Postgresql 의 MVCC, Vacuum에 대해 알아보자
동시성 제어(Concurrency Control)
MVCC 를 설명하기 전에 간단하게 동시성 제어를 짚고 가자면
동시성 제어란?
동시성 제어란 DBMS가 다수의 사용자 사이에서 동시에 작용하는 다중 트랜잭션의 상호간섭 작용에서 Database를 보호하는 것을 의미한다.
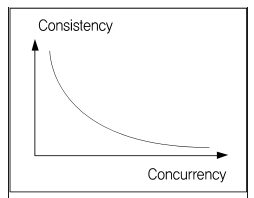
일반적으로 동시성과 일관성은 반비례 관계를 가지고 있다.
동시성 제어 분류
낙관적 동시성 제어
- 사용자들이 동시에 같은 데이터를 수정하는 경우가 적을 것으로 가정
- 락을 걸지 않고, 수정 반영 시점에 값이 변경되었는지 검사
비관적 동시성 제어
- 동시에 같은 데이터를 수정할 것이라고 가정
- Lock을 걸고 동시수정을 명시적으로 막음
- 동시성이 비교적 떨어짐
공유락과 배타락
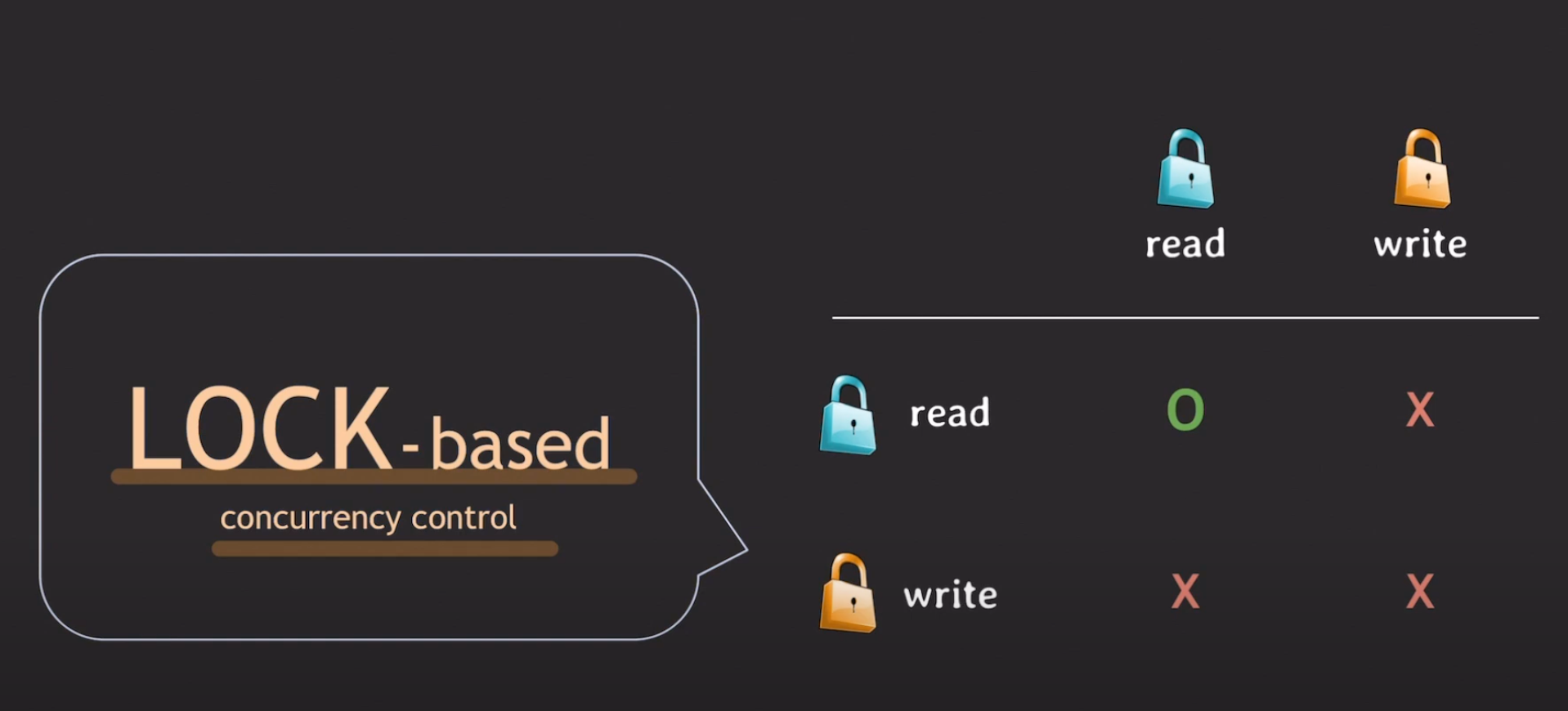
비관적 동시성 제어를 위한 대표적인 방법으로 Lock이 있는데, 여기에는 두가지 종류가 있다
- 공유락:Shared Lock:읽기 잠금
- 배타락:Exclusive Lock:쓰기 잠금
출처 : https://www.youtube.com/watch?v=wiVvVanI3p4&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=20
공유락이 걸린 경우
- 다른 트랜잭션이 공유락을 가져갈 수 있다.
- 다른 트랜잭션이 배타락을 걸 수 없다. 기다려야한다.
배타락이 걸린 경우
- 다른 트랜잭션이 공유락을 걸 수 없다.
- 다른 트랜잭션이 배타락도 걸 수 없다.
락 기반 동시성 제어의 문제점
- 읽기와 쓰기 작업이 서로 방해를 일으키기 때문에, 동시성 문제가 발생한다.
- 동시성 저하가 크게 발생한다.
이러한 문제점을 해결하기 위해 MVCC(Multi-Version Concurrency Control) 이 탄생하게 되었다.
MVCC(Multi-Version Concurrency Control)
대부분의 DBMS에서 동시성 수행을 위해 제공하는 MVCC 기능은
- 동시에 여러 트랜잭션이 수행되는 환경에서,
- 각 트랜잭션에게 쿼리 수행시점의 데이터를 보장해줌과 동시에,
- Read/Write 간의 충돌 및 Lock을 방지하여 동시성을 높일 수 있는 기능이다.
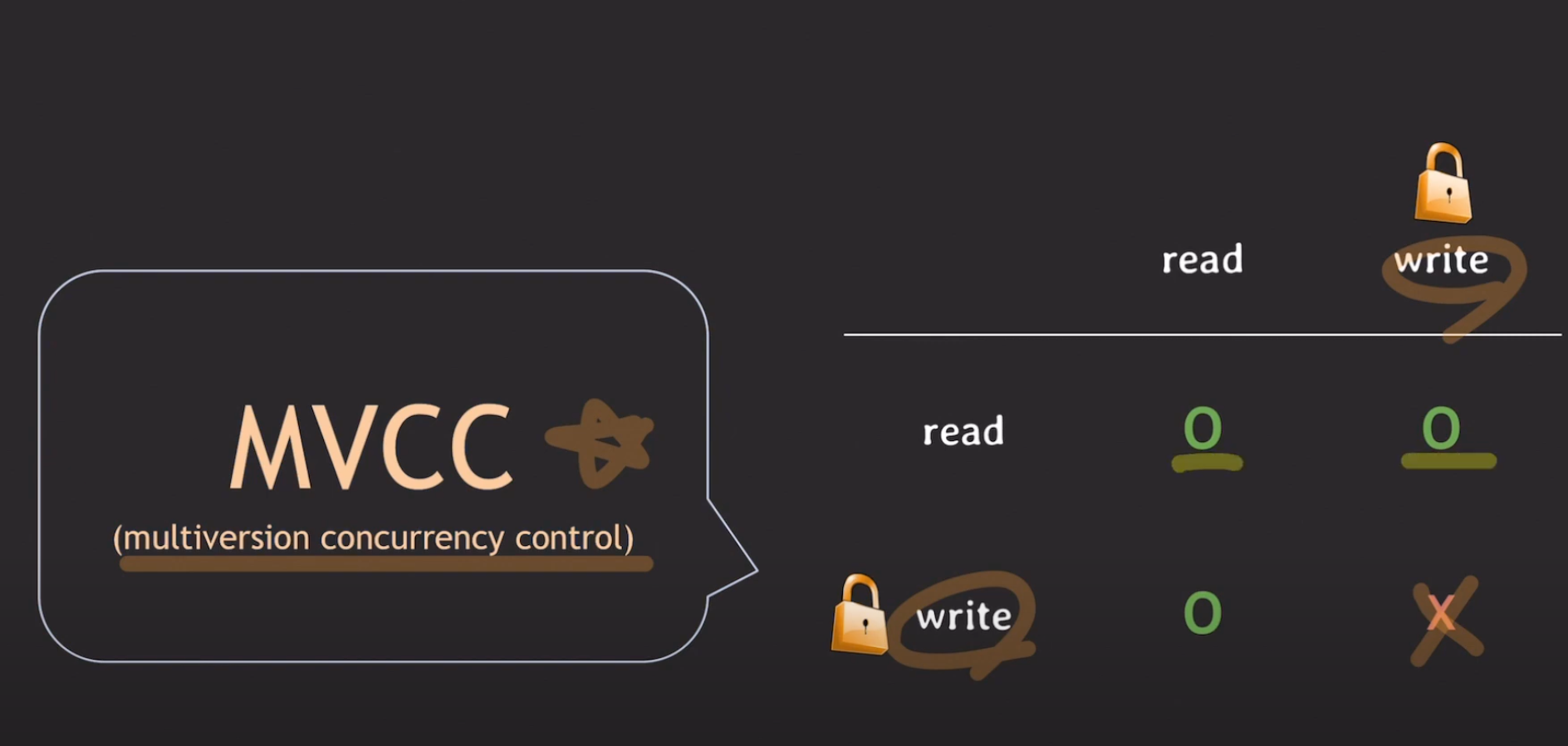
좋은건 다 가져갔다. 물론 단점과 주의해야할 점도 많다.
MySql의 MVCC
우선 Postgresql 의 동작을 알아보기 전에 mysql의 동작 방식을 살펴보자. oracle도 같은 방식으로 알고 있다.
undo 영역을 활용하는 방식이다.
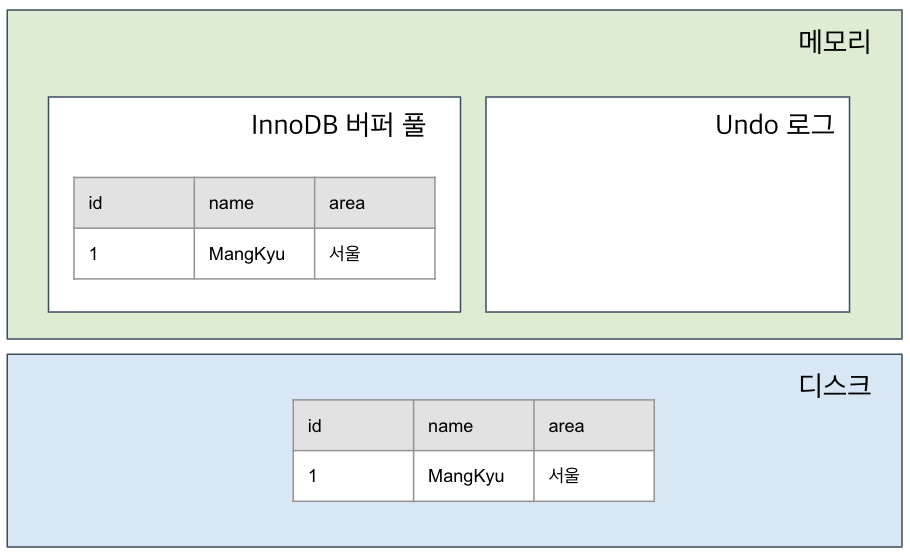
이러한 상황에서 다음과 같은 쿼리를 날렸다고 해보자
UPDATE member SET area = "경기" WHERE id = 1;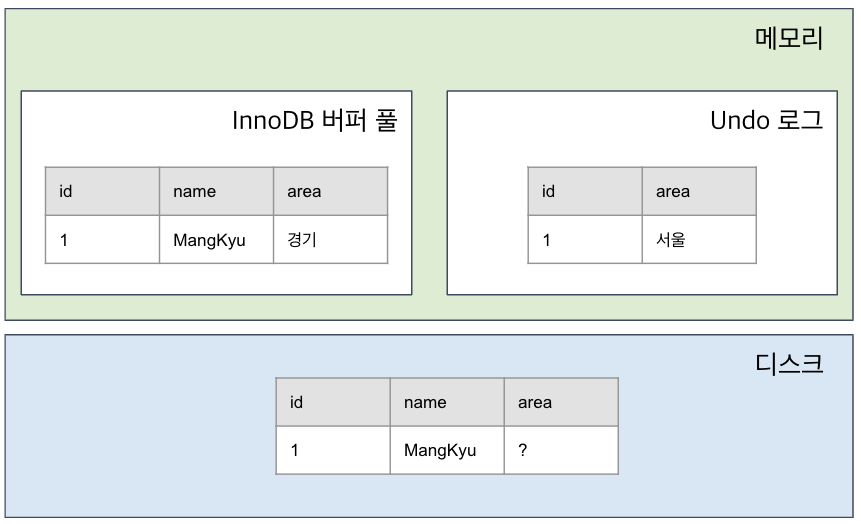
그러면 이와 같은 상태가 된다. 즉 기존의 원본 데이터를 Undo에 백업해 놓는 것이다.
그렇다면 이 상태에서 SELECT 문을 날리면 바뀐 값이 올까? 원래 값이 올까?
그것은 isolation level에 따라 다르다.
READ_UNCOMMITTED의 경우에는 바로 버퍼 풀에서 읽어서 응답할 것이고, 그 외의 READ COMMITTED, REPEATABLE_READ, SERIALIZABLE 에서는 UNDO 영역에서 읽어서 응답할 것이다.
Postgresql의 MVCC
Postgresql에서는 MVCC가 조금 다르게 구현되어 있으며, 이를 매우 조심해야한다.
일단 Postgresql에서는 Record대신에 Tuple이라는 용어를 사용하는데, 각 튜플마다 xmin, xmax 값을 기록한다
아주 쉽게 말하면 이 레코드가 읽힐 수 있는 transactionId의 범위를 말을 한다.
그렇다 Postgresql 에서는 업데이트가 발생하면, 수정하는 것이 아니라 하나의 레코드(튜플)을 추가하는 것이다.
그리고 읽을 수 있는 xmin, xmax값을 수정하는 것이다.
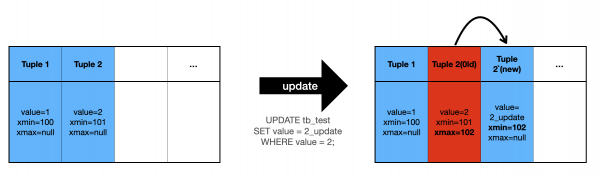
그러면 아래 표를 한번 보자
xmin | xmax | value
-------+-------+-----
2010 | 2020 | AAA
2012 | 0 | BBB
2014 | 2030 | CCC
2020 | 0 | ZZZ나의 트랜잭션 id가 2016이라면 무엇을 볼 수 있겠는가?
AAA, BBB, CCC 만 볼 수 있는 것이다.
이런 식으로 Postgresql은 MVCC를 특이하게 구현을 하였다.
문제가 보이지 않는가? 만약 업데이트가 잦다면 어떤 일이 벌어지겠는가?
Postgresql Vacuum
Postgresql은 mvcc 구현을 위해 업데이트 시, 새로운 튜플을 추가하고, 포인터를 옮기게 됩니다.
이렇게 되면, 어디에도 참조되지 않는 기존 튜플이 생기게 되는데, 이를 Dead Tuple이라고 합니다.
근데 문제는 Postgresql 이 이 죽은 튜플도 페이지(다른 DB의 블록에 대응)에 담는다는 것입니다.
Postgresql 또한 다른 데이터베이스 처럼 페이지 단위로 메모리에 로드 합니다.
따라서 디스크 사용량 뿐만 아니라 쿼리 속도에도 영향을 주게 됩니다.
아래는 우아한 기술 블로그에서 가져온 내용입니다.
### autovacuum off
testdb=> alter table tb_test set (autovacuum_enabled = off);
ALTER TABLE
### delete 전 count 조회
testdb=> select count(*) from tb_test;
count
----------
10000000
(1 row)
Time: 548.779 ms
### delete 후 count 조회
testdb=> delete from tb_test where ai != 1;
DELETE 9999999
Time: 30142.916 ms (00:30.143)
testdb=> select count(*) from tb_test;
count
-------
1
(1 row)
Time: 497.835 ms
=> 1건을 count하는데도 오래걸림
### Dead Tuple 확인
testdb=> SELECT relname, n_live_tup, n_Dead_tup, n_Dead_tup / (n_live_tup::float) as ratio
FROM pg_stat_user_tables;
relname | n_live_tup | n_Dead_tup | ratio
----------+------------+------------+----------
tb_test | 1 | 9999999 | 9999999
=> Dead Tuple이 9999999개로 증가함, 반면에 live Tuple은 1건
### 테이블 사이즈 조회
testdb=> dt+ tb_test
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+---------+-------------
public | tb_test | table | master | permanent | 1912 MB |
=> 1건짜리 테이블임에도 거의 2GB인 상황위와 같이 분명히 레코드를 지운 상황임에도, 쿼리 속도도 지연되고, 테이블 사이즈도 여전히 큰 것을 알 수 있습니다.
vacuum 수행 후는 어떨지 한번 봅시다
### autovacuum off
testdb=> alter table tb_test set (autovacuum_enabled = off);
ALTER TABLE
### vacuum 수행 후 Dead Tuple 확인
testdb=> vacuum tb_test;
VACUUM
Time: 11273.959 ms (00:11.274)
testdb=> SELECT relname, n_live_tup, n_Dead_tup, n_Dead_tup / (n_live_tup::float) as ratio
FROM pg_stat_user_tables;
relname | n_live_tup | n_Dead_tup | ratio
----------+------------+------------+-------
tb_test | 1 | 0 | 0
=> Dead Tuple이 0개로 모두 정리됨
### 데이터 조회 속도 및 테이블 사이즈 비교
testdb=> select count(*) from tb_test;
count
-------
1
(1 row)
Time: 9.971 ms
=> 앞에서와 달리 1건 counting이 바로 완료됨
testdb=> dt+ tb_test;
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+-------+-------------
public | tb_test | table | master | permanent | 1912 MB |
=> vacuum 수행 후 dead tuple은 정리되었지만 테이블 사이즈는 그대로임
### vacuum full 수행 후 테이블 사이즈 확인
testdb=> vacuum full tb_test;
VACUUM
testdb=> dt+ tb_test;
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
--------+---------+-------+--------+-------------+-------+-------------
public | tb_test | table | master | permanent | 40 kB |
=> vacuum full 수행 후에는 테이블 사이즈도 줄어들었음더 자세한 내용은 이 글의 범위를 벗어나므로, 다음 링크를 한번 읽어보시기를 강력 추천합니다.
https://techblog.woowahan.com/9478/
추가 : DB별 기본 isolation
MySql(Inno DB) - REPEATABLE_READ
Oracle DB - READ_COMMITTED
Postgresql - READ_COMMITTED
자료, 참조자료 출처
https://mangkyu.tistory.com/53 [MangKyu's Diary:티스토리]
https://www.youtube.com/watch?v=wiVvVanI3p4&list=PLcXyemr8ZeoREWGhhZi5FZs6cvymjIBVe&index=20
https://techblog.woowahan.com/9478/
