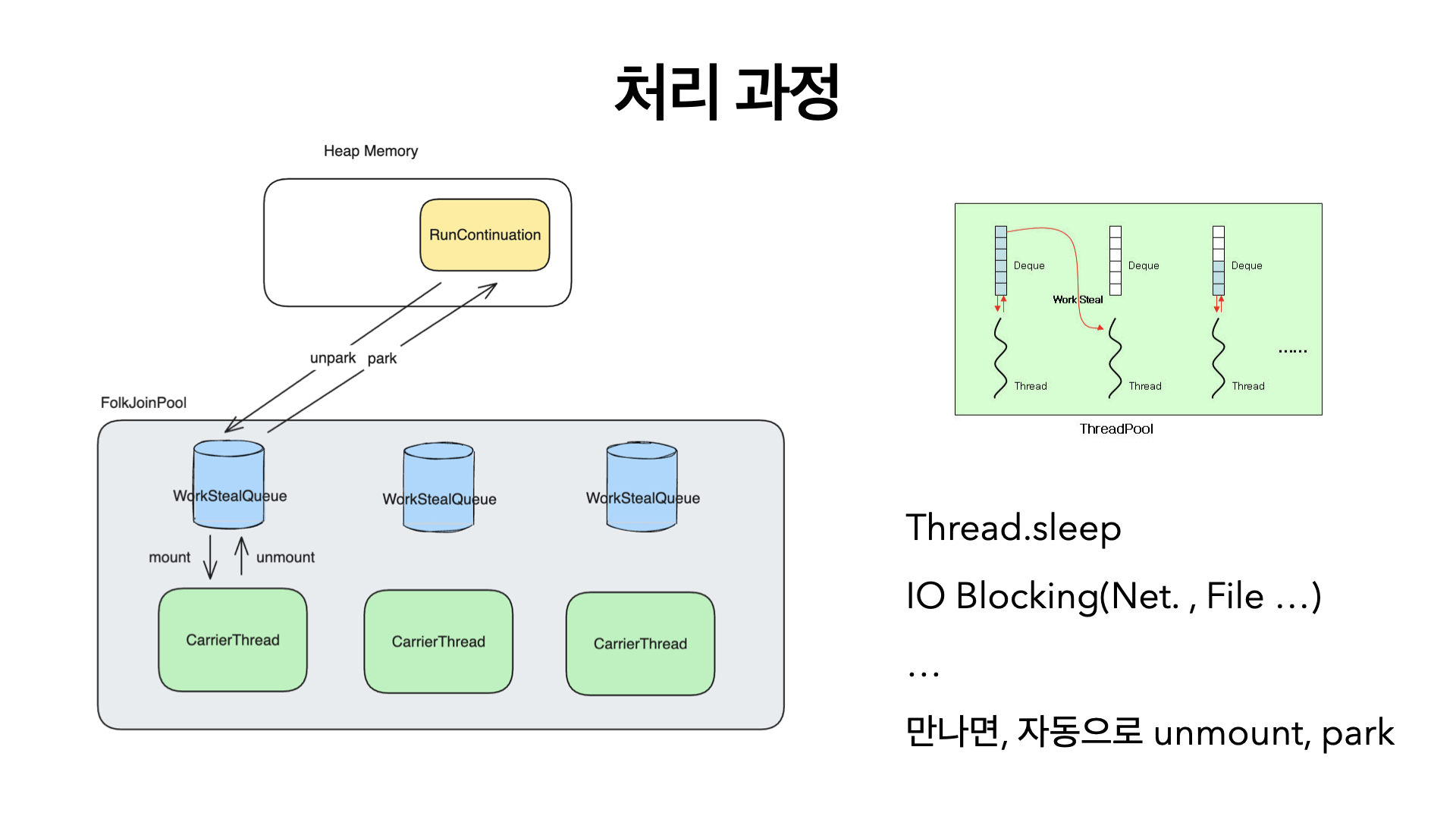
일단 work stealing queue에 대해 알 필요가 있다.
아주 쉽게 설명하면 deque다.
오른쪽 그림을 보면, 두번째 쓰레드는 현재 할 일이 없다. 그러면 어떻게 해야할까? 옆쪽에 있는 큐에서 일을 "훔쳐"오는 것이다.
근데 왼쪽 녀석이 큐의 머리 부분에서 꺼내는데, 훔치는 녀석도 앞에서 꺼낸다면, race condition이 발생하지 않겠나? 그러니까 deque 자료구조를 활용해서 훔칠땐 꼬리에서 꺼내는 것이다. 그러면 경쟁 조건이 완화된다.
아무튼 가상쓰레드의 실행정보 쉽게 말해 람다식와 상태들은 heap 메모리에 저장된다. 그러다가 unpark가 되게 되면 work stealing queue에 들어가게 되고, 쓰레드에 의해 work stealing 방법으로 처리되게 된다.
그러면 누가 이걸 꺼내는가,
이번에 virtual Thread이 도입되면서 java api의 상당수가 구현이 변경되었다. 사용법 자체는 동일하지만, 내부적으로 virtual thread인지 instanceof 검사를 하고, virtual thread라면, 현재 배정된 쓰레드에서 unmount하는 작업을 하게 된다. 대표적으로 sleep이나 네트워크, 파일 io등이 그렇다.
(시간이 다 되면 꺼내지는지는 잘 모르겠다. 꺼내져야할거 같은데)
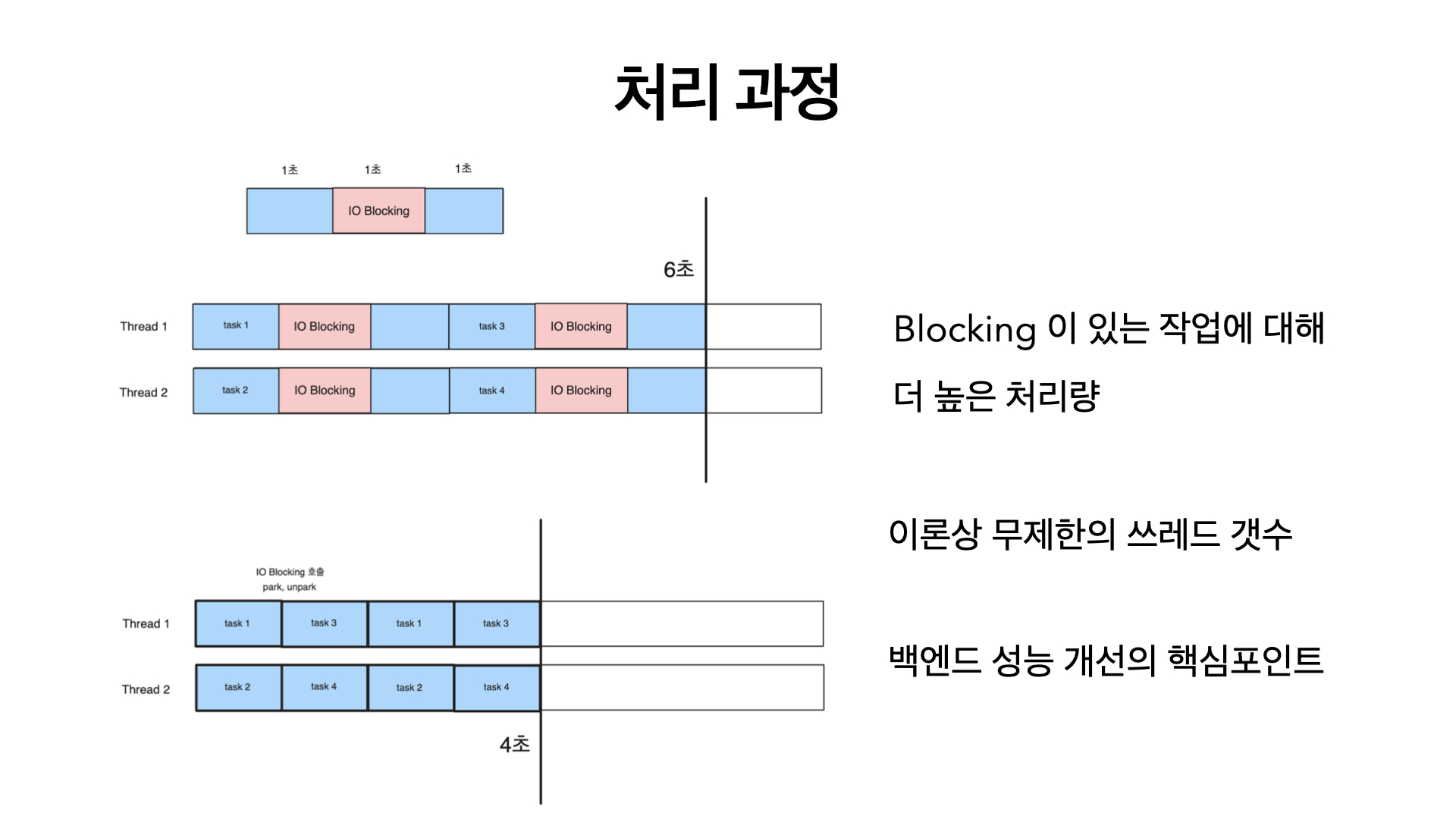
그러면 어떻게 될까? 대략적으로 모식도를 그리면, 위와 같다.
쓰레드 갯수가 두개 밖에 안되는 컴퓨터에 위와 같은 작업이 있다고 해보자. 전형적인 서버의 처리 작업이다.
가상쓰레드를 사용하게 되면, 아래와 같다. io작업동안에 쓰레드를 점유하지 않는다. 심지어 다른 가상쓰레드 작업에 양보하게 된다.
이게 바로 가상쓰레드의 성능향상에 핵심 포인트다.

아니다. 그게 Java Virtual Thread의 강점이 아닌가 싶다.
생각해봐라 이 경량 쓰레드 기능이 Ja routine이라는 이름으로 출시되고, 그 Ja routine을 사용해야만 돌아갔다면?...
기존의 코드를 싹 갈아 엎어야 할 것이다.
Java는 그렇게 처리하지 않았다.

위에서 설명했다 싶이 java는 기존 api의 인터페이스를 유지하면서도 내부 구현을 변경시켰다.
행동의 책임이 객체에 있고, 인터페이스로만 통신하고, 그 내부의 구현을 인식할 필요가 없는 객체지향의 강력함을 언어 수준에서 증명했다고 할 수 있다.
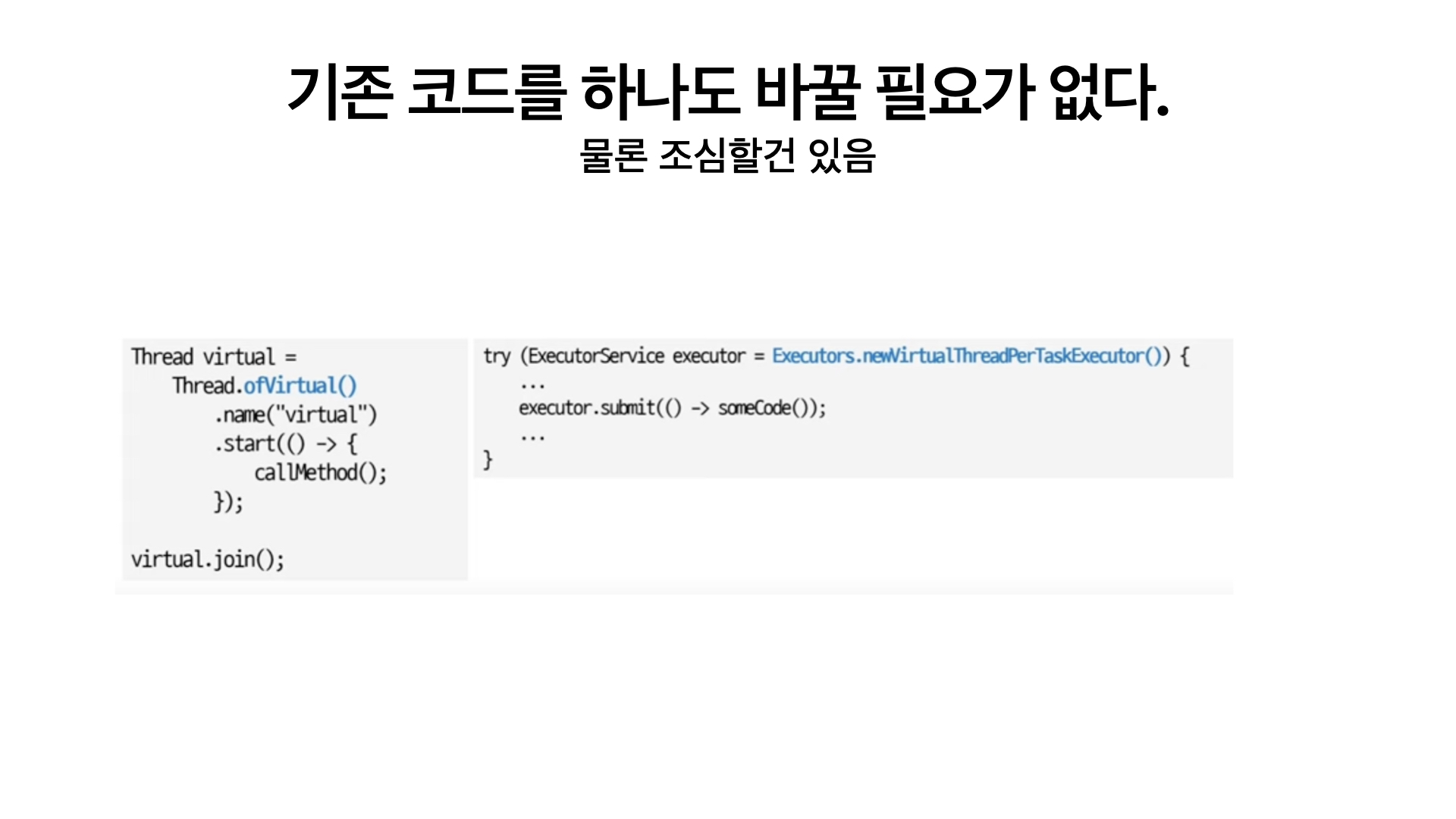
위는 사용하는 방법을 보여주는데, 핵심은 Virtual Thread도 Thread고 Virtual Thread 기반 쓰레드 풀도 ExecutorService에 받아진다는 것이다.
바로 다형성... Java 스럽게 잘 풀어냈다.

스프링 부트도 3.2부터 지원을 시작했다. 참고로 내 기억이 맞다면 3.2부터는 jdk17부터 지원하는 것으로 알고 있다. 버전이 많이 차이나는 경우 슬슬 버전업을 시도하는 것이 좋겠다.
여담이지만, 3.2에 유용한 기능이 많이 들어왔다. WebClient같은 선언형 Http 에이전트가 mvc 진영에도 생겼고, database 커넥션 같은 커넥션이 추상화 되어서 여러 꿀 기능도 사용할 수 있다.


Io가 많은 작업이다. 또, 각 작업이 비교적 가볍고, 이게 쓰레드를 활용해서 병렬적으로 처리되는 작업에 도움이 된다.
생각나는게 없는가? 그렇다 딱 서버다. 서버 그 자체이다.
서버는(spring servlet mvc) 기준 thread per request 모델로 여러 요청을 동시에 처리하고 서버의 작업은 주로 db 연결이나, 외부 서비스 호출을 포함한다(네트워크).
서버 분야에서 많이 사용되는 Java에 이 기능이 더 돋보일 수 있는 이유다.


21 기준으로(추후에는 개선될 수도) 두가지 상황에서 Pinned 상태가 걸린다.
다행히 이런 pinned 상태가 생기면 로그에 찍힌다.
그리고 지금 주요 라이브러리들이 이 pinned상태에 대응하기 위해 synchronized 블록을 빠르게 지우고 수정하고 있다. 아마 조만간 수정본을 볼 수 있을 것이다.

또 ThreadLocal도 주의해야한다.
ThreadLocal은 내부적으로 map과 비슷한 자료구조를 가지고 쓰레드마다 컨텍스트를 저장하는데
가상쓰레드는 이론상 무한히 만들 수 있기 때문에, 과도하게 Thread Local을 사용하면 메모리가 터질 수도 있다고 한다.
FAQ
발표중 있었던 잦은 질문들
- 코틀린의 코루틴보다 좋나요?
그렇다. 코틀린의 코루틴은 Jvm은 그대로이고 컴파일러가 컴파일 단계에서 코드를 변조하면서 이러한 작업이 가능하게 한다. Virtual Thread의 경우 JVM 단에서 처리가 된다.
- WebFlux 공부할 필요가 없나요?
참 계륵같은 존재. 어렵긴 하지만 또 적절한 상황이면 유용한 WebFlux
내 생각에는 만약 WebFlux 사용 목적이 Io에 대응한 처리량 증대에 목적이 있다면, 아마 사용되지 않을 것이다.
하지만 WebFlux와 reactive 프로그래밍 모델은 단순히 비동기 이벤트 루프에만 그 의의가 있지 않다.
예를 들어 SSE나 Websocket 또 특정 이벤트 스트림에 반응하는 처리(윈도잉, delay 등) 등 이 리액티브 프로그래밍이 빛을 바라는 분야가 분명히 있다.
그래서 api 나 서비스가 리액티브하다면 고려해볼만 한것 같다. (공부해보면 확실히 매력적이다.)
실제로 spring boot 3.2부터는 spring cloud gateway가 webflux기반이 아니라 mvc servlet기반으로도 제공이 된다.(안정화 되었는지는 확인 안해봄)
