개요
이번 글에서는 내 개인 프로젝트에서 Google Api 호출 비용을 줄이기 위해 Graphql 을 사용했었던 경험을 간단하게 정리하고자 한다.
문제 상황
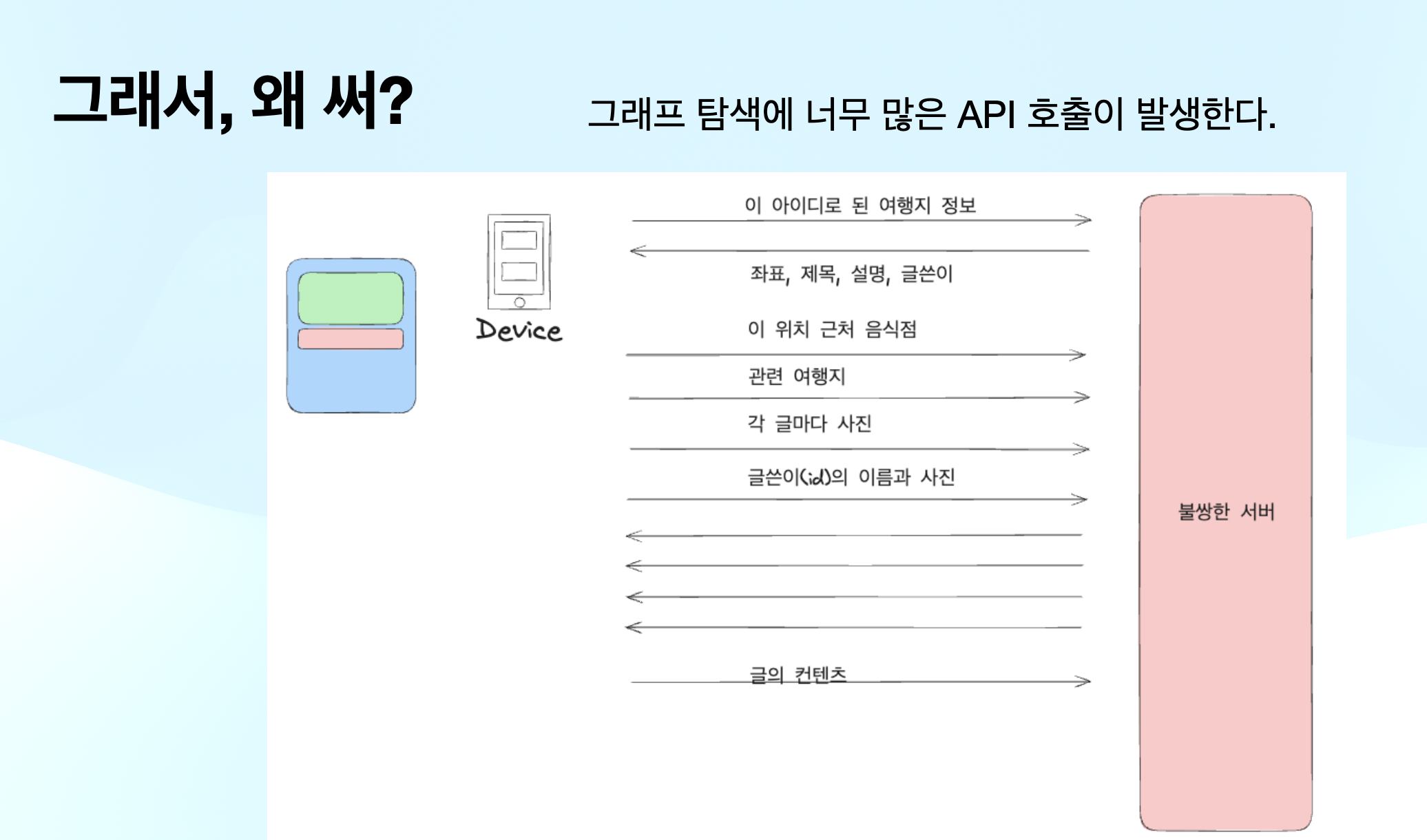
API 비용
- 프로젝트에서 관광지 정보를 제공하기 위해, 구글 Place API를 사용했습니다.
- 그런데, google api에서 제공하는 장소 정보는 매우매우 많고, 각각의 필드마다 비용을 계산했습니다.
예를 들어, A, B, C 가 포함되어 있으면 건당 10달러, D, E가 포함되어 있으면, 12달러 이런식입니다.
따라서, 정확히 필요한 필드만 요청하는게 중요했습니다.
다양한 부분 요청 수요 존재
장소 정보의 경우, 매우 많은 세부 정보가 존재하고(이름,위치, 설명, 주소, 다른 언어로 된 정보, 전화번호, 태그, 리뷰, 사진 ........) 클라이언트가 요청하는 필드 집합은 매우 다양하고, 이걸 맞춰주기가 애매하다

GraphQl 도입
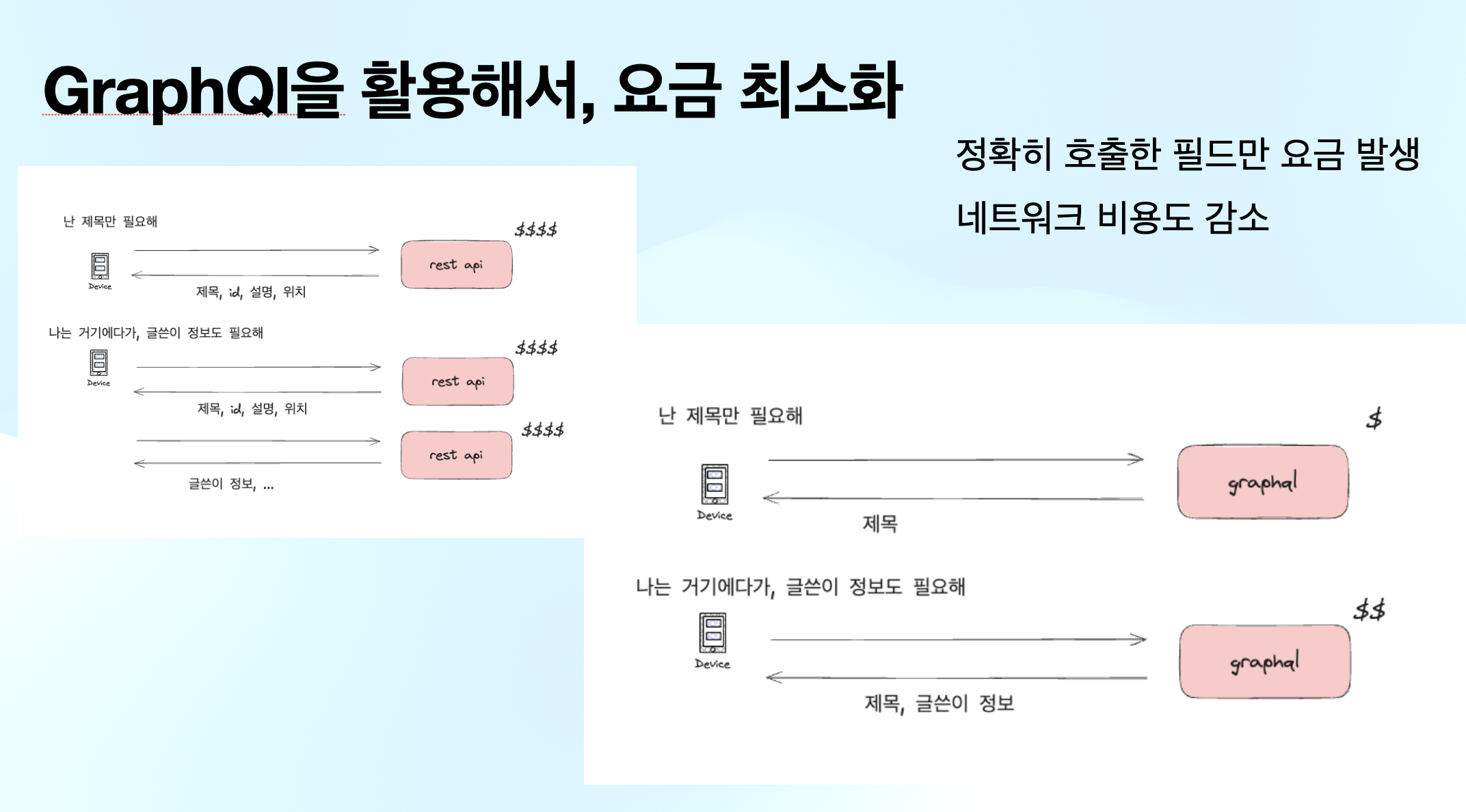
그래서, Graphql을 도입해서, 클라이언트로 부터, 정확히 필요한 필드를 입력하게 하고, 정확히 필요한 정보를 Google Place API를 활용해서 fetching하는 식으로 작성하게 되었다.
이 graphql 요청이 단순히 placeAPI를 매핑하는 역할만 하는 것은 아니었다. 뒤쪽에 있는 구글의 사진 API라던지, 장소 API, 주변 탐색 API 등 다양한 서비스를 유동적으로 호출하도록 하였다.
물론 각각은 비동기적으로 페칭하게 하였다.
문제, 한계점
Graphql의 도입을 하면서 매우 유용함을 느꼈다.
- 프로토콜로 인해 API 설계가 오히려 쉽고 견고해졌다. (null 여부 명시, 타입 명시, 응답 에러의 큰 타입이 미리 정의되어 있음, 다형성, enum들을 명시할 수 있도록 고려되어 있음...)
- 클라이언트를 위해 여러개의 GET API를 하드코딩 할 필요가 없다.
- 요즘같은 마이크로 서비스에 잘 어울리는 것 같았다. 뒷단의 여러 서비스를 독립적으로 설계하기 좋았다.
- 오버페칭을 방지하는 것은 물론이고, 서버측과 프론트 쪽 모두 하나의 엔드포인트에 집중할 수 있어서 좋았다.
근데 다음과 같은 문제점이 다소 치명적이었다.
그래프 탐색시 중첩된 객체에 대한 옵션을 설정하기 힘들다.
이게 무슨 말인지 헷갈릴 거다. 예시를 보는게 빠르다.
type Place{
id : ID!
photos : [Photo!]
}
type Photo{
url: String!
owners: [Person!]
width: Int!
height: Int!
}만약에 사용자가 Place를 조회하면서, photos까지 요청했다고 해보자.
그리고 사진은 같은 사진에 대해 여러가지 화질이 존재한다고 해보자
place(id: asdfjalhsf){
id
photos{
url
owners{
id
name
}
}
}다음과 같은 문제가 발생한다
- 사진을 최대 몇장까지 보여줄 것인가?(페이징의 문제)
- 어떤 화질의 사진을 보여줄 것인가?
- 만약 100장의 사진이 있고, 한개의 사진당 100명씩 owners가 존재하는 경우 어떻게 할 것인가?
쿼리의 인자로 넣으면 되지 않냐 할 수 있지만, graphql은 그런식으로 작동하지 않는다.
사용자가 photos를 요청할지 안할지는 인자를 설정하는 단계에서는 모른다.
이걸 해결하려면, photos를 제공하는 쿼리를 따로 제공하거나, 조건부 인자 같은게 들어가야하는데, 나는 찾지 못했다.
느낌이 오겠지만, grapqhl에서는 마치 그래프를 탐색하는 듯한 쿼리를 제공한다.
하지만 neo4j의 cyper처럼 그래프 탐색에 대한 상세한 오퍼레이션이 부족하다.
위의 문제에서 100장의 사진당 100명의 사람이 존재한다면, 어떻게 할것인가?
Batch 처리를 하면 되지 않냐고 할 수 있을 것이다. 당연히 그렇게 해야한다.
하지만 그럼에도 불구하고, person서비스(별도의 서버일 수도, 서비스 객체일수도)에는 10000명의 사람 정보 요청이 들어갈 것이다.
사진 서비스에도 100개의 사진 요청이 들어갈 것이다.
이게 문제인 이유는, 하나의 API가 차지하는 부하 정도가 클라이언트에 의해 동적으로 결정된다는 점이다. 기존의 rest api의 경우, 어느정도 부하량이 예측이 가능하고 일정 부하 수준에서 움직인다. 하지만 graphql의 경우에는 말그대로 예상이 불가능하다.
만약 위 예시에서 더 나아가, 장소의-사진의-사람의-친구의-직장의-사진의-주인의 이런식으로 그래프 쿼리를 날렸다고 해보자. 어떤 일이 벌어질거라고 예측할 수 있는가?
캐싱이 힘들다
이는 어느정도 예상은 하고 갔다. graphql을 설명하는 대부분의 페이지에서는 이를 언급하고 있다.
하지만 이는 어디까지나, 그 cache controll 같은 수준에서 말을 하고 있다. rest api의 경우에는 하나의 엔드포인트에서 동일한 리소스가 반환되는 경우, 이를 캐싱하기 유용하니까
내가 말하고자 하는 것은 서버측에서 작업에 대한 캐싱이 힘들다는 것을 말하고 싶은 것이다.
만약 rest api의 경우, 사용자가 동일한 엔드포인트에 동일한 인자로 요청을 보내면, 서버측에서 이를 캐싱하기 편리하다.
예를 들어 사용자들이 id : 1234인 여행지를 매우 빈번하게 요청한다고 해보자. 서버측에서 만약 이 여행지를 쿼리하는 작업에 오버헤드가 크다면 다음과 같은 선택을 할 수 있을 것이다.
첫 요청이 끝나면, 해당 json응답을 mongodb같은 곳에 미리 만들어진 상태로 저장해놓고, 다음 요청때 그걸 그냥 통째로 전달한다.
하지만, graphql의 경우 어떤가? 사용자가 요청하는 필드 조합의 경우의 수는 셀수 없이 많다. 따라서, 이를 캐싱하는 경우, 로직이 매우 복잡해진다.
사용자가 요청하는 필드를 개별적으로 판단해서, 캐시에 필드별로 merge를 해야한다. 근데 만약 10일 이상 된 필드는 갈아끼워야한다면?
사용자가 요청을 했을 때 해당 모든 필드가 캐시에 존재하는지 판단하는 것도 매우 복잡해진다.
현재 진행하는 방향
물론 graphql이 안좋다는 것은 아니다.
그래서 현재는 다음과 같이 진행하고 있다.
- rest, graphql, grpc를 동시에 제공한다.(presentation layer에서)
- graphql의 경우, 각각의 타입간의 관계 연결을 줄이거나 주의한다.(그래프 탐색 제한)
- graphql의 요청이 오게 되면, 그냥 구글에서 장소 정보를 통째로 받아와서 캐싱한다. 그리고 graphql요청이 오면 그 통째 문서에서 필요한 부분만 잘라서 전달한다.
- 즉 캐싱은 무조건 통째 문서로 한다.
더 진전이 되는 대로 추가 포스팅을 하겠다.
