
스토리지 (S3)
클라우드 스토리지 개요
- 블록 스토리지
원시 스토리지 데이터가 관련없는 블록의 어레이로 구성된다. - 파일 스토리지
파일 시스템이 관련없는 데이터 블록을 관리한다. 네이티브 파일 시스템이 디스크에 데이터를 배치한다 - 객체 스토리지
데이터, 데이터 속성, 메타데이터, 객체 ID를 캡슐화하는 가상 컨테이너를 저장한다.
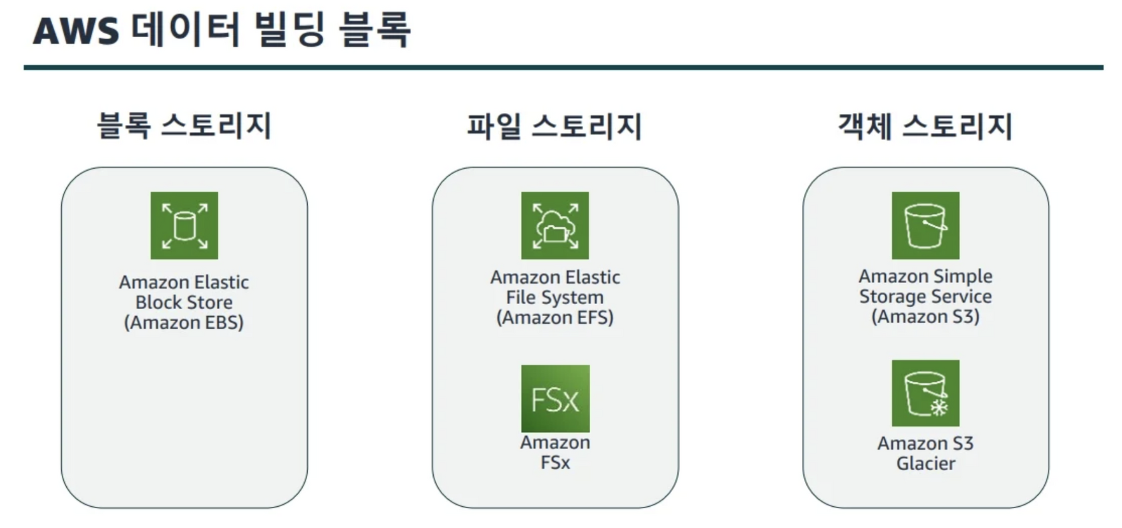
S3는 내구성, 고가용성이 높으며 최상의 수평 확장성을 특징으로 갖는다.
S3 Storage Class
S3의 종류는 다양하며 상황과 종류에 맞게 사양해줄 수 있다.
- Standard
자주 쓰는 데이터를 저장한다. 자주 쓰는 데이터란 30일을 기준으로 한 번 이상 Access하는 data를 의미한다. 저장 비용은 높지만 호출 비용이 낮은 특성을 갖는다. - IA(Infrequent Access)
- OneZone IA
가용성이 떨어진다 - Glacier
빙하라는 이름에 맞게 많이 호출하지 않는 데이터를 쓸 때 사용한다. 그렇기 때문에 저장 비용이 낮고, 호출 비용이 높다. 데이터 전환 비용이 각각의 개체에 다 부과되기 때문에 압축한 다음에 이용하는 것이 비용을 아낄 수 있다.
공유 파일 시스템 (NAS)
S3는 write many 하기에는 어울리지 않는다. 그렇기 때문에 동시에 작성해야 할 일이 많다면 NAS를 사용해야 한다.
- EFS - Linux
- FSX - Windows
데이터베이스 서비스
RDS(SQL)
RDS에는 여러 종류가 존재하는데, 가장 생소한 것이 Aurora이다. Aurora는 Aws가 만든 것으로 MySQL, PostgreSQL과 호환이 된다.
DynamoDB(NoSQL)
mongoDB와 비슷하다고 생각하면 된다. key, value값으로 저장이 되며 DB이름, PK만 지정하면 Database를 만들어줄 수 있다.
모니터링 및 크기 조정(AutoScaling)
EC2 Auto Scaling은 수평적 스케일링을 의미한다. 그렇기 때문에 AutoScaling을 통해 늘어나는 인스턴스에 대한 가격은 따로 내야 한다.
모니터링
CloudWatch
성능 수준에 대한 지표를 나타내며 경보를 생성하고 알림을 전송한다. 또한, 대시보드를 생성할 수 있다.
Cloudtrail
감사용, 계정 API에 대한 Log를 기록한다
Auto Scaling
언제 하나?
Auto Scaling을 하는 시점은 크게 3가지가 존재한다.
1. event - 특정한 상황이 발생했을 때 Scaling을 진행한다.
2. Schedule - 스케줄을 지정하여 해당 스케줄에 Auto Scaling을 진행한다.
3. ML - EC2 사용 데이터를 가지고 분석한 뒤에 자동으로 Auto Scling을 진행한다.
Best Practice는 event를 기반으로 해야한다. 하지만, 서버에 많은 인원이 들어올 것을 알고 있을 경우에는 Schedule을 기반으로 진행해야 한다.
얼마나 많이 Auto Scaling?
Auto Scaling을 세팅할 때 desired, min, max 값을 설정해주어서 어느정도로 Auto Scaling을 진행해줄 수 있다.
Load Balance
Load Balance에는 3가지의 종류가 존재한다.
- Application Load Balancer
L7 Layer에서 Load Balance를 진행하고, HTTPS, HTTP 트래픽에 대해 로드 밸런싱을 진행한다. - Network Load Balancer
L4 Layer에 대한 Load Balance를 진행하고 TCP, UDP 트래픽에 대한 로드 밸런싱을 진행한다. 또한 NLB는 고정 IP 주소를 가지고 있다. - GLB
위 종류들과는 조금 성격이 다르다. Third Party에 관한 것에 대해 Load Balancing을 진행해준다.
자동화
Template
JSON이나 YAML을 사용하여 자동화를 위한 템플릿을 만든다. 템플릿을 통해 만든 리소스를 Stack이라 부른다. Stack을 통해 생성된 리소스는 Stack이 지워지게 되면 같이 지워진다. MSA 아키텍쳐를 구성할 경우 Stack을 통해 배포하면 재사용성이 높아진다.
실습
실습 1 - VPC 인프라에 데이터베이스 계층 생성
개요
어떤 환경에서나 백엔드 데이터베이스는 중요하다. 이번 실습에서는 Aurora DB 클러스터를 생성하여 MYSQL 데이터베이스와 Application Load Balancer(ALB)를 관리한다. ALB는 프런트엔드 애플리케이션을 호스트하는 정상 EC2인스턴스로 트래픽을 라우팅함으로써 고가용성을 제공하고 Private Subnet의 ALB 뒤에서 데이터베이스와의 통신이 이루어지도록 한다.
실습 환경
실습을 진행하기 전에 제공되는 리소스는 Amazon VPC, 네트워크 구조, 인바운드 및 아웃바운드 트래픽 제어용 보안 그룹 3개, 프라이빗 서브넷의 EC2 인스턴스 2개, 관련 EC2 인스턴스 프로파일 1개이다.
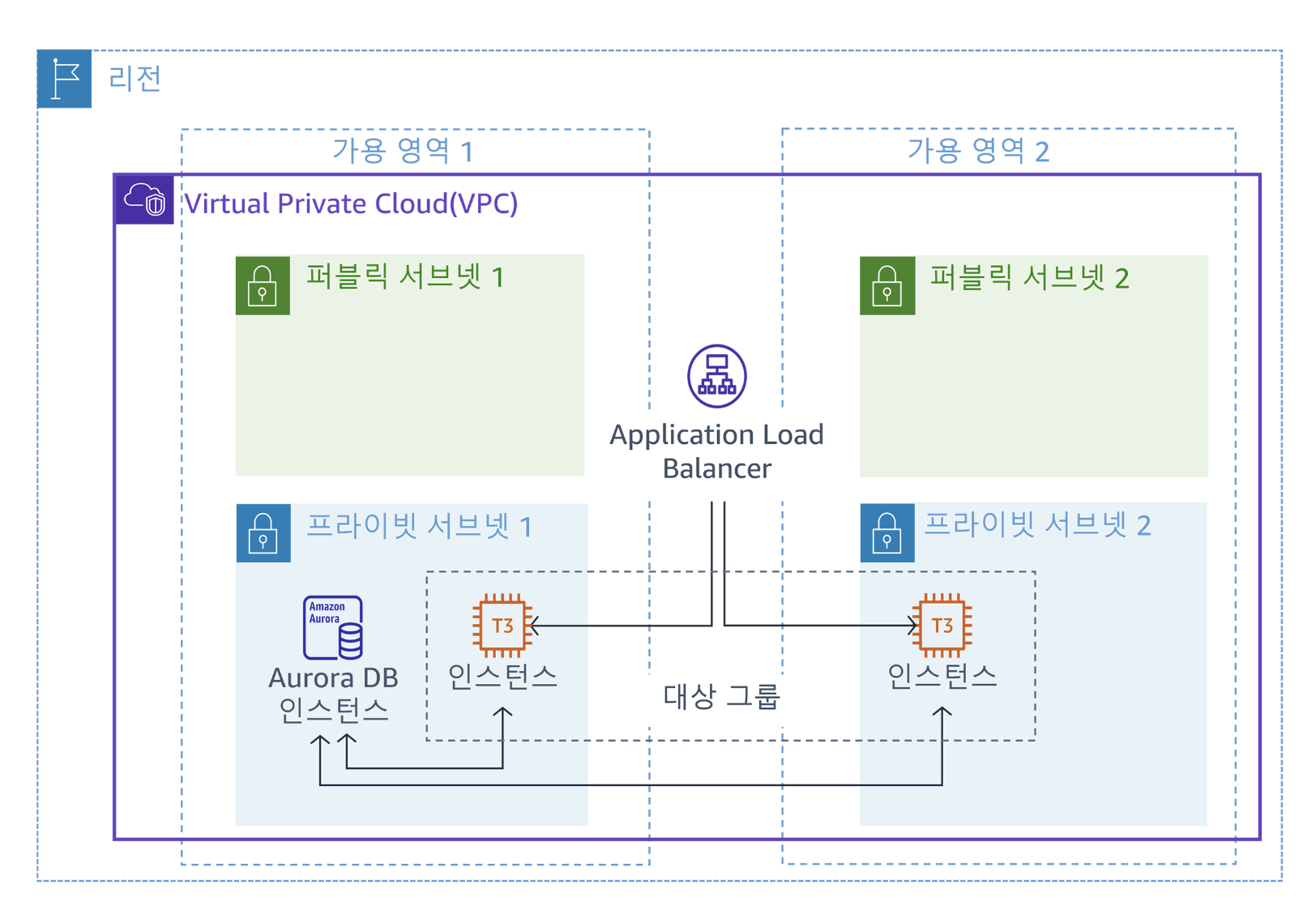
결론부터 말하면 위 아키텍쳐를 그리는 실습을 진행할 것이다.
RDS 생성
실습환경에서 주어진 대로 RDS를 생성해준다. 여기서 DB서브넷을 설정하게 되는데, DB 서브넷 그룹은 사용자가 Amazon VPC에서 생성한 다음 DB 인스턴스에 대해 지정하는 서브넷의 모음이다. DB 서브넷 그룹에서는 CLI 또는 API를 사용하여 DB 인스턴스를 생성할 때 Amazon VPC를 지정할 수 있다. 콘솔을 사용하는 경우 사용할 Amazon VPC와 서브넷만 선택할 수 있다.

아직 생성 중이지만 완성된 RDS를 확인할 수 있다.
ALB 생성 및 구성
로드 밸런서는 클라이언트에 대한 단일 접점 역할을 수행한다. 클라이언트는 로드 밸런서에 요청을 전송하고, 로드 밸런서는 EC2 인스턴스와 같은 대상에 요청을 전송한다. 로드 밸런서를 구성하려면 대상 그룹을 생성한 다음 대상 그룹에 대상을 등록한다.
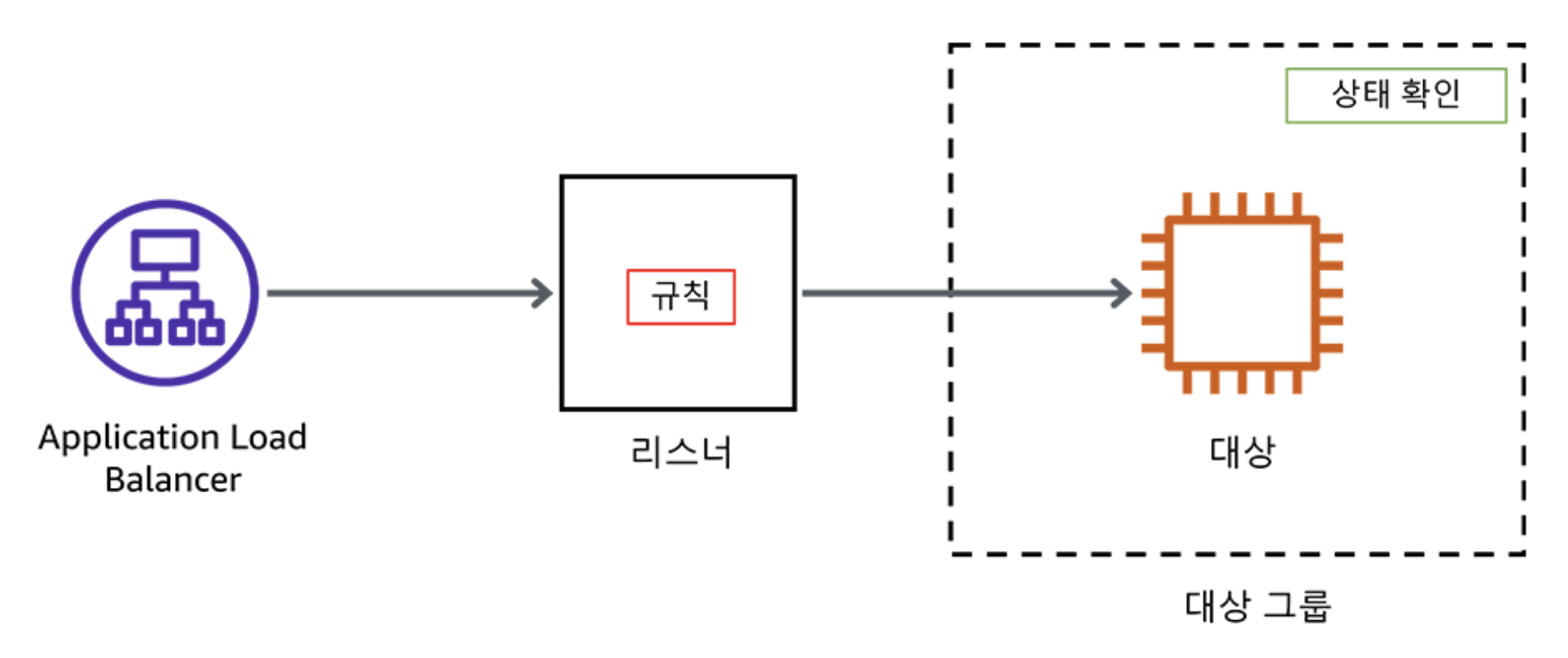
ALB 대상 그룹 생성
실습 환경에 맞게 ALB target Group을 생성한다
Application Load Balancer 생성
위에서 만든 ALB target Group은 ALB를 생성할 때 Listener를 설정해주면서 사용된다.
실습 환경대로 ALB를 생성하면 아래와 같이 ALB를 성공적으로 생성할 수 있다.
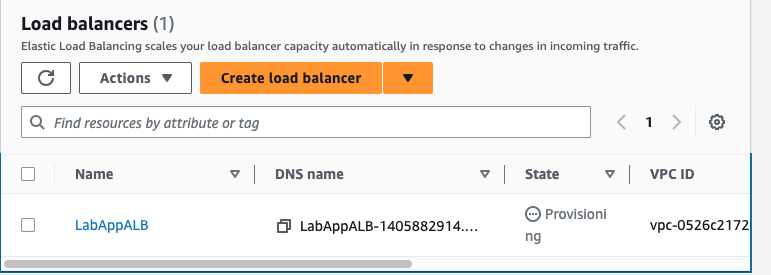
ALB를 생성하고 EC2 인스턴스를 로드 밸런서에 대상으로 추가해주었다.
RDS 관찰
우선 RDS는 콘솔에서 확인해줄 수 있다. 만들어준 RDS로 돌아가서 상세 정보를 클릭하면 아래와 같이 관리해줄 수 있는 창으로 들어갈 수 있다.
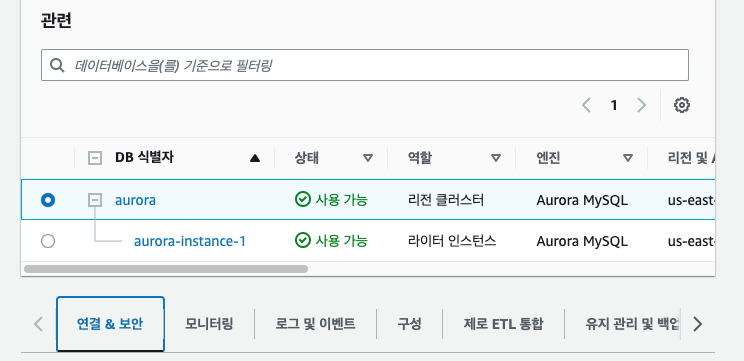
콘솔 뿐만 아니라 애플리케이션에서 DB연결을 확인할 수 있다.
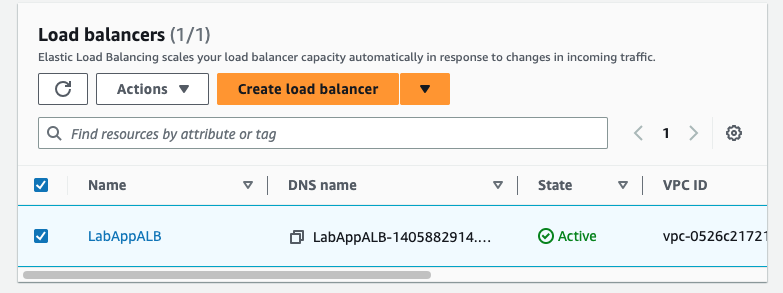
다시 Load Balancers창으로 돌아가서 위에 보이는 Dns Name을 복사한 뒤 웹에 입력해준다.
성공적으로 완료하면 위와 같은 페이지가 표시된다. 상단 우측에 보이는 Settings 버튼을 누른 뒤 EndPoint(writer instance endpoint), Database, Username, Password를 입력하면 본인이 생성한 RDS를 관리할 수 있게 된다.
성공이다.
실습 2 - Amazon VPC에서 고가용성 구성
실습 개요
Amazon 오피스 교육을 받으면서 고가용성이라는 단어를 많이 들었다. AWS는 클라우드에서 안정적이고 내결함성이 있으며 가용성이 뛰어난 시스템을 구축하기 위한 서비스와 인프라를 제공한다.
내결함성은 시스템을 구축하는 데 사용되는 일부 구성 요소에 장애가 발생해도 계속 작동할 수 있는 시스템의 능력이다.
고가용성은 시스템 장애를 예방하는 것이 아니라 장애에서 빠르게 복구하는 시스템의 능력이다.
이번 실습에서는 Elastic Load Balancing과 Auto Scaling 그룹을 통합한다. EC2 인스턴스의 Auto Scaling 그룹을 생성한 다음, Auto Scaling 그룹 내 인스턴스 간에 부하가 균형있게 전달되도록 ALB를 구성한다. 계속해서 다중 AZ를 허용하고 읽기 전용 복제본을 생성한 후 승격하는 등 Amazon Relational Database Service를 사용해본다. 읽기 전용 복제본을 사용할 경우 데이터를 Primary Database에 쓰고 읽기 전용 복제본에서 읽을 수 있다. 읽기 전용 복제본은 Primary Database로 승격할 수 있으므로 고가용성과 재해 복구에 유용한 도구이다.
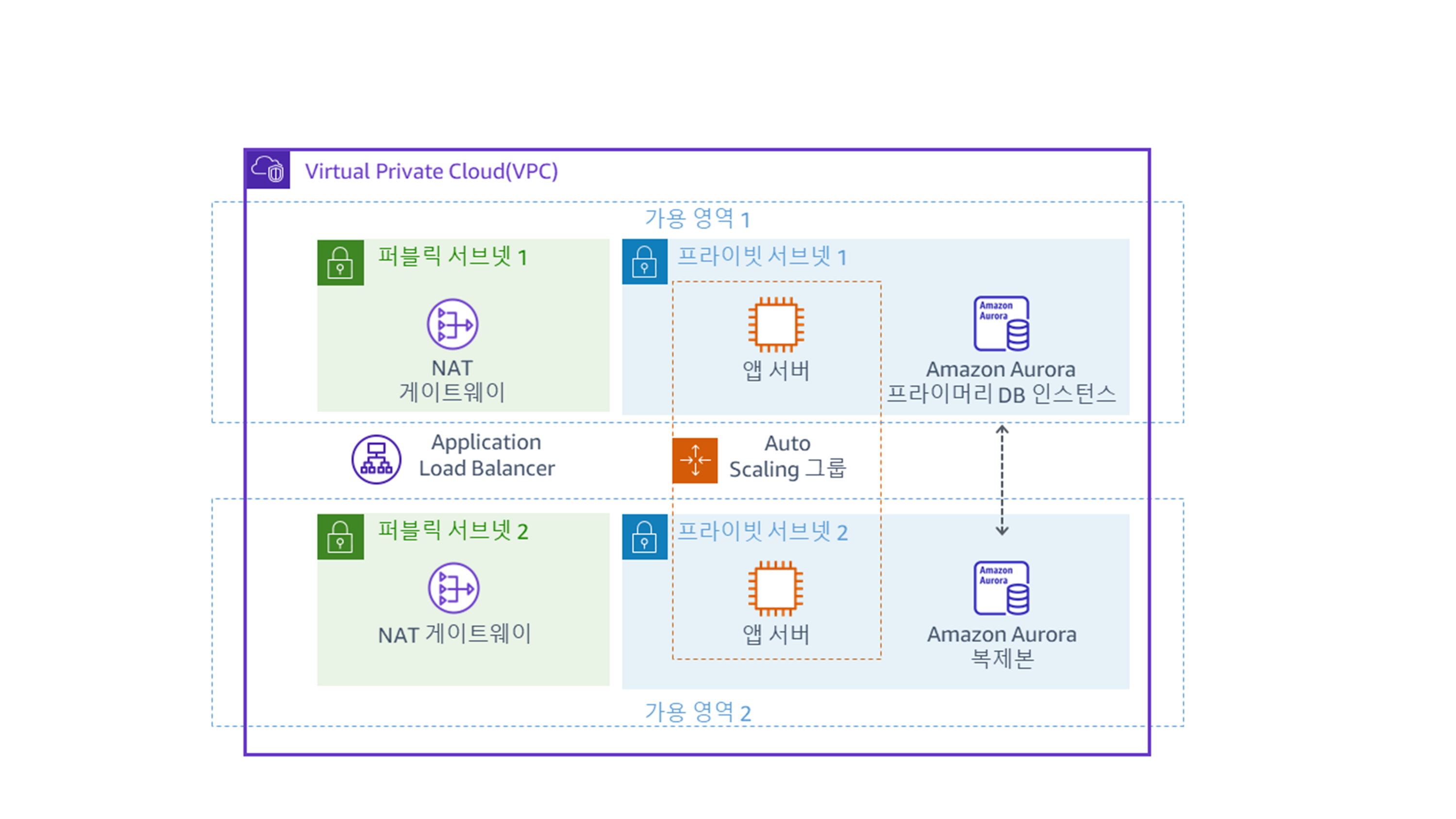
이번 실습에서 진행할 최종 아키텍쳐는 다음과 같다.
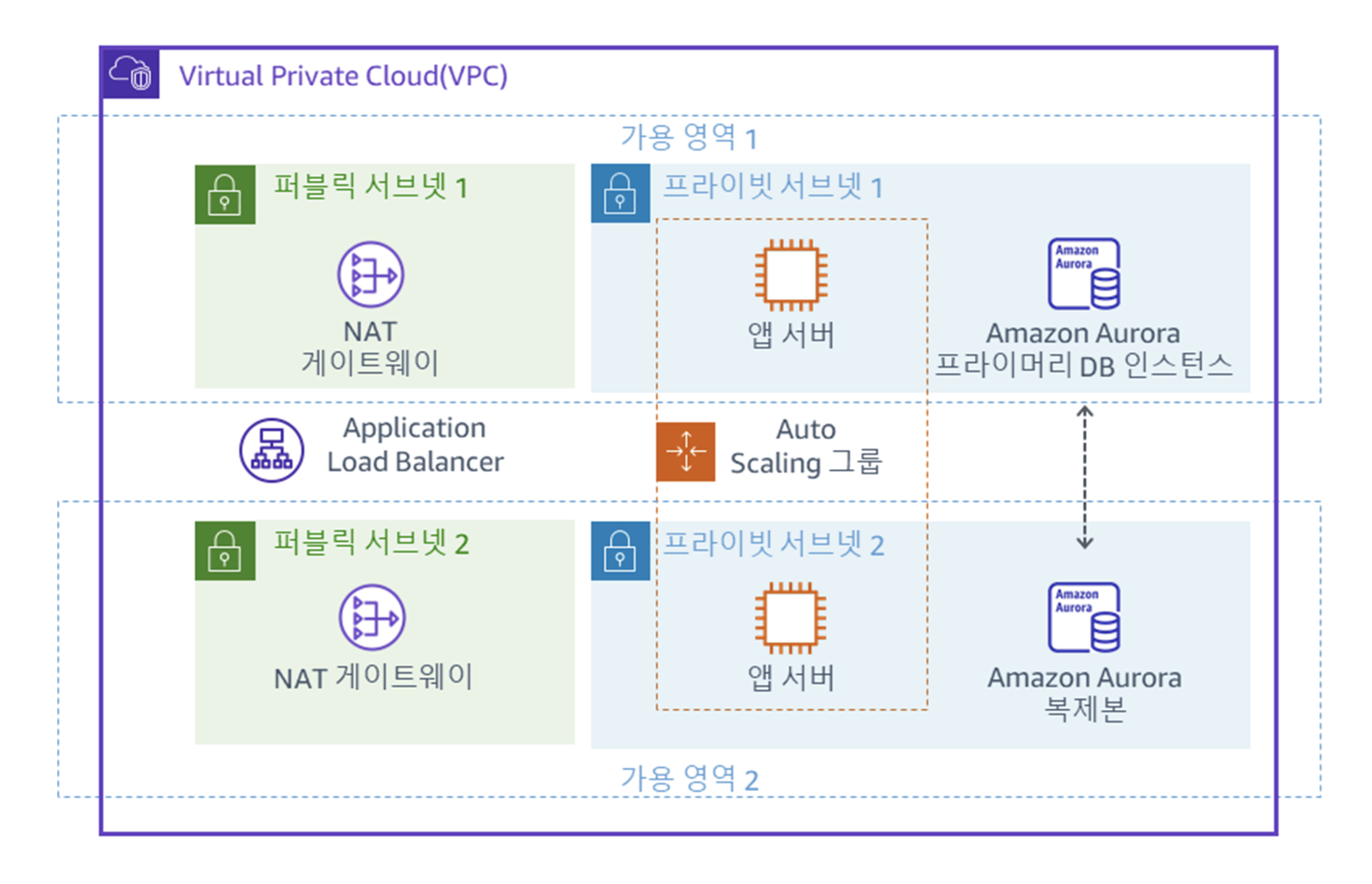
최초 제공 아키텍쳐
최초로 제공되는 아키텍쳐는 아래와 같다.
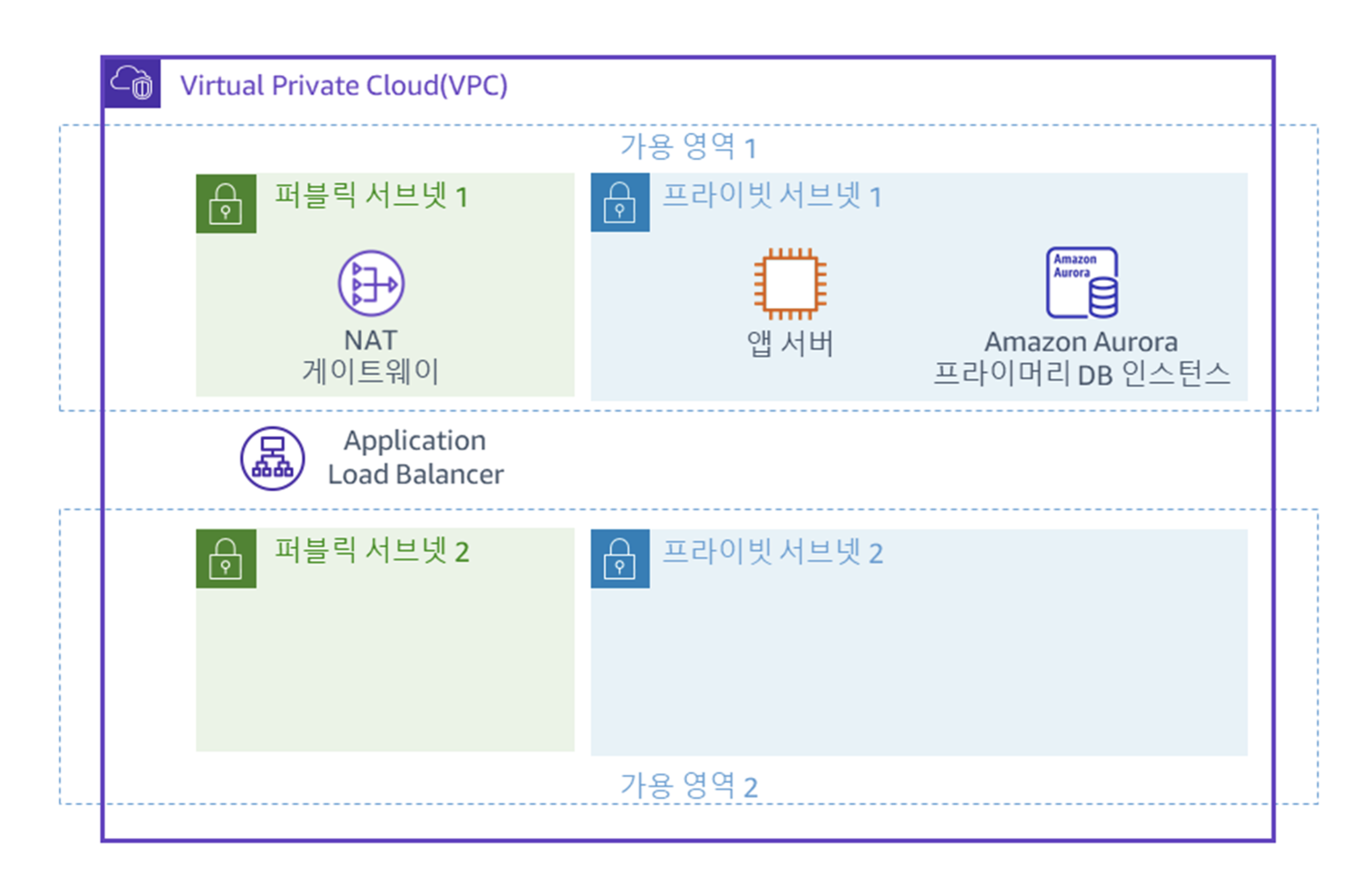
네트워크 인프라 검사
위의 아키텍쳐가 잘 구성되어 있는지 하나씩 확인해보자. 우선 VPC를 확인해보자.
서브넷 확인
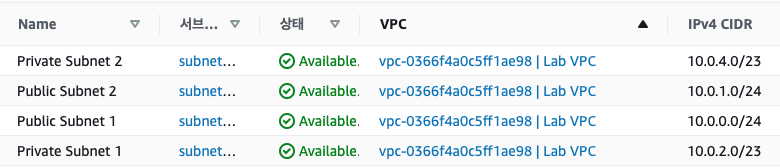
서브넷으로 바로 이동하면 위와 같다. Lab VPC에 Private, Public Subnet이 각각 연동되어 있는 것을 확인할 수 있다. CIDR 열에서 10.0.0.0/24 값은 이 서브넷이 10.0.0.0 과 10.0.0.255 사이의 IP 256개를 포함한다는 뜻이다.
라우팅 테이블 확인
먼저 Public Subnet의 라우팅 테이블 먼저 확인해보자.
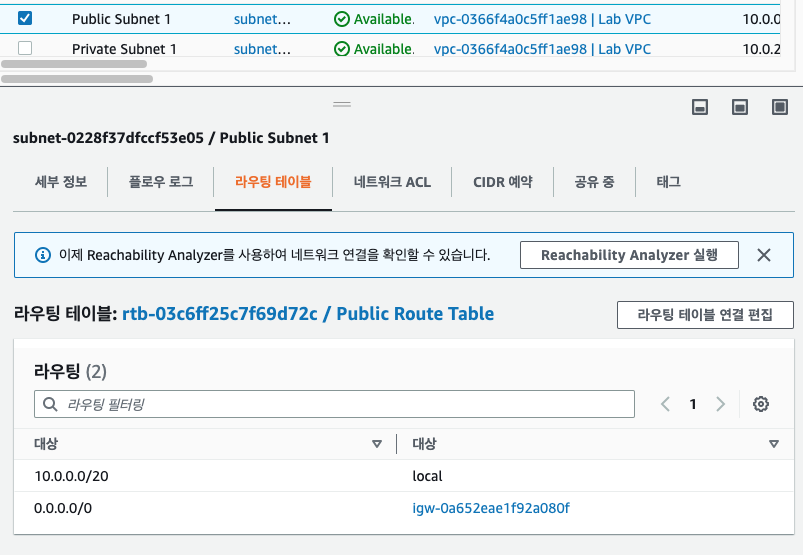
0.0.0.0/0 이 igw로 연결되어 있는 것을 확인할 수 있다.
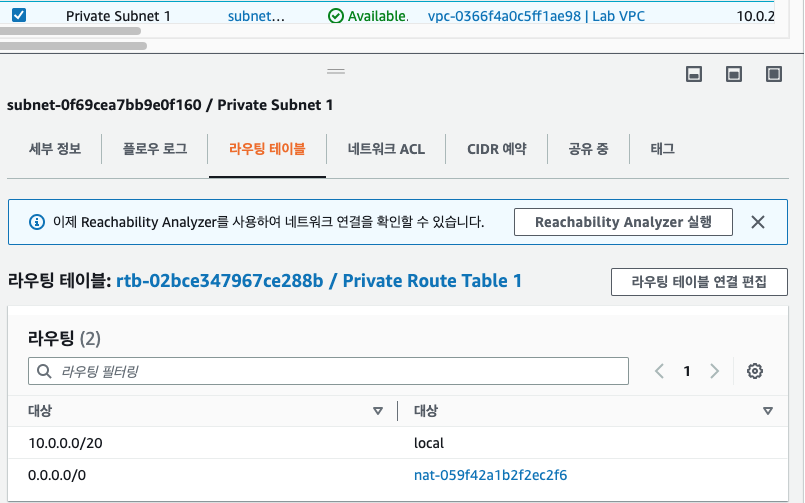
반면에 Private Subnet은 0.0.0.0/0이 Nat로 연결되어 있는 것을 확인할 수 있다.
나머지 IGW와 보안 그룹도 설정이 잘 되었는지 확인을 하면 된다.
시작 템플릿 생성
Auto Scaling 그룹을 생성하려면 AMI의 ID 및 인스턴스 유형 등 EC2 인스턴스를 시작하는 데 필요한 파라미터가 포함된 시작 템플릿을 생성해야 한다. Ec2의 시작 템플릿 생성에서 만들 수 있으며 실습 환경에 따라 만들어준다.
여기서 Ec2를 생성할 때 어떤 명령들을 넣어서 생성할지를 User data 섹션에 담아 생성해주면 된다.
Auto Scaling 그룹 생성
이번 실습에서는 Private Subnet에 EC2 인스턴스를 배포하는 Auto Scaling 그룹을 생성한다. Private Subnet의 인스턴스는 인터넷에서 액세스할 수 없기 때문에 애플리케이션을 배포할 때는 이것이 보안 모범 사례이다. 대신 사용자가 ALB에 요청을 보내면 아래 그림과 같이 해당 요청이 Private Subnet에 있는 EC2 인스턴스에 전달된다.
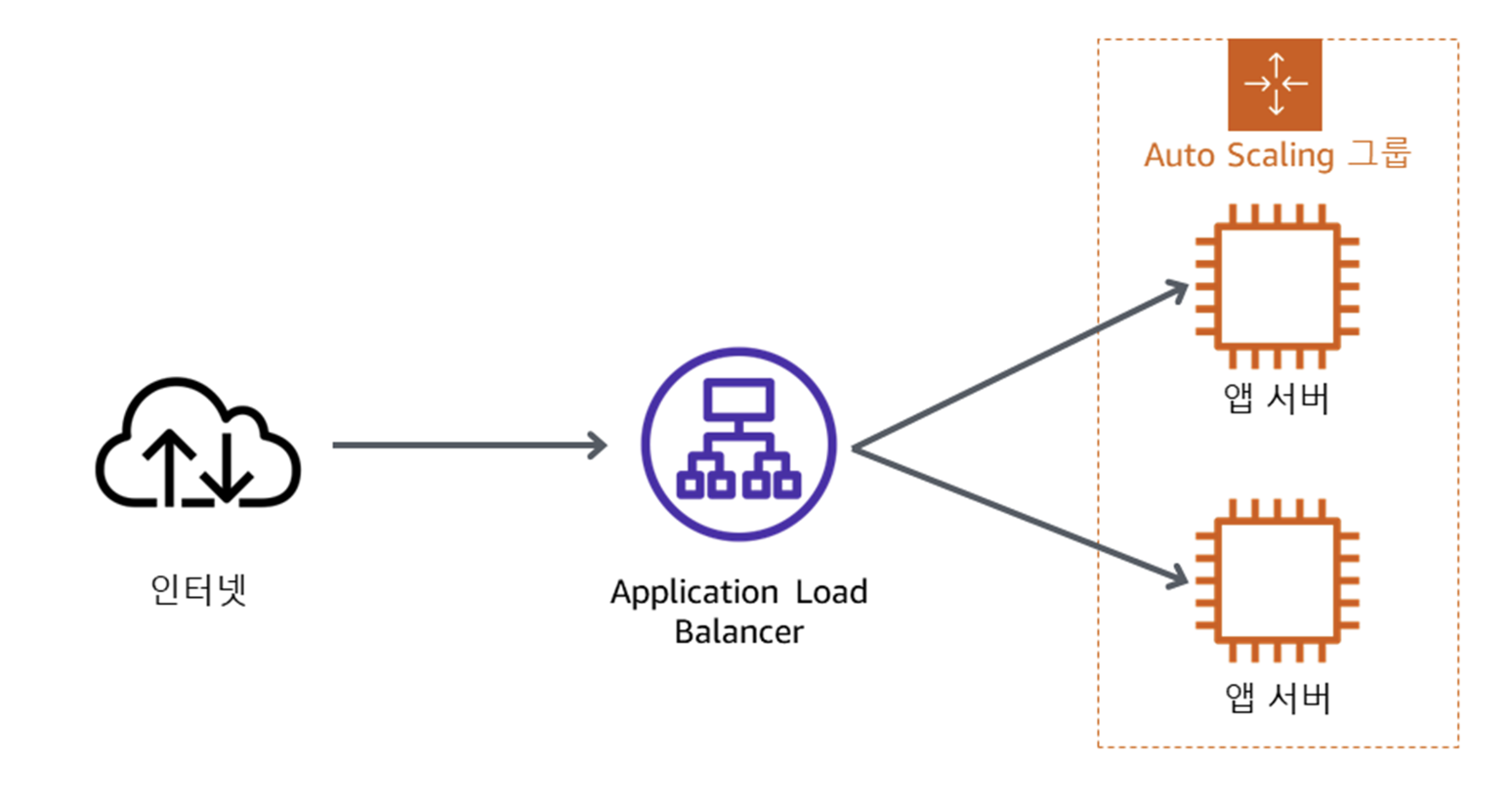
Auto Scaling 그룹 생성은 EC2의 메뉴바에 존재한다. 찾아서 생성해주면 된다.
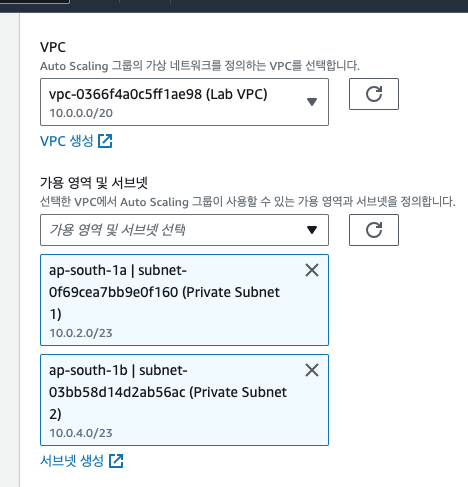
생성 옵션 중에 VPC와 Subnet은 설정해주어야 할 것들을 옵션으로 지정해준다.
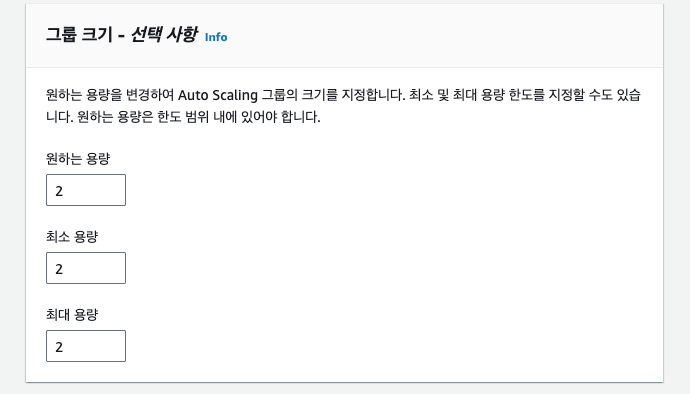
위 옵션은 Auto Scaling을 어느정도로 해줄지 세팅하는 것이다. 처음 desired는 2, max와 min 모두 2로 설정해주어 고가용성을 보장한다.
애플리케이션 테스트
이렇게 생성한 웹 애플리케이션이 실행 중이고 가용성이 높은지 확인해보자. Target Group으로 가면 3개의 인스턴스가 있는데, 2개는 Auto Scaling된 인스턴스이고 하나는 실습 1에서 진행한 인스턴스이다. 여기서 인스턴스 하나를 제거해보자.

제거 했다고 인스턴스가 제거 되는 것이 아니라, Load Balance에서 하나가 빠지는 것이다. 그런 다음 재고 웹 애플리케이션에 다시 들어가보자.
정상 동작 한다.
인터넷이 퍼블릭 서브넷에 있는 ALB를 통해 요청을 전송하면 ALB는 프라이빗 서브넷에 있는 EC2 인스턴스 중 하나를 선택해 요청을 전달한다. 그 다음 EC2 인스턴스가 ALB에 웹 페이지를 반환하고, ALB가 웹 페이지를 웹 브라우저에 반환하는 흐름으로 진행된다
애플리케이션 티어의 고가용성 테스트
Auto Scaling에 2개의 instance를 띄우라고 설정을 해놓았기 때문에 하나가 지워진다면 다른 하나가 대신해서 생성이 되어야 할 것이다. 이를 테스트 해보자
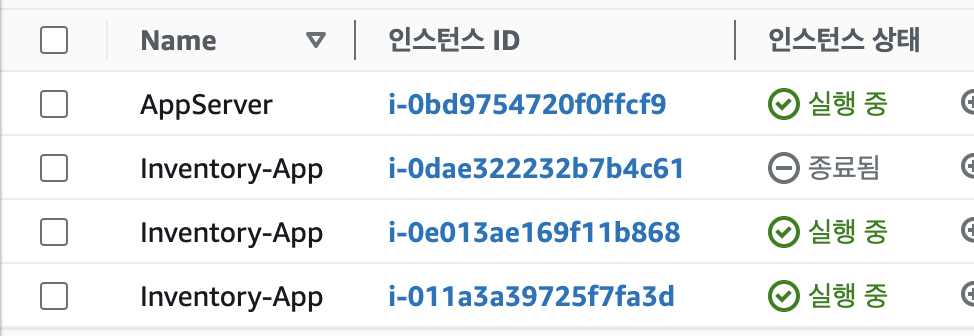
2번째 Inventory-App을 삭제했음에도 하나가 자동으로 더 생겼음을 위에서 확인할 수 있다.
데이터베이스 티어의 고가용성 테스트
EC2 instance는 Auto Scaling으로 고가용성을 테스트 해보았고, 데이터베이스의 고가용성을 구성해보자. 단순하다. AZ 한 개가 다운될 때를 대비하여 하나의 DB를 다른 AZ로 생성하면 된다.

이렇게 하면 데이터베이스의 고가용성을 보장해줄 수 있다. 하지만 이는 데이터베이스가 여러 인스턴스에 분산된다는 뜻은 아니다. DB 인스턴스와 Aurora 복제본 모두 동일한 공유 스토리지에 액세스 하지만 프라이머리 DB 인스턴스만 쓰기에 사용할 수 있다.
NAT 게이트웨이가 고가용성을 제공하도록 설정
현재에는 Public Subnet 1에만 NAT 게이트웨이가 세팅이 되어 있어서 해당 게이트웨이가 다운이 되면 고가용성을 보장해주지 못한다. 그렇기 때문에 Public Subnet 2에도 NAT 게이트웨이를 세팅해준다.
NAT 게이트웨이를 만들어주고, 라우팅 테이블을 생성한 뒤 구성해주고, 프라이빗 서브넷 2의 라우팅을 세팅에 맞게 구성해주면 성공적으로 NAT 고가용성을 위한 세팅을 해줄 수 있다.

유익한 글 잘 봤습니다, 감사합니다.