
정규화
정규화는 논리적 모델을 대상으로 데이터를 분해하는 과정이며 이상현상을 제거해 데이터가 더욱 정규화되고 유지보수가 쉬워진다.
- 정규화를 통해 입력/수정/삭제 시 성능이 향상되며 재활용 가능성이 증가된다.
- 일반적으로 정규화 시 검색 기능이 저하될 수 밖에 없다.
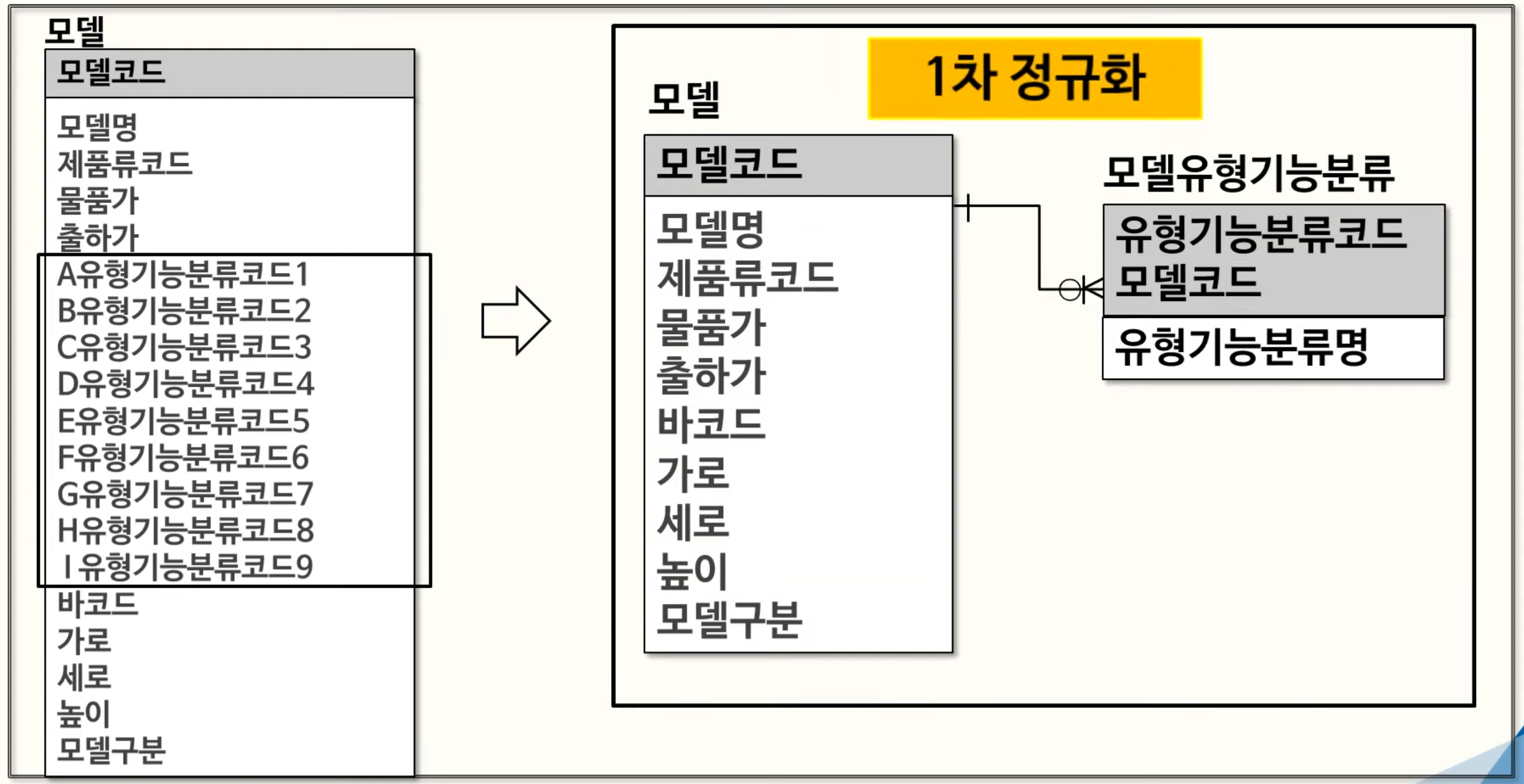
1차 정규화
데이터를 중복없이 효율적으로 저장하고 관리하기 위해 진행된다.
- 중복제거 : 중복된 데이터를 제거해 데이터베이스의 용량을 줄이고 데이터의 일관성을 유지한다.
- 하나의 원자값만 포함 : 각 열은 하나의 원자 값만 포함해야한다. 다중 값 속성을 없앤다.
- 행의 유일성 : 각 행은 고유한 식별자(PK)를 가져야 한다. 이는 각 행이 서로 다른 데이터를 나타내며 데이터의 정확성과 일관성을 보장한다.
- 구조화된 데이터 : 데이터는 테이블에 구조적으로 저장되어야 한다. 각 열은 고유한 속성을 나타내고 각 행은 서로 다른 레코드를 나타내야 한다.
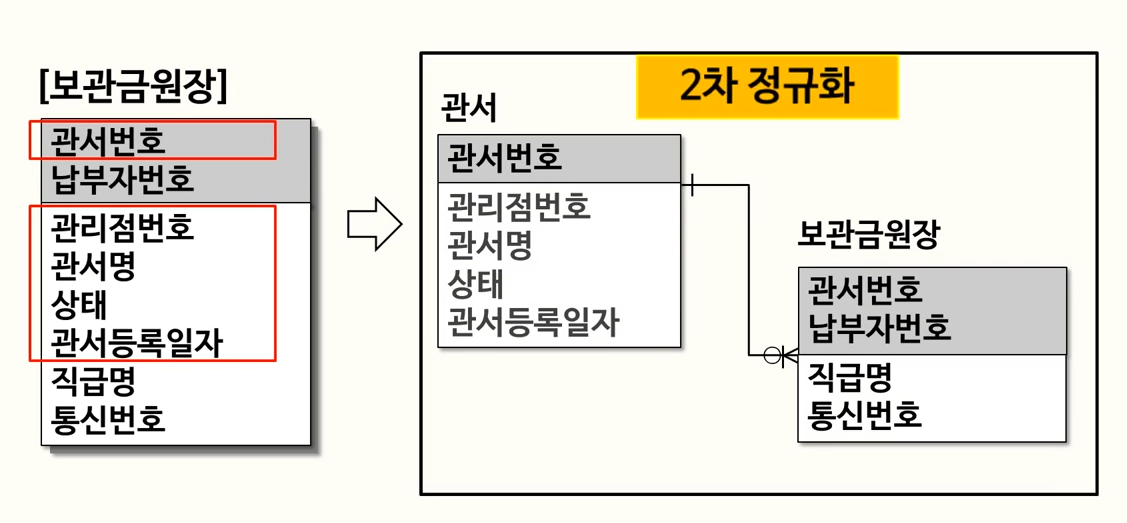
2차 정규화
1차 정규화를 통해 테이블은 각 열이 원자값만을 가지고 각 행이 고유한 식별자를 가지게 되었지만 여전히 부분 함수 종속이 존재할 수 있다.
부분 함수 종속이란 테이블의 일부 속성이 기본 키가 아닌 다른 후보 키에 종속되는 경우를 의미한다. 2차 정규화는 부분 함수 종석을 제거하기 위해 테이블을 분해한다.
- 기본 키가 아닌 모든 속성이 기본 키에 대해 완전 함수 종속 관계를 가져야한다.
- 부분 함수 종속이 발견되면 해당 속성을 별도의 테이블로 이동시키고, 기본 키를 포함해 이런 종속성을 제거한다.
3차 정규화
2차 정규화 이후에도 종속성 문제가 남아있을 수 있다. 이런 경우 3차 정규화를 사용해 해결해야 한다. 3차 정규화는 이행 함수 종속성을 제거한다.
이행 함수 종속성은 한 열이 다른 다른 열을 통해 종속되는 경우를 의미한다.
- 테이블에서 이행 함수 종속성이 있는 속성을 식별한다
- 이행 함수 종속성이 있는 속성을 별도의 테이블로 이동시키고, 이를 기본키로 사용해 원래 테이블과의 관계를 유지한다.
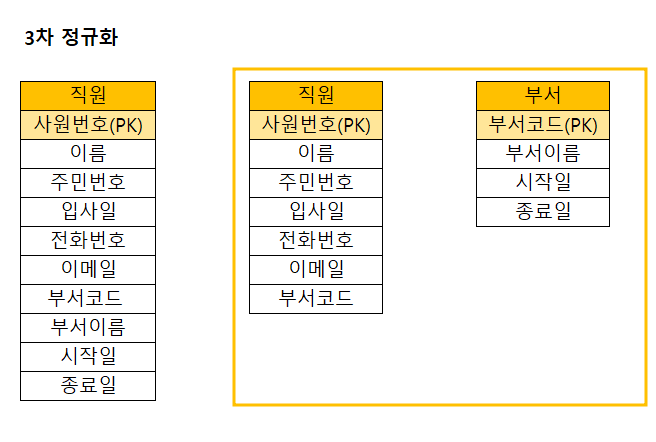
부서 코드를 통해 부서 이름을 알 수 있다. 서로 의존하는 관계이기에 데이터가 중복되어 저장공간이 낭비되고 있기에 3차 정규화를 통해 해결했다.
반정규화
정규화를 반대로 하는 것을 반정규화라고 한다. 정규화는 데이터 중복을 최소화했다면 반정규화는 성능을 위해 데이터 중복을 허용하는 것이다. 반정규화를 통해 조회 성능을 향상시킬 수 있다.
- 자주 사용되는 테이블에 접근하는 프로세스의 수가 많고 항상 일정 범위만 조회할 때
- 통계성 프로세스에 의해 통계 정보 별도로 필요할 때
- 테이블에 지나치게 많은 조인이 걸려 조회가 어려울 때
위와같은 경우에 반정규화가 필요하다.
반정규화 기법
-
중복칼럼 추가
조인 횟수를 감소시키기 위해 다른 테이블의 칼럼을 중복으로 저장한다. -
파생칼럼 추가
값의 계산으로 인한 시간 지연을 줄이기 위해 예상되는 값을 미리 계산하여 중복으로 저장한다. -
이력테이블칼럼 추가
대량 이력 데이터 처리의 성능 향상을 위해 종료 여부, 최근값 여부 등의 칼럼을 추가로 저장한다. -
PK의 의미적 분리를 위한 칼럼 추가
PK가 복합의미를 갖는 경우 구성 요소 값의 조회 성능 향상을 위해 일반 속성을 추가한다.
예를 들어, 차량 번호가지역+일련번호로 구성된 경우지역이라는 일반 속성을 추가한다. -
데이터 복구를 위한 칼럼 추가
사용자의 실수 또는 응용프로그램 오류로 인해 데이터가 잘못 처리된 경우, 원래 값으로의 복구를 위해 이전 데이터를 임시적으로 중복 저장한다.
