들어가며
인프런의 해당 강좌를 학습하며 정리한 내용입니다.
N+1 문제
N+1 문제는 주로 일대다 또는 다대다 관계에서 발생하는 성능 문제입니다. 이 문제를 이해하기 위해 한 가지 사례를 살펴보겠습니다.
사용자(User)와 사용자가 작성한 게시물(Post)이라는 두 개의 컬렉션이 있다고 가정해 봅시다.
각 사용자는 여러 개의 게시물을 작성할 수 있으며, 각 게시물은 해당 사용자에게 속합니다.
만약 일반적인 방식으로 사용자와 관련된 모든 게시물을 가져오려고 하면 다음과 같은 접근 방식을 사용할 수 있습니다.
- 모든 사용자를 가져옵니다.
- 각 사용자에 대해 해당 사용자의 게시물을 가져옵니다.
const users = await User.find();
for (const user of users) {
const posts = await Post.find({ userId: user._id });
user.posts = posts;
}
위의 코드에서는 사용자를 가져온 후에 각 사용자마다 해당 사용자의 게시물을 가져오기 위해 여러 번의 쿼리를 실행하게 됩니다. 이는 n+1 문제를 발생시키는 것입니다.
예를 들어, 사용자 100명이 있다고 가정하면 다음과 같이 실행됩니다:
- 사용자 목록을 가져오는 쿼리 한 번 실행
- 각 사용자에 대해 게시물을 가져오는 쿼리를 100번 실행
따라서 전체적으로는 101개의 쿼리가 실행되는 것이며, 이는 데이터베이스에 부하를 주고, 응답 시간을 늘릴 수 있는 성능 문제를 야기할 수 있습니다.
FK를 고려하지 않고 스키마 설계
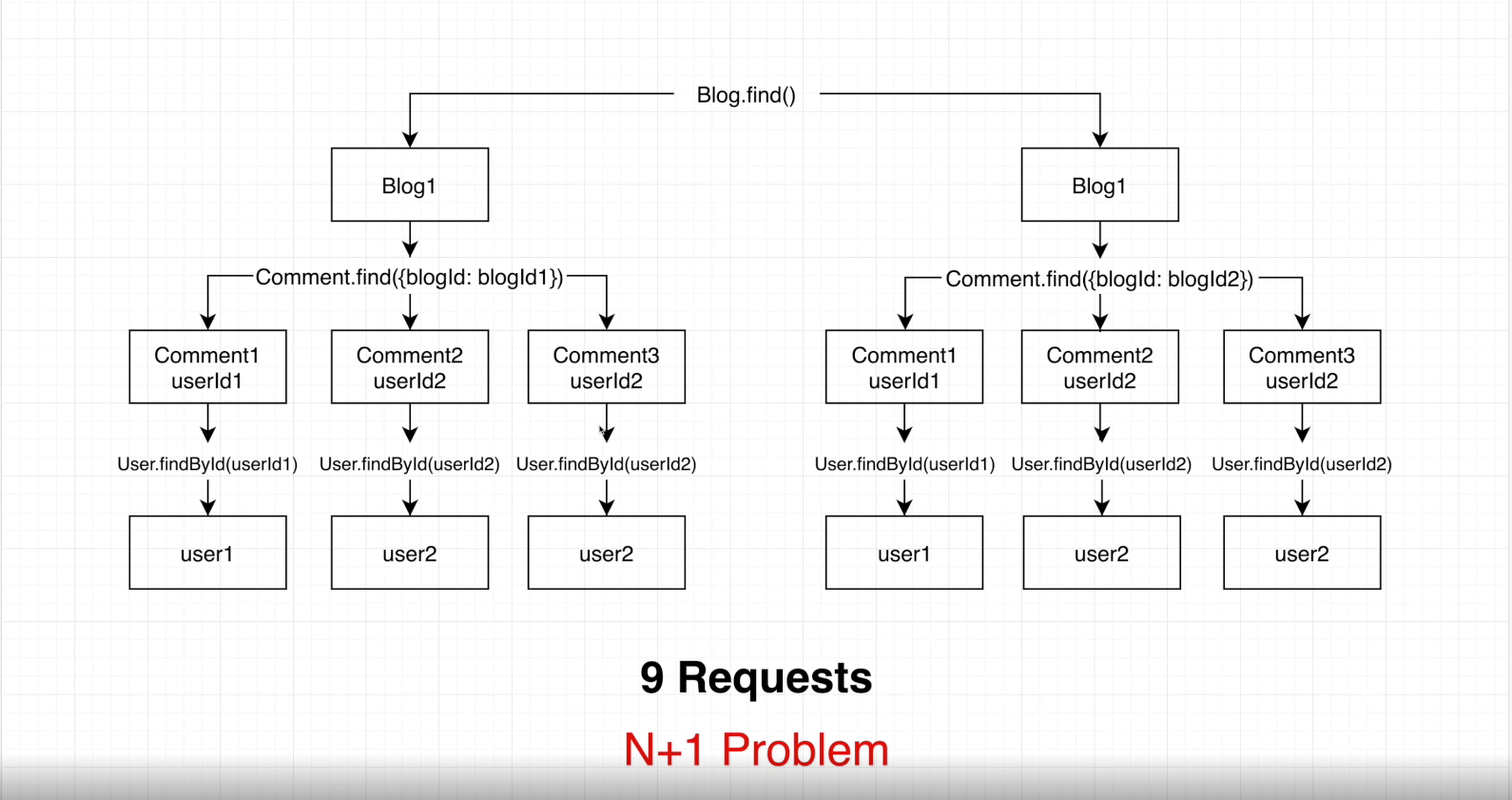
해당 이미지는 모든 Blog의 목록을 조회했을 때, Blog가 총 2개이고 각각의 Blog내에 3개의 댓글이 있는 경우입니다.
총 2개의 Blog를 불러오는 경우인데도 불구하고 9번의 요청이 일어나는 것을 볼 수 있습니다.
Blog.find() +
Commment.find({blogId:blogId1}) +
Commment.find({blogId:blogId2}) +
User.findById(userId1) +
User.findById(userId2) +
User.findById(userId2) +
...
또 비효율적인 점은, 같은 유저가 후기를 작성했을 경우에도 똑같은 호출을 반복하고 있습니다.
이와 같은 구조라면 데이터의 개수가 늘어나면 수십번, 수만번으로 DB 호출이 늘어나므로 좋지 않습니다.
Mongoose Populate 사용
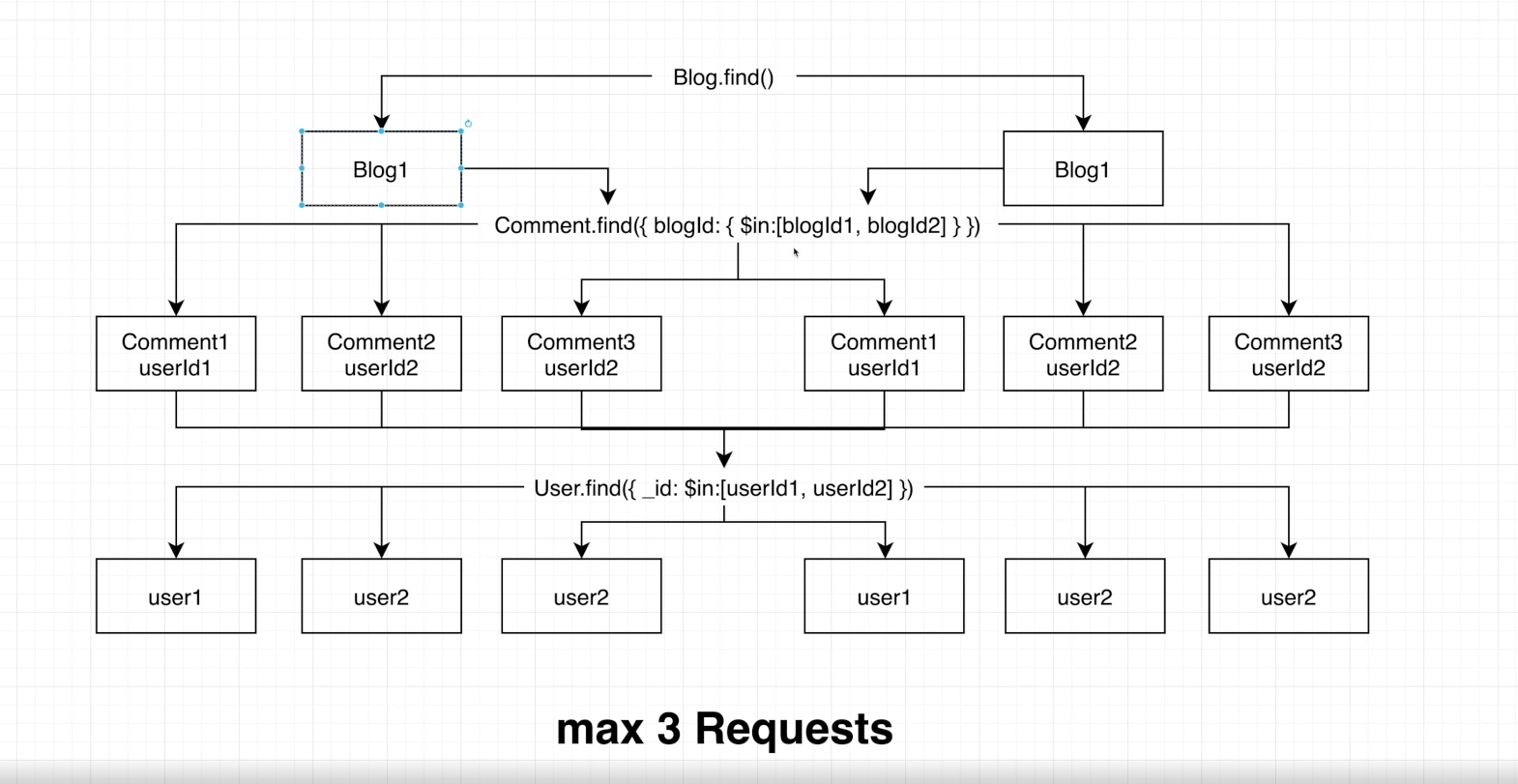
Populate를 사용해 N+1 문제를 개선해봅시다.
기존 방식에서는 findById 또는 findOne을 통해 중복된 것들도 모두 하나씩 요청을 보냈습니다.
Populate를 사용한다면 Id를 취합하여 모든 데이터를 가져온 뒤, 그에 맞는 Document에 연결해줍니다.
그림을 예로들면, Mongoose가 blogId 또는 userId를 취합하여 $in 연산자를 사용해 취합한 Id에 해당하는 모든 데이터들을 다 불러온 뒤, 각 블로그 또는 댓글에 맞게 연결해줍니다.
데이터의 정말 많아지면, 데이터를 탐색하는 시간이 길어지므로 이 또한 latency가 발생할 수 있습니다.
그렇지만 이전 방식과 비교하여 호출 횟수가 획기적으로 줄어들었습니다.
populate를 사용하여 n+1 문제를 해결하면 쿼리의 수를 줄일 수 있으며, 데이터베이스와의 통신 횟수를 최소화하여 성능을 향상시킬 수 있습니다.
(해결 방안: index 도입)
Embedded 스키마 설계
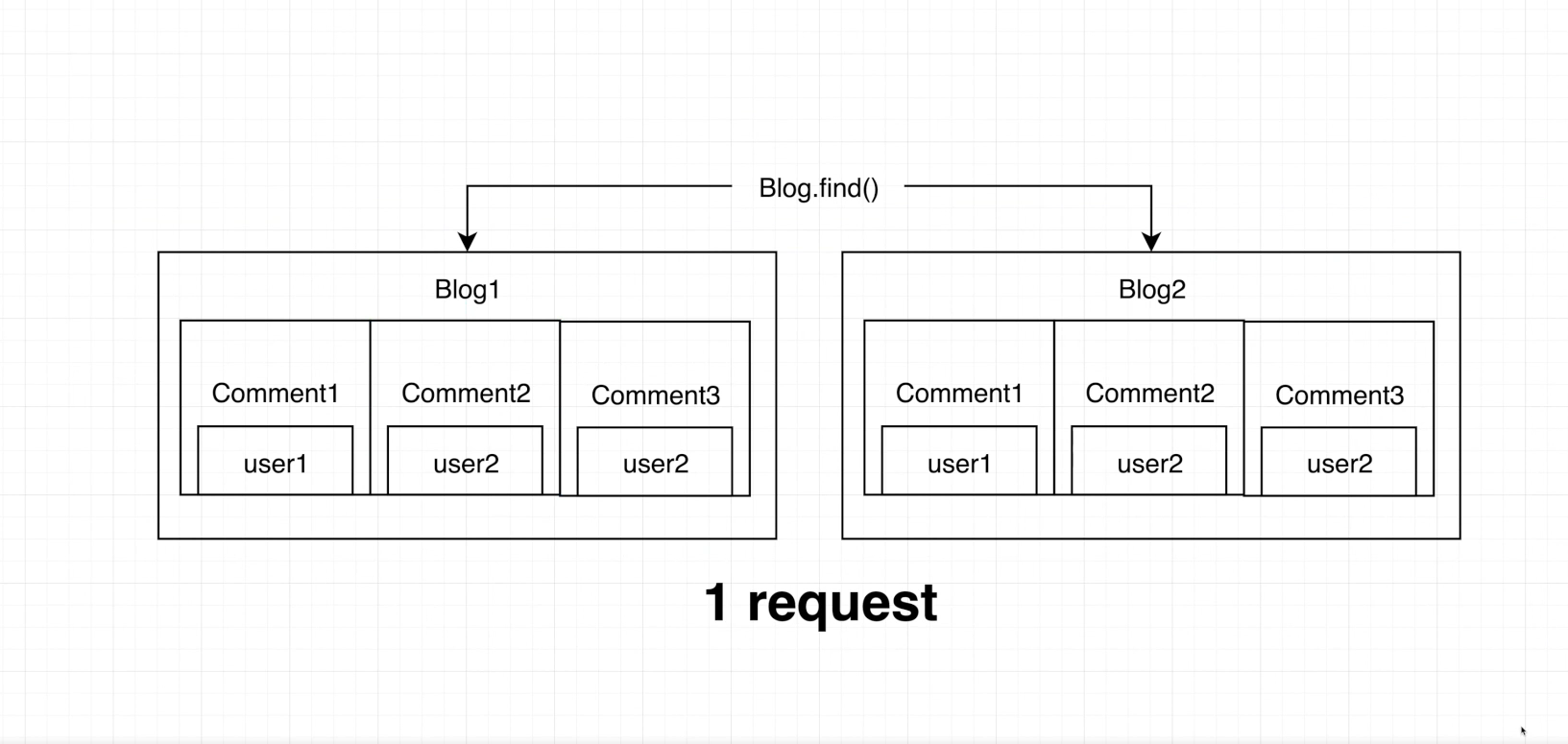
단 한번의 쿼리로 원하는 모든 정보를 가져올 수 있습니다.
하지만 이 또한 trade-off가 존재합니다. 관련 글
