: 일어날 수 있는 모든 경우의 수를 확인하는 탐색 알고리즘
알고리즘+인접 행렬
[BOJ] 외판원 순회 2
Traveling Salesman problem
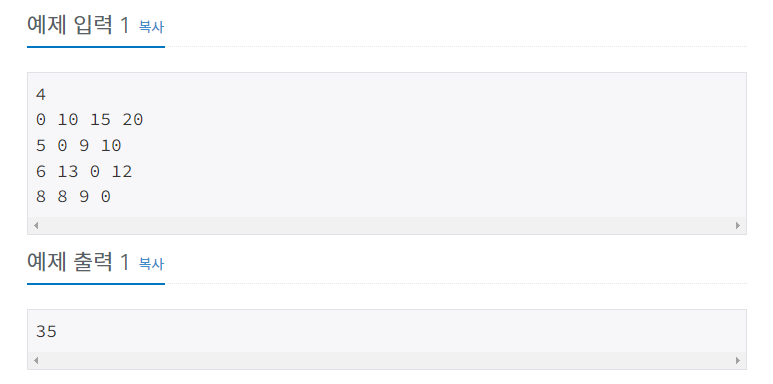
숫자 N과 int[N][N]의 2차원 배열을 받아서
[i][j] → [j][k] … [z][i] 를 N번 더해서 가장 작은 수 출력
DFS 깊이 우선 탐색
import sys
N = int(sys.stdin.readline())
lst = [list(map(int,sys.stdin.readline().split(" "))) for _ in range(N)]
visited = [False] * N #방문한 나라 True
cost = sys.maxsize
# 나라 -> 나라 비용계산
def DFS(start, cur, cnt, val):
global cost
#start -> cur, cnt
if cnt==N and lst[cur][start]: # 방문 수가 n이면서 시작 도시로 가는 길이 있다면
cost = min(cost,val+lst[cur][start]) # 최소비용 저장
return
if val > cost: # 계산 비용이 최소 비용보다 커지면 탈출
return
for i in range(N): #lst[][] 순회
if lst[cur][i] and visited[i] == False: # i에 갈 수 있으며, 방문하지 않았다면
visited[i] = True # 방문 표시
DFS(start, i, cnt+1, val+lst[cur][i]) # recursion
visited[i] = False # recursion 끝나면 방문 표시 지우기
for i in range(N): #lst[] 순회
visited[i] = True
DFS(i,i,1,0)
visited[i] = False
ㅇprint(cost)
{kind=link}
[BOJ] 안전 영역
가장 많은 안전 영역 찾기
안전 영역 : 물에 잠기 않는 연속된 지역들
BFS 너비 우선 탐색
import sys
N = int(sys.stdin.readline())
lst = [list(map(int, sys.stdin.readline().split(" "))) for _ in range(N)]
# 좌표별 상하좌우 확인 리스트 생성
x = [-1, 1, 0, 0]
y = [0, 0, -1, 1]
# 0,0 부터 시작해서 탐색 시작
max_cnt = 0
# 안전 영역 찾기 시~작
for rainfall in range(max(map(max, lst))):
cnt=0
visited = [[False]*N for _ in range(N)] # 방문 확인 배열
for i in range(N):
for j in range(N):
if lst[i][j] > rainfall and visited[i][j] == False: # 해당 좌표를 방문한 적 없고, rainfall 보다 크다면
queue = [] # queue를 만들어서
queue.append([i,j]) # 현 좌표 넣고
visited[i][j] = True # 방문 흔적 남기기
while queue: # queue 에 값이 있는 동안에 반복
a,b = queue.pop(0) # pop(0) : popleft()와 같은 역할
# 상하좌우 탐색 시작
for k in range(4): # 들어간 순서대로 빼내야하기 때문에
x_index = a+x[k]
y_index = b+y[k]
# x, y 가 좌표안에 있으면서, rainfall 보다 크고,
if x_index > -1 and x_index < N and y_index > -1 and y_index < N:
if lst[x_index][y_index] > rainfall and visited[x_index][y_index] == False:
visited[x_index][y_index] = True
queue.append([x_index,y_index])
cnt+=1 # (while 탈출 후) queue가 비면, 영역 하나 count
max_cnt = max(cnt,max_cnt)
print(max_cnt)DFS / BFS
n, m, v = map(int, input().split(" ")) #n 정점의 수, m 간선의 수, v 시작 정점
lst = []
for _ in range(m):
arr = list(map(int, input().split(" ")))
lst.append(arr)
lst.append(arr[::-1]) # 양방향 간선, 받은 내용 반대로 한번 더 저장
lst = sorted(lst, key=lambda x: (x[0], x[1]))↑ 입력 세팅
dfs_lst = []
def dfs(v):
if len(dfs_lst) == n:
return
dfs_lst.append(v)
for edge in lst:
if v == edge[0] and edge[1] not in dfs_lst:
dfs(edge[1])↑ 깊이 우선 탐색 함수
def bfs(v):
visited = [0] * (n+1)
queue = []
visited[v] = 1
queue.append(v)
while queue:
node = queue.pop(0)
print(node,end= " ")
visited[node] = 1
for edge in lst:
if edge[0] == node and visited[edge[1]] == 0:
visited[edge[1]] = 1
queue.append(edge[1])↑ 너비 우선 탐색 함수

hello, world