
RDS (Relation Database Service)
RDS는 AWS에서 제공하는 완전 관리형 관계형 데이터베이스 서비스로, MySQL, PostgreSQL, Oracle 등 다양한 데이터베이스 엔진을 지원한다.
Amazon Aurora
AWS 자체에서 제공하는 RDS로, MySQL 및 PostgreSQL 호환의 클라우드 네이티브 관계형 데이터베이스이다.
고가용성 및 재해 복구(HA & DR)
1. RDS Multi-AZ 배포
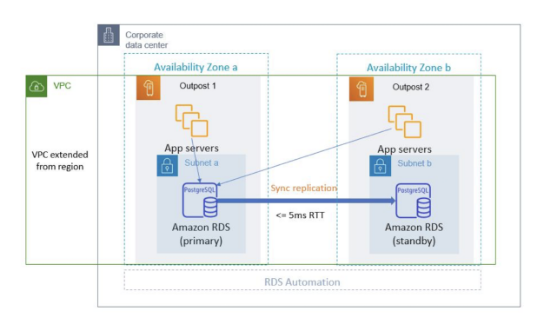
동일 리전 내 여러 가용 영역(AZ)에 걸쳐 데이터베이스를 운영하여 고가용성을 확보한다. DB 장애 발생 시 다른 AZ로 자동 장애 조치를 수행해 다운타임을 최소화한다.
동기 복제 방식을 사용하여 데이터를 동시에 두 노드에 저장하므로 데이터 유실이 거의 없다.
- Multi AZ Instance (전통적인 방식)
- Primary DB Instance 1대 + Standby Instance 1대
- 동일 리전 내 다른 AZ에 스탠바이 배치
- Standby 인스턴스는 읽기 불가능하며 Failover 시에만 활성화되어 Primary로 승격
- 읽기 부하 분산 불가
- Multi AZ Cluster
- 하나의 Writer(Primary) + 여러 Reader(Standby) 구조
- Standby 인스턴스가 읽기 가능
- 동일 리전 내 여러 AZ 배치
- Reader 인스턴스를 Read Replica로 활용 가능
- 기존 단일 AZ DB도 다중 AZ로 전환해 SPOF(단일 실패 지점) 제거 가능
2. Aurora Global DB를 활용한 크로스 리전 DR
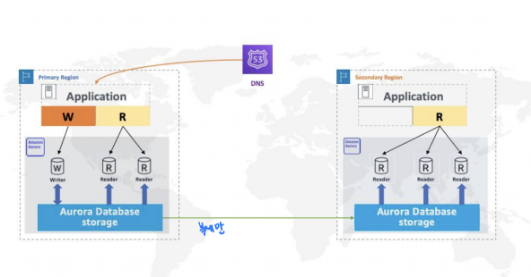
AWS의 Aurora DB를 여러 리전으로 실시간 복제하여 글로벌 재해를 대비한다.
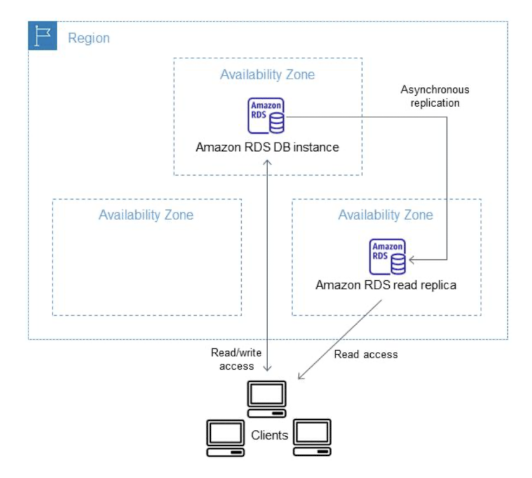
3. Cross-Region Read Replica
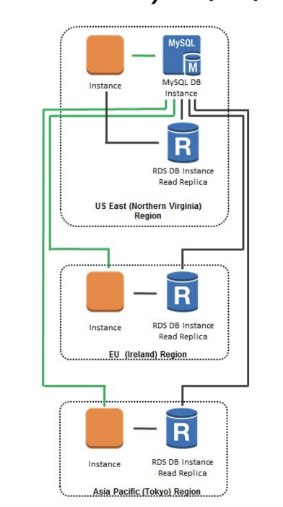
사진과 같이 다른 리전에 읽기 전용 복제본을 만들어 운영한다. 장애에 대비하고 다른 리전 사용자도 빠르게 읽을 수 있다.
읽기 전용 데이터베이스를 전세계에 만들기에 사용자들은 자신과 가장 가까운 복제본에서 데이터를 읽기에 앱의 로딩 속도가 빠르다.
4. 스냅샷 기반 DR
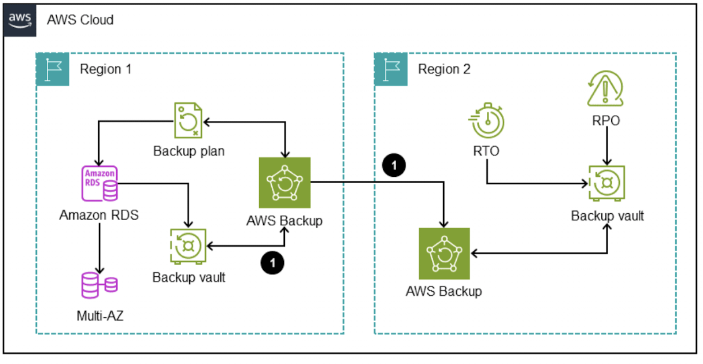
DB를 주기적으로 스냅샷을 찍어 다른 리전에 복사한다. RPO, RTO가 있을 때 스냅샷을 이용해 인스턴스를 새롭게 생성한다. 리전에 장애가 발생하면 다른 리전에 장애 발생 전 스냅샷을 사용해 복원하여 운영한다.
RDS 성능 최적화
1. 읽기 트래픽 분산
| 종류 | 설명 |
|---|---|
| RDS 읽기 전용 복제본 (Read Replica) | 읽기 쿼리를 주 DB에서 분리하여 부하를 줄이고 성능 저하 방지 |
| Aurora Reader Endpoint | 예측 불가능한 읽기 워크로드에 따라 자동으로 스케일 |
| Custom Endpoint | 특정 사양을 가진 Aurora Replica 그룹에만 읽기 쿼리를 분산해 효율적인 리소스 관리 가능 |
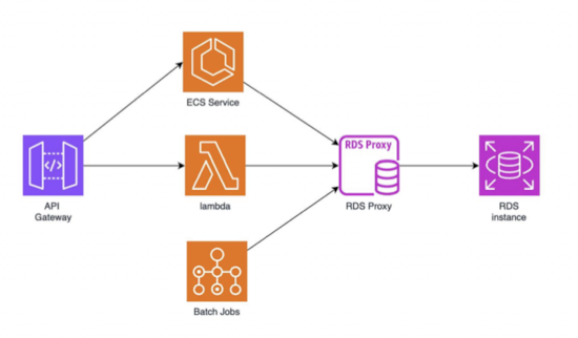
2. 데이터베이스 연결 관리
| 종류 | 설명 |
|---|---|
| RDS Proxy | - 서버리스 애플리케이션 등에서 빈번하게 발생하는 DB 연결 생성 및 종료를 효율적으로 관리 - 연결 풀링을 통해 연결 시간을 단축하고, 장애 조치 시에도 연결을 유지하여 중단 시간을 최소화. |
| connection pooling | 애플리케이션에 새로 DB 연결을 만들지 않도록 이미 만들어놓은 연결을 재활용 |
3. 스토리지 성능 최적화
RDS 스토리지 Auto Scaling을 이용해 디스크 공간이 부족할 때 다운타임 없이 자동으로 스토리지를 확장한다.
Dynamo DB
DynamoDB는 AWS의 완전관리형 NoSQL 데이터베이스 서비스로, 유연한 스키마를 제공하여 데이터 구조 변경에 빠르게 대응할 수 있다.
- 다양한 비관계형 데이터 저장 가능
- 데이터 스키마를 빠르게 변경할 수 있는 유연성 제공
비관계형 데이터?
고정된 스키마없이 JSON, Key-Value 등으로 저장{ "id": 1, "name": "철수", "hobbies": ["축구", "독서"], "address": { "city": "서울", "zip": "12345" } }
성능 최적화
1. DynamoDB Accelerator (DAX)
인메모리 캐싱 서비스로, 읽기 집약적인 워크로드의 지연 시간을 마이크로초 수준으로 단축시킨다. 애플리케이션 코드 변경 없이 성능 향상이 가능하다.
2. 읽기 일관성
최신 데이터를 반환하지 않는 문제 발생 시 읽기 일관성을 요청해 해결할 수 있다.
비용 최적화
1. 온디맨드 모드
예측 불가능한 트래픽에 적합하며, 사용량에 따라 용량이 자동으로 조절된다.
2. 프로비저닝 모드
워크로드가 예측 가능할 때, 필요한 읽기/쓰기 용량(RCU/WCU)을 미리 할당하여 비용을 절감한다. 프로비저닝한 시간당 읽기 및 쓰기 용량을 기준으로 요금이 청구된다. Auto Scaling을 사용해 트래픽 변경에 따라 테이블의 프로비저닝된 용량을 자동으로 조정할 수 있다.
3. DynamoDB 테이블 클래스
데이터 접근 패턴에 따라 테이블 클래스를 선택하여 비용을 최적화할 수 있다.
- Standard: 자주 접근하는 데이터에 적합
- Standard-IA (Infrequent Access): 자주 접근하지 않는 데이터를 저장하는 데 최적화되어 있으며, 읽기 비용이 상대적으로 비쌈
데이터 관리, 백업 및 복구
1. TTL (Time To Live)
데이터에 만료 시간을 지정하여 자동으로 삭제되도록 설정할 수 있어 용량 관리가 용이하다.
2. PITR (Point-In-Time Recovery)
활성화 시, 최대 35일 이내의 특정 시점으로 데이터를 복구할 수 있는 지속적인 백업을 제공한다.
3. DynamoDB Streams
테이블의 변경 사항을 실시간으로 캡처하여 AWS Lambda 함수를 호출하는 등 자동화된 작업을 구현할 수 있다.
4. 글로벌 테이블 사용
여러 리전에 데이터를 자동복제하여 복원력있는 아키텍처를 구축한다.
재해 복구시, DR 리전에 Auto Scaling 그룹과 ELB를 구성하고 DynamoDB를 글로벌 테이블로 구성해 데이터를 복제하며 트래픽을 DR 리전으로 전환해 최소한의 다운타임으로 가용성을 확보한다.
Elastic Cache
ElastiCache는 인메모리 캐싱 서비스로, 데이터베이스의 읽기 부하를 줄이고 애플리케이션 성능을 향상시키는 데 사용된다.
- EC2 인스턴스에서 실행되는 배치 애플리케이션의 RDS 읽기 횟수 줄이는데 사용
- 자주 호출되는 동안 동일 쿼리 결과를 캐싱해 데이터베이스 부하를 줄이고 애플리케이션 성능 증가
- 반복적인 읽기 작업으로 인한 DB 클러스터 부하 캐싱해 비용 효율성 증가
고려사항
1. Redis vs. Memcached
- Redis: 다양한 데이터 구조를 지원하여 세션 관리, 순위표 등 복잡한 기능 구현에 적합
- Memcached: 단순한 키-값 저장소로, 가볍고 간단한 캐싱 목적에 주로 사용
2. 캐싱 전략
- Write-Through: 데이터를 DB에 쓸 때 캐시에도 동시에 반영하여 데이터 일관성을 높임. 일기/쓰기 부하가 많이 발생
- Lazy Loading: 캐시에 데이터가 없을 때(캐시 미스)만 DB에서 읽어와 캐시를 채우는 방식
3. 고가용성 및 데이터 지속성
- Multi-AZ: 여러 가용 영역에 복제 그룹을 구성하여 고가용성을 확보 가능
- Redis AOF (Append Only File): 모든 쓰기 명령을 로그 파일에 기록하여 재시작 시 데이터를 완전하게 복원할 수 있음
