
RDS (Relational DB Service)
AWS RDS에서 사용한 DB는 다음과 같다
Microsoft SQL, Oracle, MySQL, Postgre, Aurora, Maria DB
Data Warehousing
Business Intelligence에 사용되는 매우 방대한 분량의 데이터 즉 빅 데이터를 로드할 시에 사용된다.
OLTP vs OLAP
-
OLTP : insert와 같이 종종 사용되어 지는, 규모가 작은 데이터를 불러올 때 사용되는 SQL 쿼리가 필요할 때 유용하다.
-
OLAP : 매우 큰 데이터를 불러올 때 사용하며 주로 덩치가 큰 SELECT 쿼리가 사용된다.
Database Backups
AWS 데이터베이스 백업에는 두 가지의 종류가 존재한다. Automated Backups와 DB Snapshots이 그 종류이다.
Automated Backups(AB) - 자동 백업
- Retention Period(1-35일)안의 어떤 시간으로 돌아가게 할 수 있다.
- AB는 그날 생성된 스냅샷과 Transaction Logs(TL)을 참고한다.
- 디폴트로 AB기능이 설정되어 있으며 백업 정보는 S3에 저장한다.
- AB동안 약간의 I/O suspension이 존재할 수 있다. (Latency)
DB 스냅샷
- 주로 사용자에 의해 실행된다
- 원본 RDS Instance를 삭제해도 스냅샷은 존재한다.
스냅샷만으로 백업을 진행할 수 있다.
데이터베이스를 백업을 하면 RDS Instance와 RDS Endpoint가 새로 생성된다. 새로운 객체가 생성된다는 것이다.
Multi AZ
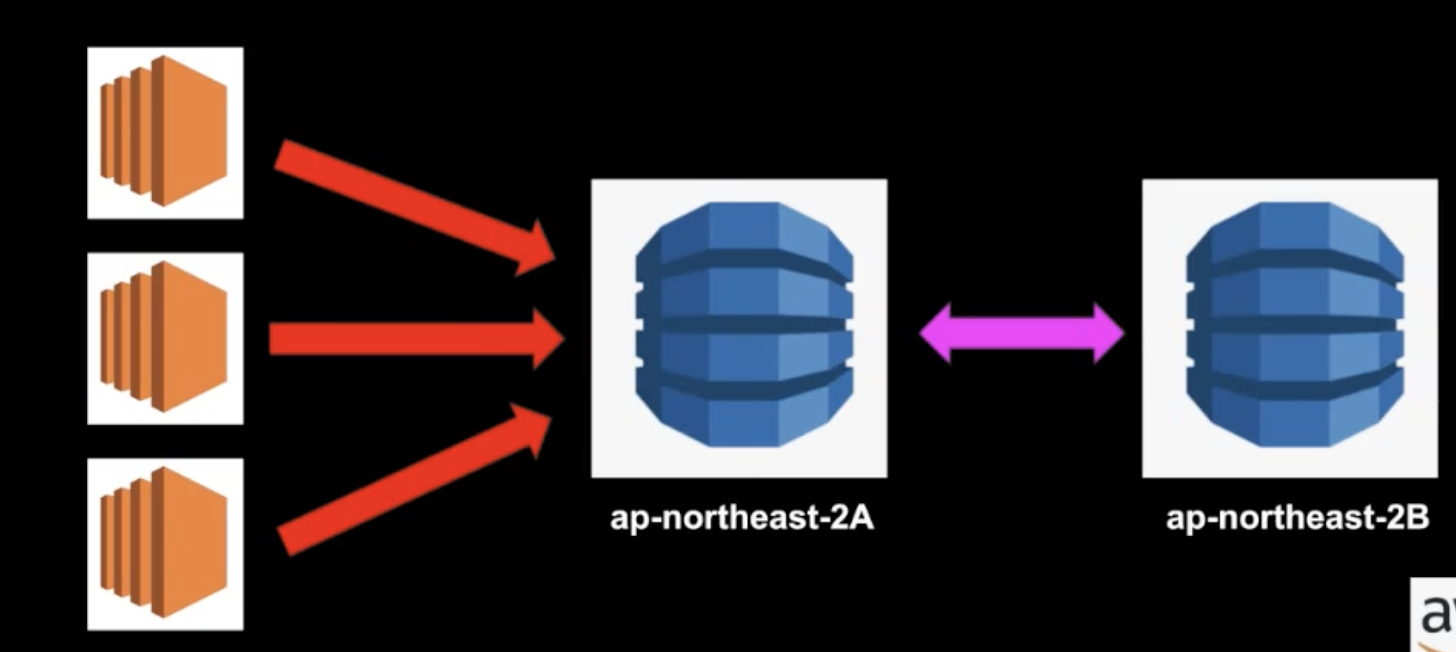
- 원래 존재하는 RDS DB에 무언가 변화가 생길때 다른 Availability Zone에 똑같은 복제본이 만들어짐
- AWS에 의해 자동으로 관리가 이뤄짐
- 원본 RDS DB에 문제가 생길 시 자동으로 다른 AZ의 복제본이 사용
- Disaster Recovery Only
성능 개선을 위해서 사용되지는 않는다. 위 사진을 살펴보자 AWS는 자동으로 2A의 RDS를 2B로 복제한 뒤 2A에서 문제가 발생하면 자동으로 2B를 참고하여 데이터베이스를 꺼낸다. 재해 복구 시간이 현저히 감소된다.
Read Replica
Read Replica는 Multi AZ와 다르게 쓰기가 사용되는 것이 아니라, 읽기 전용 Database가 생성되는 것이다. Disaster Recovery 용도가 아니라, 성능 개선 용으로 사용 된다. 특징은 아래와 같다.
- Production DB의 읽기 전용 복제본 생성
- DB작업 시 효율성의 극대화를 위해 사용됨
- 최대 5개 Read Replica DB허용
- Read Replica의 Read Replica 생성 가능
- 각각의 Read Replica는 자기만의 고유 Endpoint 존재
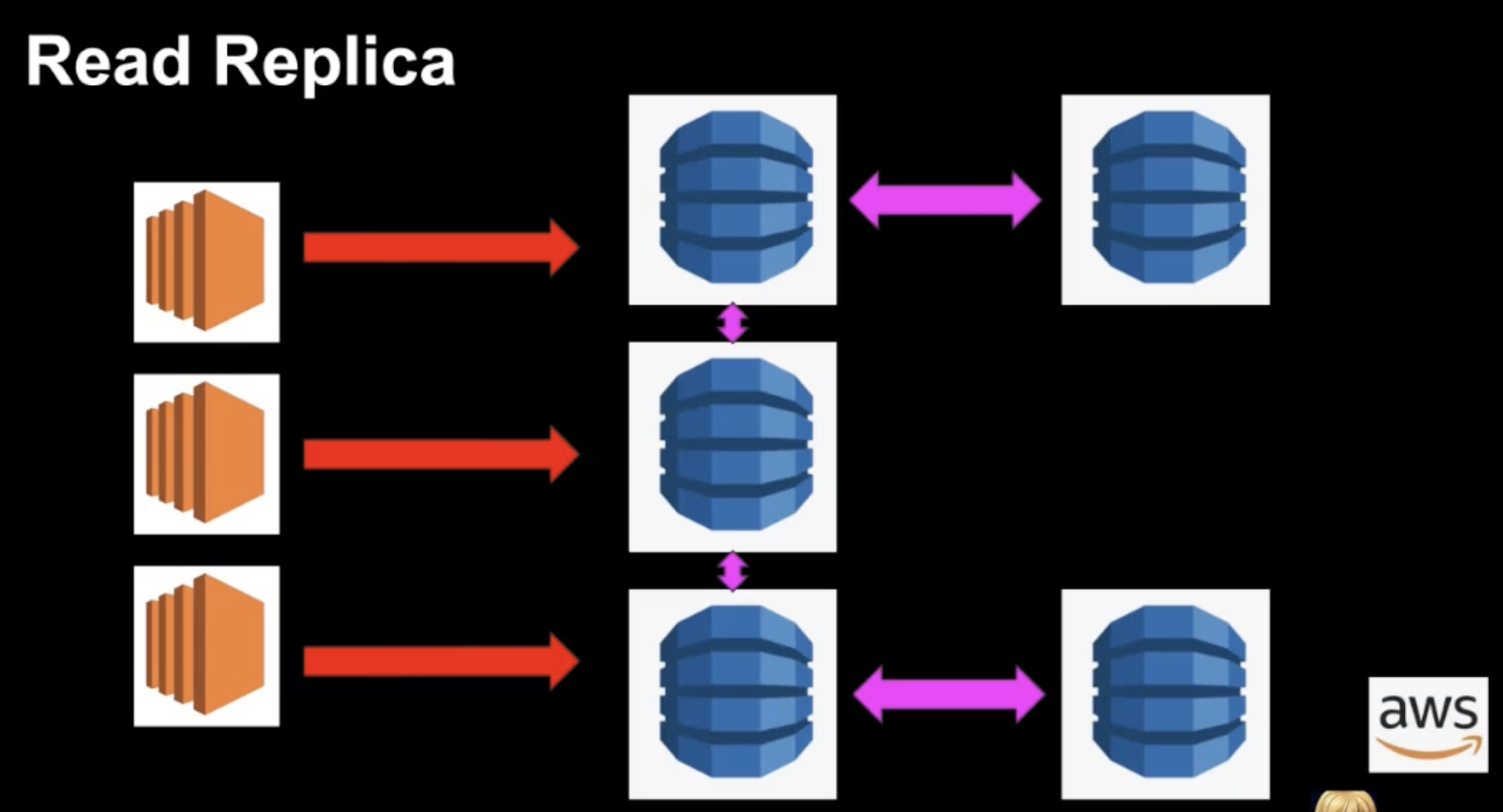
위 사진을 살펴보면 복제한 RDS를 각각의 EC2에 제공함으로써 성능을 크게 향상시킬 수 있다. 또한, Read Replica에서 또다른 Read Replica를 생성할 수 있는 특징도 가지게 된다.
ElastiCache
RDS의 특징은 아니고, RDS에 더 효율적인 퍼포먼스를 제공한다. 특징은 다음과 같다.
- 클라우드 내에서 In-memory 캐시를 만들어줌
- 데이터베이스에서 데이터를 읽어오는 것이 아니라 캐시에서 빠른 속도로 데이터를 읽어옴
- Read-Heavy 어플리케이션에서 상당한 Latency 감소 효과 누림
데이터의 양이 방대할 때 굉장히 유용하게 사용된다. 두 가지의 다른 타입이 존재한다. 첫 번째는 Memcached이고, 두 번째는 Redis이다.
Memcached
- Object 캐시 시스템으로 잘 알려져 있음
- ElastiCache는 Memcached의 프로토콜을 default로 따름
- EC2 Auto Scailing 처럼 크기가 커졌다 작아졌다 가능함
Memcached를 사용하는 환경은 간단하다. 캐싱 모델이 간단할 경우와 캐시 크기를 마음대로 Scaling하기를 원할 때 사용하여야 한다.
Redis
Set,List와 같은 형태의 데이터를 In-Memory에 저장 가능하다. Mulit AZ를 지원하기 때문에 Disaster recovery가 가능하다. 또한, 리더보드처럼 데이터셋의 랭킹을 정렬하는 용도가 필요할 때 Redis를 사용할 수 있다.
