대회 개요
주제
- 데이터 제작 및 수정을 통한 이미지 속 글자 검청 성능 개선 대회
개요
- 데이터가 학습에 미치는 영향을 확인하기 위해 데이터 제작 및 수정이 가능하다.
- 데이터의 영향력을 확인하기 위해 모델, Optimizer 변경은 불가하고 Augmentation만 가능하다.
데이터
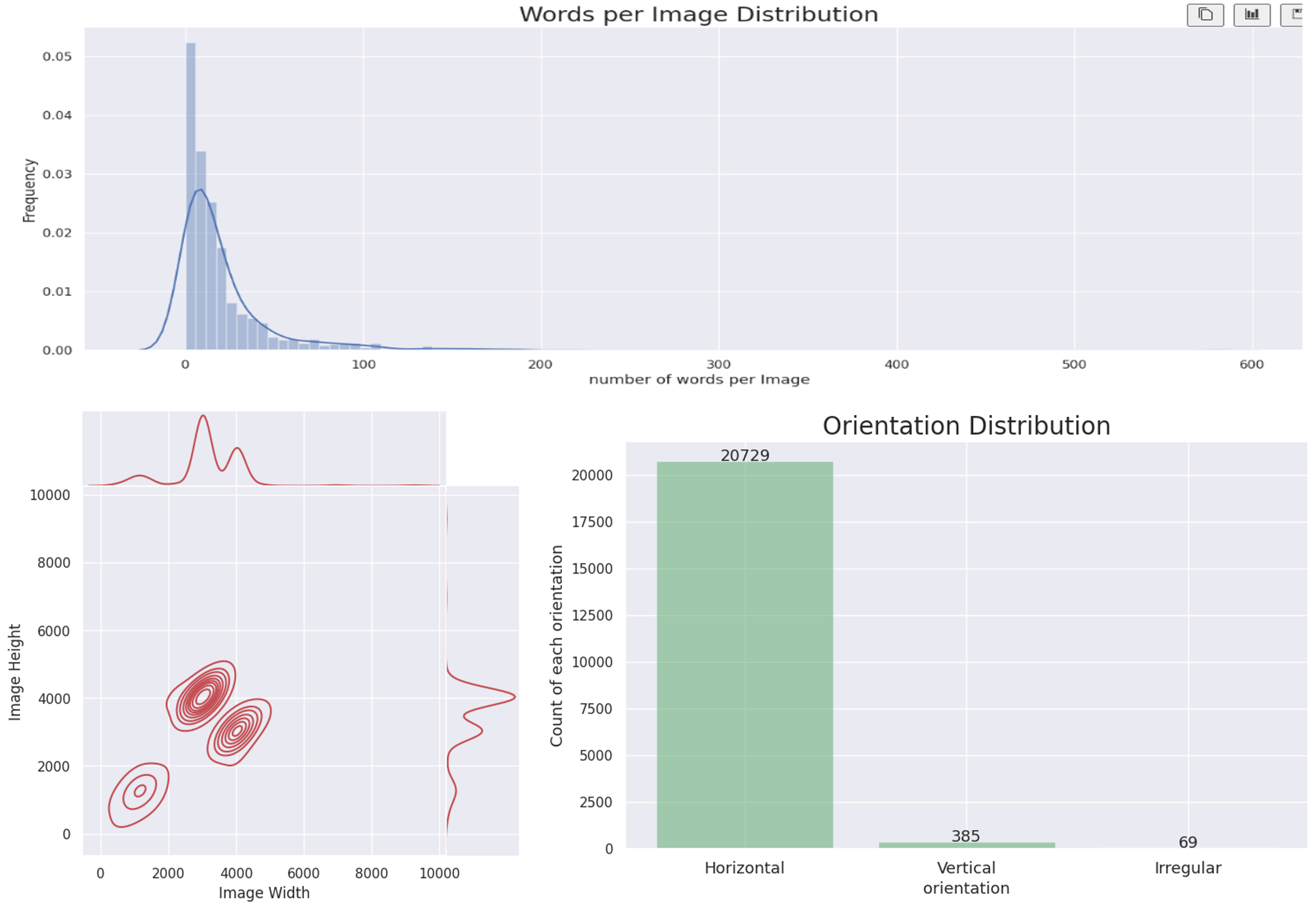
- ICDAR_Korean 데이터셋 536장 + Upstage Annotation Tool로 제작한 974장
- 총 Annotation 21,183개
- 아래 그래프는 이미지 당 Annotation의 수, Annotation 넓이 분포, Annotation 형태의 분포
문제 정의
1. Annotation의 불규칙성
- Upstage Annotation Tool로 제작한 데이터는 다수의 사람이 참여하였고, 최종 검수 작업이 없었다. 그 결과 Annotation에 일관성이 없었다.
2. 데이터의 불균형
- 세로로 쓰인 글자와 곡선 형태의 글자가 가로로 쓰인 글자보다 현저하게 적었다.
3. 곡선 형태 Annotation 처리
- 제공된 Baseline 코드에서는 사각형의 형태의 Bounding Box만 학습이 가능하여, 곡선 형태의 글자에 대한 전처리가 필요했다.
데이터 제작 및 검수 & Augmentation
데이터 제작 및 검수
- Upstage Annotation Tool을 이용하여 다수가 데이터 제작에 참여하였지만, 최종 검수하는 작업이 없었다. 그래서 팀 내에서 시각화 작업을 통해 통일된 규칙으로 데이터를 검수하였다.
- 다각형 형태의 Annotation의 경우, 사각형 형태로 변환을 해야 학습이 가능했다. 그래서 다각형의 최대 X, Y 좌표와 최소 X, Y 좌표를 이용하여 다각향 전체를 포함할 수 있는 사각형으로 변환하였다.
Augmentation
- 글자 이미지의 경우 상하 좌우가 명확하게 구분되기 때문에 Flip을 이용한 Augmentation은 진행하지 않았다.
- 글자 이미지의 특성상 글자와 배경의 경계가 명확해야 글자를 인식하기 수월하다고 판단하였고, CLAHE를 적용하여 경계선이 명확해지는 효과를 주었다.

개인 회고
- 데이터를 추가하고 수정하는 것만으로 유의미한 성능 향상으로 이어졌고, 이런 경험을 통해 데이터의 중요함을 다시 느낄 수 있었다.
- 또한 이미지의 특성에 맞는 Augmentation만으로 성능을 높일 수 있음을 확인하였다.
- 다만 외부 데이터를 추가하여 어느 정도 Noise가 존재하는 데이터의 증가가 성능 향상으로 이어지는 확인하는 실험을 진행하지 못한 점이 아쉬웠다.
- 일주일이라는 대회 기간 동안 데이터에만 집중하여 다양한 시사점을 얻을 수 있었고 이를 추후 진행할 대회와 프로젝트에 적극적으로 적용할 계획이다.

Hello!