개발 용도로 하나의 서버에 hadoop cluster를 구축하였습니다.
그 와중에 시행착오를 많이 겪어서 추후 참고할 수 있게 포스팅 합니다.
참고로 AWS를 활용하는 분들을 위해 조언하자면, EC2 t2.micro 기준 설치는 되나, map reduce 를 실행시키면, 서버가 거의 멎는다. (ssh 접속도 안된다.) 조금 더 넉넉한 인스턴스를 선택해야할듯
구성 환경
나의 경우, 개인 집에 있는 홈서버에 구성을 하였다.
- cpu 6코어, 16gb 메모리
- hadoop 3.1.3
- java - OpenJDK 11, 17
1. 인바운드 포트 설정
하둡 노드들 끼리 통신을 하기 위해서는 인바운트 포트를 열어 줘야한다.
참고로, hadoop 3과 2는 포트가 꽤 다른것 같다. 아래는 3 기준 포트이다.
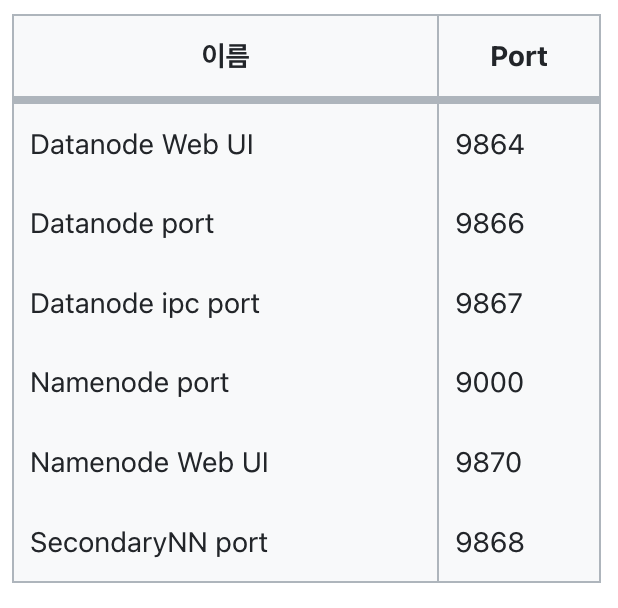
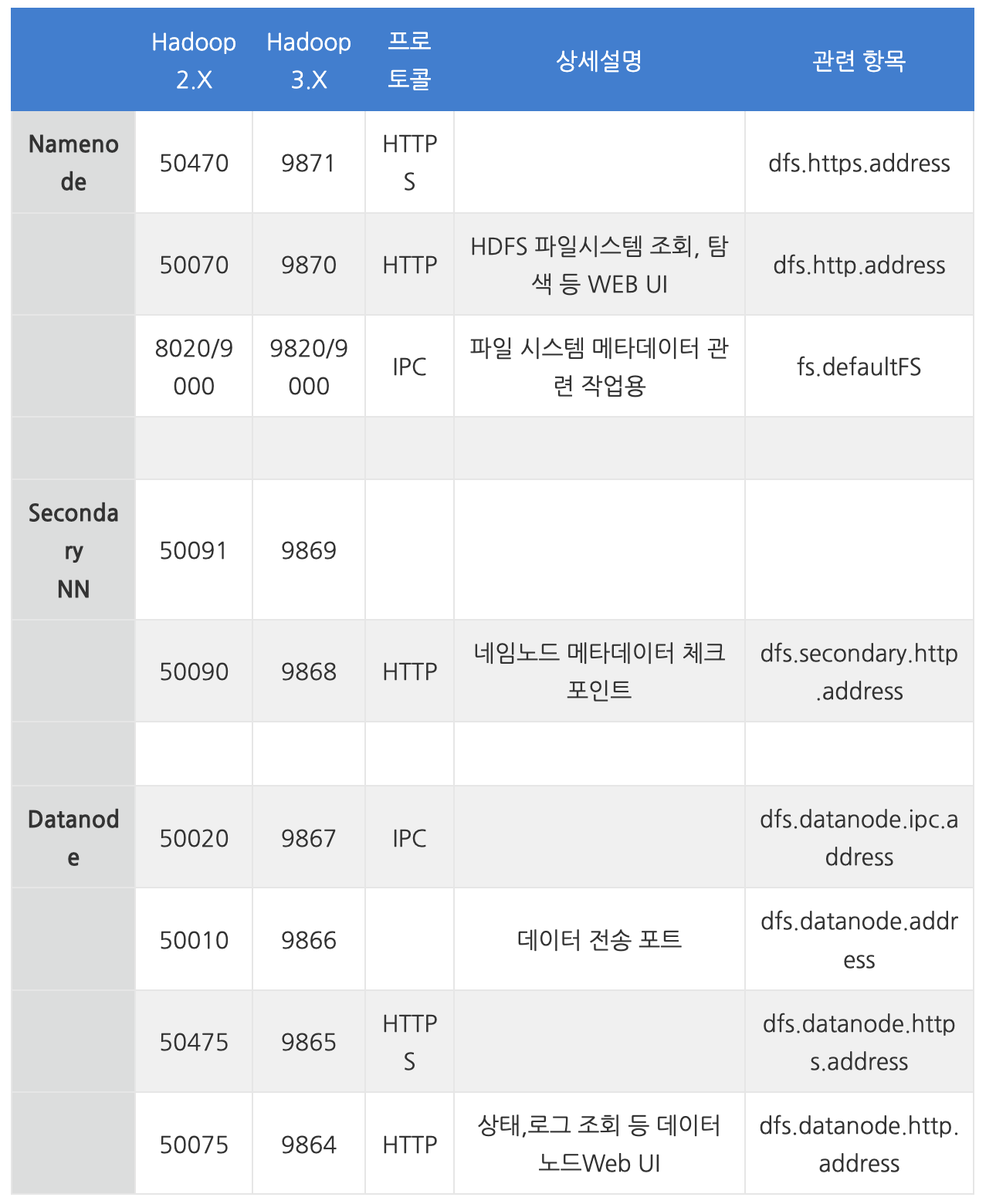
aws의 경우 보안 그룹을 통해 인바운드 포트를 열어 줘야하고, 나와 같이 홈서버로 돌리는 경우, 포트포워딩 같은 설정을 해주어 외부에서 필요한 포트에 들어올 수 있게 설정해주어야 한다.
2. Java
JAVA의 경우, 8,11,17이 가능한 것 같다.
나의 경우 설치할 때는 11로, 현재는 17로 돌리고 있는데, 그 이유는 spark가 17 이하 버전에서 추가적인 설정이 필요하다고 들어서 그렇다.
$ sudo apt install openjdk-11-jdk
$ sudo vim ~/.bashrc
=====
# bashrc 파일 안에 아래 내용을 작성
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export PATH=$PATH:$JAVA_HOME/bin
=====
$ sourve ~/.bashrc
# 자바가 잘 설치되었는지 자바 버전 확인
$ java --version3. Hadoop
3-1. 하둡 설치
하둡 설치의 경우, 원하는 버전을 다운로드 받으면 된다.
# hadoop 다운로드
$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.4/hadoop-3.2.4.tar.gz
# 압축파일 풀기
$ tar xvzf hadoop-3.2.4.tar.gz
# 이름 변경
$ mv hadoop-3.2.4 hadoop
# 설치 파일 삭제
$ rm hadoop-3.2.4.tar.gz
$ sudo vim ~/.bashrc
=====
# bashrc 파일에 아래 내용을 작성
# hadoop
export HADOOP_HOME=/home/ubuntu/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HADOOP_HOME/etc/hadoop
# hadoop user
export HDFS_NAMENODE_USER=유저이름
export HDFS_DATANODE_USER=유저이름
export HDFS_SECONDARYNAMENODE_USER=유저이름
export YARN_RESOURCEMANAGER_USER=유저이름
export YARN_NODEMANAGER_USER=유저이름
=====
$ source ~/.bashrc하둡에서 사용하는 환경 설정을 설정하는 부분이다.
3-2. ssh 설정
원래 분산 모드에서는 서버간 통신이 가능하도록 ssh 키를 공유하는 작업이 필요하다.
하지만 하나의 서버에서 돌릴때는, 쉽게 말해 ssh 를 localhost로 시도한다고 보면 된다.
최종적인 목표는 비밀번호를 입력하지 않고, ssh로 localhost가 접속이 가능하면 된다.
- keygen으로 생성하던지
- ssh config를 가지고 설정을 해두던지
localhost나 자기 자신의 호스트로 비밀번호 없이 ssh 사용이 가능하면 된다.
완료 되었으면, 한번 테스트를 해보자
ssh localhost3-3. 설정파일 설정
사실상 앞까지는 그냥 환경 설정이었고, 여기서 부터가 진짜 하둡 설정이다. 아래 설정파일을 설정해주어야 한다.
1. core-site.xml
2. yarn-site.xml
3. mapred-site.xml
4. hdfs-site.xml
5. workers(hadoop 3) || slaves(hadoop 2)
6. hadoop-env.sh
이러한 설정 파일들은 $HADOOP_HOME/etc/hadoop에 존재하고 있다.
이는 아까 우리가 설정해 두었던 HADOOP_CONF_DIR 환경변수와 동일하다.
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
</configuration>mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>\
</property>
</configuration>hdfs-site.xml
여기서 저 위에 두개는 실제로 데이터가 저장되는 곳이므로, 자유롭게 지정하고, mkdir로 무조건 폴더를 만들어주자.
3번째 설정은 namenode의 web ui로 사용되므로 참고하여 설정하자
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/유저이름/Project/hadoop/data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/유저이름/Project/hadoop/data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.http.address</name>
<value>localhost:9870</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>workers
localhost우리의 worker는 로컬호스트 밖에 없다.
hadoop-env.sh
값들은 각자 환경에 맞게
export JAVA_HOME=/usr/lib/jvm/default-java
export HADOOP_PID_DIR=/${HADOOP_HOME}/pids
export HADOOP_HOME=/home/유저명/Project/hadoop
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop포맷 후 실행
$ hdfs namenode -format
$ start-all.sh모두 잘 돌아가는지 확인해보자
$ jps
13128 NameNode
14073 NodeManager
13307 DataNode
69037 Jps
13518 SecondaryNameNode
13743 ResourceManager이렇게 모두 뜨지 않는 경우가 있는데 나의 경우
- namenode, datanode -> 포맷을 두번 한 경우, data 저장 폴더를 완전히 지웠다가 다시 만들고 포맷을 한다.
- 무언가 뜨지 않는다. -> $HADOOP_HOME/logs 에 .log 파일들을 살펴보면, 로그가 남겨져 있다. 어떤 예외가 던져졌는지 확인해본다.
