최근 면접에서 클라우드 컴퓨팅과 관련한 개념을 묻는 아주 기본적인 질문이 나왔었다. 하지만 이에 대해 제대로 답변하지 못했다. 그래도 클라우드 컴퓨팅 교과목도 들었고 교육까지 수강했는데.. 내 자신이 부끄러웠다. 이번 기회에 노트에 끄적였던 클라우드 개념에 대해 다시 정리하고 복습하는 시간을 가졌다.
클라우드 컴퓨팅을 한 마디로 표현하면 ‘클라우드를 빌려 쓰는 것’이라 할 수 있다.
더욱 명확한 정의는 다음과 같다.
클라우드 컴퓨팅은 컴퓨팅 자원에 언제 어디서나 필요에 따라 편리하게 네트워크를 통해 접근하는 기능을 제공하는 것을 말하고, 컴퓨팅 자원은 최소한의 관리로 신속하게 프로비저닝되고 배포된다.
[미국국립표준기술연구소, NIST]
- 특징
- 온디맨드 셀프 서비스: 클라우드 서비스 제공자의 직접적인 관여없이 원하는 컴퓨팅 파워, 네트워크 스토리지 등을 자동으로 프로비저닝한다.
- 광대역 네트워크: 네트워크를 통해서 모바일 폰, 노트북, PDA와 같은 다양한 이기종 클라이언트를 통해 접근 가능하다.
- 리소스 풀링: 컴퓨팅 자원이 풀링되어 서로 다른 사용자가 자원을 나누어서 사용하는 멀티테넌트 모델이다.
- 신속한 탄력성: 컴퓨팅 자원을 신속하게 프로비저닝, 사용자의 요구량에 따른 자원을 탄력적으로 운영, 시간과 자원의 제약이 없는 것처럼 보인다.
- 사용량 측정: 사용자가 사용한 사용량과, 자원에 대한 모니터링이 투명하게 제공된다.
- 장점
- 자본 비용을 가변 비용으로 대체할 수 있다.
- 규모의 경제(하나보다 여러 개를 동시에 사는게 단가가 낮음)로 인한 이득을 취할 수 있다.
- 온디맨드로 인해 용량 추정이 불필요하다.
- 몇 번의 클릭으로 리소스를 확보 가능하기 때문에 개발비용이 절감된다.
- 영향을 준 기술들
- 클러스터링(Clustering): 여러 독립적인 IT 자원을 연결하여 마치 하나의 시스템(single system)과 같이 동작하도록 하는 기술
- 그리드 컴퓨팅(Grid Computing): 여러 개의 컴퓨터를 하나의 가상 슈퍼컴퓨터처럼 연결하여 대규모 연산 작업을 분산 처리하는 기술
🤔개념
데이터 센터
On-premise(이하 온프레미스): 기업이 자체적으로 보유한 물리적인 서버와 데이터 센터에 소프트웨어를 직접 설치하고 운영하는 방식
이때, 데이터 센터는 한 마디로 ‘서버가 모여있는 인프라를 관리하기 위한 공간’이라 할 수 있다.
데이터 센터: 어플리케이션의 서버를 호스팅하는 실제 시설
- 운영에 필요한 인프라: 컴퓨팅 시스템을 위한 하드웨어 / 네트워킹 장비 / 전원 공급장치 / 전기 시스템 / 백업 발전기 / 환경 제어장치 / 운영 인력 등
- 단점
- 많은 비용 소요: 건물 유지 비용, 서버 구매 비용, 셋업, 유지보수 등 비용이 많이 들고, 한 번 구매하면 수요에 상관없이 계속 보유해야 한다.
- 느린 구축시간: 사용자 수요에 빠르게 대처하기 힘들며, 장애 기기를 교체하는 데 시간이 많이 소요된다.
데이터 센터 vs 클라우드 컴퓨팅
클라우드 컴퓨팅을 통해 데이터 센터의 이슈를 해결할 수 있다.
| 데이터 센터 | 클라우드 컴퓨팅 | |
|---|---|---|
| 활용성 | 유휴 상태에 놓여있는 다수의 컴퓨팅 자원 | 자원이 필요할 때 필요한 만큼만 동적으로 자원을 확보 |
| 견고성 | 문제 자원을 분리하기 까다로움 | 자동화된 모니터링과 오토스케일링으로 문제 자원을 신속히 격리 및 대체 가능 |
| 복구성 | 장애 발생 시 물리적 장비 교체 및 수동 복구 필요, 복구 시간 장기화 | 장애 발생 시 가상머신 파일을 이동하거나 공유 스토리지를 통해 클라우드 컴퓨팅 인프라 내에서 빠른 복구 가능 |
| 비용 절감 | 건물 유지 비용, 서버 구매 비용 등 많은 비용 소요 | 자본지출을 운영지출로 대체 |
Service Model
클라우드에서 어떤 서비스를 제공하느냐에 따라 IaaS, PaaS, SaaS로 나눌 수 있다. 이때, 서비스 모델은 구현의 관점보다는 사용자 관점에서 기술된다.
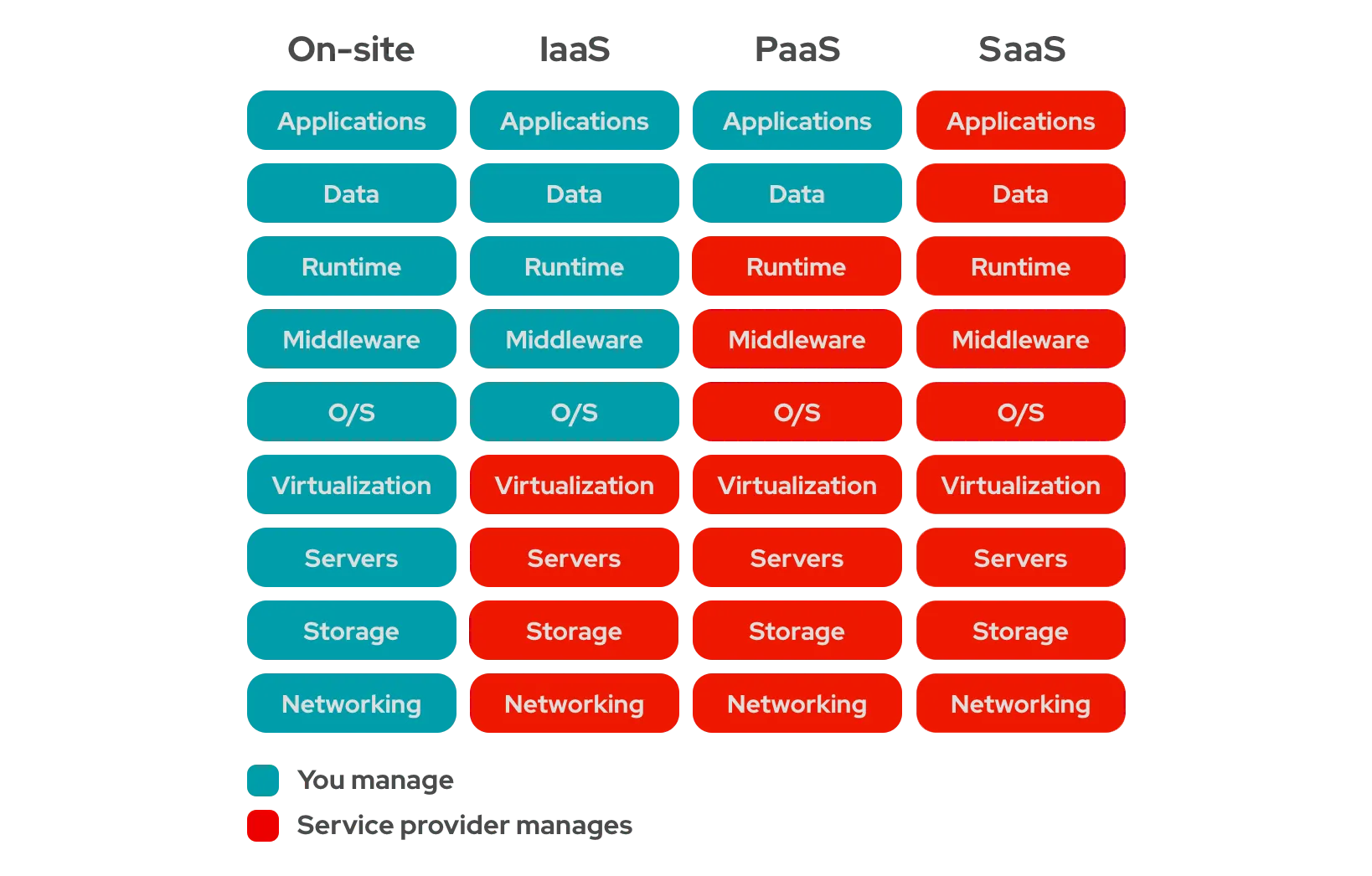
[출처: 레드햇]
Infrastructure as a Service(IaaS)
한 마디로 ‘주방만 빌리는 것’이라 할 수 있다.
인프라(물리적인 머신을 가상머신으로 제공)만 제공하는 형태이며, 일반적으로 네트워킹 기능, 컴퓨터(가상 또는 전용 하드웨어) 및 데이터 스토리지 공간을 제공한다. 따라서 사용자는 OS를 직접 설치해야 하며 그 위에 필요한 소프트웨어를 개발해서 사용해야 한다.
ex) AWS EC2 등
Platform as a Service(PaaS)
한 마디로 ‘주방에 더해 주방기기, 재료까지 빌려주어 레시피만 준비하면 되는 것’이라 할 수 있다.

인프라에 더해 운영체제와 기타 프로그램을 추가하여 제공한다. 따라서 사용자는 애플리케이션 개발과 관리에만 집중할 수 있다.
ex) Firebase, Google App Engine 등
- 특징
- 프로그램 개발자와 같은 특정 그룹에 중점을 둔다.
Software as a Service(SaaS)
한 마디로 ‘모두 다 빌리는 것’이라 할 수 있다.
- 특징
- 광대역 네트워크를 통한 소프트웨어 서비스, 사용한 만큼 비용을 지불한다.
- 개별 사용자에 중점을 둔다.
- 전통적인 소프트웨어 구매 방식과 차별화되는 서비스이다.
ex) Gmail, Slack 등
Deployment Models
클라우드 서비스 모델을 실제 서비스로 어떻게 제공하느냐에 따라 공개형(클라우드), 혼합형(하이브리드), 온-프레미스(폐쇄형)로 나눌 수 있다.
Public
클라우드 상에 완전히 배포되며 애플리케이션의 모든 부분이 클라우드에서 실행되는 형태이다.
- 특징
- 상대적으로 낮은 비용이 든다.
- 높은 확장성을 지닌다.
- 인프라가 일반 사용자에게 오픈된다.
Private
가상화 및 리소스 관리 도구를 사용하여 온프레미스에 리소스를 배포하는 형태이다.
- 특징
- 높은 수준의 커스터마이징이 가능하다.
- 보안성이 높다.
- 비싼 초기 비용과 유지보수 비용
- 인프라가 특정 기관의 사용자에게만 오픈되어 있다.
Hybrid(Public + Private)
- 사례
- IBK 기업은행 (공공 및 금융기관 최초 하이브리드 클라우드 기반 구축)
- 민감한 정보는 프라이빗 클라우드에 구성
- 대외기관과의 연계가 필요하거나 사용량에 대한 예측이 어려운 시스템은 퍼블릭 클라우드에 구성
- KB 국민은행
11월에는 기존 클라우드를 확장해 실시간 재해복구(DR)가 가능한 시스템 환경을 갖추겠다고 발표했다. 메인 데이터센터와 백업 데이터센터에서 각각 운영 중인 프라이빗 클라우드 용량을 확장해 멀티 어빌리티 존을 구축하겠다는 것이다. 이를 실제로 구현하기 위해 백업 센터의 프라이빗 클라우드 용량을 확장하고 자동화 수준을 높일 예정이다. 마이데이터 서비스 또한 퍼블릭 클라우드 기반으로 운영 중... [출처 : 녹색경제신문]
- IBK 기업은행 (공공 및 금융기관 최초 하이브리드 클라우드 기반 구축)
특징
고가용성
고가용성(Availability)이란 장애 상황을 해결하고 서비스를 지속할 수 있는 능력을 말한다.

T(sheduleshutdown) 계획된 셧다운은 제외한다.
내결함성
내결함성(Fault Tolerance) 또는 장애 내구성이란 장애 상황에도 서비스를 지속할 수 있는 능력을 말한다.
- 특징
- 비용 증가: 일반적으로 완전한 장애 내구성을 위해서 한 개 이상의 예비 인프라가 필요하다.
- 복잡성 증가: 이외에 두 개 이상의 인프라를 활용하기 위한 추가적인 아키텍쳐가 필요하다.
이와 같은 특징으로 인해 장애 내구성을 확보할 지에 대한 적절한 판단이 필요하다.
확장성
확장성(Scalable)이란 쉽고 빠르게 규모를 늘릴 수 있는 능력을 말한다.
탄력성
탄력성(Elastic)이란 수요에 따라 컴퓨팅 파워/용량을 확장하거나 축소할 수 있는 능력을 말한다.
대표적인 클라우드 컴퓨팅 서비스
인터넷을 통해 서버, 스토리지, 데이터베이스, 네트워킹, 소프트웨어 등을 제공하는 IT 서비스 모델이다. 사용자 또는 기업이 처한 상황이나 목적에 따라 잘 고려하여 적합한 CSP를 선택해야 한다.
AWS vs GCP vs Azure
| AWS | Azure | GCP | |
|---|---|---|---|
| 약어 | Amazon Web Services | - | Google Cloud Platform |
| 공급자 | Amazon | Microsoft | |
| 시작일 | 2006 | 2010 | 2011 |
| 시장 점유율 (24년 기준) | 31% | 20% | 12% |
| 장점 | 다양한 분야의 수 많은 서비스들을 종합적으로 제공하여, 사용자의 상황에 맞게 서비스를 조합하여 운영 가능 | 하이브리드 클라우드 활용성 우수 | 빅데이터(Bigquery), 머신 러닝(Tensorflow) 활용성 우수 |
| 거의 모든 DB 유형에 대해 완전 관리형 서비스를 제공 | Office 제품 등 자사의 다른 상품들과 긴밀하게 연결 | Google Analytics, Maps 등 자사의 다른 상품들과 긴밀하게 연결 | |
| 전세계에 많은 데이터 센터 보유하여, 서비스의 신뢰성, 견고성 우수 | 직관적인 가격 모델 | 비용 효율에 최적화 | |
| 온디맨드 서비스로, 사용한 리소스에 대해서만 비용을 지불 | 장기계약건에 대한 할인을 자주 제공 ⇒ 예상가능한 워크로드를 필요로 하는 사업에서 유리 | 스타트업 등 작은 범위의 서비스 제공하는 사업에 적합 | |
| 사용자 친화적 대시보드 제공 | 다양한 형식의 대량의 데이터 포인트를 관리하므로, 잦은 운영 최적화하는 데이터 중심 기업에 적합 | ||
| 단점 | 가격 구조가 다소 복잡하고, 문제를 처리하기 어려움 | 효율성이 떨어지는 관리 툴 | 다소 부족한 글로벌 데이터 센터 |
| 대표적 서버/스토리지/데이터베이스 | EC2/S3/RDS | Virtual Machines/Blob Storage/Azure SQL Database | Compute Engine/Cloud Storage/Cloud SQL |
| 가격 (상대적 비교) | 상 | 중 | 하 |
| 프리티어 | 12개월, 매월 750시간의 EC2 t2.micro 인스턴스 무료, 5GB의 S3 스토리지무료 | 12개월, $200 크레딧으로 30일 간 모든 서비스 체험 | 매월 1개 서비스(f1-micro VM 인스턴스, 5GB 스토리지 등) 무료 제공 |
AWS의 EC2 리소스는 컴퓨팅 성능에 따라 다양한 인스턴스 패밀리가 존재한다. 따라서 고성능의 그래픽, 메모리 성능을 지원하는 G, X와 같은 인스턴스 패밀리의 경우 상당히 높은 시간당 요금이 책정되어 있다. 이는 인공지능, 빅데이터를 처리하기 위해 많은 컴퓨팅 리소스가 필요하고, 이를 지원하는 서버 리소스에 해당하는 서비스(AWS EC2, Azure VM, GCP Compute Engine 등)들이 필수적이기 때문이다.
SLA(Service Level Agreement)
| AWS | Azure | GCP | |
|---|---|---|---|
| SLA | 서비스별로 개별적으로 제공 | 가용성 집합과 가용성 영역 개념을 나누어 제공 | 서비스별로 개별적으로 제공 |
| 예시 | EC2: 월간 가동 시간 99.99% 보장 | VM: 99.9% 보장 | Compute Engine: 월간 가동 시간 99.99% 보장 |
| 보상 | EC2: 리전 수준과 인스턴스 수준으로 나뉘며, 월간 가동률에 따라 서비스 크레딧 백분율이 상이 | AWS와 대동소이 | AWS와 대동소이 |
데이터 센터 운영에서 Human Error로 발생한 사고 사례
Summary of the Amazon S3 Service Disruption in the Northern Virginia (US-EAST-1) Region
Amazon S3 서비스 장애(2017)
2017년 2월 28일, Amazon S3 서비스는 미국 북부 버지니아 리전(US-EAST-1)에서 장애가 발생했다. S3 팀은 빌링 시스템이 예상보다 느리게 진행되는 문제를 디버깅 중이었고, 이를 해결하기 위해 일부 서버를 제거하는 명령을 실행했다. 하지만 명령 입력 오류로 인해 더 많은 서버를 제거했고, 이로 인해 메타데이터와 객체 위치 정보를 관리하는 ‘index subsystem’과 새로운 객체의 저장 공간 할당을 담당하는 ‘placement subsystem’이 중단되었다.
두 시스템의 대규모 용량 손실로 인해 전체 재시작이 불가피했고, 이로 인해 S3는 일시적으로 모든 요청(GET, LIST, PUT, DELETE)을 처리할 수 없게 되었다. 또한 S3에 의존하는 EC2 인스턴스, EBS 볼륨, AWS Lambda 등 여러 서비스도 영향을 받았다. ‘index subsystem’은 약 세시간 후 일부 기능을 복구했고, 완전한 복구는 1시 18분(태평양 시간 기준)에 완료되었다.
참고자료
AWS 강의실 (리뉴얼)쉽게 설명하는 AWS 기초강의
Cloud Providers Compared: A Comprehensive Guide to AWS, Azure, and GCP
d1.awsstatic.com
