🌞 인덱스란?
원하는 데이터를 좀 더 빠르게 찾을 수 있도록 해주는 도구이다.
인덱스를 사용 할 때 장점과 단점이 있다.
🌼 장점
-
검색 속도가 무척 빨라질 수 있다. (무조건 빨라지는 건 아님)
-
쿼리의 부하가 줄어들어 시스템 전체의 성능이 향상된다.
🌼 단점
-
인덱스를 넣기위해서는 데이터베이스 크기의 10% 정도의 추가적인 크기가 필요하다.
-
처음 인덱스 생성시 시간이 소요된다.
-
데이터의 변경작업(Insert,Update,Delete)이 자주 일어나는 경우 성능이 나빠질 수 있다.
🌞 인덱스의 종류
🌼 클러스터형 인덱스
-
테이블 당 한개만 지정 가능한 인덱스이다. 예시로 학번이면 학번, 이름이면 이름이 인덱스가 된다.
-
테이블 내의 레코드들을 클러스터형 인덱스 열을 기준으로 정렬한다.
= 물리적으로 데이터를 정렬하였다. (같은 말이다.)
-
클러스터형 인덱스로 지정된 열을 기준으로 오름차순으로 정렬이 된다.
그래서 행이 추가가 되면, 인덱스 기준으로 다시 정렬하기 때문에 조회를 하게되면 입력한 순서가 아닌 클러스터형 인덱스 기준 오름차순으로 조회가 된다.
🌼 보조 인덱스
-
기본 인덱스 이외의 인덱스이다. ( 키의 순서가 레코드의 순서를 의미하지는 않는다. )
-
보조 인덱스는 데이터 블록에서 실제로 조직화된 행들에 전혀 영향을 미치지 않는다. (물리적으로 정렬하지 않는다.)
-
보조 인덱스는 순서를 가지지 않는다.
-
보조 인덱스 엔트리는 물리적으로 정렬된 데이터 블록에 포인터로 대응되어 있다.
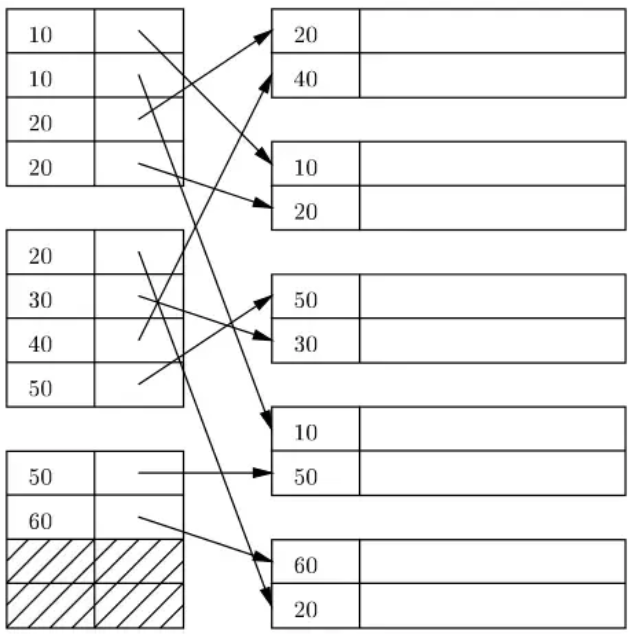
🌼 인덱스의 자동생성
-
Primary Key, Unique+Not Null 두가지의 경우 클러스터형 인덱스를 달아준다.
-
Unique의 경우 보조 인덱스를 달아준다.
-
위가 없는 경우에는 인덱스가 생성되지 않는다.
주의사항 Primary Key와 Unique+Not null 열 두개가 모두 존재하는 테이블의 경우에는 Primary Key가 클러스터형 인덱스가 된다.
🌼 성능의 차이
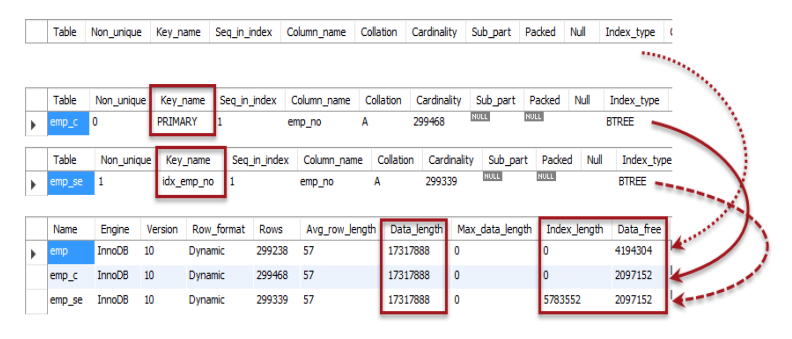
-
emp : 인덱스없음, emp_c : 클러스터형 인덱스 , emp_se : 보조 인덱스
-
위의 사진에서 볼 부분은 emp_c의 index_length가 0이고 emp_se는 index_length가 5783552인 부분이다.

-
위의 명령문은 첫번째 줄은 쿼리 실행전에 읽은 페이지 수를 가져온다. 그리고 두번째에서는 세컨더리 메모리에서 메인메모리로 값을 가져오고 있을 것이고, 이를 다시 세번째 명령문을 통해서 몇줄이나 읽은지를 확인하는 것이다.
-
위의 명령문은 인덱스가 없을 경우였고, 그결과로는 1058페이지를 읽었다.
-
클러스터형 인덱스는 3페이지를 읽었다.
-
보조 인덱스는 5페이지를 읽었다.
-
위의 경우 읽은 페이지가 적은 것이 효과가 더 좋은 것 왜냐하면 적게보고 찾았다는 것이기 때문이다.

위의 명령어를 통해서 중복도가 높은 gender 열에 대하여 인덱스를 추가했다. 그결과 인덱스를 추가하기전에는 3만개의 쿼리비용이 나왔고,
인덱스를 추가하고나서는 2만개의 쿼리비용이 나왔다.
데이터의 중복도가 높은 경우에, 인덱스 사용하는 것이 효율이 미미하다.
INSERT 등의 구문에서는 오히려 성능이 저하될 수 있다는 점 등을 고려하면 인덱스가 반드시 바람직하다고 보기는 어렵다. -> INSERT시 SORT를 하기 때문에
cf) 헝가리안 타입 표현법 : 타입_이름분절1_이름분절2
🌞 결론
-
WHERE절에 있으면서 자주 찾는 데이터라면 인덱스가 있는 것이 효율적이다.
-
데이터가 중복도가 높은 열은 인덱스를 만들어도 효용이 없다.
-
외래 키 지정한 열에는 자동으로 외래 키 인덱스가 생성된다.
-
JOIN에 자주 사용되는 열에는 인덱스를 생성해주는 것이 좋다.
-
INSERT/UPDATE/DELETE가 자주 발생하는 테이블은 인덱스가 없는 것이 좋을 수 도있다. SORT를 하기 때문이다.
