
🍈소개
코틀린에서 사용하는 숫자에 대한 내용 정리
🍈정수형
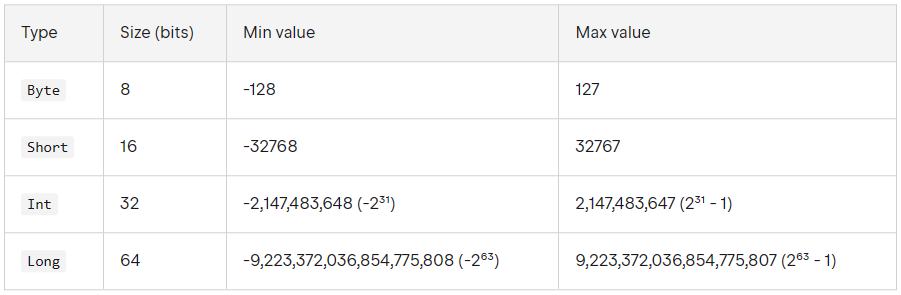
코틀린은 자바와 달리 타입을 명시적으로 선언하지 않으면 자동으로 정해준다.
val num1 = 1 // Int
val num2 = 3000000000 // Long
println(num1::class.simpleName)
println(num2::class.simpleName)Long 타입은 뒤에 L을 추가하면 Long 타입이 된다.
val num1 = 1L // Long참고로 선언한 타입의 범위를 벗어나는 수를 선언하면 에러가 발생한다.
val num1: Int = 3000000000 // error!🍈실수형

코틀린에서는 실수형은 Double이 기본이고 Float는 뒤에 f, F를 붙여야 한다.
val num1 = 1.0 // Double
val num2 = 1.0f // Float코틀린은 Double와 Float이 서로 변환이 되지 않는다. 이유는 아래에 설명이 나온다.
val num1 = 1.0 // Double
val num2:Float = num1 // error!🍈표현
코틀린에서는 0x와 0b를 사용해 16진법과 2진법을 표현할 수 있다.
이때 타입을 따로 정하지 않으면 Int와 Long 중 숫자 크기에 맞는 타입이 선언된다.
8진법은 지원되지 않는다.
val num2 = 0xFF
val num3 = 0b11숫자가 너무 긴 경우에는 _을 사용해 가독성을 높일 수 있다.
val num1 = 3_000_000_000
val num2 = 0xFF_EC_DE_5E
val num3 = 0b11010010_01101001_10010100_10010010🍈원시 타입 & 래퍼 타입
코틀린에서는 === 연산자를 선언해 같은 주소를 검사할 수 있는데 숫자를 비교하면 재밌는 결과가 나온다.
val num1: Int = 100
val num2: Int = 10000
val numA1: Int = num1
val numA2: Int = num1
val numB1: Int = num2
val numB2: Int = num2
println(numA1 === numA2) // true
println(numB1 === numB2) // true여기서 Int를 Int? 타입으로 바꾸면 이상한 결과가 나온다.
val num1: Int = 100
val num2: Int = 10000
val numA1: Int? = num1
val numA2: Int? = num1
val numB1: Int? = num2
val numB2: Int? = num2
println(numA1 === numA2) // true
println(numB1 === numB2) // false코틀린은 JVM에 의해 컴파일되는데, JVM이 -128~127인 숫자를 참조하는 Int? 객체는 같은 객체로 처리하지만, 범위를 벗어나는 숫자를 참조하는 Int?는 다른 객체로 처리하지 때문이다.

보통 숫자는 원시 타입이라 객체가 없다고 생각할 수 있다.
코틀린에서는 원시 타입과 래퍼 타입을 따로 구분하고 있지 않다.
대신 JVM이 자바 코드로 변환할 때 숫자의 사용 방법에 따라 구분하고 있다.
다음 예시 코드를 보면 코틀린으로 작성하면 타입에 큰 신경을 안써도 된다.
val num1:Int = 10
val num2: List<Int> = listOf(10)
val numA = num1
val numB = num2.first()
val numC: Int? = num2.firstOrNull()이걸 Androdi Studio의 Kotlin Bytecode 기능을 사용해 자바 코드로 변환하면 다음 코드가 나온다.
int num1 = true;
List num2 = CollectionsKt.listOf(10);
int numB = ((Number)CollectionsKt.first(num2)).intValue();
Integer numC = (Integer)CollectionsKt.firstOrNull(num2);하나씩 보면 숫자를 선언만 하면 int로 처리된다.
int num1 = true;
int numB = ((Number)CollectionsKt.first(num2)).intValue();반면 제네릭이나 nullable로 사용하면 래퍼 타입으로 변환된다.
// Number는 래터 타입으로 Integer의 추상 클래스
int numB = ((Number)CollectionsKt.first(num2)).intValue();
// Int?는 Integer로 선언된다.
Integer numC = (Integer)CollectionsKt.firstOrNull(num2);JVM이 이런 동작을 하는 이유는 메모리 최적화 때문이라고 한다.
코틀린에서 사용하는 Int나 Double 같은 숫자 타입은 코드를 보면 클래스로 되어 있다.
숫자는 Number 추상 클래스를 상속하는데 정작 Int나 Long은 같은 정수형이여도 서로 호환되지 않는다.
다른 타입에 저장하려면 toLong() 같은 메소드를 사용해야 한다.
var num1: Int = 100
var num2: Long = 100
num2 = num1 // error
num2 = num1.toLong()🍈실수형 비교
실수형은 부동소수점을 사용하기 때문에 컴퓨터에서 정확한 값을 알 수 없다.
그래서 IEEE754를 기준으로 표현하는데, 이래도 오차가 발생한다.
저 오차 때문에 재밌는 결과가 나온다.
숫자로 연산할 때 불가능한 연산이면 NaN이 출력된다.
이 NaN은 Double 클래스에 전역 변수로 선언되어 있고 -(0.0 / 0.0 )인 Double 타입이다.
결국 부동소수점을 가진 실수형이기 때문에 같은 NaN의 값을 비교하면 false가 나온다.
println(Double.NaN == Double.NaN) // false0.0에도 재밌는 현상이 있는데 -0.0과 0.0을 비교하면 다음 결과가 나온다.
// 동일한 값
println(0.0 == -0.0) // true
// 동일한 값이지만, list에 넣으면 다르게 인식
println(listOf(0.0) == listOf(-0.0)) // false
println(listOf(1.0) == listOf(1.0)) // true마지막으로 정렬을 하면 다음 결과가 나온다.
NaN은 -(0.0 / 0.0 )이고 POSITIVE_INFINITY는 1.0/0.0으로 선언되어 있다.
// [-0.0, 0.0, Infinity, NaN]
println(listOf(Double.NaN, Double.POSITIVE_INFINITY, 0.0, -0.0).sorted())