백준 알고리즘을 풀며 알게된 점을 메모한 게시물입니다.
처음 백준을 풀기 시작해보니 코드 처리 속도가 중요하다는 것을 알게 되었다.
오늘은 Scanner와 BufferedReader 차이점과 StringTokenizer와 split의 차이점에 대해 메모한다.
문제는 두 수의 입력을 받고 두 수의 차이값을 출력하는 간단한 문제이다.
문제
백준 문제 1001번
: 두 정수 A와 B를 입력받은 다음, A-B를 출력하는 프로그램을 작성하시오.
입력
: 첫째 줄에 A와 B가 주어진다. (0 < A, B < 10)
출력
: 첫째 줄에 A-B를 출력한다.
Scanner 사용했을 때
import java.util.*;
public class Main{
public static void main(String args[]){
Scanner sc = new Scanner(System.in);
int a,b;
a = sc.nextInt();
b = sc.nextInt();
System.out.println(a-b);
}
}
Scanner 클래스를 이용해서 두 수를 nextInt()로 간단하게 읽어왔고, 속도는 212ms 정도 걸렸다.
BufferedReader 사용했을 때
import java.io.*;
public class Main{
public static void main(String args[]) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String[] s = br.readLine().split(" ");
int a = Integer.parseInt(s[0]);
int b = Integer.parseInt(s[1]);
System.out.println(a-b);
}
}
BufferedReader를 이용해 입력한 값을 읽어왔고, 입력한 값을 분리하는 과정을 거쳤다. 이 경우 처리속도가 120ms 정도이다.
왜 이런 속도차이가 나는 것일까?
Scanner와 BufferedReader의 차이점
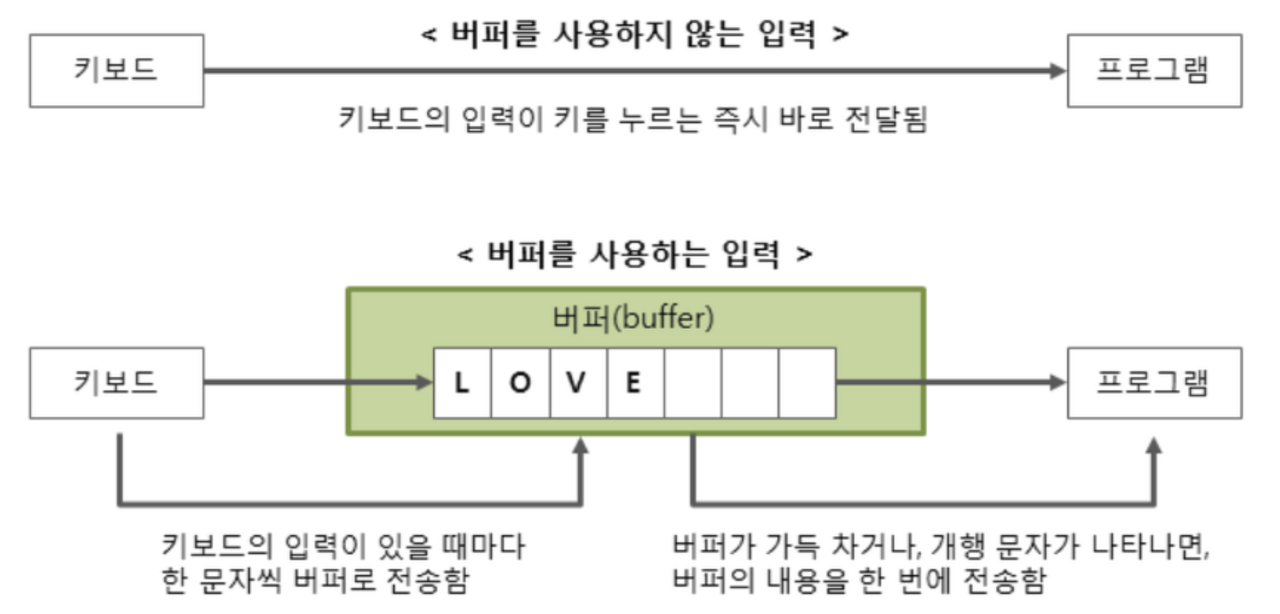
-
데이터 가공
- Scanner는 값을 정수, 문자열, 불리안 등 다양하게 읽어들일 수 있어 간편하다.
- BufferedReader는 입력 받은 데이터가 텍스트이기 때문에 문자나 문자열로 읽어들인 후 값을 변환해야 한다.
-
버퍼 사용
- Scanner는 키보드의 입력이 키를 누르는 즉시 전송한다.
- BufferedReader는 8192 byte 크기의 버퍼에 입력 받은 값을 담아두었다가 한번에 전송한다.
👉 데이터를 하나하나 전달하는 것보다 한번에 모아 데이터를 전송하는 것이 성능적인 측면에서 더 효율적이다. 따라서 버퍼의 사용이 더 빠른 처리 속도를 낼 수 있다.
BufferedReader 사용할 때 주의점
- java.io 패키지를 import 해준다.
throws IOException으로 예외처리를 해준거나try, catch문으로 예외처리를 해줘야한다.- 여러 데이터를 입력 받을 때는
split()함수를 사용해주거나StringTokenizer클래스를 이용한다.
위의 경우는split ()을 이용하여 문자열을 구분해주었다.
StringTokenizer 클래스 사용해서 문자열을 구분할 때
import java.util.*;
import java.io.*;
public class Main{
public static void main(String args[]) throws IOException{
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
StringTokenizer st = new StringTokenizer(br.readLine());
int a = Integer.parseInt(st.nextToken());
int b = Integer.parseInt(st.nextToken());
System.out.println(a-b);
}
}StringTokenizer 클래스는 java.util 패키지에 있고, split () 처럼 문자열을 분리해준다. 분리된 문자열을 nextToken()으로 가져올 수 있다. 분리된 모든 문자열을 확인하기 위해서는 hasMoreTokens() 을 이용하여 반복문을 돌면서 확인하는 방법이 있다.
StringTokenizer를 생성하는 방법 3가지도 알아보자.
-
StringTokenizer st = new StringTokenizer(문자열);
👉 띄어쓰기를 기준으로 문자열을 분리해준다. -
StringTokenizer st = new StringTokenizer(문자열, 구분자);
👉 명시한 구분자로 문자열을 분리해준다. -
StringTokenizer st = new StringTokenizer(문자열, 구분자, true/false);
👉 세번째 매개변수의 true/false는 구분자를 토큰에 포함할지 여부를 결정한다. true면 구분자를 토큰에 포함되고, false면 포함되지 않는다.
Split과 StringTokenizer의 차이점
- StringTokenizer는 빈문자열을 토큰으로 인식하지 않지만, Split은 빈문자열을 토큰으로 인식한다.
- StringTokenizer는 결과값이 문자열이라면 Split은 결과값이 문자열 배열이다.
- StringTokenizer는 문자 또는 문자열로 입력값을 구분하고, split은 정규 표현식으로 구분한다.
참고 게시물
