해시함수란?
해시함수는 임의의 길이의 데이터를 고정된 길이의 데이터 로 매핑하는 함수를 말한다.
이 함수를 통해 얻어지는 값을 해시 코드라고 한다.
쉽게 말해 아무리 큰 숫자를 넣더라도 정해진 크기의 숫자가 나오는 함수이다.
해시코드는 원하는 데이터를 빠르게 찾기 위해서 사용합니다.
주민등록번호와 비슷한건가? 라고 생각 할 수 있다.
하지만 주의해야할 점은 해시코드는 중복이 될 수 있다는 것이다. (아래 설명)
또한 해시코드는 보통 입력의 범위보다 보통 작은 범위의 출력 범위가 나오므로
필연적으로 중복이 발생할 수도 있다. (입력보다 작은범위의 출력의 경우)
내가 조금 헷갈린 주의해야할 부분은 이 해시함수는 하나만 있는게 아니라는 점이다.
처음에는 해시코드를 메모리 주소로 잘못 착각해서
그러면 어떤 객체든 해시코드만 같으면 모두 같은 값인가 보다라고 생각했고,
마치 객체의 중복되지 않는 지문과 같은 개념으로 생각했다. 하지만 그 설명은 틀렸다.
나의 아래의 글을 읽으면 이해가 되겠지만,
즉 객체마다, 또는 쓰임세 마다 아주 다양한 해시함수와 해시코드가 각각 있다.
위의 설명은 단지 Object class 의hashCode()를 보고 잘 못 이해 한 것이다.해시함수는 매우 다양하고, 목적에 따라 정의 될 수 있다.
아래에 나오겠지만 String class의hashCode()는 같은 글자를 갖고 있으면
같은 hashCode를 반환한다. 객체의 메모리 주소가 다르더라도...
핵심은 이거다.
임의의 길이의 데이터를 고정된 길이의 데이터 로 매핑한다.
원하는 데이터를 빠르게 찾을 수 있다
해시함수의 사용
이러한 특성에 따라 다양한 목적에 맞게 설계된 해시 함수가 존재하며, 다양한 분야에서 사용된다.
- 자료구조
- 해시 테이블 (또는 해시 맵)
- 해시 셋
- 캐시
- 중복 레코드 검색
- 유사 레코드 검색
- 유사 부분 문자열 검색
- 기하학적 해시
- 변조 탐지/에러 검출
암호학적 해시 함수라는 것도 있는데, 이는 같은 입력값에 대해서는 같은 출력값이 보장되며,
이 값들은 가능한 고른 범위에 균일하게 분포하는 특성이 있다.
입력값이 조금만 변해도 결과가 크게 달라지는 특성을 갖도록 설계된다.
해시의 보안과 관련된 부분은 꽤나 흥미롭다.
나무위키 해시 문서에 4. 보안과 해시 부분을 읽어보는 것도 좋다.
해시충돌

출처: 위키피디아 - 해시함수
해시 함수는 보통 입력의 범위 보다 출력 값의 범위가 작으므로
서로 다른 입력값에도 동일한 출력이 되는 경우도 존재한다
이런 경우를 해시 충돌 이라고 한다.
헷갈리지 말하야 할 점은 이것은 설계상의 오류 일 수도 있지만,
설계 자체가 입력범위보다 출력 범위가 작으면 어쩔 수 없이 발생할 수도 있다는 점이다.
해시충돌 해결방법
개별 체이닝(Separate Chaining)
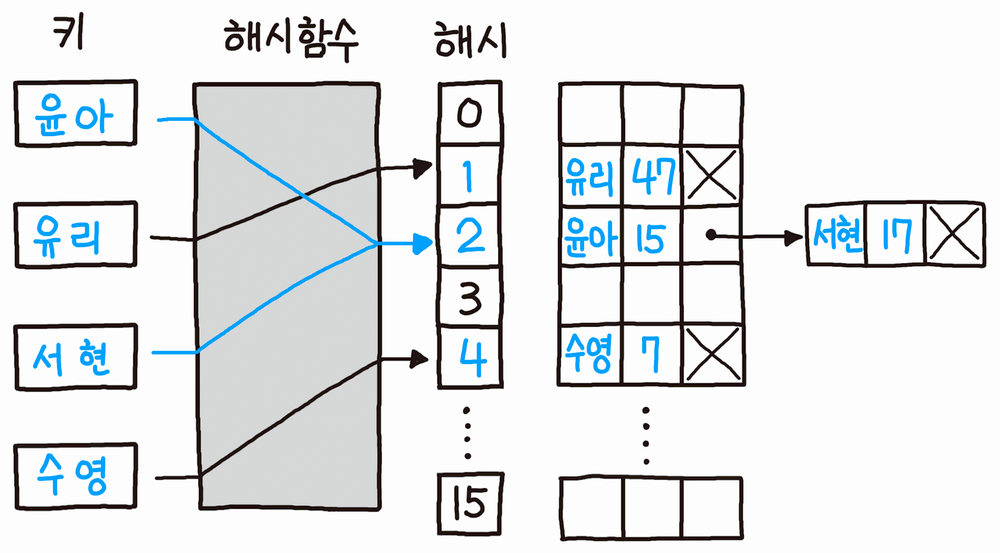
출처: https://namu.moe/w/%ED%95%B4%EC%8B%9C
이 방법은 충돌 발생 시 그림과 같이 리스트로 연결하는 방식이다.
기본적인 자료구조와 임의로 정한 간단한 알고리즘만 있으면 되기 때문에 인기가 높다.
원래 해시 테이블 구조의 원형이며, 가장 전통적인 방식이다.
흔히 해시 테이블을 말하면 이 방식을 말한다.
검색 시에는 해당 연결 리스트를 차례로 지나가며 탐색한다.
삽입의 경우는 해시 코드 값을 가지고 리스트에 저장만 하면 되기 때문에 O(1)의 시간 복잡도만 걸리지만,
탐색의 경우 연결 리스트를 모두 탐색해야 하므로 연결 리스트의 길이가 길어질 수록 효율적이지 못하다.
장점 : 간단한 구현
단점 : 리스트가 길어지면 탐색의 효율성 떨어짐
오픈 어드레싱(Open Addressing)
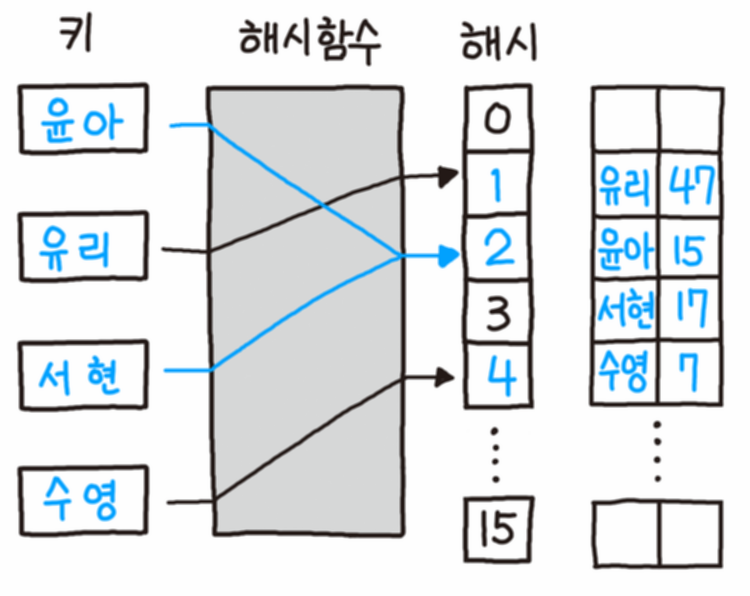
출처: https://namu.moe/w/%ED%95%B4%EC%8B%9C
이 방법은 충돌 발생시 탐사를 통해 빈 공간을 찾아 나서는 방식이다.
사실상 무한정 저장할 수 있는 체이닝 방식과 다르게,
전체 슬롯의 개수 이상은 저장 할 수 없다.
모든 원소가 자신의 해시값과 일치하는 추소에 저장된다는 보장이 없다.
위의 그림은 가장 간단한 선형 탐사(Linear Probiding)방식이며 해당 위치부터 순차적으로 탐사를 진행한다.
선형탐사는 간단하면서도 성능이 괜찮다.
이차원 탐사는 1^2, 2^2, 3^2... 같이 차수가 2인수 만큼 떨어진 영역에 데이터를 삽입하는 방식이다.
선형조사보다 넓은 범위를 가져서 검색에 효율적 일 수 있지만, 초기 해시값이 같은 경우 역시 계속 충돌이 발생 할 수 있다.
더블 해싱은 이러한 Secondary Clustering을 해결하기 위해 사용하며, 두개의 해시 함수를 사용하는 것이다.
JAVA의 hashCode()
Java에서는 HashMap이나 HashTable을 통해 자료를 저장할 때 활용하고 있다.
또 Object 클래스의 hashCode() 메서드는 객체의 동일성을 비교하기 위해 사용한다.
이해를 위해 예를 보겠다.
우리가 익숙한 Object 클래스에 hashCode() 메서드는 객체의 주소를 기반으로 해시 코드 값을 반환한다.
하지만 String 클래스의 hashCode() 메서드는 문자열을 기반으로 해서 해시 코드 값을 반환한다.
따라서 String 객체에서는 같은 문자열을 가진 String은 같은 해시코드를 갖게 된다.
하지만 Object 객체에서는 같은 주소를 가진 Object만이 같은 해시코드를 갖는다.
즉 객체에서 같은 객체라고 판단할 수 있는 기준을 hashCode()로 구현해주어야 한다.
JAVA의 hash() 메서드
JDK 1.8 부터 java.util.Objects클래스의 hash() 함수가 추가되었다.
아래의 두 함수는 기능이 별반 다르지 않다.
public int hashCode() {
return (name+age).hashCode();
}public int hashCode() {
return Objects.hash(name,age);
}아래의 방법을 권장한다.
잘못된 예시
class Card {
String name;
String number;
public Card(String name, String number) {
this.name = name;
this.number = number;
}
@Override
public String toString() {
return "Card{" +
"name='" + name + '\'' +
", number=" + number +
'}';
}
}이 객체는 Object클래스의 상속을 받으면서 toString() 메서드를 오버라이딩 해놓았다.
Set<Card> cardSet = new HashSet<>();
set.add(new Card("Hyundai","0000-0000-0000"));
set.add(new Card("Hyundai","0000-0000-0000"));만약 이런식으로 HashSet에 Card 객체를 넣으려고 하면 어떨까?
HashSet은 add시 중복을 허용하지 않음에도 불구하고 두 객체 모두 넣어진다.
그 이유는 Card class는 hashCode()를 오버라이드 하지 않았기 때문에,
Object 클래스의 hashCode()를 그대로 상속 받는다.
즉 메모리 주소값이 다름으로 다른 hashCode를 갖게 되고,
둘이 중복됬다고 판단하지 않는 것이다.
올바른 예시
class Card {
String name;
String number;
public Card(String name, String number) {
this.name = name;
this.number = number;
}
@Override
public String toString() {
return "Card{" +
"name='" + name + '\'' +
", number=" + number +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return number == person.number && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, number);
}
}이런식으로 hashCode() 와 equals()를 구현해주어야 한다.
이렇게 되면 HashSet에서 중복값이 정상적으로 처리되어서
같은 내용이 중복으로 들어가지 않는다.
hashCode() 와 equals()의 구현 이유
중요한 것은 여기 HashSet, HashMap, HashTable은 다음과 같은 방법으로 두 객체가 동등한지 비교한다.
1. hashCode()를 이용해서 해시 코드가 같은지 확인한다. 다르면 다른 객체로 판단하고, 같으면 다음단계로 넘어간다.
2. hashCode()에서 값이 같으면, equals()를 통해 동등 객체인지 판단한다.
즉 hashCode()가 다르면 equals()는 비교도 하지 않는다.
아래에서 자세히 다루겠다.
Java HashTable
equals와 hashcode 메서드를 이해 하기 위해 Java에서 HashTable이 작동하는 원리를 간단히 살펴보자.
(HashTable, HashMap, HashSet 모두 동작원리는 동일하다)
HashTable은 <key,value>형태로 데이터를 저장한다.
Key는 Hash Funtion(해시 함수)를 이용해서 해시 값을 만든다.
Value는 버킷에 담는데 , LinkedList를 이용해 리스트 형태로 담는다.
이는 위에서 설명한 해시 충돌을 해결하기 위해 Chaining을 사용한 것이다.
(* 참고로 java8인가 9버전부터 LinkedList 아이템의 갯수가 8개 이상으로 넘어가면 TreeMap 자료구조로 저장된다고 한다.)
HashTable에 put 메서드로 객체를 추가하는 경우
값이 같은 객체가 이미 있다면(equals()가 true) 기존 객체를 덮어쓴다.
값이 같은 객체가 없다면(equals()가 false) 해당 entry를 LinkedList에 추가한다.
HashTable에 get 메서드로 객체를 조회하는 경우
값이 같은 객체가 있다면 (equals()가 true) 그 객체를 리턴한다.
값이 같은 객체가 없다면(equals()가 false) null을 리턴한다.
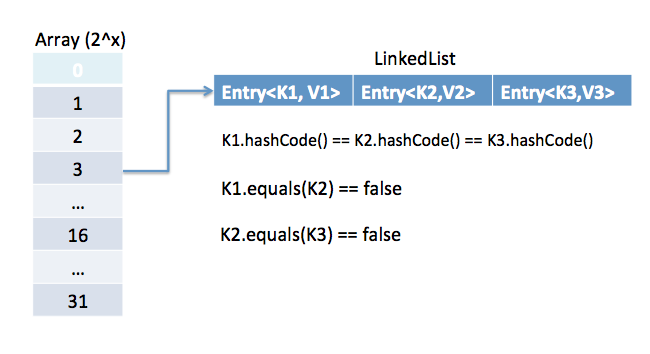
위를 보면 세 객체 모두 같은 해시값을 갖는다. 하지만 그 후 실행된 equals()메서드에 의해 값이 다른 객체라고 판단된다.
따라서
만약 equals hashCode중 하나만 구현하거나 둘다 구현하지 않을경우 적절한 구현이 되지 않는다.
마무리
여러분에게 많은 도움이 되셨길 바라며, 저 또한 정리하며 많은 도움이 되었습니다.
출처
https://jisooo.tistory.com/entry/java-hashcode%EC%99%80-equals-%EB%A9%94%EC%84%9C%EB%93%9C%EB%8A%94-%EC%96%B8%EC%A0%9C-%EC%82%AC%EC%9A%A9%ED%95%98%EA%B3%A0-%EC%99%9C-%EC%82%AC%EC%9A%A9%ED%95%A0%EA%B9%8C
https://namu.moe/w/%ED%95%B4%EC%8B%9C
https://brunch.co.kr/@purpledev/16
