들어가며
해당 강의를 보고 정리한 내용입니다.
B-Tree vs self-balancing BST
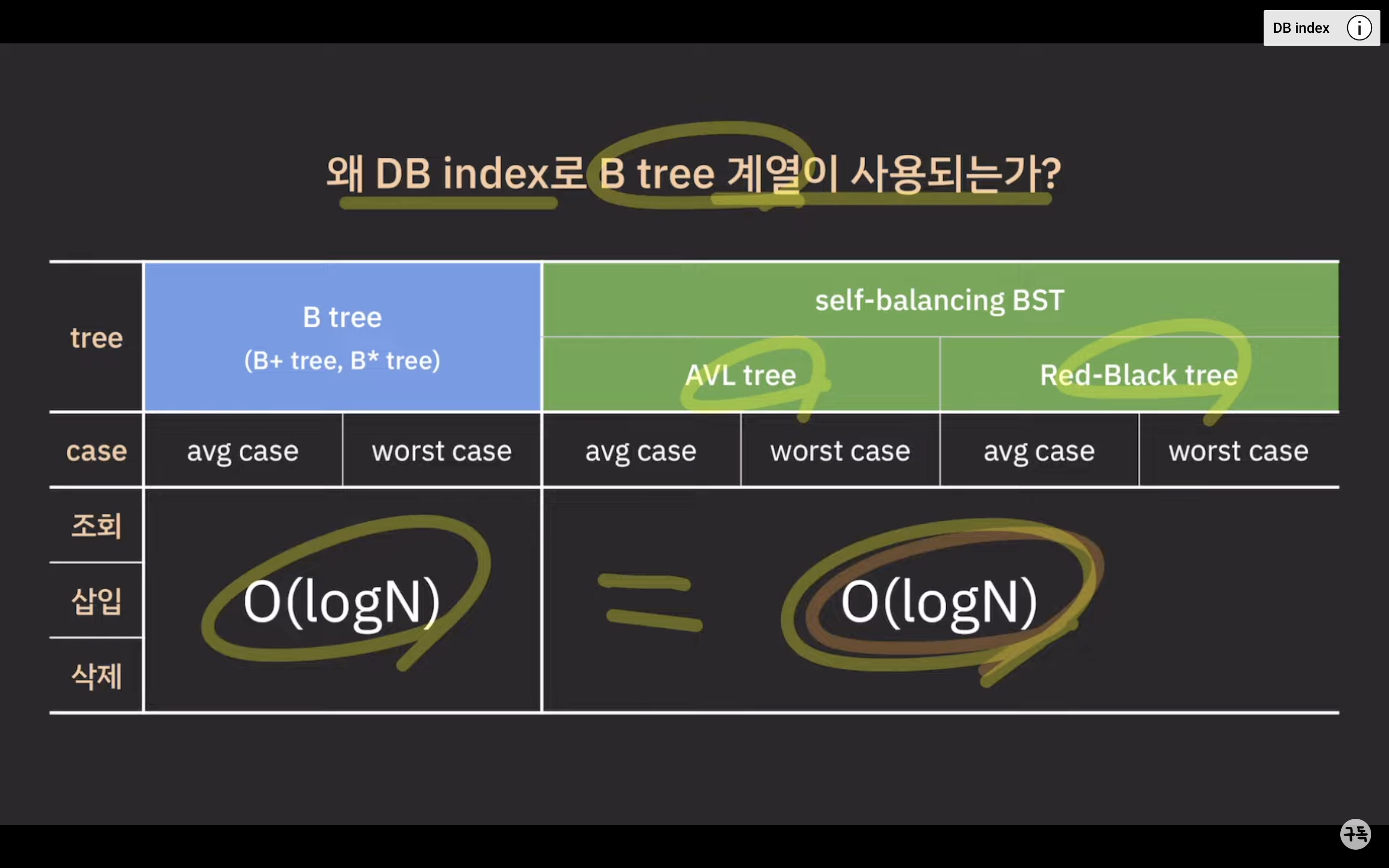
둘다 시간 복잡도가 동일한데 B-Tree가 왜 DB 인덱스(index)로 사용될까?
이유를 살펴보기 위해 일단 컴퓨터 시스템에 대해 간략하게 살펴보자
컴퓨터 시스템
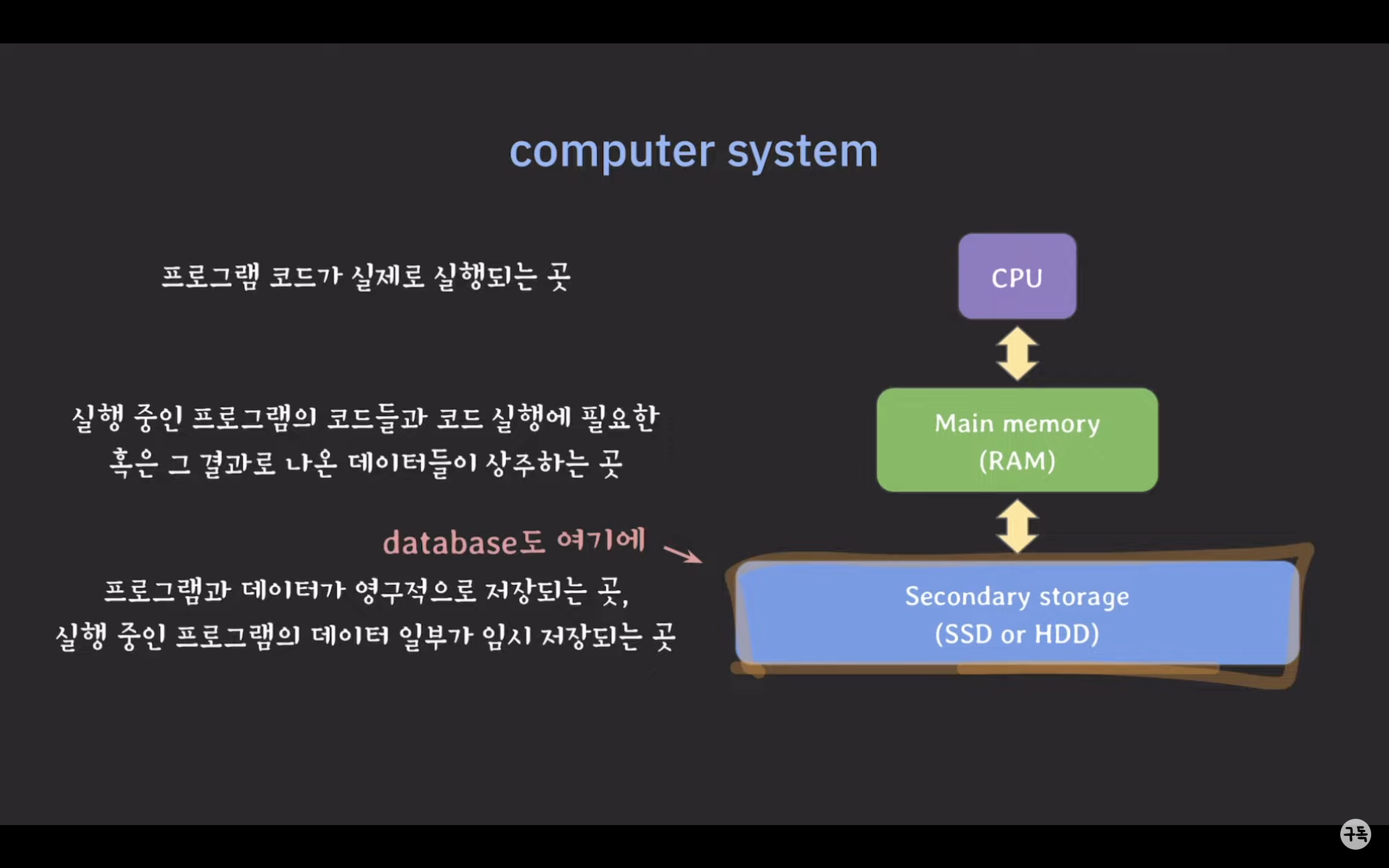
Secondary storage
특징
-
데이터를 처리하는 속도가 가장 느립니다.
-
데이터를 저장하는 용량이 가장 큽니다.
-
데이터를 블록(block) 단위로 읽고 씁니다.
- 블록은 파일 시스템이 데이터를 읽고 쓰는 논리적인 단위로, 주로 2의 승수로 표현됩니다.
- 대표적인 블록 크기에는 4KB, 8KB, 16KB 등이 있습니다.
- 불필요한 데이터까지 읽어올 가능성이 있습니다.
DB관점에서 지금까지 내용 정리
-
DB는 Secondary storage에 저장됩니다.
-
중요한 데이터 몇 개는 메인 메모리(main memory)에 캐싱되고, 나머지 데이터는 Secondary storage에 보관됩니다.
-
외부에서 데이터 조회와 같은 요청이 들어오면, 필요한 데이터가 메인 메모리에 이미 캐싱되어 있다면 메인 메모리에서 처리됩니다. 그러나 Secondary storage에 저장된 데이터가 필요한 경우, 데이터를 블록 단위로 가져와서 메인 메모리에 로드한 다음 데이터를 처리합니다.
DB 시스템이 동작할 때, 데이터를 조회할 때 Secondary storage에 최소한의 접근을 하는 것이 성능 측면에서 중요합니다. 이를 위해 연관된 데이터를 모아서 블록에 저장하고 데이터를 효율적으로 인덱싱하는 등의 기술을 사용하여 데이터베이스 성능을 향상시키는 작업이 필요합니다.
따라서 데이터베이스 설계와 관리는 데이터를 Secondary storage와 메인 메모리 간에 효율적으로 이동시키며, 데이터 액세스 패턴을 최적화하는 데 중요한 역할을 합니다. 데이터베이스 성능 향상을 위해 데이터 관리, 인덱스 구성, 쿼리 최적화 등 다양한 기술과 접근 방법을 고려해야 합니다. 이를 통해 데이터베이스 시스템의 성능을 최적화하고 사용자 및 애플리케이션의 경험을 향상시킬 수 있습니다.
인덱스로 성능 비교 전 몇 가지 가정

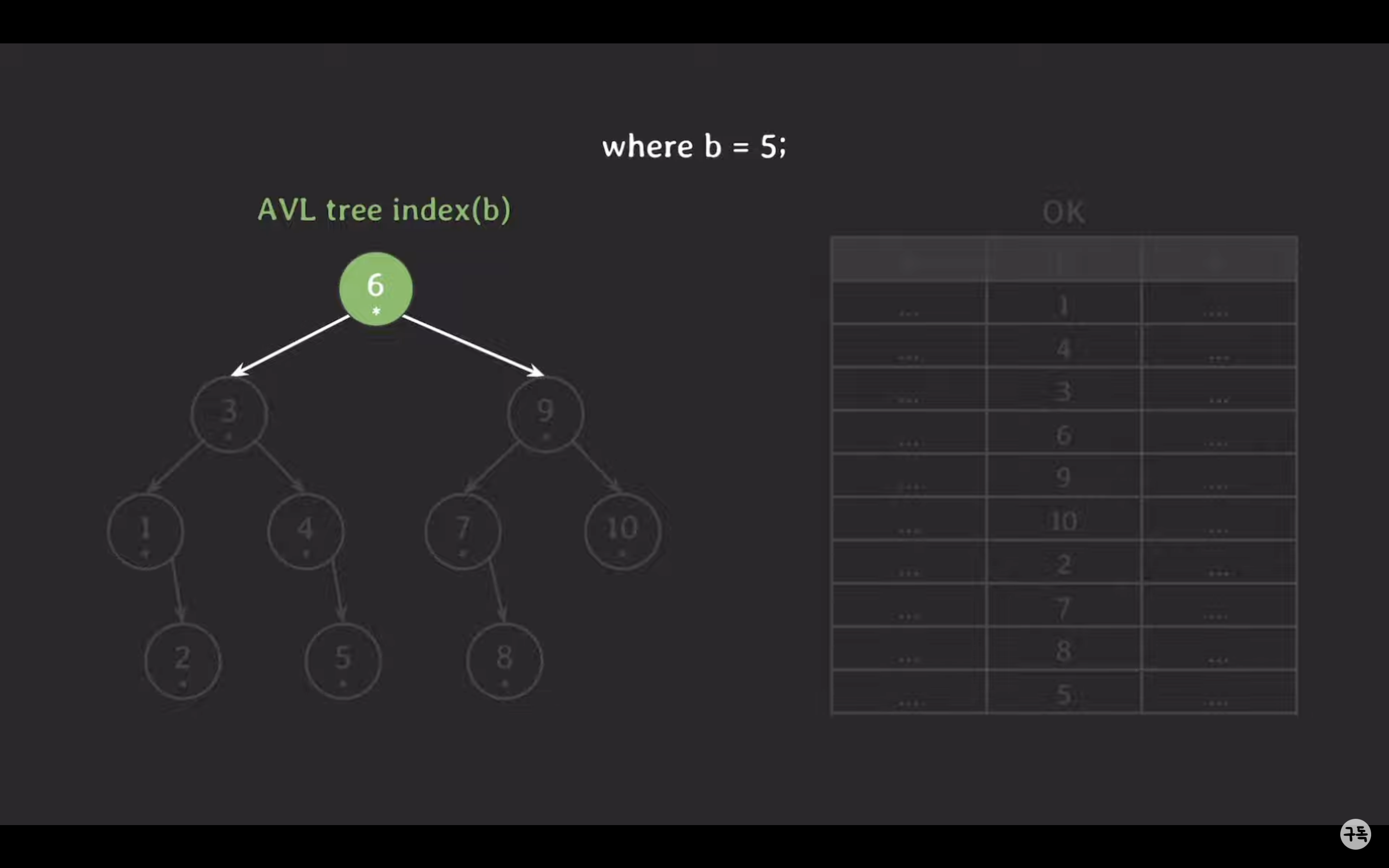
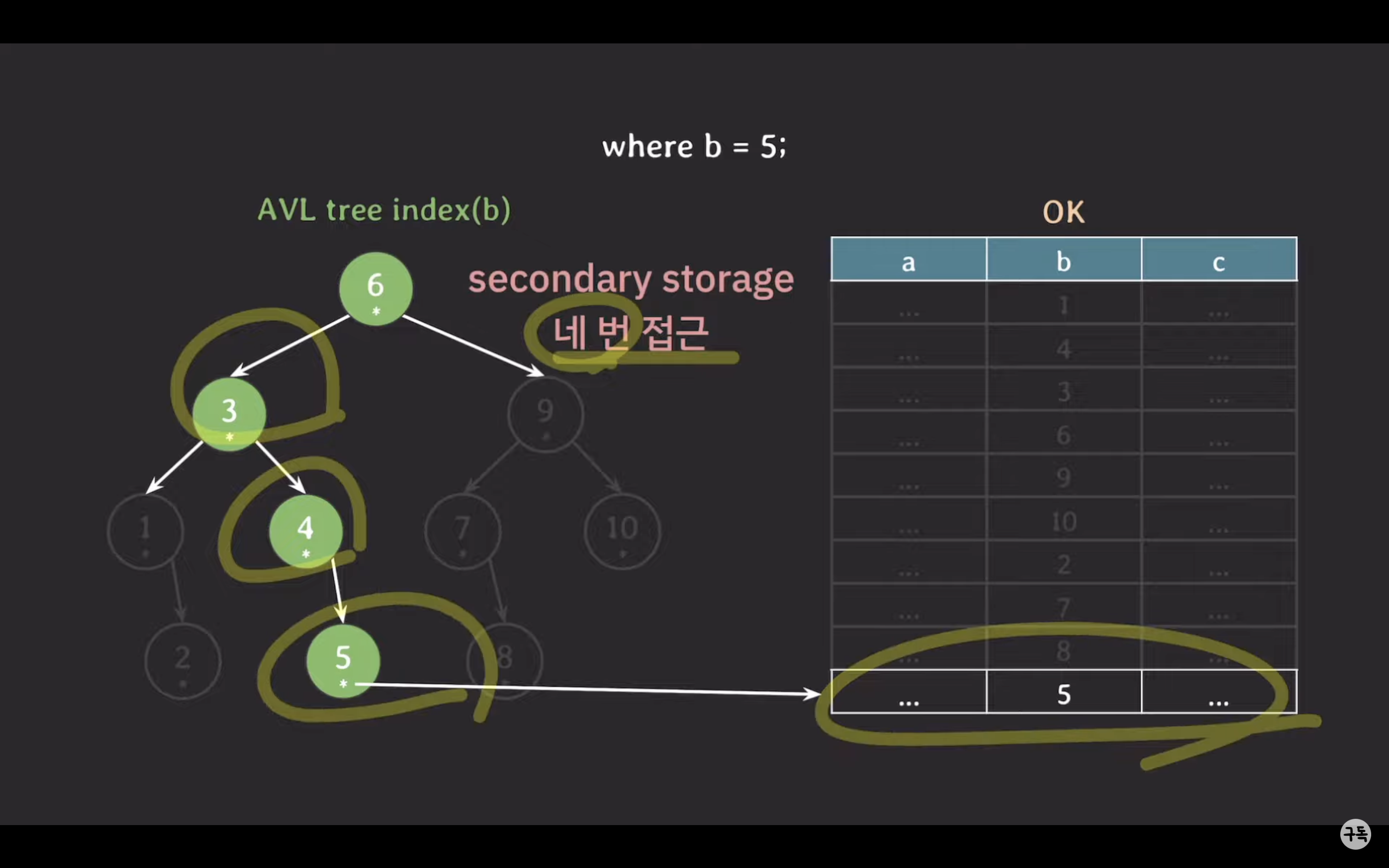
AVL tree 인덱스로 조회 시
5차 B-Tree 인덱스로 조회 시
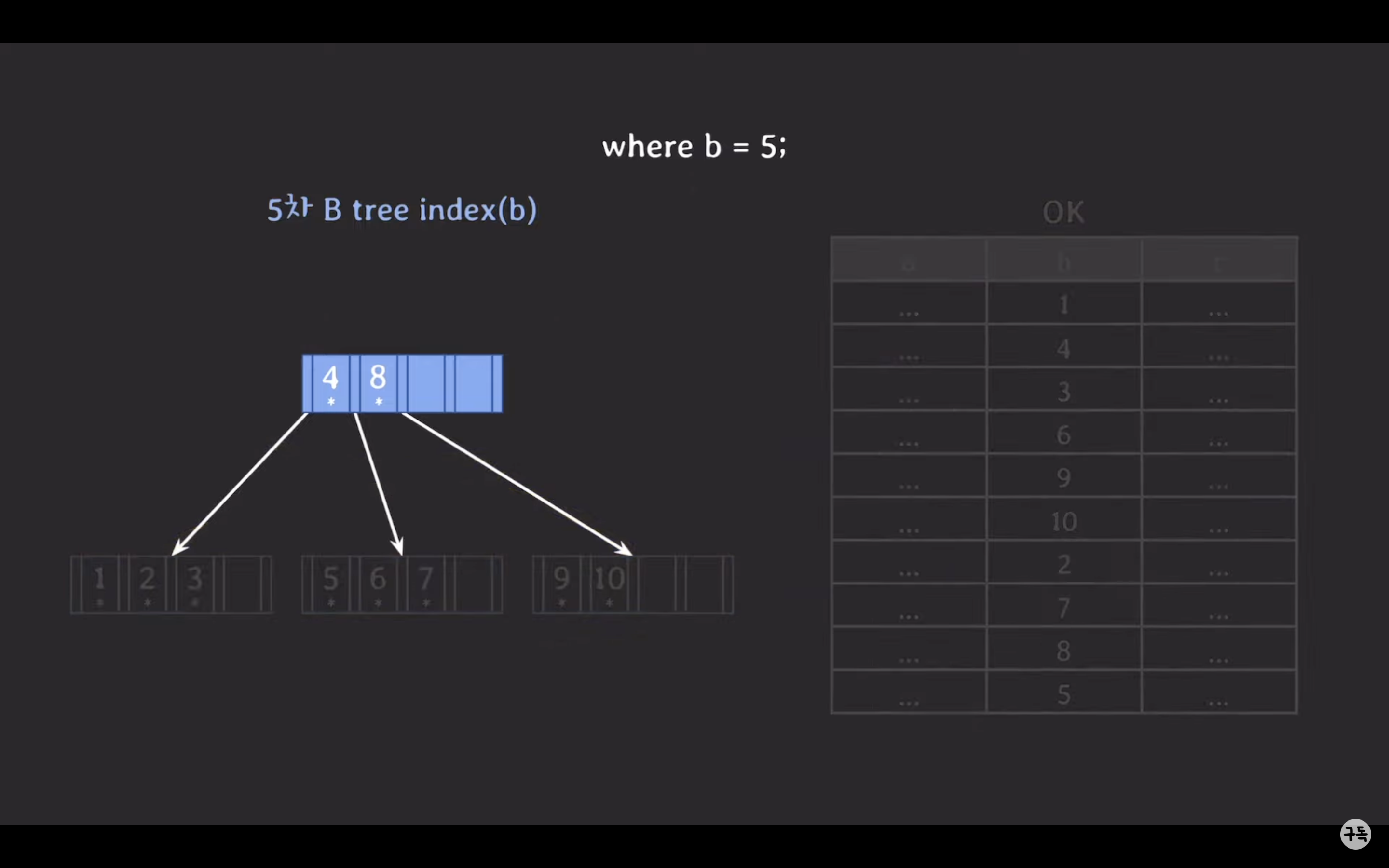
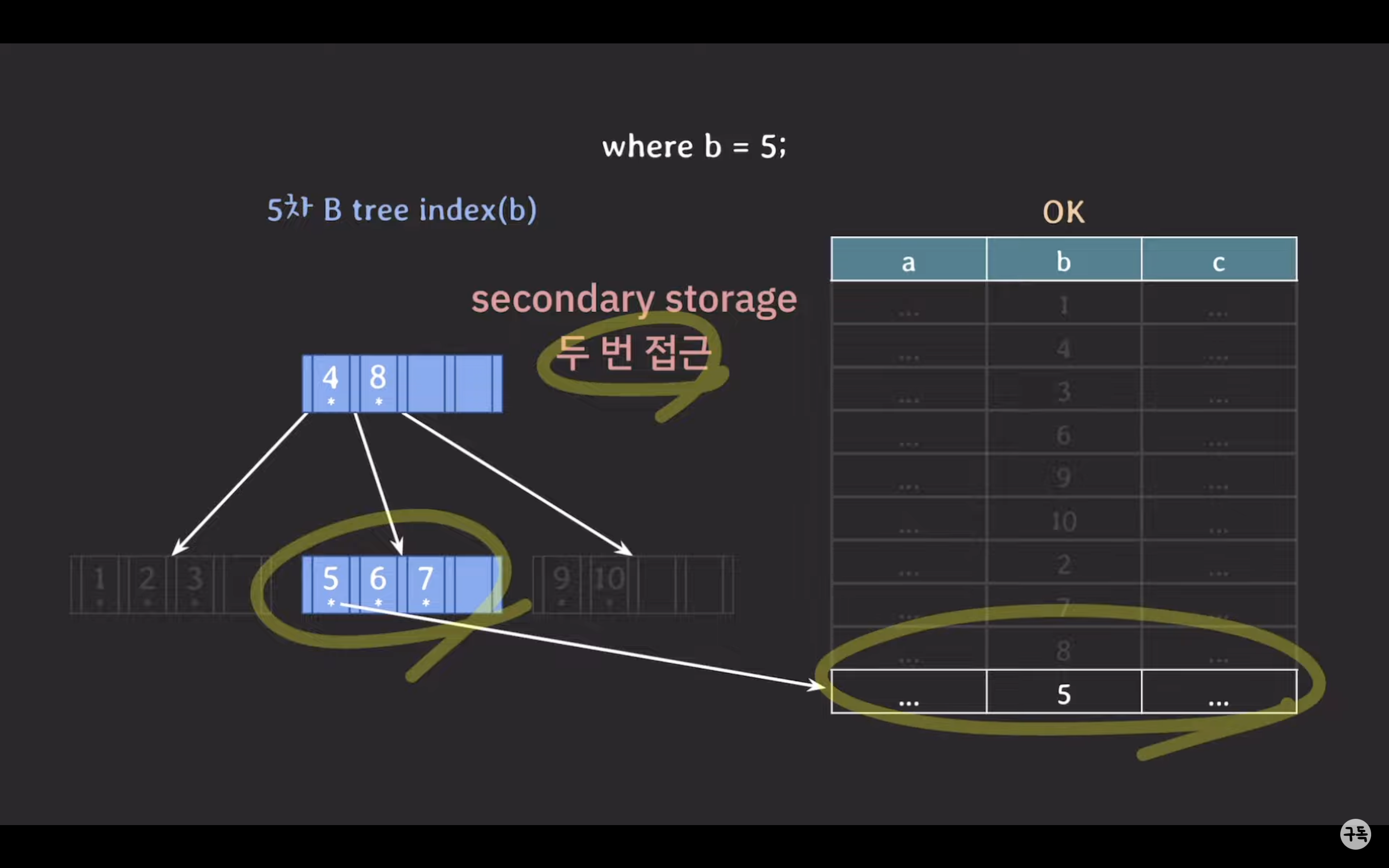
왜 5차 B-Tree가 더 성능이 좋은가?
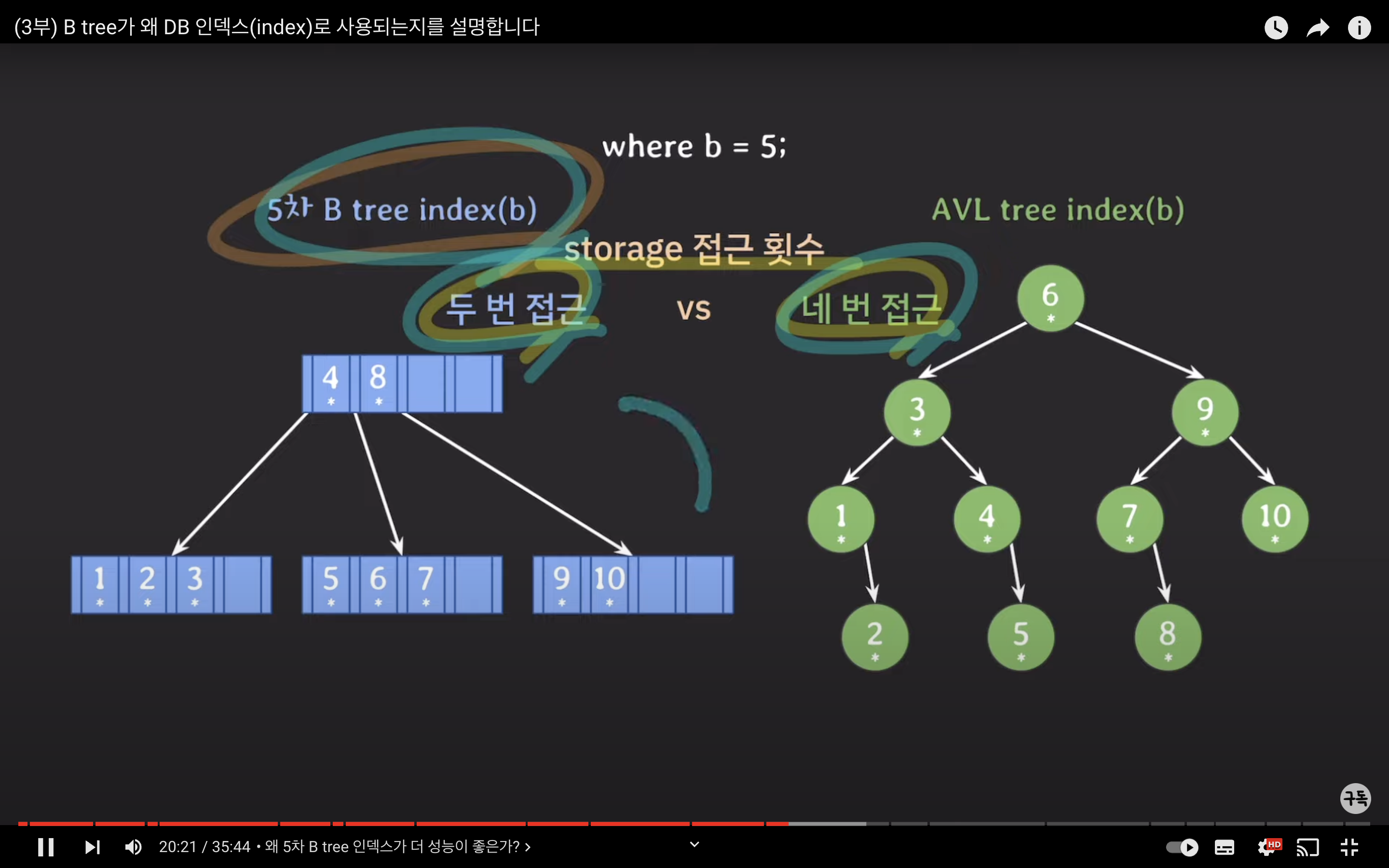
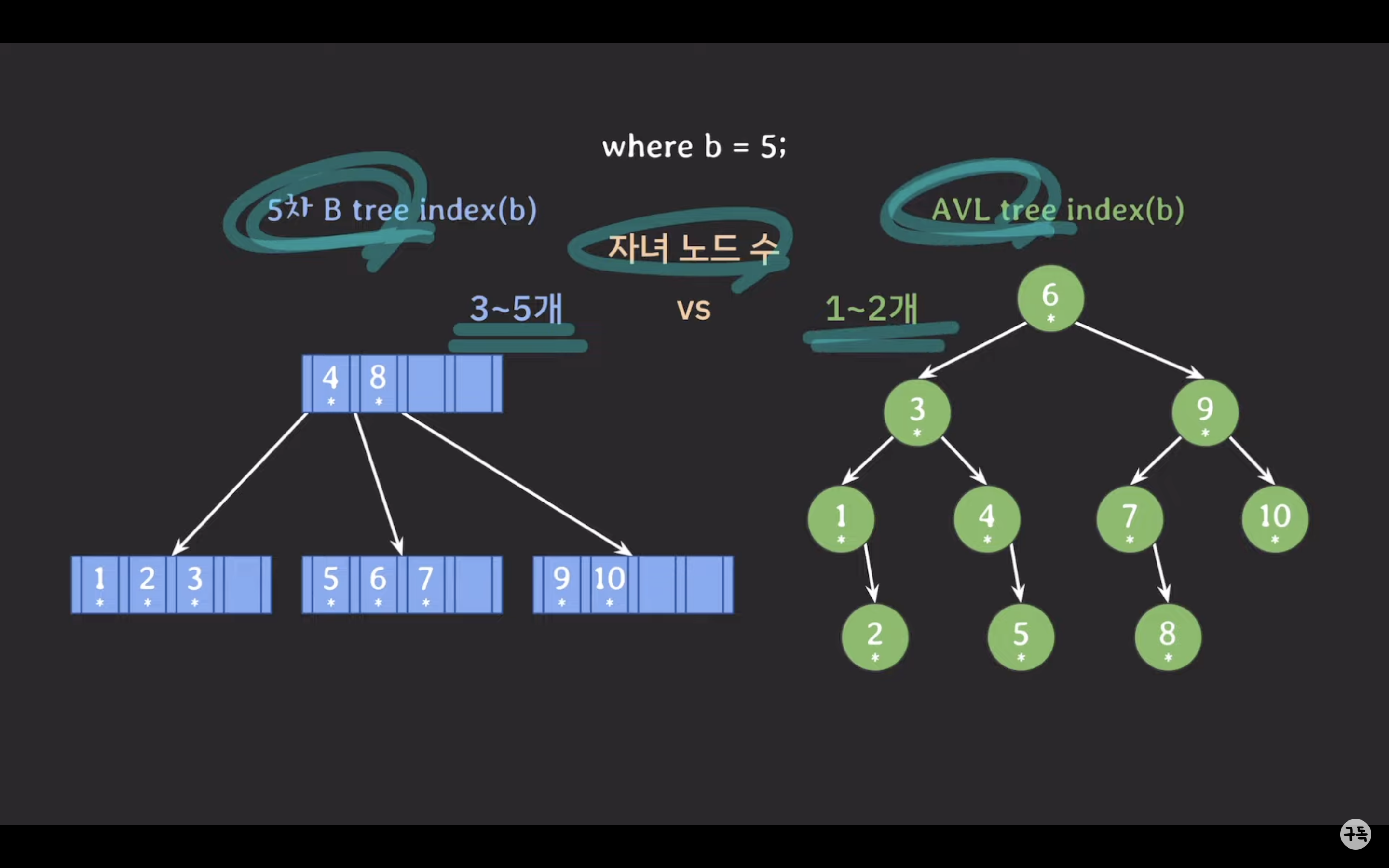
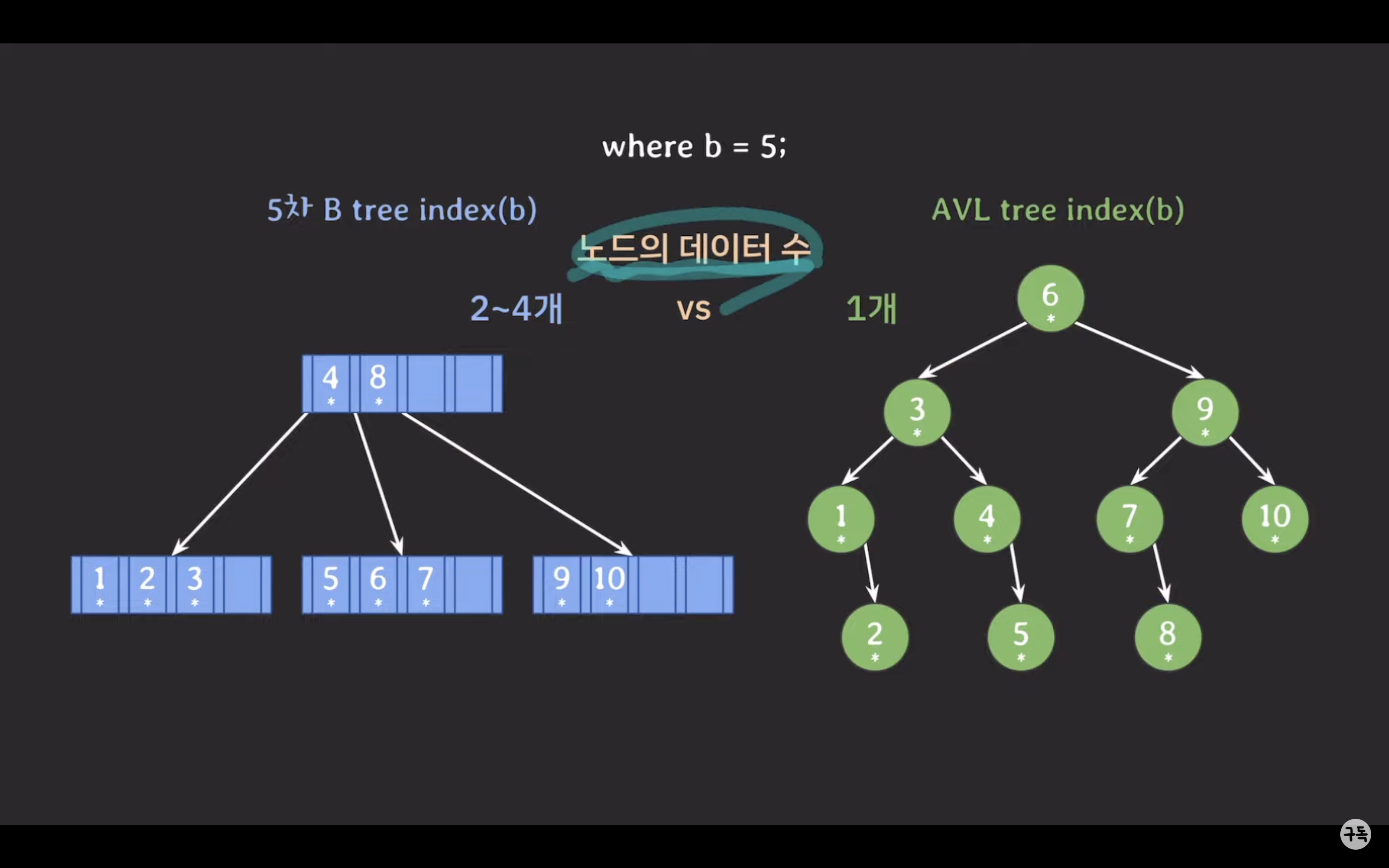
- 자녀 노드 수: 5차 B-Tree에서 각 노드는 3에서 5개의 자녀 노드를 가질 수 있습니다. 반면 AVL 트리는 각 노드가 1에서 2개의 자녀 노드를 가질 수 있습니다. 이로 인해 5차 B-Tree에서는 데이터를 찾을 때 탐색 범위를 더 빠르게 줄일 수 있습니다. AVL 트리에서는 좌우로만 브랜치가 나가므로 1/2씩 탐색 범위를 줄여나가지만, 5차 B-Tree에서는 최소한 1/3씩 탐색 범위를 줄여나가고 최대로는 1/5씩 탐색 범위를 줄여나갈 수 있습니다.
- 자료수 저장 용량: AVL 트리에서 각 노드는 1개의 데이터를 가질 수 있지만, 5차 B-Tree에서는 각 노드가 2에서 4개의 데이터를 가질 수 있습니다. Secondary storage에서는 데이터를 블록(block) 단위로 읽기 때문에 AVL 트리에서 특정 데이터를 읽어올 경우 해당 노드를 포함한 전체 블록을 읽어와야 합니다. 이로 인해 불필요한 데이터까지 읽어올 가능성이 있습니다. 그러나 5차 B-Tree에서는 하나의 노드에서 데이터 수를 더 많이 가질 수 있으므로 특정 노드를 읽어올 때 연관된 데이터를 효율적으로 읽어올 수 있습니다. 이로 인해 5차 B-Tree의 경우 블록 단위 저장 공간 활용도가 더 좋아집니다.
B-Tree의 강력함
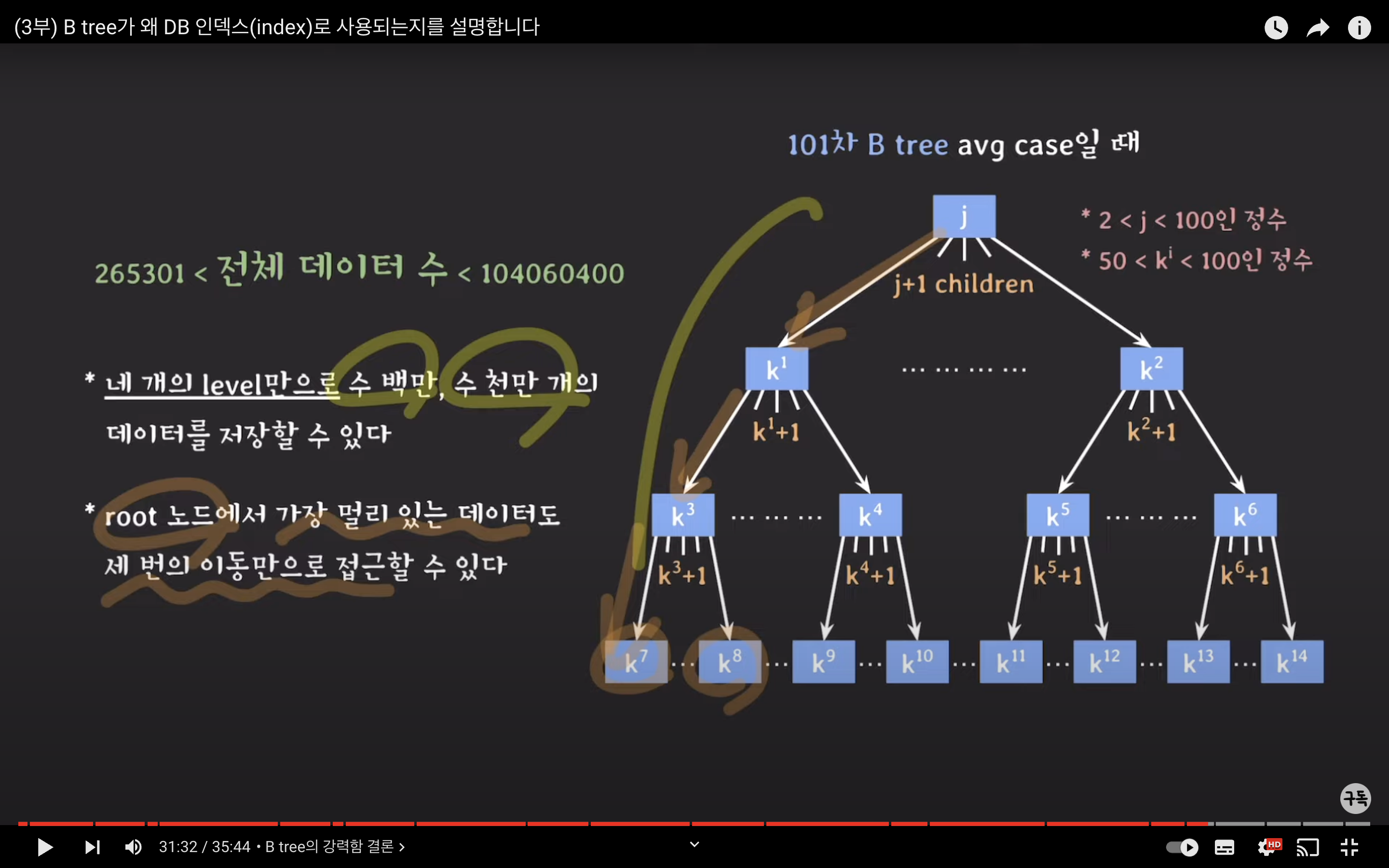
데이터 저장 용량: B-Tree는 네 개의 레벨만 사용하여 수 백만 또는 수 천만개의 데이터를 저장할 수 있습니다. 이는 대량의 데이터를 효율적으로 저장할 수 있는 강력한 구조를 제공합니다.
데이터 접근 속도: B-Tree는 데이터베이스의 root 노드에서 가장 멀리 떨어진 데이터에도 세 번의 이동만으로 접근할 수 있는 빠른 접근 속도를 제공합니다. 이로 인해 데이터 접근이 빠르고 효율적입니다.
B-Tree 계열을 DB인덱스로 사용하는 이유
Secondary Storage 활용: 데이터베이스는 기본적으로 secondary storage에 저장됩니다. B-Tree 인덱스는 self-balancing BST에 비해 secondary storage에 적은 접근을 필요로 합니다. 이는 디스크 I/O 작업을 줄여 데이터베이스 성능을 향상시킵니다.
블록 단위 저장: B-Tree의 노드는 block 단위의 저장 공간을 효율적으로 활용할 수 있습니다. 데이터베이스에서는 주로 블록(block) 단위로 데이터를 읽고 쓰기 때문에, B-Tree의 노드 구조는 디스크 I/O 작업을 최소화하고 연관된 데이터를 효율적으로 저장할 수 있습니다.
이러한 이유로 B-Tree는 대용량 데이터베이스에서 효과적으로 인덱스로 사용되며, 데이터의 저장과 검색을 빠르고 효율적으로 처리할 수 있는 강력한 구조입니다.
