들어가며
해당 강의를 보고 정리한 내용입니다.
이번 글에서는 RDBMS와의 비교를 통한 NoSQL 특징, NoSQL 종류, NoSQL 장점을 살펴보겠습니다.
RDBMS의 단점
경직된 스키마
RDBMS의 경직된 스키마는 데이터베이스의 스키마(테이블 구조, 컬럼, 관계 등)를 변경하기가 어렵고 복잡한 문제를 가리킵니다. 이러한 단점은 시간이 지남에 따라 애플리케이션의 요구사항이나 비즈니스 프로세스의 변화에 적응하기 어려움을 초래할 수 있습니다.
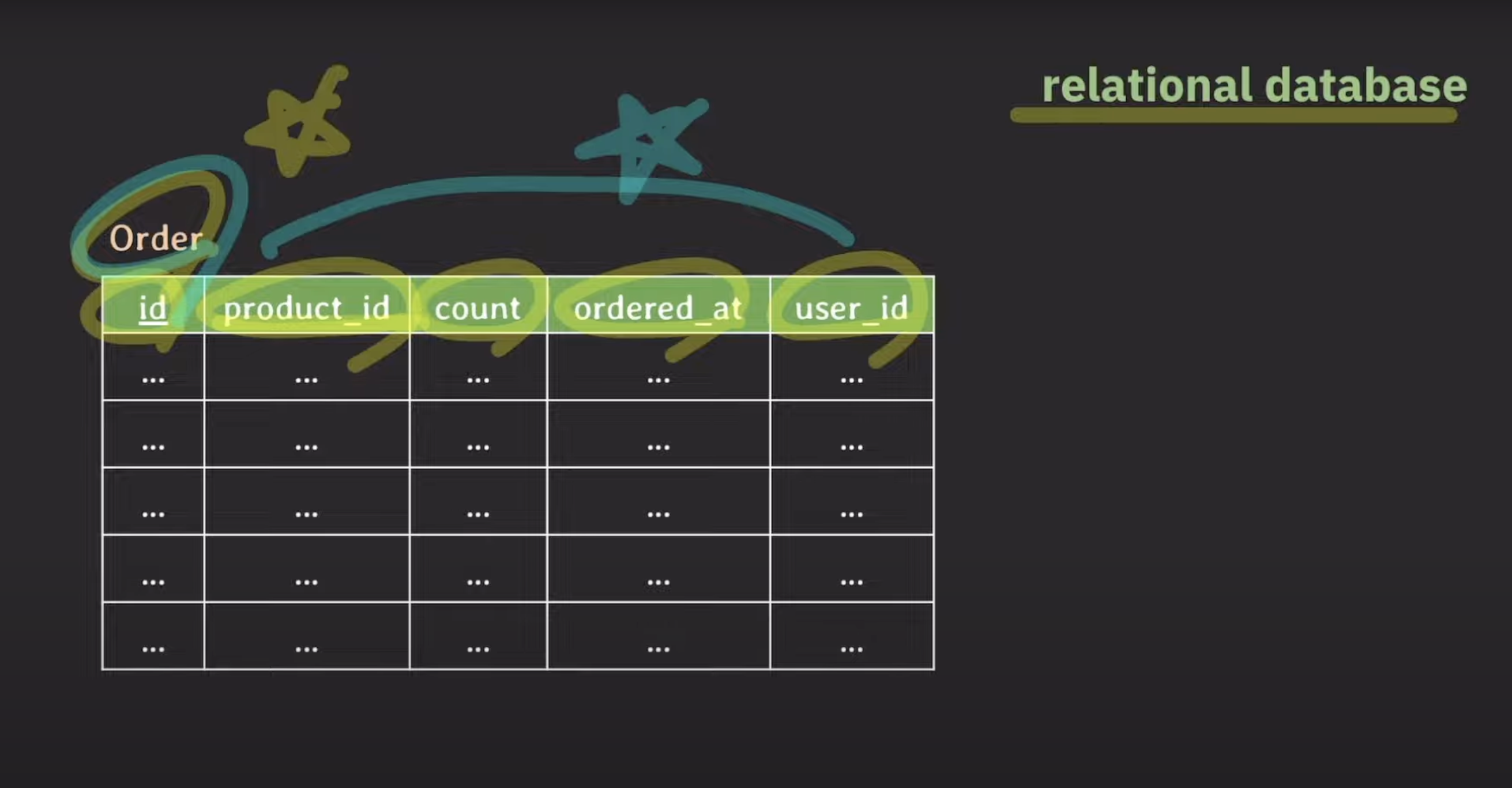
예를 들어, 이미 수많은 데이터가 쌓인 주문 테이블에 새로운 컬럼을 추가해야 하는 상황을 생각해보겠습니다. 주문 테이블에 로켓배송 여부를 나타내는 컬럼을 추가해야 한다고 가정해봅시다.

이런 변경 작업은 다음과 같은 문제를 유발할 수 있습니다.
대량의 데이터 업데이트: 이미 데이터가 많은 테이블에 새로운 컬럼을 추가하고 초기화하는 작업은 많은 양의 데이터를 업데이트해야 하므로 대량의 write 작업이 필요합니다. 이로 인해 데이터베이스 서버와 애플리케이션 서버에 부하가 발생할 수 있습니다.
과도한 조인으로 인한 성능 하락
정규화는 데이터 중복을 최소화하기 위해 테이블을 분리하여 설계하는 과정이지만, 이로 인해 여러 테이블을 조인해서 데이터를 가져와야 하는 경우 성능 문제가 발생할 수 있습니다.
scale-out 편하지 않음

관계형 데이터베이스(RDB)는 기본적으로 한 대의 컴퓨터에 데이터를 저장하는 구조를 가지고 있습니다. 이는 작은 규모의 애플리케이션에서는 문제가 되지 않지만, 대규모 트래픽이 발생하거나 데이터베이스에 대량의 read/write 요청이 몰리는 상황에서는 데이터베이스 서버의 CPU 사용량이 늘어나고, 이로 인해 성능 부하가 발생할 수 있습니다.
이러한 경우를 해결하기 위한 여러 방법이 존재합니다.
scale-up
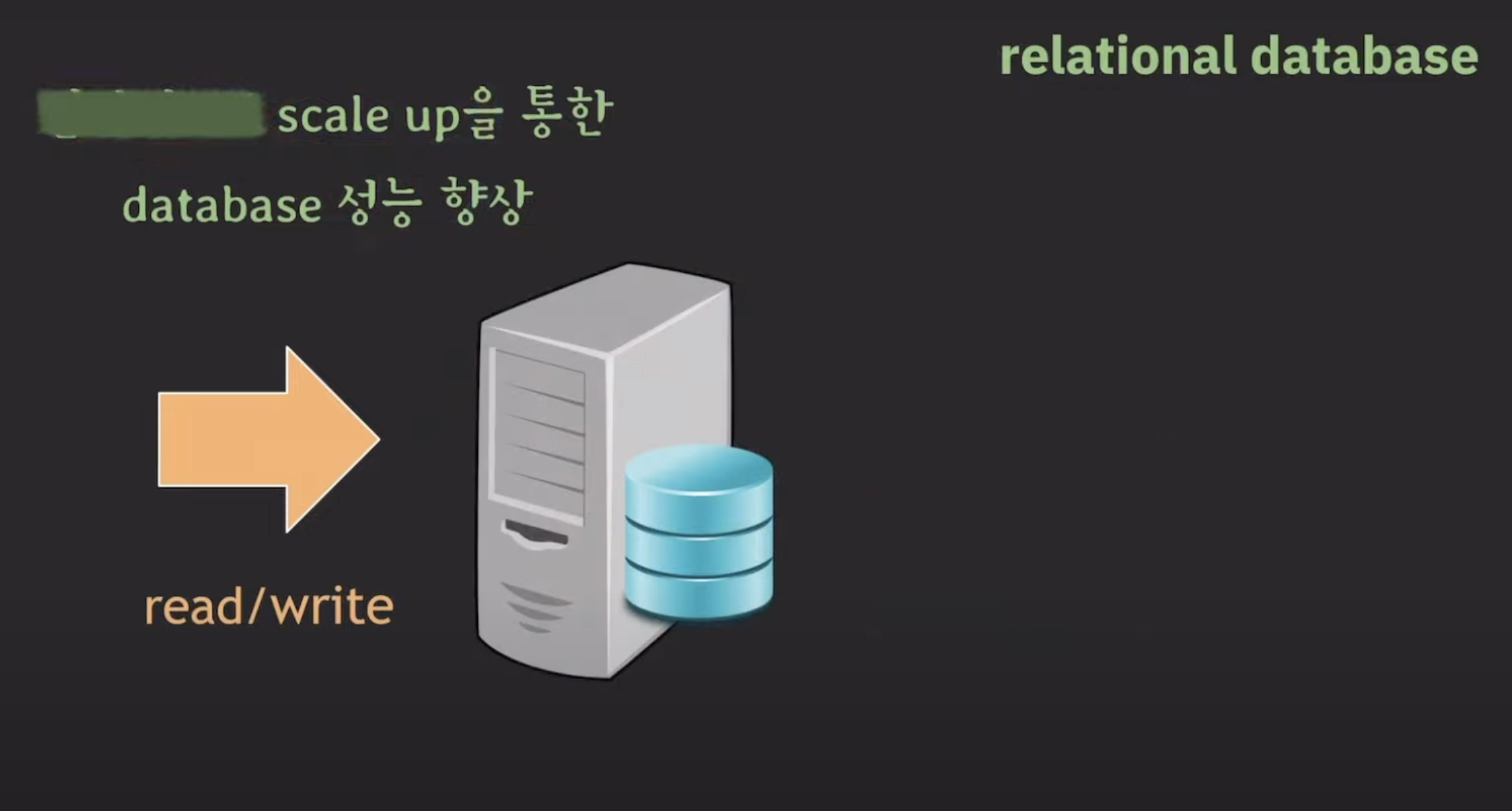
단일 서버의 성능을 향상시키는 방법으로, 더 강력한 CPU, 메모리, 스토리지 등으로 업그레이드하는 것입니다.
이는 성능 문제를 일부 해결할 수 있지만, 확장성 제한이 있고 비용이 높을 수 있습니다.
Replication
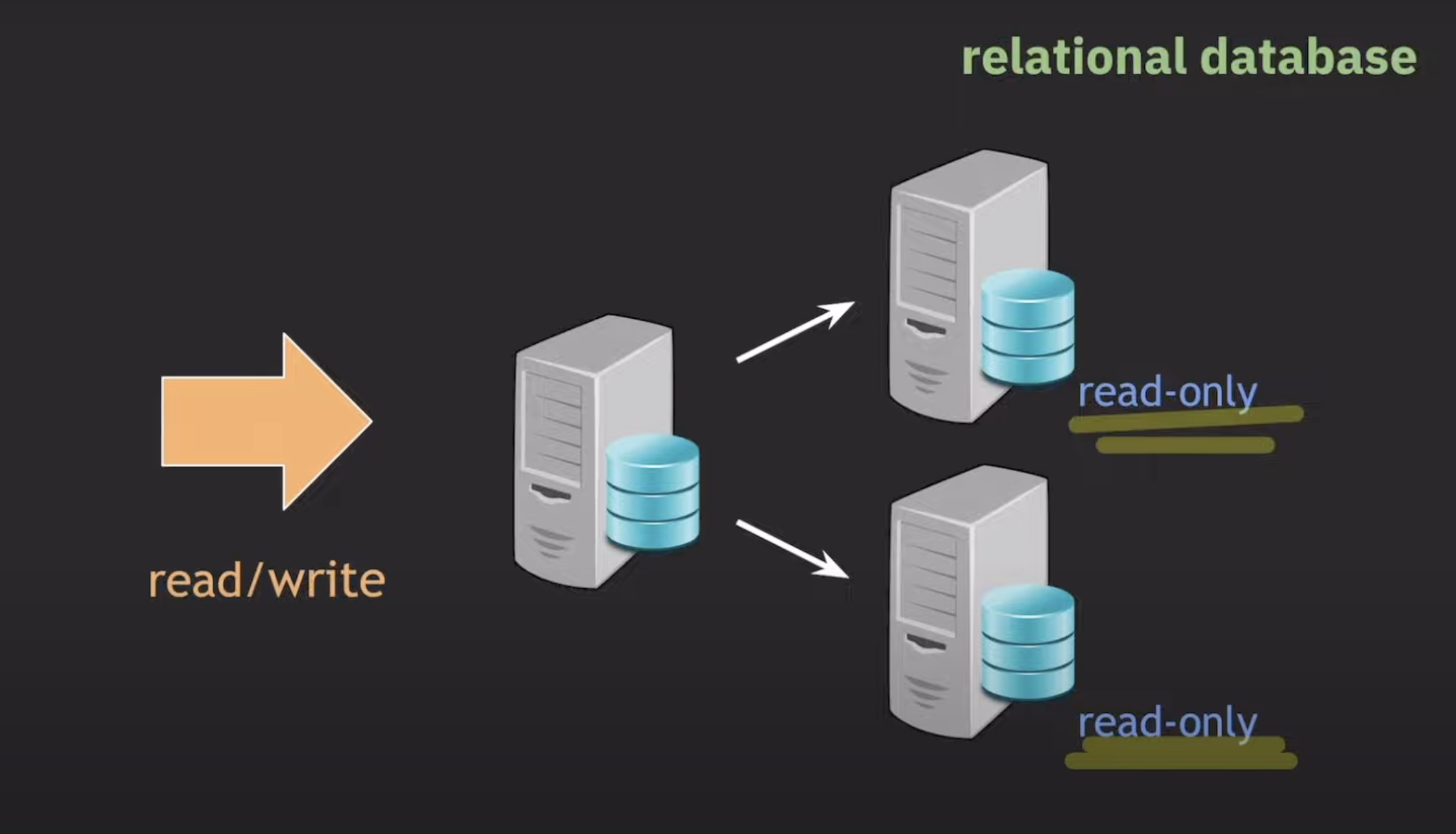
데이터베이스 서버를 여러 개 복제하여 부하 분산을 시도하는 방법입니다. 복제된 서버 중 하나가 주(primary) 서버로 쓰기 / 읽기 요청을 처리하고, 다른 서버들은 읽기 요청만 처리합니다.
Replication의 한계
그러나 Replication은 완벽한 해결책이 아닙니다. 왜냐하면 다음과 같은 제한 사항이 있습니다.
왜냐하면 write 요청이 몰려올 경우, primary 서버를 제외한 secondary 서버는 read-only이기 때문에
결국 write를 담당하는 primary 서버는 cpu 사용량은 늘어날 것이고 부하가 발생할 것입니다.
물론, Multi-master replication, sharding을 통한 방법을 통해 이러한 문제들을 해결할 수 있지만,
일반적으로 RDB는 scale-out에 유연한 db가 아닙니다.
NoSQL (Not only SQL)
시대적 흐름
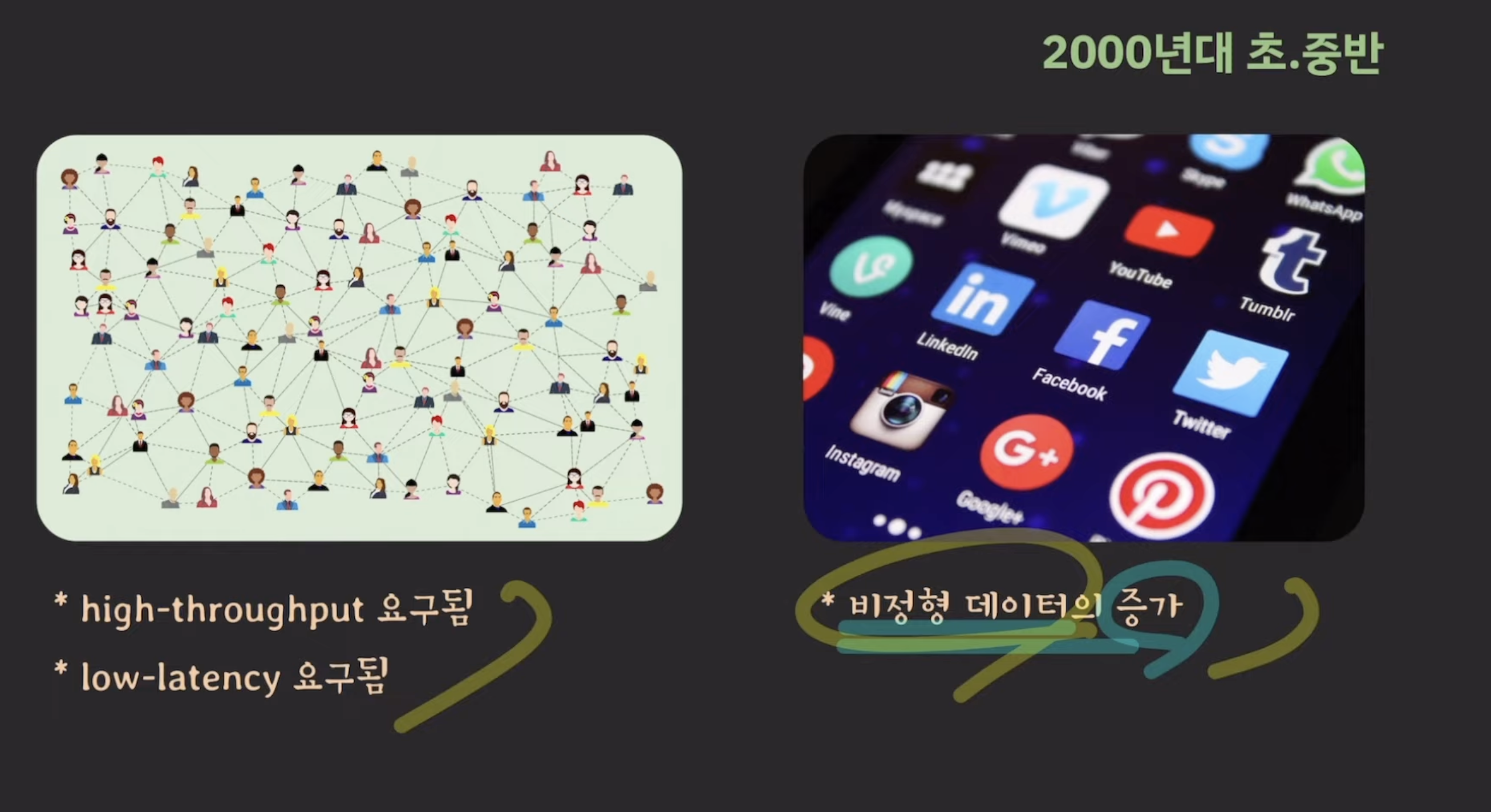
이러한 시대적 흐름속에서 NoSQL이 점점 많이 쓰이게 되었습니다
NoSQL의 일반적인 특징에 대해 살펴보겠습니다.
유연한 스키마 (ex.MongoDB)
- flexible schema

RDB 같은 경우에는 스키마 관리를 RDBMS에서 해줬는데, mongoDB 같은 경우에는 application 레벨에서 스키마 관리가 필요합니다.
중복 허용 (ex.MongoDB)
NoSQL 데이터베이스는 관계형 데이터베이스와는 다른 특징을 가지며, 중복 허용은 그 중 하나입니다. 이 특징은 NoSQL 데이터베이스가 데이터 모델을 유연하게 다루고, 조회 성능을 향상시키는 데 도움이 됩니다. 중복 허용의 예시로 MongoDB를 살펴보겠습니다.
MongoDB에서는 문서(document) 내에 다른 문서를 중첩(embed)할 수 있습니다. 이를 통해 관련 데이터를 하나의 문서에 포함시키는 방식으로 중복 데이터를 저장할 수 있습니다.
관계형 데이터베이스에서는 복잡한 쿼리를 작성하기 위해 조인 연산을 사용해야 했습니다. 그러나 MongoDB에서는 중복된 데이터를 포함한 문서를 한 번의 조회로 가져올 수 있으므로, 조회 쿼리 성능을 향상시킬 수 있습니다. 특히 읽기 쿼리가 빈번한 경우, 중복 데이터를 통해 응답 시간을 줄일 수 있습니다.
하지만, application 레벨에서 중복되는 데이터들이 모두 최신 데이터를 유지할 수 있도록 관리해야합니다.
scale-out 더 편함
NoSQL
NoSQL 데이터베이스는 일반적으로 데이터를 여러 서버로 분산하여 클러스터를 형성하고, 이를 통해 데이터베이스의 성능을 확장합니다. 이러한 방식에서 Scale-Out이 더 편리한 이유는 다음과 같습니다:
NoSQL은 중복을 허용하는 컨셉이기때문에 DB 서버 간의 데이터 이동이나 조인 연산을 필요로 하지 않습니다. 따라서 클러스터의 각 서버에서 데이터를 읽을 수 있으므로 응답 시간이 줄어듭니다.
이러한 철학이 있다보니 데이터를 나눠서 각각의 서버에 나눠서 저장하고 하나의 클러스터를 구성해도 scale-out이 더 편한 것입니다.
RDBMS
반면에 해당 클러스터가 RDBMS로 구성된 서버라면, RDBMS는 정규화된 데이터 모델을 사용하고, 데이터를 여러 테이블에 나누어 저장하기 때문에 Scale-Out이 상대적으로 어려울 수 있습니다.
여러 테이블 간의 조인 연산이 필요하면 조인 대상이 되는 테이블들이 여러대의 서버로 나누어져 있기 때문에 그만큼 조인 시 DB 서버 간의 네트워크 트래픽이 증가하며, 데이터 일관성과 분산 환경에서의 복잡성도 증가할 수 있습니다.
NoSQL에서는 중복을 허용하는 컨셉 때문에 RDBMS에 비하여 scale-out도 좀 더 용이하게 될 수있습니다.
Redis
Redis는 in-memory key-value 데이터베이스로서, 데이터를 메모리에 저장하므로 빠른 응답 시간을 제공합니다.
다음은 Redis의 주요 특징과 개념입니다:
개념
- in-memory key-value database
- data type: strings, lists, sets, hashes, stored sets, ...
- Hash-based Sharded Cluster: Redis는 데이터를 여러 서버에 분산 저장하는 기능을 제공하며, 해시 기반의 샤딩(sharding) 클러스터를 형성할 수 있습니다. 이를 통해 대용량 데이터의 확장성을 확보할 수 있습니다.
- 고가용성: Redis는 데이터 복제(replication)와 자동 장애 복구(automatic failover)를 지원하여 고가용성을 제공합니다. 이로써 Redis 클러스터가 안정적으로 운영될 수 있습니다.
Redis를 cache로 사용한 예제
Redis는 in-memory 기반의 DB이고 memory의 응답성이 ssd, hdd보다 빠르기 때문에 DB 앞단에 Redis를 두어 cache로 많이 사용합니다.
적은 트래픽
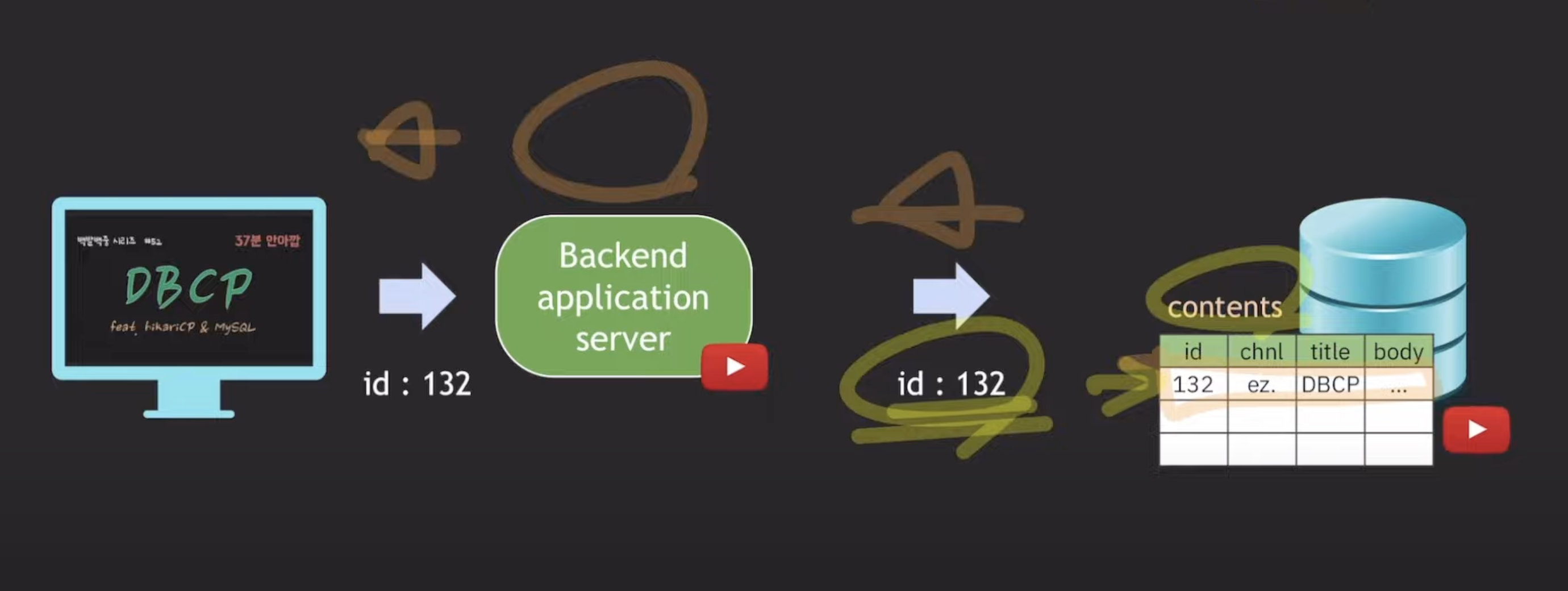
트래픽 증가
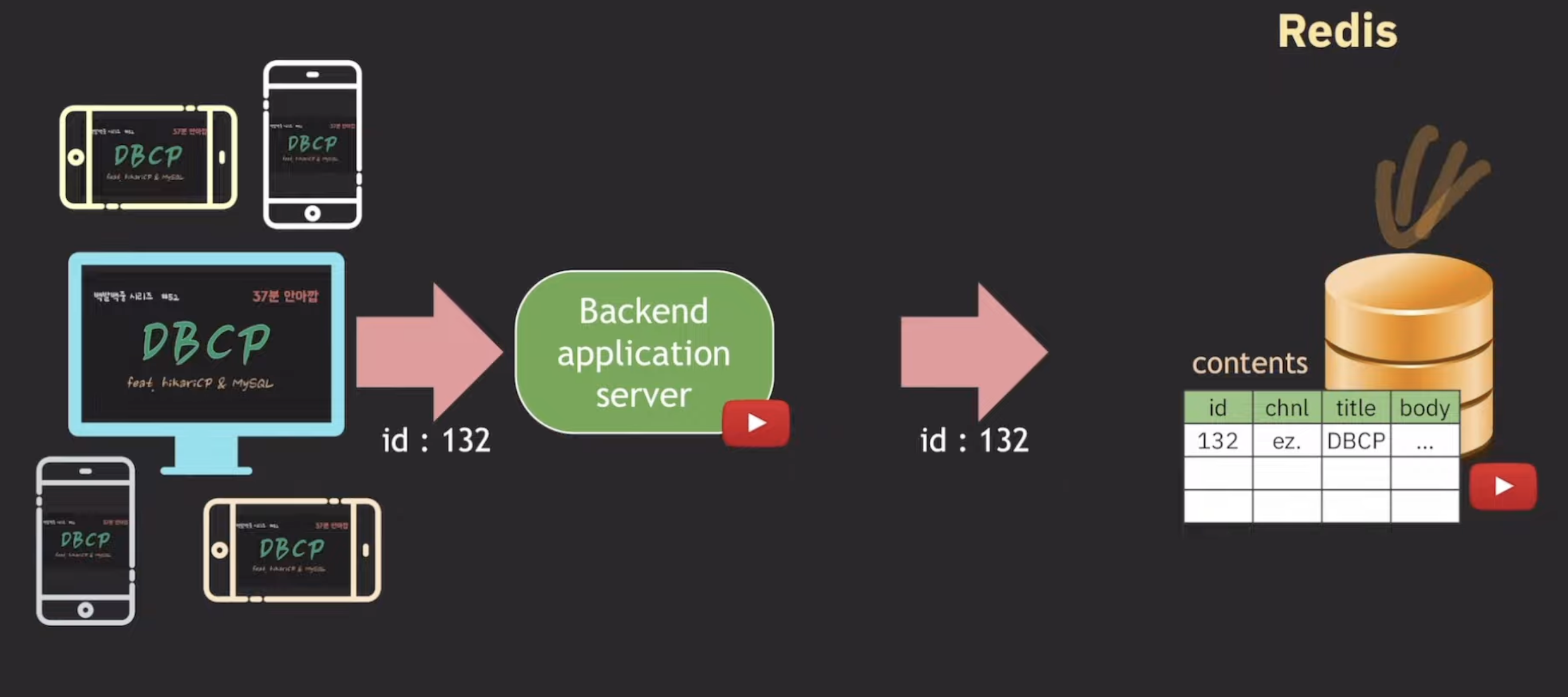
트래픽이 증가하면 DB 서버에 부하가 발생할 것입니다. 이로 인해 DB 서버의 응답 시간이 증가하고, 퍼포먼스가 떨어질 수 있습니다.
Redis를 cache로 사용
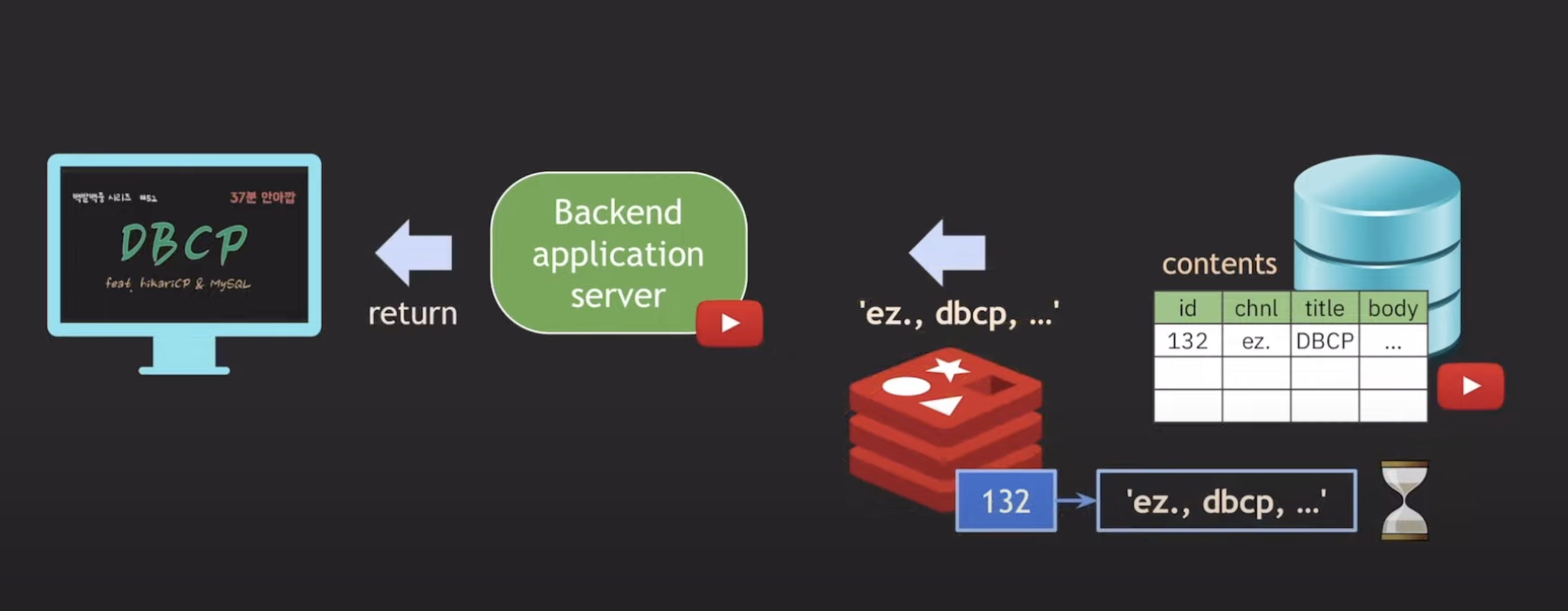
Redis를 Cache로 사용하면 DB 서버 혼자서 모든 트래픽을 처리하지 않아도 됩니다. Redis는 메모리 기반이므로 빠른 응답성을 제공하며, 캐시 역할을 하여 DB 서버의 부하를 줄여줍니다. 따라서 훨씬 더 많은 트래픽을 처리할 수 있으며, 응답 시간이 개선됩니다.
