실험 결과 공유 : 라즈베리파이 클러스터에 하둡과 쿠버네티스 동시 구축하기
사용 기기 : 라즈베리파이4B 4GB 4개 + 4코어 4GB 노트북 한대
편의상 아래와 같이 부르겠다
ras01
ras02
ras03
ras04
nb01하둡은 아래와 같이 구축했다.
ras01 - nn, yarn, dn
ras02 - dn
ras03 - dn
ras04 - dn
nb01 - db, secondary nn뻔한 구성이다.
쿠버네티스는 아래와 같이 구축했다.,
kube_control_plane:
hosts:
ras01:
nb01:
kube_node:
hosts:
ras1:
ras2:
ras3:
ras4:
nb01:
etcd:
hosts:
ras1:
ras2:
ras3:
k8s_cluster:
children:
kube_control_plane:
kube_node:
calico_rr:
hosts: {}간단하게 말하면 ras01이 가장 무거운 노드이다
hadoop : nn, resource_manager, dn
kube : api, etcd, 마스터
그리고 ras01에서 나서 리소스를 확인해보니
NAME CPU(cores) CPU% MEMORY(bytes) MEMORY%
node1 611m 15% 2750Mi 74%
node2 526m 13% 2245Mi 60%
node3 452m 11% 2668Mi 72%
node4 360m 9% 1452Mi 39%
node5 106m 2% 1651Mi 44%역시 ras01이 터질라고 한다.
대충 top 기준으로 리소스 사용량을 파이그래프로 그려보았다. (ras01기준)
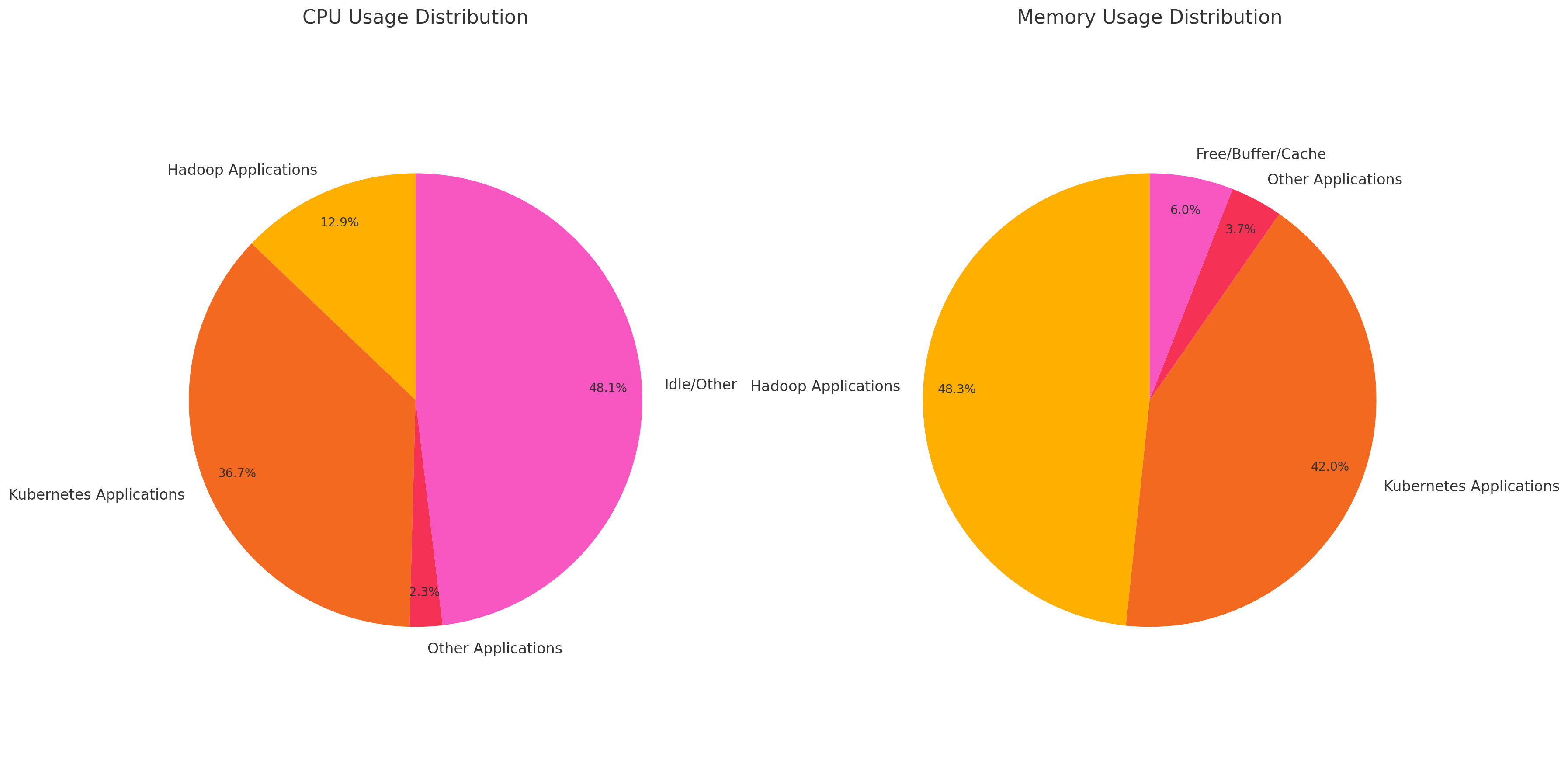
물론 주요 컴포넌트가 몰려서 그렇기는 하겠지만, 메모리 부분에서 너무 치명적이었다.
ras03의 경우에는 데이터 노드와 단순한 쿠버네티스 워커 노드만 담당하고 있는데
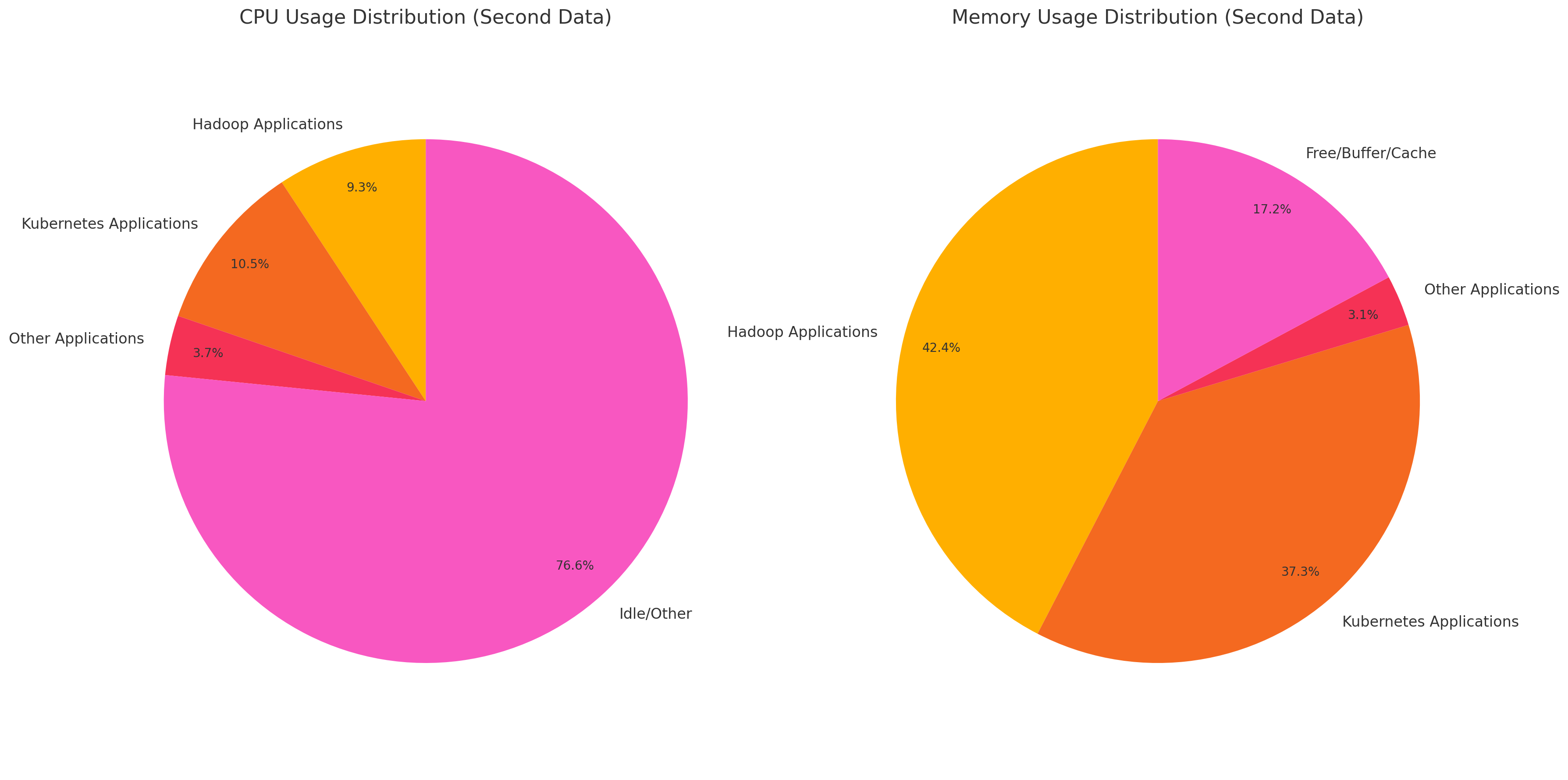
여기도 마찬가지로 쿠버네티스 메모리 사용량이 상당한 것을 볼 수 있다..
클러스터 갯수가 늘어나다 보니 쿠버네티스로 관리하면 어떨까 했었는데, 일단은 쿠버네티스를 들어내고, yarn 기반으로 클러스터를 운영해야겠다.
추후에 spark까지 돌리려면 메모리가 남아나질 않겠다.

더 좋은 구조를 고민하는 개발자 입니다