레디스 심화 - 프로토콜, 내부 구조, 확장, 분산 기법, 운영시 주의사항
레디스 사용법, 복구, 자료구조 같은 건 알고 있었지만 조금 더 딥한 내부 동작 원리를 알고 싶었다.
레디스 프로토콜
- 레디스 서버가 수신하는 모든 명령은 레디스 프로토콜을 통해서 수신된다.
- TCP/IP 기반으로 HTTP와 비슷하게 텍스트 기반 프로토콜이며,
- 사람이 읽기도 쉽고 이해하기도 쉽다.
- 바이너리 세이프하다.
요청 프로토콜
*3 // 인자의 갯수
$3 // 인자 1의 바이트 수
set // 인자 1
$5 // 인자 2의 바이트 수
mykey // 인자 2
$6 // 인자 3의 바이트 수
value1 // 인자 3이런 식으로 이루어져 있다.
응답 프로토콜
앞의 1바이트 값이 응답 데이터 종류를 의미한다.
+: 상태 응답-: 에러 응답:: 숫자 응답$: 단일 벌트 응답*: 멀티 벌크 응답
응답 예시는 아래와 같다.
+OK:10레디스 내부 구조
레디스 객체 구조
우선 Redis는 ANSI C로 개발 되어 있다.
레디스에서 저장된 데이터를 관리하기 위해서는 redisObject라는 객체를 통해 관리된다.
문자열 데이터와 해시 데이터는 모두 redisObject 객체를 사용해서 저장한다.
아래와 같은 정보가 포함되어 있다.
- type : 데이터 형 표시
- notused : 사용안되는 필드
- encoding : 인코딩 타입
- lru : 생성되거나 변경된 시간
- refcount : 참조 카운트
- *ptr : 데이터 주소, 운영체제에 따라 크기가 다르다.
내부 구조 요약
너무 지협적인 내용이 많아 개발자가 알아야할 내용만 간단히 요약한다.
- 레디스 데이터를 저장할 때 인코딩을 한다.
- 이 인코딩에는 다양한 종류가 있으며, redisObject라는 구조체에 명시해둔다.
- 레디스 문자열은 char*(포인터)를 활용해 저장하지만, 이렇게 되면 길이를 체크할 때마다 데이터에 접근해야 하므로, buffer, free, len으로 구성된 구조체에 저장하여 O(1)시간내에 길이를 구할 수 있게 해둔다.
- 레디스는 자주 사용되는 값을 전역변수인 공유 객체에 저장해둔다.
- 공유 객체의 각각의 속성을 redisObject로 표현한다.(특이,,)
확장과 분산 기법
복제
- 마스터 슬레이브 구조를 사용한다.
- 읽기 성능의 증대를 위해 사용한다.
- 슬레이브 노드 시작시, 마스터 복제하고 이후 변경사항을 반영한다.
단일 복제
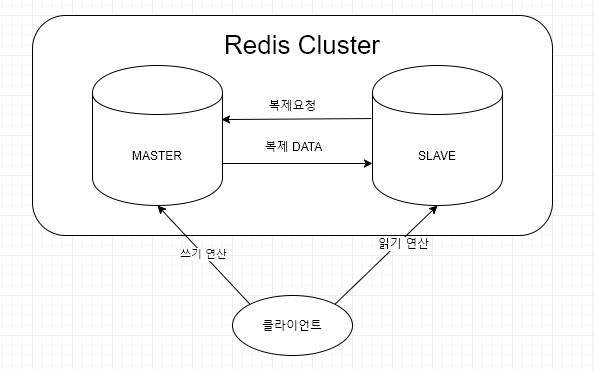
- 가장 단순한 방식
- 슬레이브에서 데이터 변경이 발생하는 순간 마스터는 감지하지 못해 정합성 무너진다.
- 클라이언트가 마스터와 슬레이브에 대해 다 알고 있어야 한다.
- 클라이언트 복잡도 증가
- 마스터 노드가 슬레이브에게 동일한 데이터 복제 연산 수행
- 슬레이브 쪽 설정에 마스터를 설정한다.
- 굉장히 빠른 시간안에 동기화 되지만, 시간이 소요된다.
- 복제 시간보다 네트워크 접근시간이 짧은 경우, 동기화 되기 직전 정보를 읽을 수 있다.
다중 복제
- 단일 복제에 단순한 확장
- 단일 복제와 설정 동일, 슬레이브 쪽에 마스터 명시
- 쓰기 연산에 비해 읽기 연산이 많은 서비스에 적합한 클러스터
- 마스터의 네트워크와 cpu 소모가 심하며, 슬레이브가 많을 시 상당히 많은 리소스가 소모된다.
계층형 복제
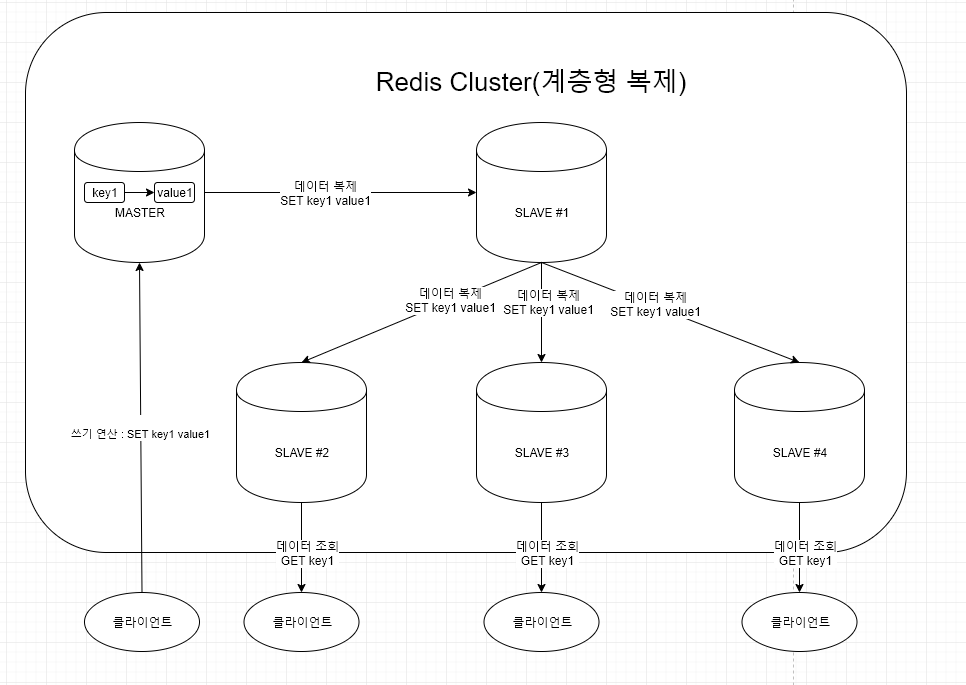
- 마스터에 너무 많은 슬레이브가 접속되어 쓰기 성능이 저하되는 문제점을 해결하기 위한 복제 방법
- 마스터가 일부 슬레이브에 복제하고, 그 슬레이브에 다른 슬레이브가 붙어서 복제하는 방식
샤딩
샤딩은 데이터를 나누어 저장하는 것을 의미한다.
이로 인해 얻게 되는 것은 다음과 같다.
- 더 많은 데이터 저장 가능
- 쓰기 성능 증대
레디스 클라이언트의 샤딩 방법은 다음과 같다.
- 수직 샤딩 : RDB의 테이블에 해당하는 그룹 단위로 분산 저장
- 범위 지정 샤딩 : 특정 범위별로 끊어서 분산 저장
- 해시 기반 샤딩 : 키를 해싱해서 분산 저장
샤딩과 복제의 혼합
샤딩을 하며 샤딩 단위로 마스터 슬레이브를 만들 수 있다.
근데 좀 아쉬운 점은 이런것들을 모두 클라이언트 단에서 처리해야한다는 것이다.
그래서 보통은 헬퍼클래스를 만들어서(유틸성)이를 처리한다고 한다.
그러니까 즉 샤딩이던 복제던 10개의 인스턴스가 띄워져 있으면, 클라이언트 앱이 이를 인식하고 분산해서 읽고 써야 한다는 것이다. 🤔
레디스 운영시 고려사항
단일 CPU
알다 싶이 레디스는 단일 쓰레드로 동작한다. 따라서 여러개의 코어가 있는 서버에 띄워도 하나의 코어만 사용한다.
따라서 멀티 코어 서버에서 실행을 고려한다면 코어 수만큼 여러개의 레디스를 띄우는 것을 고려할 있다.
메모리 대역폭
위와 같은 이유로 단일 머신에서 여러대의 레디스 인스턴스를 수행할 때, 각 프로세스가 동시에 메모리를 접근하려고 시도하게 된다. 이 때 각 프로세스가 메모리 버스 대역폭을 소모하므로, 병목현상이 발생한다.
메모리 크기
redis.conf의 maxmemory 설정을 하지 않고 사용하는 경우
운영체제에 계속해서 추가적인 메모리를 요청하게 되고, 스왑메모리라는 가상 메모리를 생성하여 사용한다.
이 때 레디스의 응답시간은 수 십배에서 수 백배까지 늘어나게 된다.
이 스왑까지도 충분하지 않으면, 운영체제가 실행 중인 프로세스를 kill해서 메모리를 확보하게 된다. 이것이 그 유명한 OOM 킬러라고 한다.
그래서 OOM 킬러를 피하려면 꼭 maxmemory를 물리메모리 이내의 값으로 설정해야한다.
maxmemory 설정값은 데이터만을 위한 것 뿐만 아니라 키라던지 부가적인 용량이 포함된다. 따라서 4GB로 설정한다면 실제 저장가능한 데이터는 이보다 작다.
스왑영역
일반적으로 운영체제는 설치된 메모리의 두배 만큼 스왑공간을 확보한다.
하지만 요즘같이 메모리 크기가 커진 상황에서는 이 값을 설정할수 있게 하는 경우가 있다.
만약 레디스에서 AOF나 스냅샷같은 영구 저장소 기능을 사용한다면, 스왑영역은 최소한 물리메모리 크기만큼은 확보되도록 설정해야 한다. 그 이유는 AOF나 RDB을 위한 fork()함수가 실행되면 현재 레디스가 사용하고 있는 만큼의 메모리를 확보하려고 시도하게된다.
네트워크
- 마스터 노드에서 슬레이브 노드로 복제를 할 때 네트워크 대역폭이 점유된다.
- 마스터 노드와 슬레이브 노드가 연결이 끊어지면, 재접속을 시도하고 마스터 노드의 전체 데이터를 받아 동기화를 수행한다.
이 두가지 상황을 잘 고려해야한다. 즉 이러한 과정속에서 네트워크 대역폭이 심하게 점유당한다.
따라서 네트워크 허브를 두개로 분리해서, 복제를 위해 사용하는 대역폭과 레디스 접속에 사용하는 대역폭을 분리하는게 중요하다.
