들어가며
해당 영상을 보며 정리한 내용입니다.
Clustered Index
Clustered Index는 데이터베이스 테이블의 레코드들을 물리적으로 정렬하는 데 사용되는 인덱스입니다. Clustered Index는 테이블당 하나만 존재할 수 있으며, 주로 기본 키(primary key) 열에 자동으로 생성됩니다.
특징
테이블 당 1개만 존재 가능: 각 테이블은 오직 하나의 Clustered Index만 가질 수 있습니다. 테이블의 레코드들을 물리적으로 정렬하므로 하나만 존재해야 합니다.
기본 키(primary key) 제약조건으로 자동 생성: 대부분의 DBMS는 테이블에 기본 키를 정의할 때, 해당 기본 키 열을 기반으로 Clustered Index를 자동으로 생성합니다.
인덱스와 데이터 페이지가 함께 존재: Clustered Index의 특징 중 하나는 실제 데이터 페이지와 인덱스 페이지가 동일한 페이지에 존재한다는 것입니다. 이로 인해 Clustered Index의 검색 속도가 빠르며, 데이터를 가져오기 위해 두 번의 I/O 작업을 수행하지 않아도 됩니다.
리프 페이지 == 데이터 페이지: Clustered Index의 Leaf Page(가장 하위 수준의 인덱스 페이지)는 실제 데이터 페이지와 동일합니다. 따라서 Clustered Index를 통해 데이터를 검색할 때 Leaf Page에 접근하면 실제 데이터를 찾을 수 있습니다.
데이터가 정렬된 상태: Clustered Index는 데이터를 정렬된 상태로 저장하기 때문에 범위 검색(range scan) 및 정렬된 결과를 빠르게 반환하는 데 유용합니다.
예시
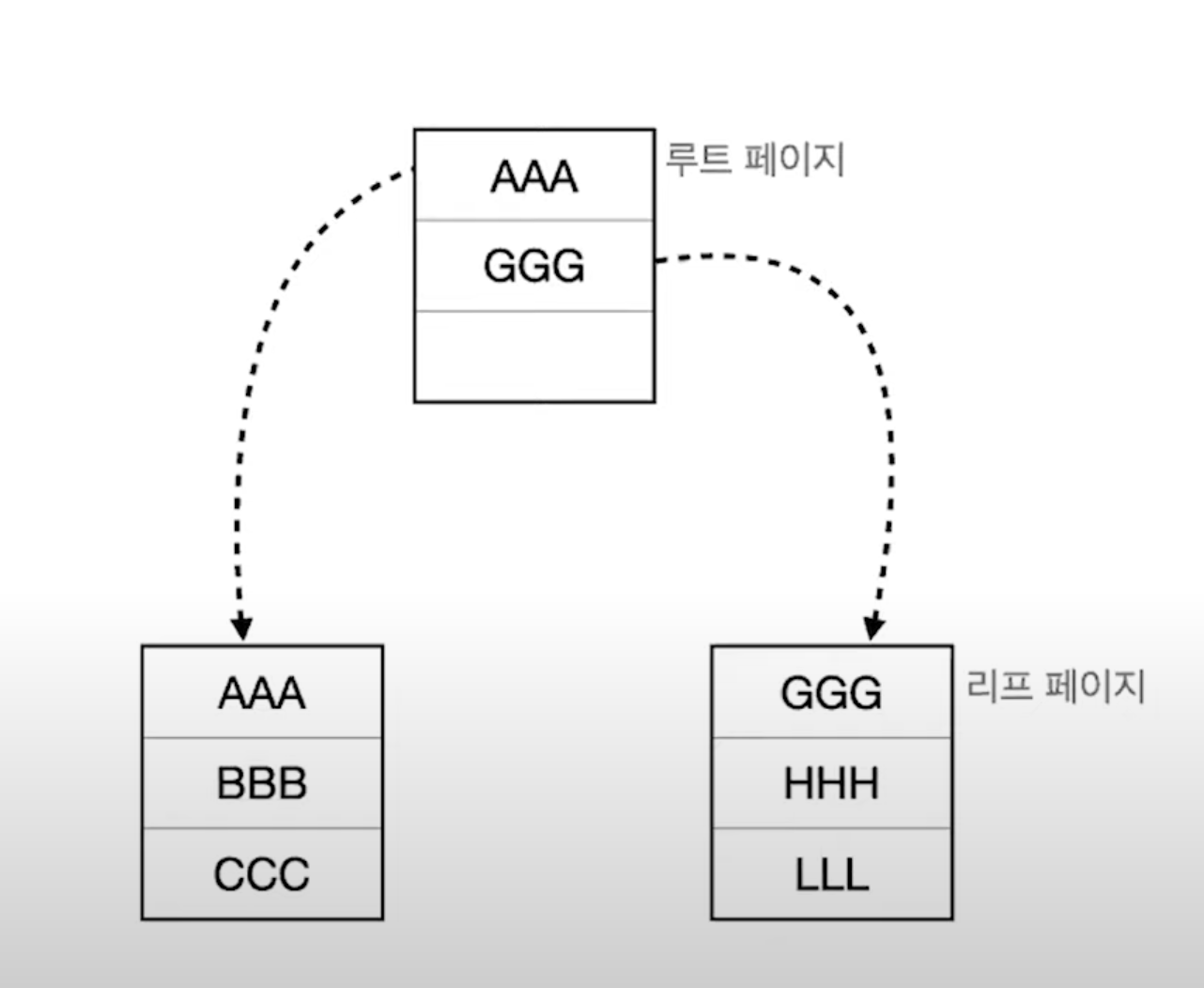
새로운 데이터인 "ddd"를 삽입하려고 합니다.
그러나 리프 페이지에는 더 이상 공간이 없기 때문에 페이지 분할이 발생합니다.
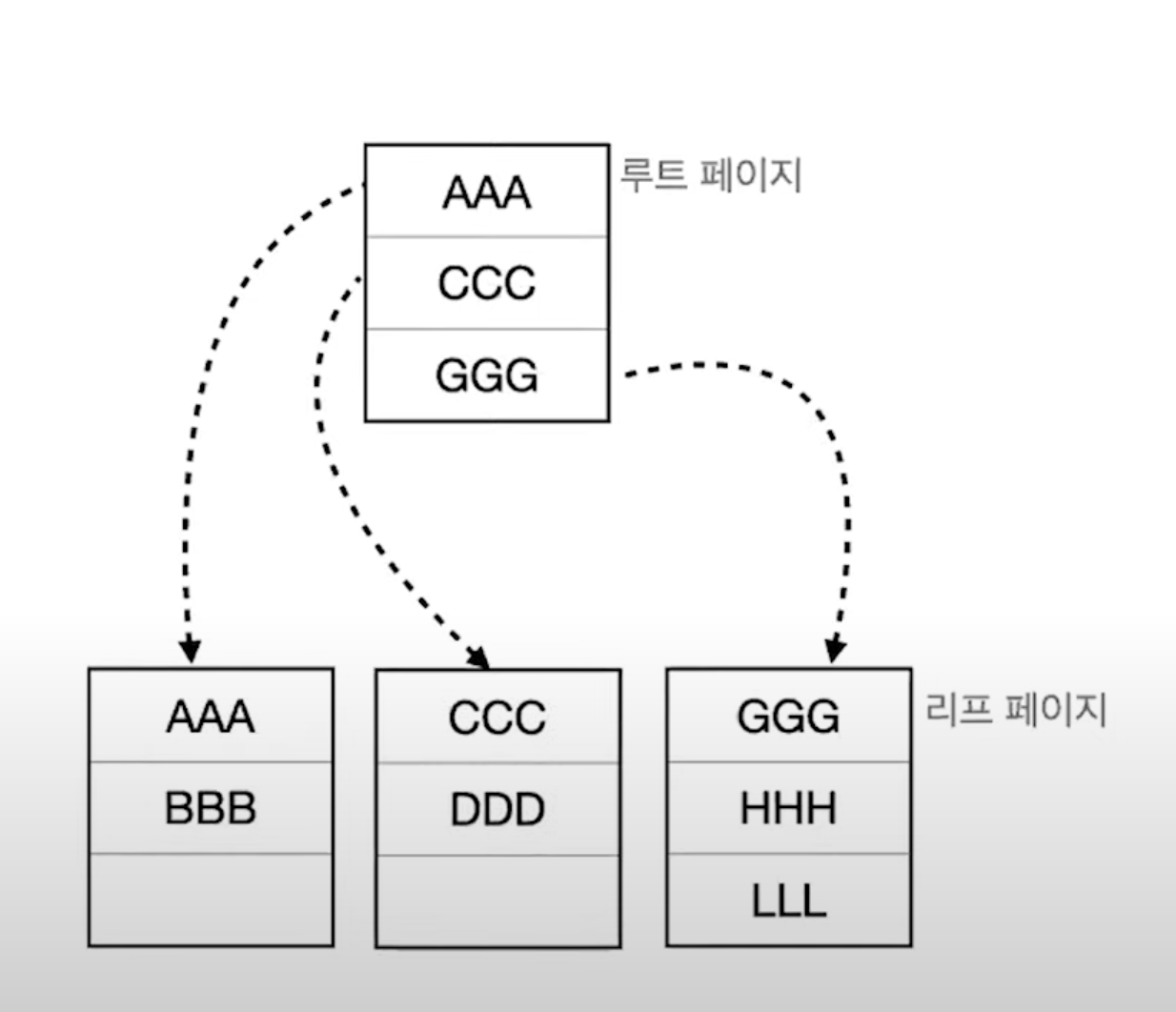
새로운 페이지가 생성되고, "ddd" 데이터는 그 페이지에 저장됩니다.
이로써 데이터는 여전히 정렬된 상태를 유지하게 됩니다.

이제 "kkk" 데이터를 삽입하려고 합니다.
ggg, hhh, lll 데이터가 존재하는 리프 페이지에는 공간이 없으므로 다시 페이지 분할이 발생합니다.
"kkk" 데이터는 새로운 페이지에 저장됩니다.
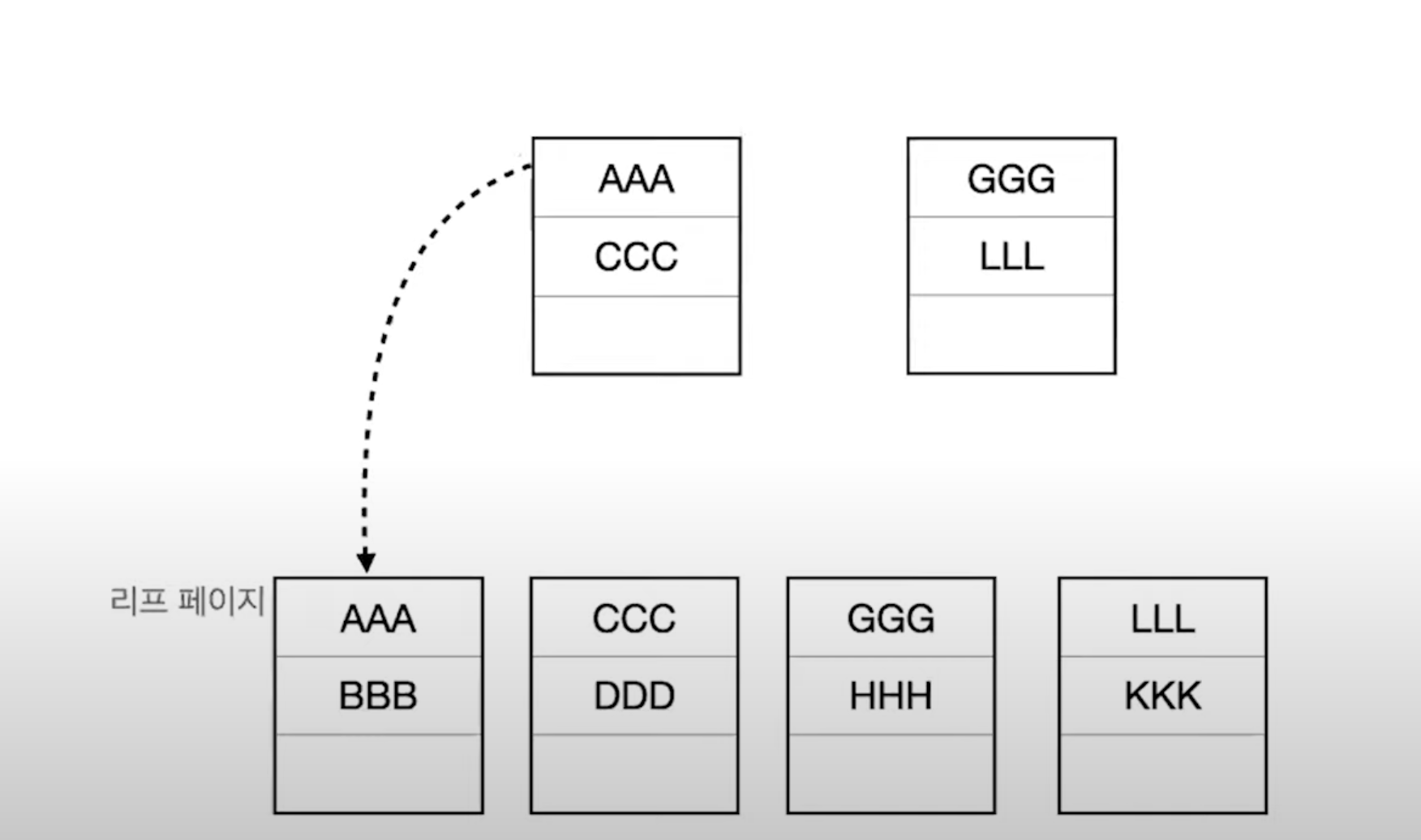
이제 루트 페이지에 새로운 데이터 "lll"을 추가해야 합니다.
그러나 aaa, ccc, ggg 데이터가 존재하는 루트 페이지에는 공간이 없습니다.
따라서 루트 페이지도 페이지 분할이 발생하며 새로운 루트 페이지가 생성됩니다.
분할 된 루트 페이지는 루트 페이지와 리프 페이지를 연결하는 중간 단계인 브랜치 페이지 역할을 수행합니다
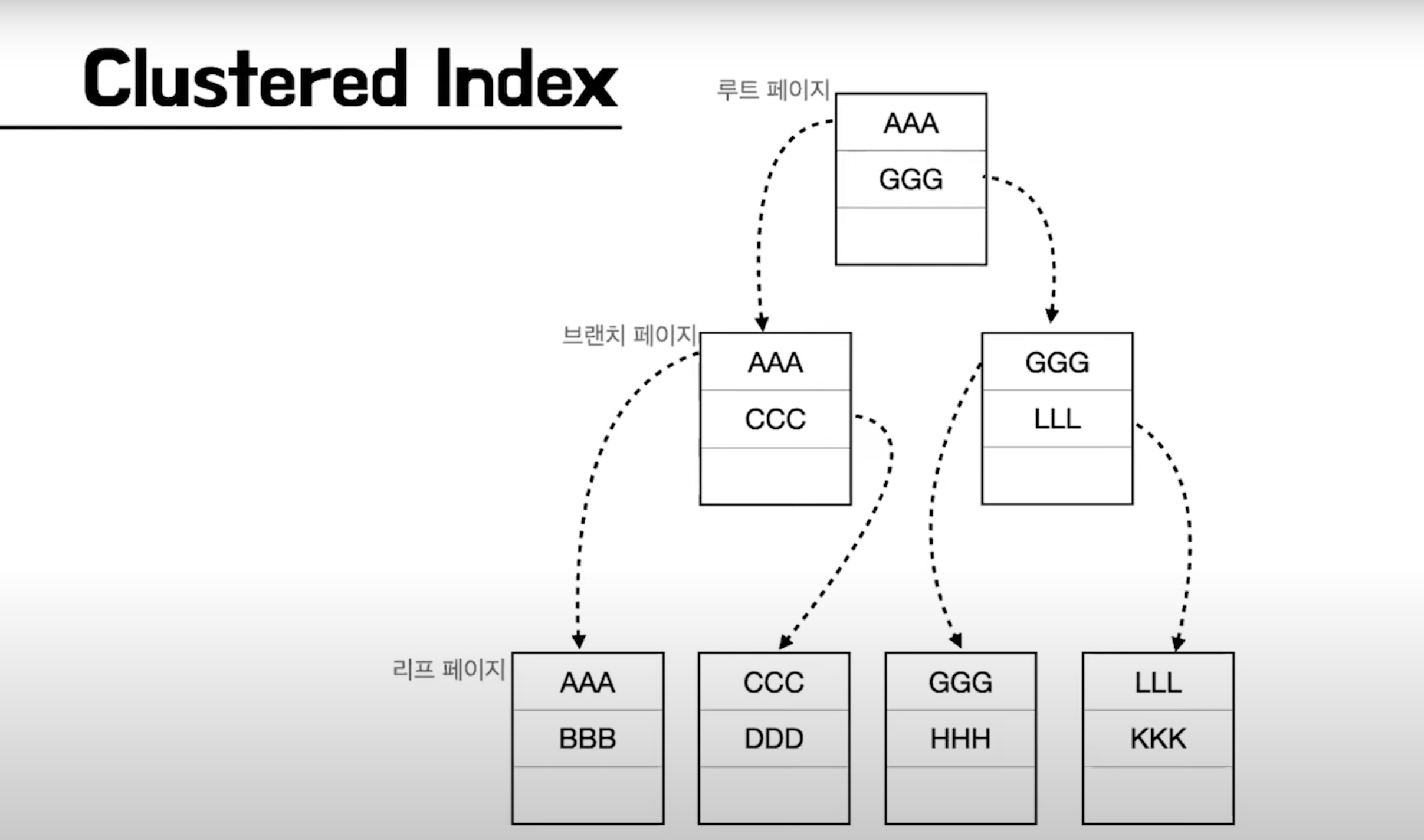
새로운 루트 페이지가 생성됩니다.
이러한 과정을 통해 밸런스를 유지하면서 트리 구조를 이루게 됩니다. 그러나 페이지 분할 작업은 데이터베이스에 부하를 주는 작업이므로 데이터베이스의 성능에 영향을 미칠 수 있습니다.
DB 예시

Non-Clustered Index
Non-Clustered Index는 데이터베이스에서 데이터의 빠른 검색을 지원하는 또 다른 유형의 인덱스입니다
특징
secondary Index (보조 인덱스): Clustered Index는 테이블에 하나만 존재할 수 있지만, Non-Clustered Index는 여러 개 생성할 수 있습니다.
Unique 제약조건으로 생성 가능: unique 제약조건으로 컬럼을 생성하면 자동으로 생성됩니다.
인덱스와 데이터 페이지 분리: Non-Clustered Index의 핵심 특징은 데이터 페이지와 인덱스 페이지가 서로 분리되어 있다는 점입니다. 데이터 페이지에는 데이터가 저장되고, 인덱스 페이지에는 인덱스 키 값과 데이터의 위치를 가리키는 포인터가 저장됩니다.
리프 페이지에서 데이터 주소를 가짐: Non-Clustered Index의 리프 페이지(가장 하위 수준의 인덱스 페이지)에는 실제 데이터가 아니라 데이터가 저장된 위치(포인터)를 가지고 있습니다. 이 포인터를 사용하여 데이터 페이지로 이동하여 실제 데이터를 찾습니다
데이터 정렬 필요 없음: Non-Clustered Index는 데이터 페이지에 데이터를 정렬할 필요가 없습니다. Clustered Index와는 다르게 데이터 페이지에 저장된 데이터의 물리적인 순서와는 무관합니다.
예시

데이터 페이지에서는 정렬이 일어나지 않고, 인덱스 페이지에서만 정렬이 발생하므로 Write 연산(데이터 추가, 수정, 삭제) 시에는 Clustered Index보다 오버헤드가 적을 수 있습니다. 데이터 페이지에 레코드를 추가할 때 정렬을 고려할 필요가 없기 때문입니다.
조회 시 인덱스 페이지에서 데이터의 위치를 찾은 후 데이터 페이지로 이동해야 합니다. 이로 인해 Clustered Index에 비해 조회 속도가 약간 느릴 수 있습니다.
범위 검색(range scan)의 경우 인덱스 페이지에서 다수의 데이터 페이지로 이동해야 하므로 효율성이 떨어질 수 있습니다.
범위 검색의 경우 Clustered Index 비교해서 페이지 이동이 더 많이 발생할 수 있기 때문에 효율이 좋지 않을 수 있다.
[Clustered Index in MongoDB]
MongoDB Doc
How MongoDB Clustered Collection Can Boost Query Performance
