사용량 기반 비용 청구, 로그 데이터 파이프라인 구축기
이 글은 졸업 프로젝트로 진행한 '위치추적모듈' 프로젝트에서 겪었던 경험을 정리한 글입니다.
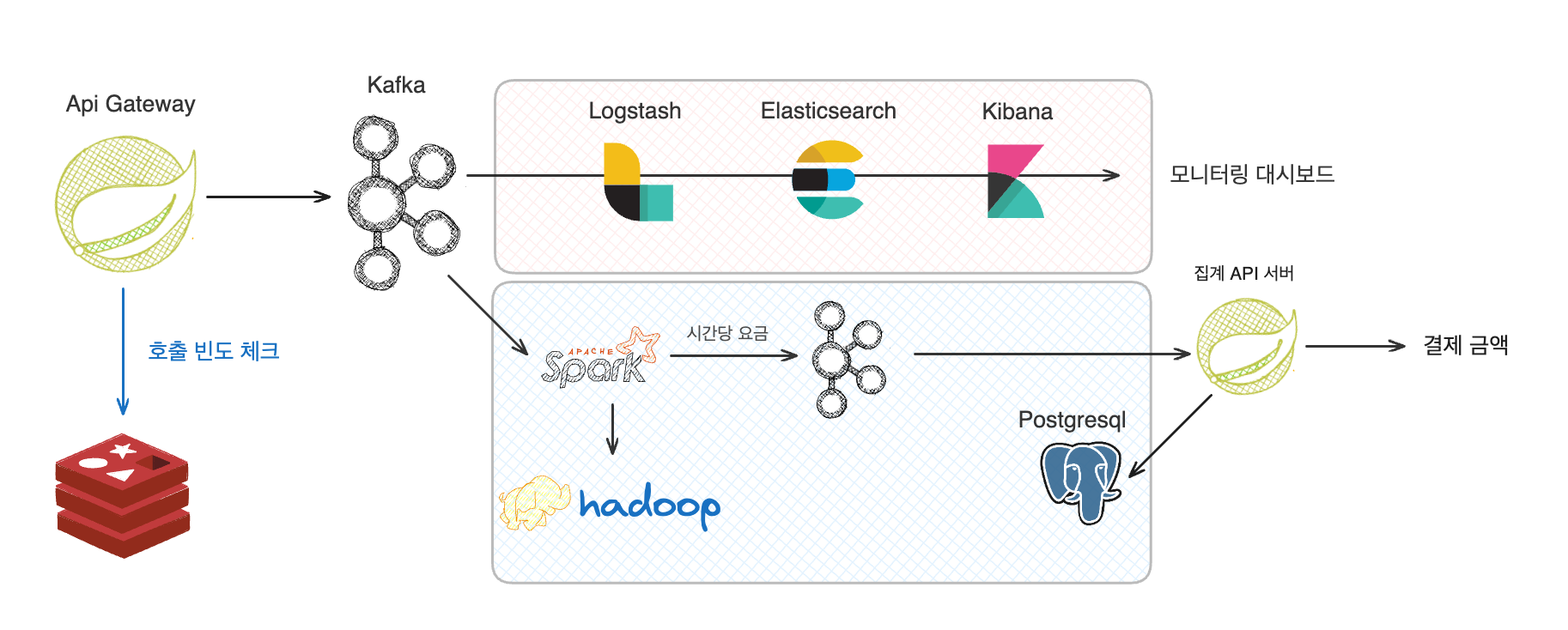
프로젝트 간단 소개
간단하게 소개하면, 사용량 기반으로 비용을 내는 SAAS 서비스로, 위치 추적 서비스를 제공합니다.
마주한 문제
나는 두가지 기능을 담당하였다.
- 전체 API 호출 모니터링 시스템
- 사용량 기반 비용 청구 기능
오늘을 이 중에서 사용량 기반 비용 청구와 관련된 경험을 정리해 보려고 한다.
Api Gateway
우리 팀은 각각의 기능을 서버로 분리하고 서버간 통신을 하는 구조로 설계를 하였다.
따라서 나는 Api Gateway를 개발하여 모든 서버의 엔트리 포인트를 담당하였다.
뒷단의 서비스는 클라이언트에서 직접 접근하지 못하고 내 Gateway를 통해서만 접근하게 하였다.
그리고 이 Gateway에서 다른 기능과 더불어 로깅을 하자는게 기본 아이디어였다.
하지만 문제는 이 로그를 어떻게 처리하느냐 였다.
호출 로그의 문제
당연히 대충 구현하자면 금방 구현하겠지만 생각해보면 많은 문제점이 있었다.
- 호출 로그는 모든 서비스의 요청량보다 물리적으로 많다.(뒷단의 모든 요청수의 합이 gateway의 포워딩 수 이므로)
- 굉장히 자주 발생한다.
- 처리량이 매우 중요하다.
그렇다 엄청 자주 발생하고, 엄청 많이 발생하면서, 처리량이 높아야 한다는게 문제였다.
DB 단발성 INSERT
그래서 맨 처음 나의 생각은 다음과 같았다.
그냥 RDB에 때려 넣으면 되는거 아니야?
근데 문제점이 두가지가 있었는데,
- 처리량이 매우 떨어진다는 점, DB부하가 크다는 점
- 구간 쿼리시 DB에 상당한 부하가 가고, 느리다는 점
이 두가지였다. 그냥 생각해 보아도, 초당 1만개의 요청이 온다고 치면(말그대로 모든 요청이니까) DB에 단발성 INSERT 문이 초당 1만번 호출이 된다는 건데 DB에 상당한 부하가 갈것은 당연해 보였다.
또 처리량도 DB 처리량에 연동이 되므로 서비스 전체의 성능이 저하될 수 있었다. 또 RDB의 경우 수평적 확장도 어려우니깐..
또 다른 문제는 관리자 API에서 그래프를 그리기를 원한 다는 것이다. 쉽게 말하면, 구간 비용 쿼리가 자주 발생하는 상황이었다.
생각해보라, 특정 사용자(업체)가 초당 1000번 이상 api를 호출하고, 월 단위의 비용 쿼리를 한다면, 1달만 조회해도 1억개의 레코드를 집계해야한다.
이는 매우 느리고 DB에 말도 안되는 부하를 가할 수 있다고 생각했다.
Redis, MongoDB
그래서 다음 생각한 방법은 Redis와 MongoDB를 사용하는 방식이었다.
Redis의 경우 사용량 제한기능(Rate Limiter)를 위해 이미 내가 사용중이었기 때문에 가장 먼저 고려해 보았다.
Redis에는 List라는 구조가 있는데 이것을 버퍼로 활용하면 어떨까 생각하였다.
Gateway 측에서 발생 로그를 Redis List에 빠르게 집어넣고, 뒷쪽 서버가 주기적으로 이를 폴링하면 어떨까 생각했다.
이렇게 되면 다음과 같은 장점이 생긴다.
- 게이트 웨이 처리량이 올라간다.
- 단발성 INSERT가 Bulk INSERT로 바뀐다.
하지만 이를 구현하고 느낀점은 이 또한 사용하기 어렵다는 점이었다. 다음과 같은 문제가 예상되었는데
- 레디스에서 이벤트를 폴링한다음 DB에 넣기 전에 서버에 문제가 생기면(꺼진다던가) 데이터가 유실된다는 점
- 만약 뒷단의 폴링 서비스가 죽거나, 처리량이 받쳐주지 않으면, 레디스의 과도한 메모리가 점유당하거나 터질 수도 있다는 점이다.
우선 이는 결제에도 사용되는 이벤트라 절대 유실이 되면 안되었다.
첫번째 문제의 경우, 카프카랑 매우 대조되는데, 카프카에 경우 커밋을 잘 활용하면 서버에서 처리중 죽더라도 다시 처리하게 할 수 있다.(중복되더라도) 하지만 레디스의 경우 이벤트를 영구 저장하는 방식이 아니라 가져가는 순간 지워버리므로 만약 처리중 문제가 생기면 그 많은 양의 이벤트가 말그대로 유실되어 버린다.
두번째 문제는 카프카만큼 안정적이지 않다는 점이었다. 뒷단의 폴링서비스가 죽거나 점검에 들어간다고 가정해보자. 엄청난 양의 이벤트가 레디스 리스트에 쌓이게 될 것이다. 여기서 만약 장애가 나면, 다른 서비스에도 영향이 가는 것은 당연하고 그 엄청난 양의 사용 로그 또한 유실 될 수 있다.
그래서 이 방법은 철회하게 되었다.
물론 Redis에도 PUB/SUB이나 Stream(유사 카프카)가 존재하나, 자료가 매우 부족했다. 또 이건 내가 못찾은 것일 수 있는데 Stream의 경우 메시지를 지우는 옵션을 찾지 못했다. 카프카의 경우 일정시간이 지나면 이벤트를 지우거나 압축하는 옵션이 있는데 이상하게 Stream의 경우 해당옵션을 찾기 쉽지 않았다.(설마,, 안지우는건 아니겠지)
Hadoop, Spark, Kafka
그래서 도입하게 된 것이 Hadoop 생태계를 활용한 데이터 파이프라인이었다.
카프카에 경우 어느정도 지식이 있는 상태였고, 하둡과 스파크의 경우 기본적인 개념만 얼핏 들어보았었다.
https://d2.naver.com/helloworld/1016 이글에서 상당한 인사이트를 얻을 수 있었는데, 네이버 쪽에서 2011년에서 비슷한 상황을 극복한 경험이었다.
어쨌든 빠르게 하둡과 스파크 같은 기반 기술들을 공부하였고, 라즈베리파이 4대를 구매해 하둡 스파크 클러스터를 구축하였다.
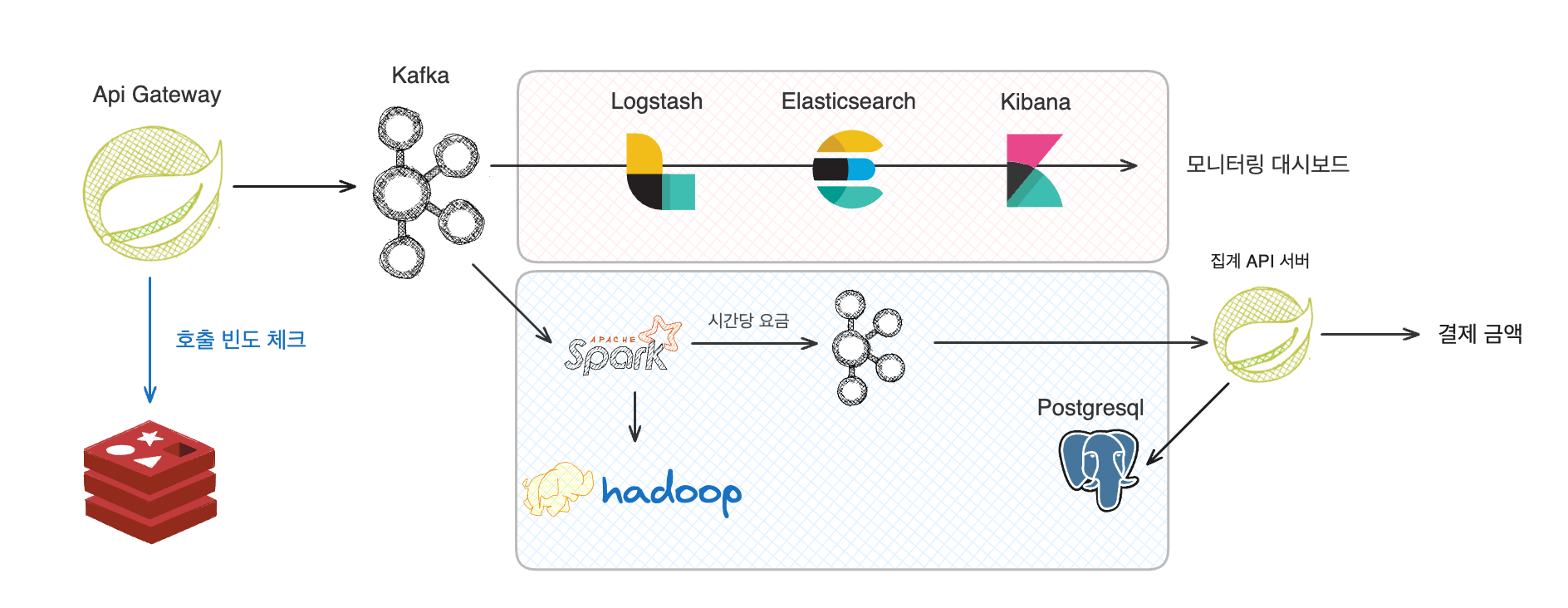
우선 Gateway에서 사용자 행동 로그를 집계해서 JSON포맷으로 카프카로 전송을 한다.
이것을 컨슘하는 컨슈머 그룹은 두가지가 있는데,
- 모니터링을 위한 ELK
- 실시간 처리를 위한 Spark, Hadoop 이다.
ELK
나는 모니터링을 위해 ELK를 사용하였는데, 일단 로그스태시가 카프카로 부터 메시지를 폴링해서 ES에 적재했다.
이 과정에서 ip 주소를 기반으로 지리적 좌표를 유추하도록 하였다.
input {
kafka {
bootstrap_servers => "카프카 서버:29092"
group_id => "api_usage_logstash"
topics => ["api-usage-trace"]
consumer_threads => 1
decorate_events => true
codec => json
}
}
filter {
geoip {
source => "clientIp"
target => "requestLocation"
}
mutate {
remove_field => ["event"]
}
}
output {
elasticsearch {
index => "api_usage_trace"
hosts => "elasticsearch:9200"
user => "logstash_internal"
password => "${LOGSTASH_INTERNAL_PASSWORD}"
}
}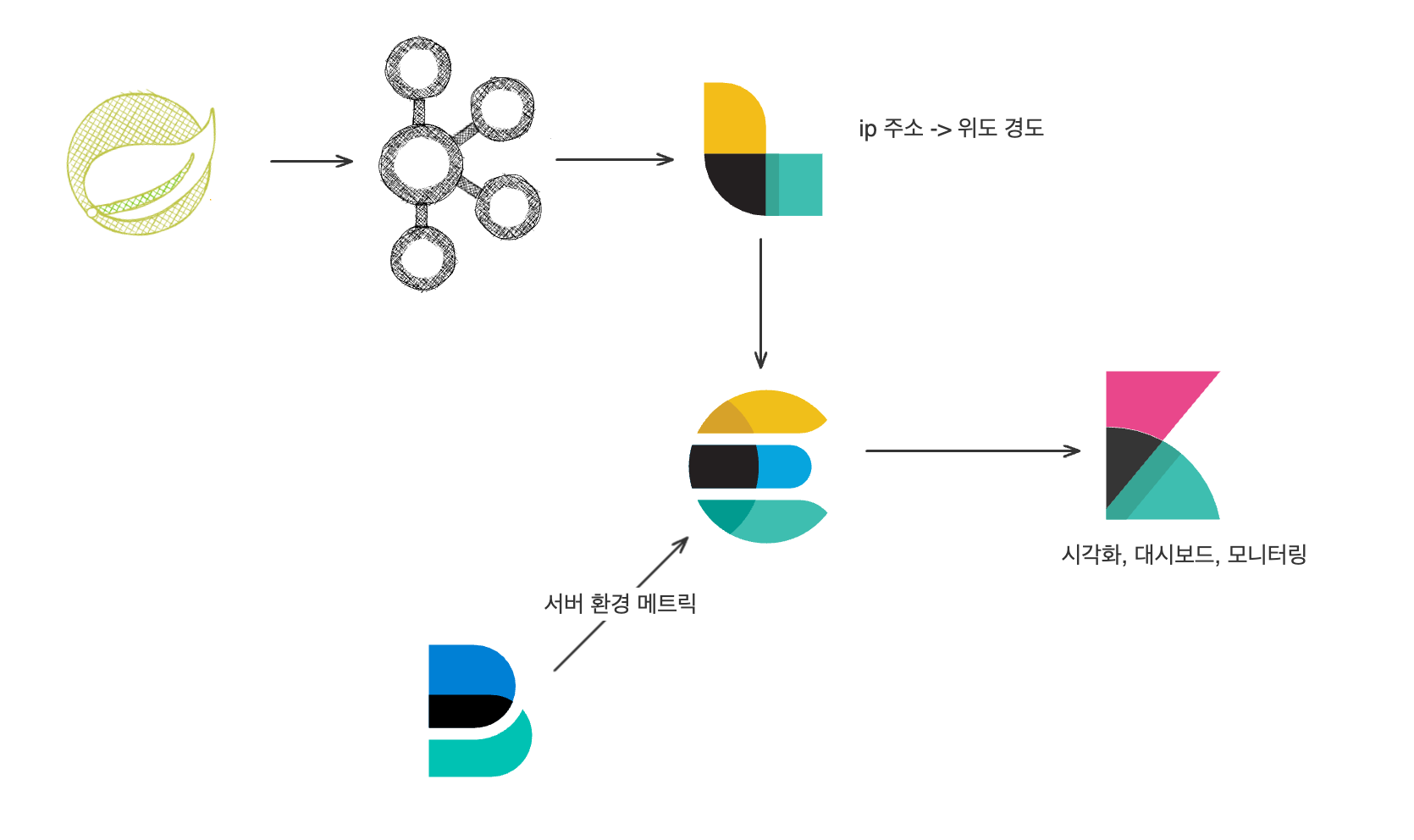
그리고 적재된 이벤트를 키바나로 대시보드를 그렸다.
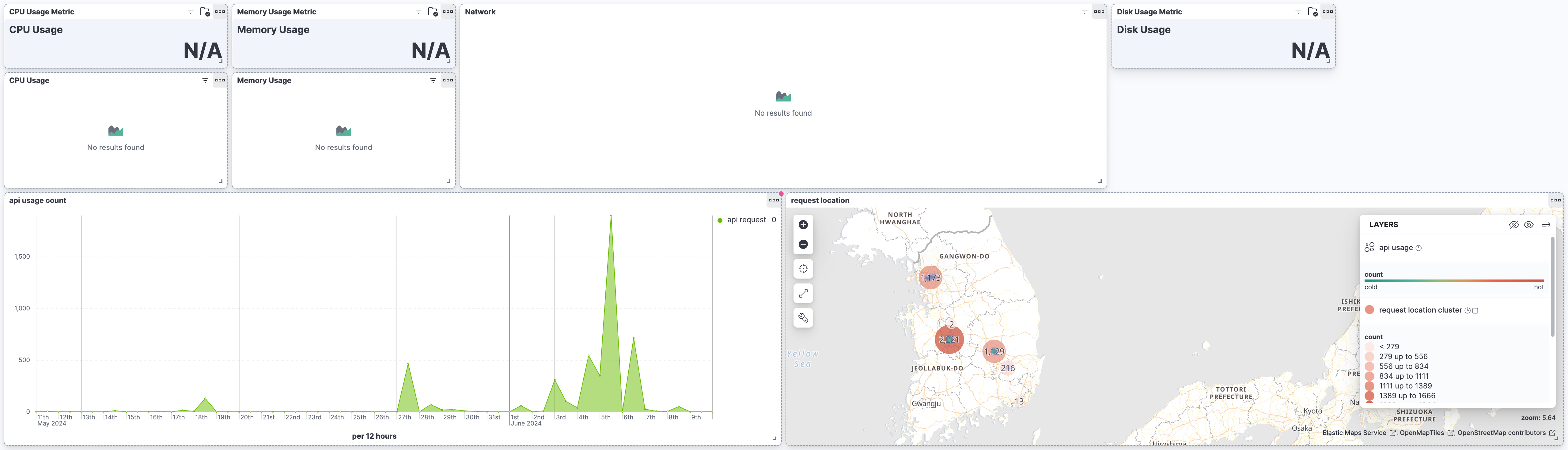
(메트릭비트의 경우, 현재는 꺼놔서 N/A로 표시된다.)
어쨌든 각 시간대별로 요청량이 얼마나 되는지, 그리고 어떤 위치에서 호출이 많이 이루어졌는지와 같은 정보를 시각화하였다.
Hadoop, Spark
여기서는 Spark Stream을 활용하여 Kafka 이벤트를 처리하였는데, 크게 두가지 작업을 하였다.
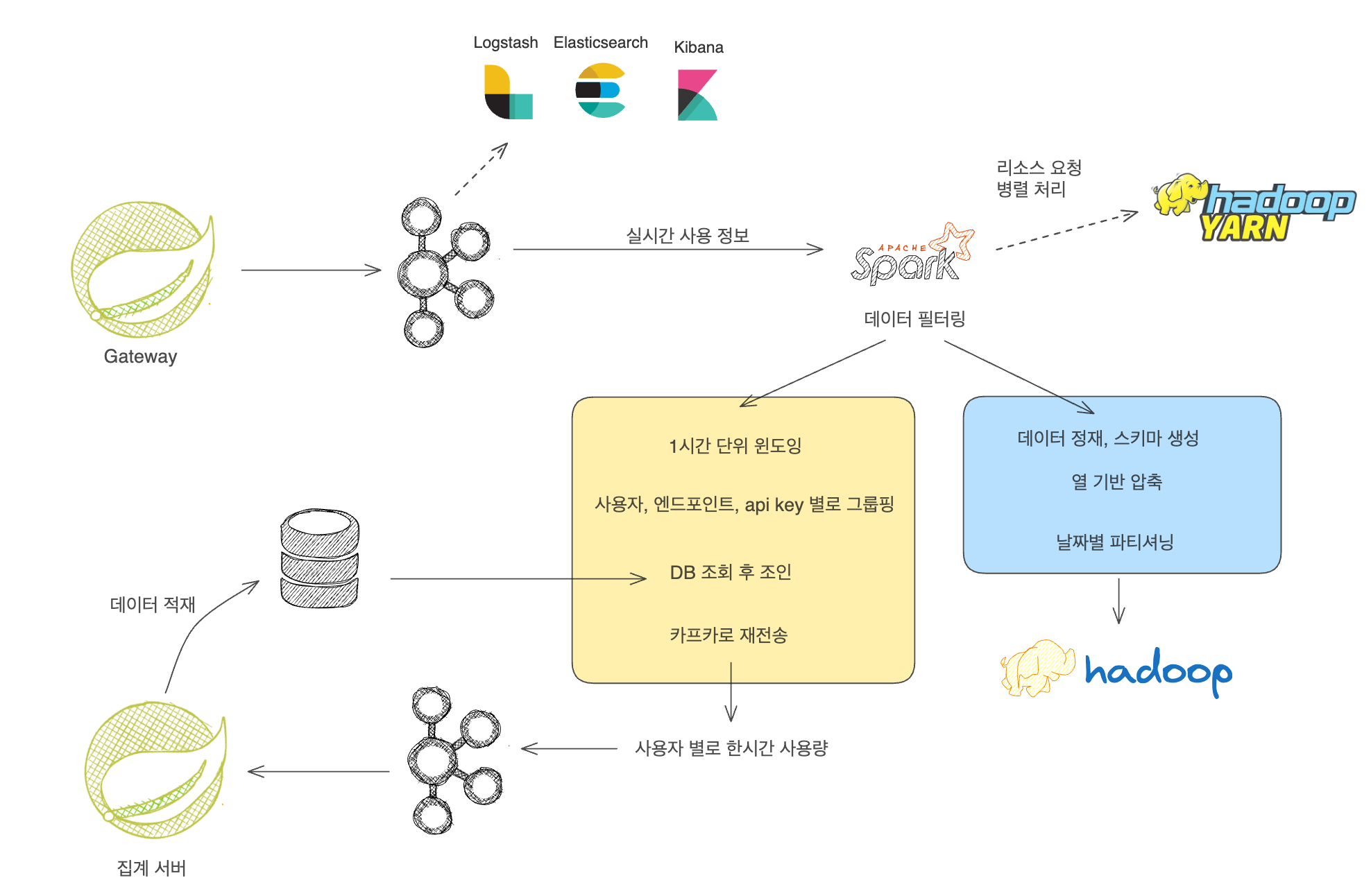
- 이 이벤트를 정재하고 parquet형식으로 Hdfs에 저장하는 작업이다. 이를 통해 추후 DM으로 전환할 수 있도록 하였다.
- 실시간으로 윈도잉하고 그룹핑하고 DB의 가격정보와 조인해서, 멤버당 시간당 비용을 다시 카프카로 보냈다.
두번째가 조금 난이도가 있었는데, 이렇게 처리하는 이유는 맨 처음에 발생했던 1억개의 레코드 집계쿼리를 만들지 않기 위해서 였다. 그러니까 먼저 스파크 스트림 쪽에서 1시간 단위로 묶은 뒤 데이터 베이스에 적재하기 위함이었다.
또 이 과정에서 Kafka의 이벤트 지연 문제를 해결하기 위해서 watermark 기법을 사용하였다.
어쨋든 이 집계된 카프카 이벤트는 집계 서버에 의해 소비되어 DB에 적재하도록 하였다.
그러면 이러한 의문점이 생길 수 있는데
- 왜 직접 DB에 안넣냐?
- 왜 직접 집계서버 API 호출 안하냐?
우선 DB에 넣거나 API를 호출하는 순간 강결합 되게 된다. 생각해보자 만약 DB 스키마를 변경하거나 API 쪽에 변경사항이 생긴다면? 데이터 파이프라인도 다 뜯어 고쳐야 하며, 한순간에 변경사항을 배포해야한다.
만약 집계서버가 바쁘거나 장애가 난다면? API를 직접 호출하는 시스템에서는 장애가 우리 데이터 파이프라인에 전파될 것이다.
이 집계 정보를 받아보고 싶은 시스템이 늘어난다면? 또 파이프라인 코드를 수정해야할 것이다.
그리고 내가 느끼기에는 Spark Stream 의 output모드 자체가 좀,, 서버와 직접 연동하는 목적으로 만들어지지 않은게 아닌가 싶다. 세밀한 조작이 힘들고 트랜잭션 처리도 서버 공부를 한 내가 느끼기에는 너무너무 투박하다. 진짜 분석 용도로 만들어진 느낌이 든다. (이런 요구사항이 크다면 Spring Batch를 고려해야한다)
이러한 것들을 방지하기 위해, 우리의 데이터 파이프라인을 외부에 독립적으로 만들기 위해 가운데 카프카를 두었다.
결과
어쨌든 이러한 복잡한 파이프라인을 거쳐서 사용량 기반 비용 정산 기능을 완성할 수 있었다. 이렇게 개선을 시킨 끝에
- 대용량의 데이터를 효과적으로 처리 -> 클러스터, 수평적 확장
- 처리량이 높으며 -> 카프카 버퍼로 활용
- 쿼리시 부하가 적은 -> 1시간 당으로 미리 윈도잉
기능을 완성할 수 있었다.
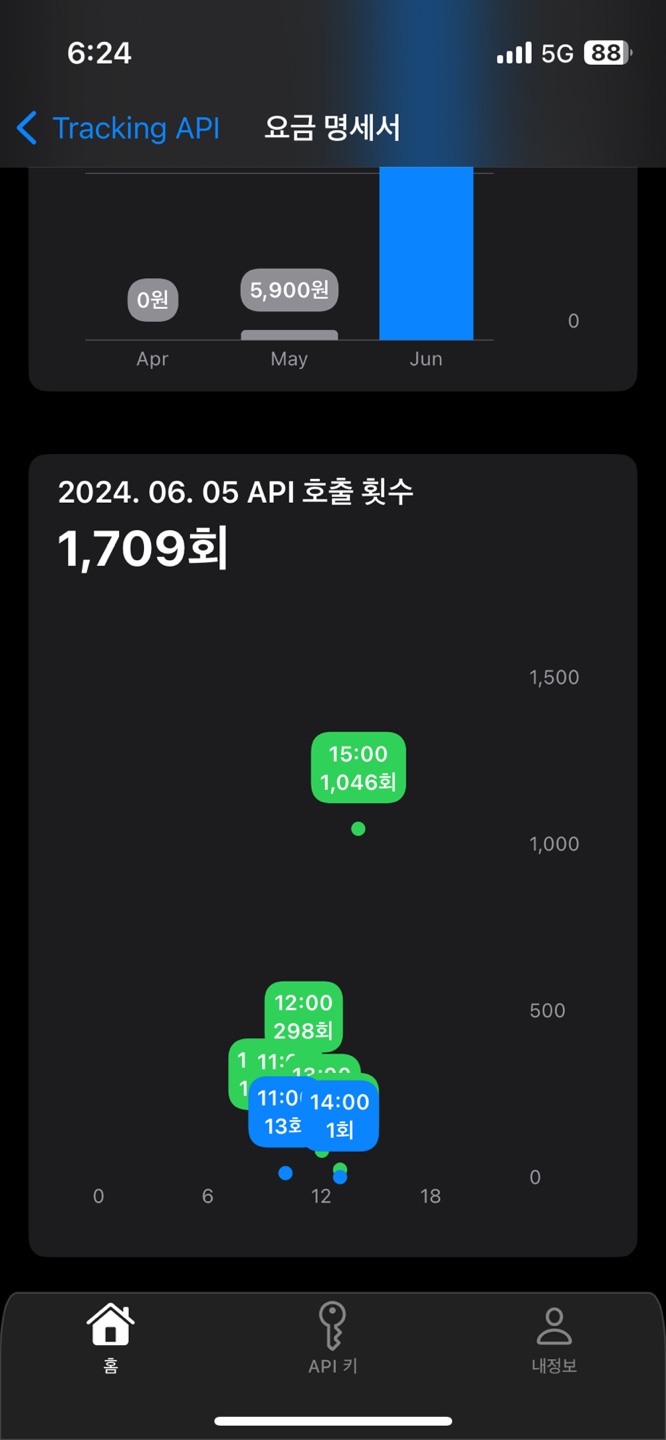
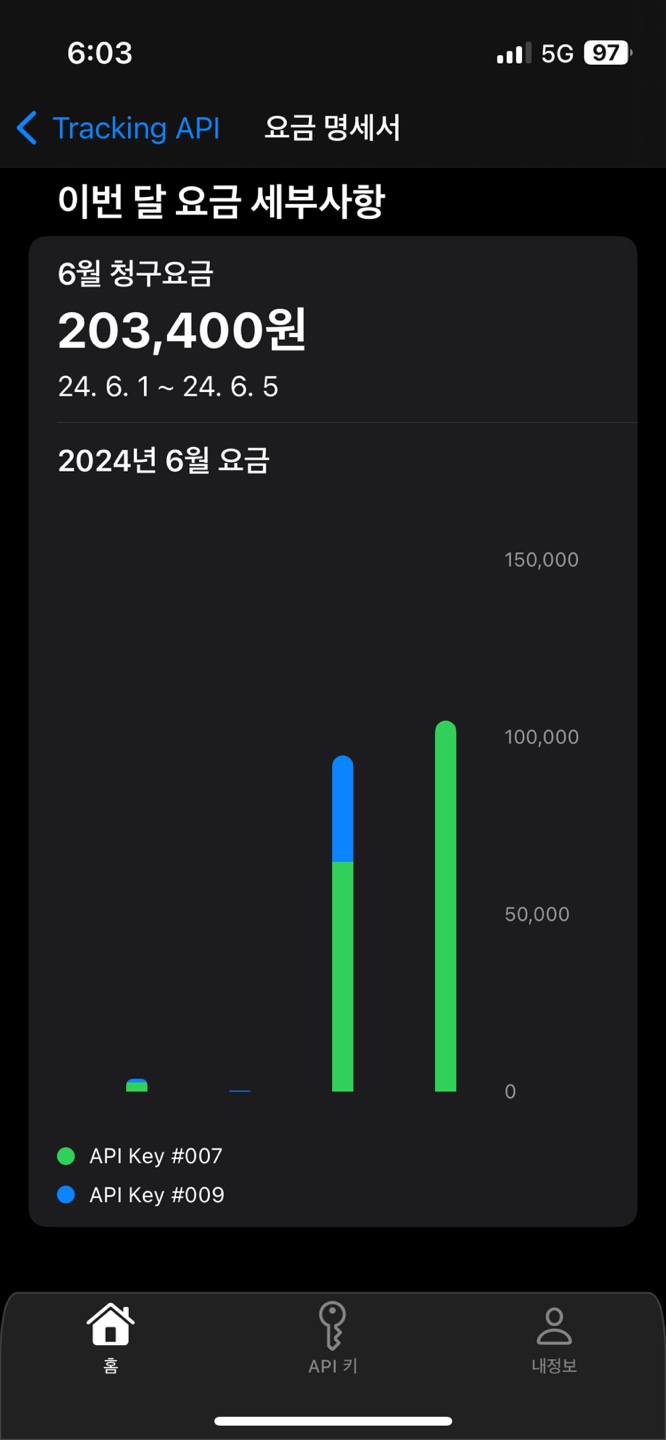
간단해 보이지만.. 정말 간단하지 않았다 ㅠㅠ
