NestJS에서 Grafana, Loki, Prometheus를 활용한 모니터링 시스템 구축하기
들어가며
현재 팀에서는 총 4개의 서버를 운영하고 있습니다:
-
광고주용 백엔드 서버
-
메가·매크로 인플루언서용 백엔드 서버
-
나노·마이크로 인플루언서용 백엔드 서버
-
내부 운영을 위한 백오피스 서버
기존에는 AWS CloudWatch를 활용해 로그를 저장하고, 에러 발생 시 Slack 알림을 전송하는 방식으로 디버깅을 진행해 왔습니다. 또한, AWS Logs Insights를 이용해 requestId 기반으로 에러 로그를 필터링하고, 이를 한눈에 확인할 수 있는 URL을 제공하는 형태로 모니터링 시스템을 구축했습니다.
초기에는 이러한 방식이 큰 불편함 없이 동작했지만, 시간이 지나며 모든 서버의 로그를 한눈에 확인할 수 있는 통합 대시보드에 대한 니즈가 커졌습니다.
이에 따라, 서버별 및 로그 레벨별로 로그를 분류하고, 시각적으로 모니터링할 수 있는 시스템의 필요성을 느꼈습니다.
이를 통해 문제를 더 빠르게 파악하고 대응할 수 있는 로그 모니터링 시스템을 구축하기로 결정했습니다.
Loki
Loki는 로그 데이터 자체를 인덱싱하지 않고, 라벨(metadata)만 인덱싱하는 방식으로 동작합니다. 이를 통해 저장 공간을 크게 절약할 수 있으며, 특히 대규모 로그 데이터를 처리할 때 전통적인 로그 시스템(예: ELK 스택) 대비 비용 효율성이 뛰어납니다.
또한, Grafana와 연동하여 로그 데이터를 손쉽게 시각화할 수 있어, 서버별·로그 레벨별로 로그를 분류하고 한눈에 모니터링할 수 있는 환경을 구축할 수 있습니다.
더불어, ELK 스택에 비해 러닝 커브가 낮아 빠르게 도입하고 활용할 수 있다는 점도 큰 장점으로 작용했습니다. 이러한 이유로 Loki를 활용하여 로그 데이터를 관리하기로 결정했습니다.
NestJS에서 Loki로 로그 전송하기
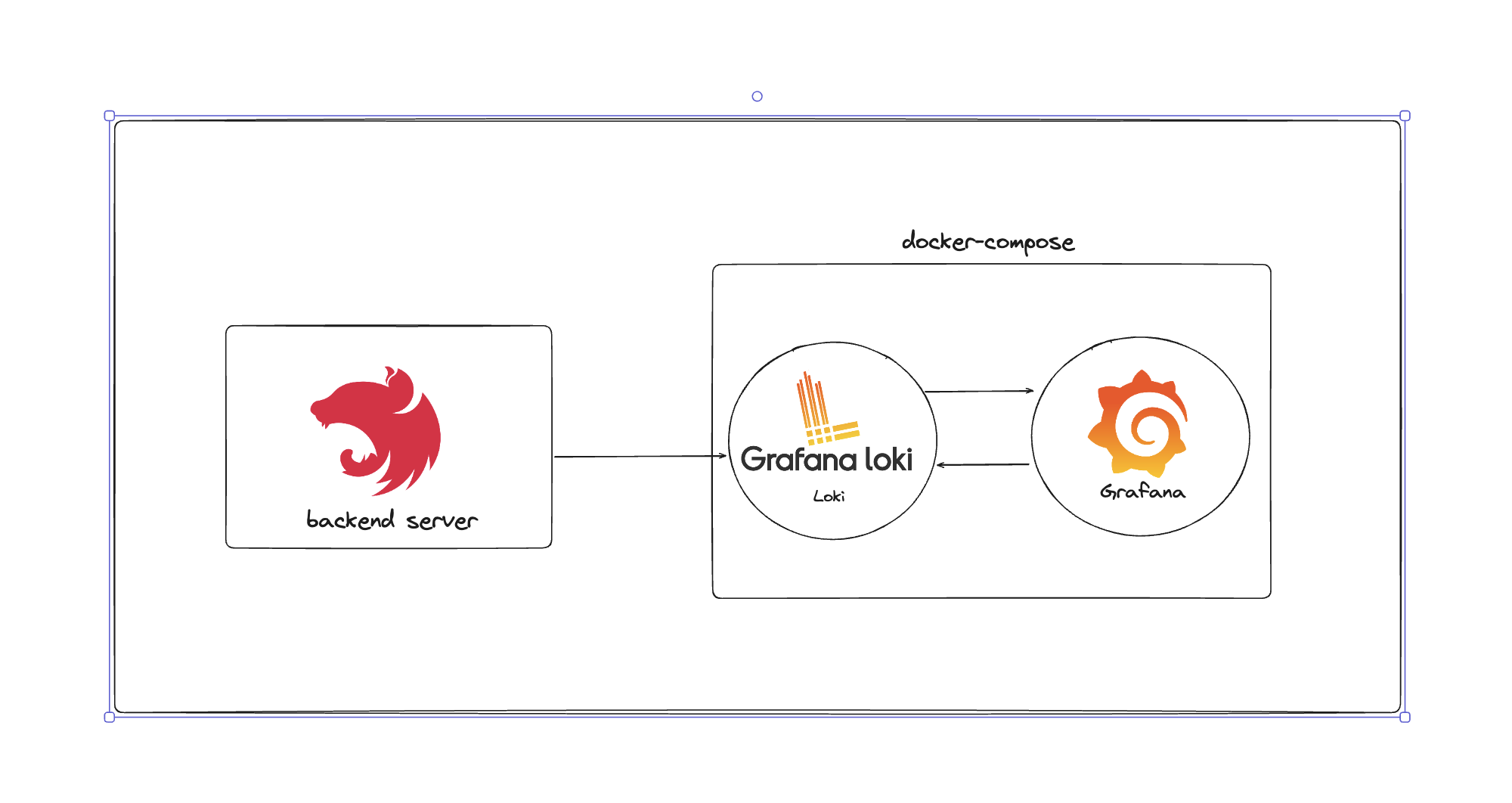
NestJS에서는 winston-loki 라이브러리를 사용하여 손쉽게 Loki 서버와 연동할 수 있습니다.
아래와 같이 WinstonModule을 설정할 때 LokiTransport를 추가하면, 로그를 Loki 서버로 전송할 수 있습니다.
WinstonModule.forRootAsync({
inject: [ConfigServiceKey],
useFactory: (configsService: CreplanetConfigServiceInterface) => {
const { ENV, NAME } = configsService.getAppConfig();
const lokiConfig = configsService.getLokiConfig();
if (ENV !== Env.local && ENV !== Env.test) {
return {
transports: [
new winston.transports.Console({ level: 'info' }), // 콘솔 출력
new LokiTransport({
host: lokiConfig.LOKI_HOST, // Loki 서버 URL
labels: { app: `${ENV}-${NAME}` }, // 로그 라벨 설정
}),
],
};
}
},
});
이렇게 설정하면, 애플리케이션에서 발생하는 로그가 자동으로 Loki 서버로 전송되며, 이후 Grafana를 통해 시각적으로 확인할 수 있습니다.
Loki 서버 설정
로그를 Loki 서버로 전송하기 위해서는 Loki 서버가 필요합니다. 저는 AWS Lightsail을 활용해 서버를 띄우고, Docker Compose를 통해 Loki와 Grafana 서버를 배포했습니다.
Docker Compose 파일
version: "3.8"
services:
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3001:3000"
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: admin
volumes:
- grafana_data:/var/lib/grafana
depends_on:
- loki
networks:
- app-network
loki:
image: grafana/loki:latest
container_name: loki
ports:
- "3100:3100"
command: -config.file=/etc/loki/local-config.yaml
volumes:
- ./monitoring/loki/local-config.yaml:/etc/loki/local-config.yaml
- ./data/loki:/loki
networks:
- app-network
prometheus:
image: prom/prometheus:latest
container_name: prometheus
ports:
- "9090:9090"
volumes:
- ./monitoring/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
networks:
- app-network
volumes:
grafana_data:
networks:
app-network:
driver: bridge
Loki 설정 파일
# /loki/local-config.yaml
# Loki를 파일 시스템을 백엔드로 사용하여 배포하는 완전한 구성입니다.
# 인덱스는 tsdb-shipper를 통해 스토리지로 전송됩니다.
auth_enabled: false # 인증을 사용하지 않도록 설정
server:
http_listen_port: 3100 # Loki 서버가 수신할 HTTP 포트 설정 (기본값: 3100)
common:
ring:
instance_addr: 127.0.0.1 # Loki 인스턴스의 주소 (클러스터링을 위한 주소 설정)
kvstore:
store: inmemory # 키-값 스토어 설정 (여기서는 메모리 내에서 관리)
replication_factor: 1 # 복제 인스턴스 수 (기본값: 1)
path_prefix: /tmp/loki # Loki의 기본 경로 설정 (데이터를 저장할 디렉터리 경로)
schema_config:
configs:
- from: 2020-05-15 # 스키마 버전 시작일 설정 (이 날짜 이후부터 적용)
store: tsdb # 저장소 유형 (TSDB 사용)
object_store: filesystem # 객체 스토어 유형 (파일 시스템 사용)
schema: v13 # 스키마 버전 설정
index:
prefix: index_ # 인덱스 파일의 접두사 (기본값: 'index_')
period: 24h # 인덱스 생성 주기 설정 (24시간마다 새로운 인덱스를 생성)
storage_config:
filesystem:
directory: /tmp/loki/chunks # 파일 시스템에 저장할 로그 청크 디렉터리 경로 설정
limits_config:
volume_enabled: true
ingestion_rate_mb: 10 # 초당 최대 수집 속도 (기본값: 4MB, 이 값을 10MB로 설정)
ingestion_burst_size_mb: 20 # 버스트 모드에서 최대 수집량 (기본값: 6MB, 이 값을 20MB로 설정)
per_stream_rate_limit: 5MB # 스트림 당 최대 수집 속도 (기본값: 3MB, 이 값을 5MB로 설정)
per_stream_rate_limit_burst: 10MB # 스트림 당 버스트 모드에서 최대 수집량 (기본값: 15MB, 이 값을 10MB로 설정)
위와 같은 설정을 통해 Docker Compose를 사용하여 Loki와 Grafana 서버를 배포하고, NestJS 서버에서 Loki 서버로 로그를 전송하여 Grafana에서 이를 시각화할 수 있습니다.
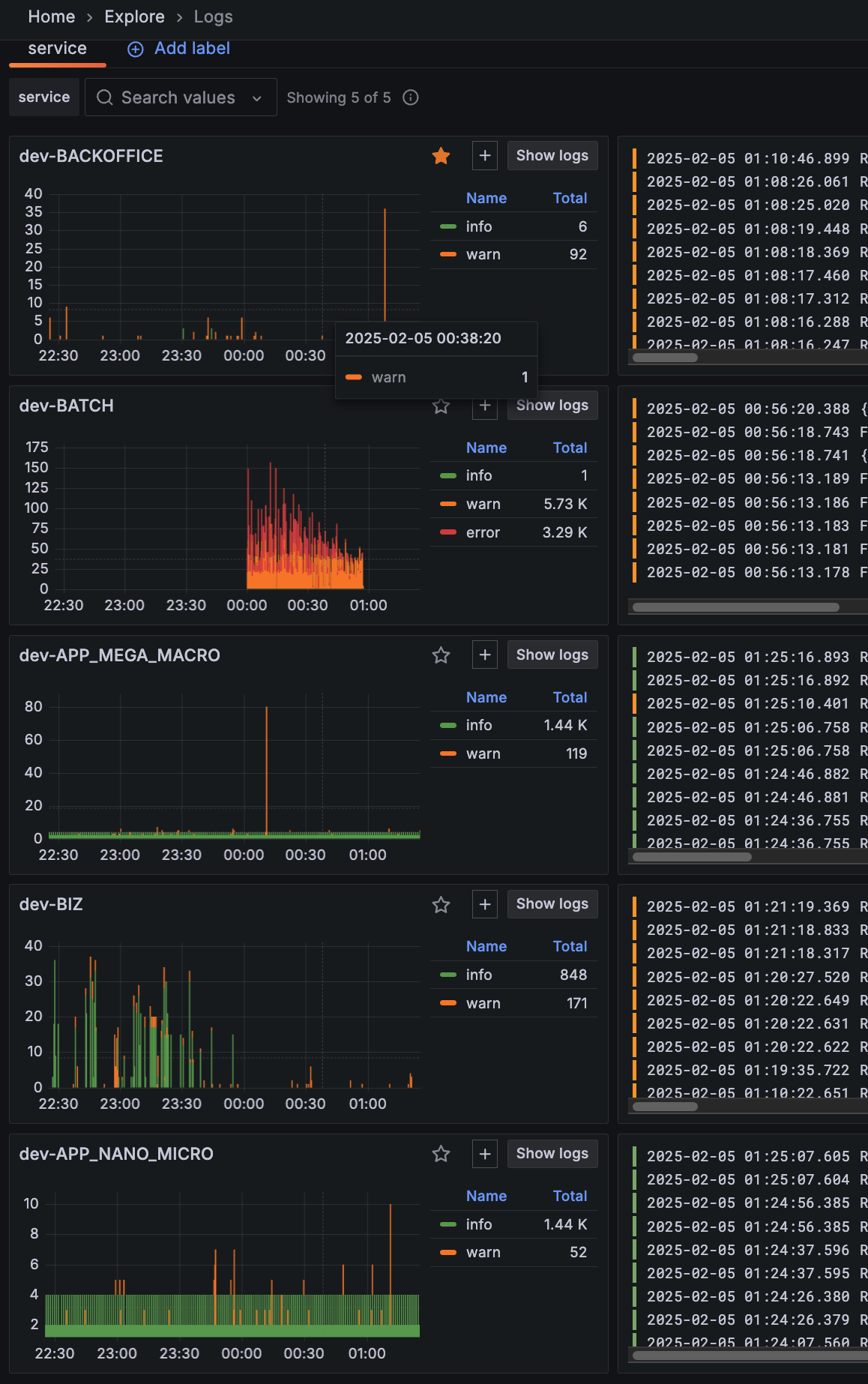
Prometheus
Prometheus는 시계열(time-series) 데이터 수집 및 모니터링을 위한 오픈 소스 시스템입니다. 주로 애플리케이션 및 인프라에서 발생하는 메트릭 데이터를 수집하고 저장하며, 이를 기반으로 경고 및 시각화를 제공합니다.
NestJS 애플리케이션에서 Prometheus를 활용하면 요청 수, 응답 시간, 에러율 등 다양한 성능 메트릭을 실시간으로 모니터링할 수 있습니다. 이를 통해 애플리케이션의 상태를 파악하고 성능 최적화를 위한 인사이트를 얻을 수 있습니다.
nestjs에서 @wilsoto/prometheus를 활용해 메트릭 수집하기
NestJS에서 Prometheus와의 연동을 위해 @wilsoto/prometheus 라이브러리를 사용할 수 있습니다.
설치
npm install @wilsoto/prometheus
module 코드 예시
NestJS 애플리케이션에서 Prometheus를 설정하려면, PrometheusModule을 추가하고 원하는 메트릭을 수집하는 코드를 작성합니다.
import { Module } from '@nestjs/common';
import {
makeCounterProvider,
makeGaugeProvider,
makeHistogramProvider,
makeSummaryProvider,
PrometheusModule,
} from '@willsoto/nestjs-prometheus';
import { MetricsService } from './metrics.service';
import { MetricsController } from './metrics.controller';
@Module({
imports: [
PrometheusModule.register({
path: '/api/metrics', // 엔드포인트 설정
defaultMetrics: {
enabled: true,
},
}),
],
controllers: [MetricsController],
providers: [
MetricsService,
makeCounterProvider({
name: 'feature_metric',
help: 'This is a feature specific metric',
}),
makeGaugeProvider({
name: 'memory_usage',
help: 'Current memory usage',
}),
makeHistogramProvider({
name: 'http_request_duration_seconds',
help: 'Duration of HTTP requests in seconds',
buckets: [0.1, 0.5, 1, 2.5, 5, 10],
}),
makeSummaryProvider({
name: 'http_request_summary',
help: 'Summary of HTTP request durations',
percentiles: [0.5, 0.9, 0.99],
}),
],
exports: [MetricsService],
})
export class MetricsModule {}
이제 애플리케이션은 /api/metrics 엔드포인트에서 Prometheus가 수집할 수 있는 메트릭을 노출하게 됩니다.
interceptor 코드 예시
import { MetricsService } from './metrics.service';
import {
CallHandler,
ExecutionContext,
Injectable,
NestInterceptor,
OnModuleInit,
} from '@nestjs/common';
import { Gauge, Histogram } from 'prom-client';
import { catchError, Observable, tap } from 'rxjs';
@Injectable()
export class MetricsInterceptor implements NestInterceptor, OnModuleInit {
constructor(private readonly metricsService: MetricsService) {}
// 초기화 각 수집 metrics 초기화
onModuleInit() {
this.metricsService.resetMetrics();
}
// status code 2XX 요청 성공동안 걸리는 시간
private readonly requestSuccessHistogram = new Histogram({
name: 'nestjs_success_requests',
help: 'NestJs success requests - duration in seconds',
labelNames: ['handler', 'controller', 'method'],
buckets: [0.0001, 0.001, 0.005, 0.01, 0.025, 0.05, 0.075, 0.09, 0.1, 0.25, 0.5, 1, 2.5, 5, 10],
});
// status code != 2XX 실패 동안 걸리는 시간
private readonly requestFailHistogram = new Histogram({
name: 'nestjs_fail_requests',
help: 'NestJs fail requests - duration in seconds',
labelNames: ['handler', 'controller', 'method'],
buckets: [0.0001, 0.001, 0.005, 0.01, 0.025, 0.05, 0.075, 0.09, 0.1, 0.25, 0.5, 1, 2.5, 5, 10],
});
static registerServiceInfo(serviceInfo: {
domain: string;
name: string;
version: string;
}): MetricsInterceptor {
new Gauge({
name: 'nestjs_info',
help: 'NestJs service version info',
labelNames: ['domain', 'name', 'version'],
}).set(
{
domain: serviceInfo.domain,
name: `${serviceInfo.domain}.${serviceInfo.name}`,
version: serviceInfo.version,
},
1,
);
return new MetricsInterceptor(new MetricsService());
}
// metrics가 포함된 url 요청은 수집하지 않는다.
private isAvailableMetricsUrl(url: string): boolean {
const excludePaths = 'metrics';
if (url.includes(excludePaths)) {
return false;
}
return true;
}
// @ts-ignore
intercept(context: ExecutionContext, next: CallHandler): Observable<any> {
const originUrl = context.switchToHttp().getRequest().url.toString();
const method = context.switchToHttp().getRequest().method.toString();
const labels = {
controller: context.getClass().name,
handler: context.getHandler().name,
method: method,
};
try {
// 시간 재기위해 시간 시작!
const requestSuccessTimer = this.requestSuccessHistogram.startTimer(labels);
//실패시간 재기 위해 시간 시작!
const requestFailTimer = this.requestFailHistogram.startTimer(labels);
return next.handle().pipe(
tap(() => {
if (this.isAvailableMetricsUrl(originUrl)) {
// 성공하면 성공시간 기록!
requestSuccessTimer();
// 성공 횟수 증가
this.metricsService.incrementSuccessCounter(labels);
}
}),
catchError((err) => {
if (this.isAvailableMetricsUrl(originUrl)) {
// 실패하면 실패시간 기록
requestFailTimer();
// 실패해서 request 실패 횟수 증가
this.metricsService.incrementFailureCounter(labels);
}
throw err;
}),
);
} catch (error) {}
}
}
Prometheus 설정 파일
Prometheus는 애플리케이션의 /metrics(default 경로) 엔드포인트를 주기적으로 조회(scraping)하여 데이터를 수집합니다. 이를 위해 prometheus.yml 파일을 설정해야 합니다.
global:
scrape_interval: 15s # 기본 스크랩 간격 설정
scrape_configs:
- job_name: "local-biz-server"
metrics_path: "/api/metrics"
static_configs:
- targets: ["host.docker.internal:9000"] // # Prometheus가 수집할 대상 서버 URL
이 설정을 적용하면 Prometheus는 15초마다 host.docker.internal:9000/metrics 엔드포인트에서 메트릭을 수집합니다.
Grafana Dashboard
Prometheus에서 수집한 메트릭 데이터를 시각화하려면 Grafana를 활용할 수 있습니다
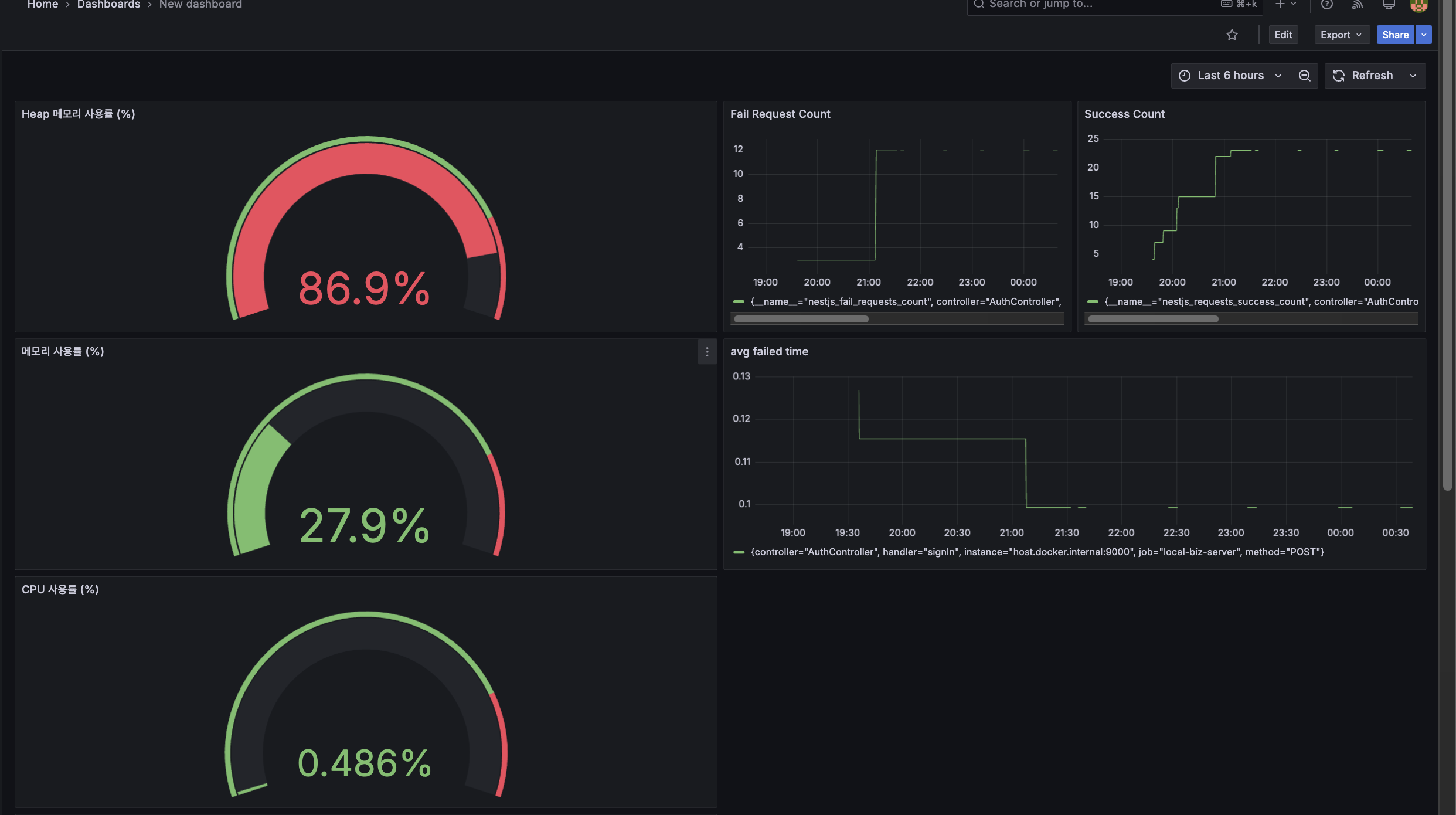
Prometheus + Grafana를 활용한 모니터링 효과
Prometheus와 Grafana를 연동하면 애플리케이션의 성능을 직관적으로 모니터링할 수 있습니다. 요청 수, 응답 속도, 에러율 등 다양한 지표를 대시보드에서 실시간으로 확인하고, 이상 징후가 발생했을 때 빠르게 대응할 수 있습니다.
또한, 알람 시스템을 설정하면 특정 임계값을 초과할 경우 Slack 또는 이메일로 알림을 받을 수 있어 장애 대응 능력을 향상시킬 수 있습니다.
이러한 방식으로 Prometheus를 활용하여 NestJS 애플리케이션의 성능을 효과적으로 모니터링할 수 있습니다. 앞으로는 추가적인 메트릭을 도입하고, 보다 정교한 모니터링 체계를 구축하여 시스템 안정성을 더욱 향상시킬 계획입니다.
Prometheus, Loki 차이점 정리
수집하는 데이터의 종류
-
Prometheus: 시계열(Time-Series) 데이터를 수집합니다. 주로 성능 지표(메트릭)로, 예를 들어 요청 수, 응답 시간, CPU 사용량, 메모리 사용량 등을 포함합니다.
-
Loki: 로그 데이터를 수집합니다. 주로 애플리케이션에서 발생하는 로그 메시지(예: 에러, 디버깅 정보, 이벤트 등)를 다룹니다.
수집 방식
-
Prometheus:
Pulling방식을 사용합니다. Prometheus 서버가 일정 주기로 애플리케이션의 /metrics 엔드포인트를 통해 메트릭 데이터를 직접 가져옵니다. 이 방식은 Prometheus가 대상 애플리케이션을 "polling"하여 데이터를 수집하는 방식입니다. -
Loki:
Tailing방식을 사용합니다. 로그 파일의 끝을 지속적으로 추적(tail)하며, 새로운 로그 항목이 생성될 때마다 이를 실시간으로 수집하여 Loki 서버로 전송합니다. 이 과정은 Push 방식을 기반으로 하며, 로그를 수집하는 데는 promtail과 같은 에이전트를 사용합니다.
저장 방식
-
Prometheus: 메트릭 데이터를 시계열 데이터베이스에 저장합니다. 시간과 메트릭 값이 쌍으로 저장되며, 주로 PromQL 쿼리 언어를 통해 데이터를 분석하고 시각화합니다.
-
Loki: 로그 데이터를 로그 라인 형식으로 저장하며, 인덱싱을 최소화하여 대량의 로그 데이터를 효율적으로 처리합니다. LogQL을 사용해 로그 데이터를 검색하고 필터링할 수 있습니다.
사용 사례
-
Prometheus: 서버 및 애플리케이션의 성능 모니터링에 적합합니다. 예를 들어, 응답 시간, 요청 수, 시스템 자원 사용량 등 실시간 모니터링과 경고 알림을 제공하는 데 사용됩니다.
-
Loki: 애플리케이션 로그 분석과 디버깅에 적합합니다. 에러 로그, 경고 메시지, 트랜잭션 로그 등을 실시간으로 수집하고 분석하는 데 사용됩니다.
백엔드 로그 전송 아키텍처 개선: Loki 직접 전송 방식 vs. 사이드카 방식
Loki와 Grafana를 통해 빠르고 손쉽게 로그 모니터링 시스템을 구축했습니다. 초기에는 빠른 구현에 초점을 맞추어 일부 필요한 부분을 간소화하였고, 현재 방식은 단기적으로 잘 작동하고 있습니다. 그러나 로그 수집 및 전송 방식에서 몇 가지 개선이 필요하다는 점을 느끼고 있습니다.
현재 방식에서는 백엔드 서버가 직접 Loki 서버로 로그를 전송하는 구조입니다. 이 경우, 네트워크 오버헤드와 리소스 사용량 증가로 인해 서버 성능에 악영향을 미칠 가능성이 있습니다.
반면, 사이드카 방식은 로그 수집 및 전송을 백엔드 서버와 분리하여 처리합니다. 보통 애플리케이션과 함께 별도의 로그 수집기 컨테이너(예: Promtail, fluentbit)를 배치하여 로그를 수집하고 Loki로 전송하는 방식입니다. 이 방식은 서버의 성능에 부담을 주지 않으며, 장애가 발생해도 로그 수집이 독립적으로 유지되기 때문에 더 안정적이고 확장성 있는 시스템을 구축할 수 있습니다. 백엔드 서버의 리소스를 독립적으로 관리하면서 로그 처리가 이루어지므로, 서버는 주요 업무인 요청 처리에 집중할 수 있습니다.
따라서, 현재 방식은 빠르게 구현할 수 있는 장점이 있지만, 장기적인 확장성과 서버 성능을 고려했을 때 개선이 필요합니다.
Fluent Bit 사이드카를 활용한 로그 아키텍처 개선
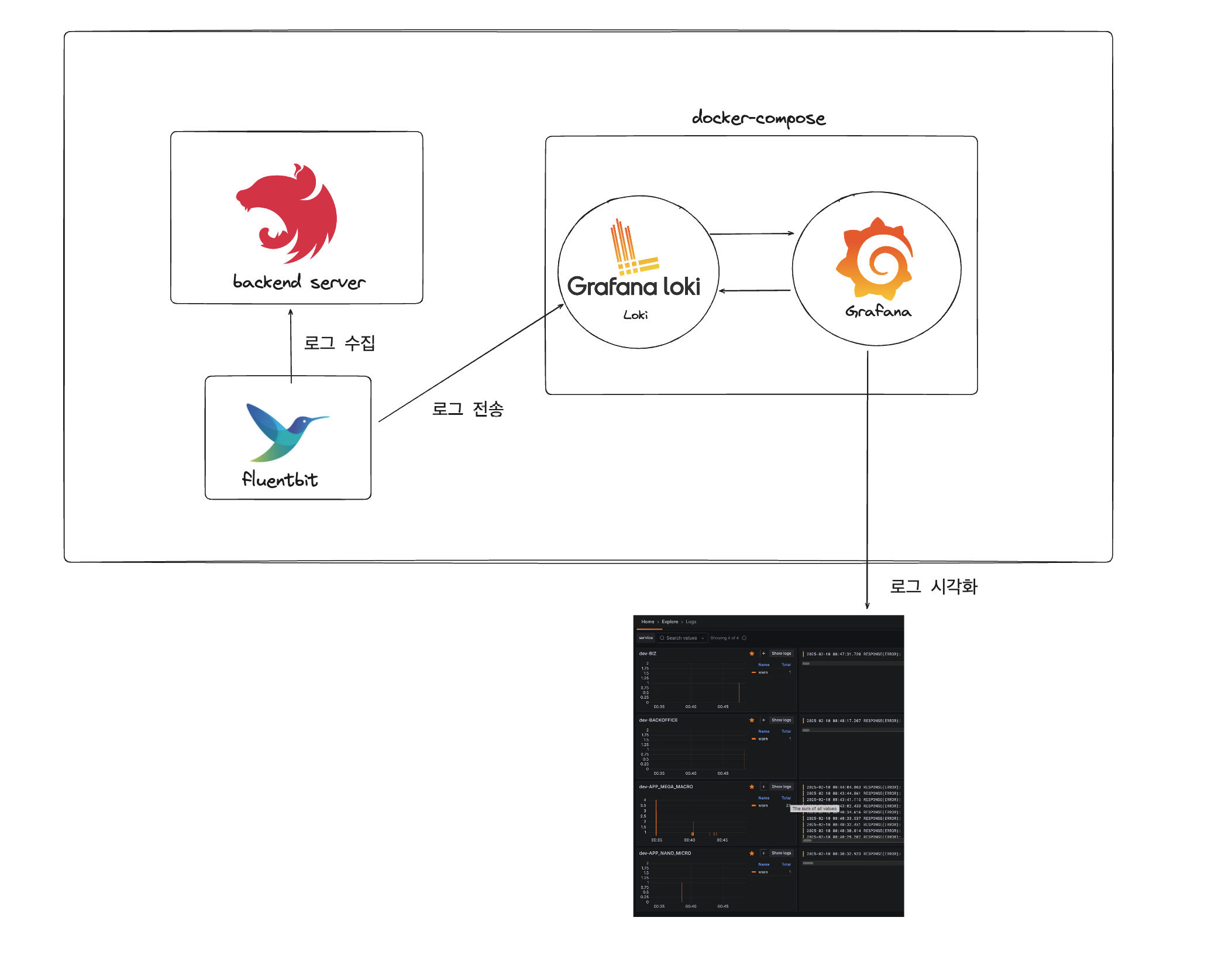
ECS Fargate 환경에서 Fluent Bit를 사이드카 컨테이너로 추가하여 백엔드 서버의 로그를 Loki 서버로 전송하는 방식을 구현할 수 있습니다. 이를 통해 백엔드 서버의 성능 부담을 줄이고, 로그 전송을 더욱 효율적으로 관리할 수 있습니다.
아래는 Fluent Bit 기반의 Loki 로그 전송을 설정한 ECS Task Definition 예제입니다.
{
// ...
"containerDefinitions": [
"logConfiguration": {
"logDriver": "awsfirelens",
"options": {
"Labels": "{app=\"test-server\"}",
"line_format": "key_value",
"Name": "grafana-loki",
"RemoveKeys": "container_id,ecs_task_arn,container_name,ecs_cluster,ecs_task_definition",
"Url": "loki 서버/loki/api/v1/push"
},
"secretOptions": []
},
"systemControls": []
},
{
"name": "log_router",
"image": "grafana/fluent-bit-plugin-loki:2.9.1",
"cpu": 0,
"memoryReservation": 51,
"portMappings": [],
"essential": true,
"environment": [],
"mountPoints": [],
"user": "0",
"logConfiguration": {
"logDriver": "awslogs",
"options": {
"awslogs-group": "/ecs/ecs-aws-firelens-sidecar-container",
"mode": "non-blocking",
"awslogs-create-group": "true",
"max-buffer-size": "25m",
"awslogs-region": "ap-northeast-2",
"awslogs-stream-prefix": "firelens"
},
"secretOptions": []
},
"systemControls": [],
"firelensConfiguration": {
"type": "fluentbit"
}
}
],
// ...
}
참고
https://jminc00.tistory.com/m/91
https://khalti.engineering/implementing-aws-firelens-with-grafana-loki-in-aws-ecs
