🌻최소잔여시간우선(SRTF)
- Shortest Remaining Time Fist
- SRT라고도 한다.
- SJF의 선점버전으로 시분할 시스템에 유용하다.
- 장점
->항상 실행 시간이 짧은 작업을 신속하게 실행하므로 평균 대기시간이 가장 짧다. - 단점
->초기의 긴 작업은 짧은 작업을 종료할 때까지 대기시키기 때문에 기아가 발생한다.
->기본적으로 짧은 작업이 항상 실행되도록 설정하므로 불공정한 작업을 실행한다.
->실행 시간을 예측하긱 어려워 실용적이지 못하다. - 장기 스케줄러에나 적용 할 수 있다. 단기스케줄러에는 하기 어려운 방법

정답
P1 -> 0초, 9초
P2 -> 0초
P3 -> 15초
P4 -> 2초
대기시간 = 반환시간 - 도착시간 - 버스트타임
(9+15+2)/4 = 26/4
(17-0) + (5-1) + (26-2) + (10-3) = 52 / 4 = 13

정답
4번
🌻우선순위 스케줄링
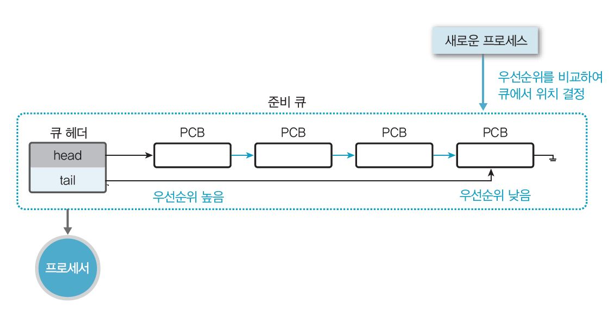
-
우선순위 순으로 실행한다.
-
우선순위가 동일하면 선입선처리를 한다.
내/외부적 우선순위
- 내부적
->다음 CPU버스트 시간, 제한 시간, 기억장소 요청량, 사용 파일 수, 평균 CPU버스트에 대한 평균 입출력 버스트의 비율, 전면/후면 등- 외부적
->프로세스 중요성, 사용료 높은 사용자, 요청 부서, 정책 등
- 선점 또는 비선점이 가능하다.
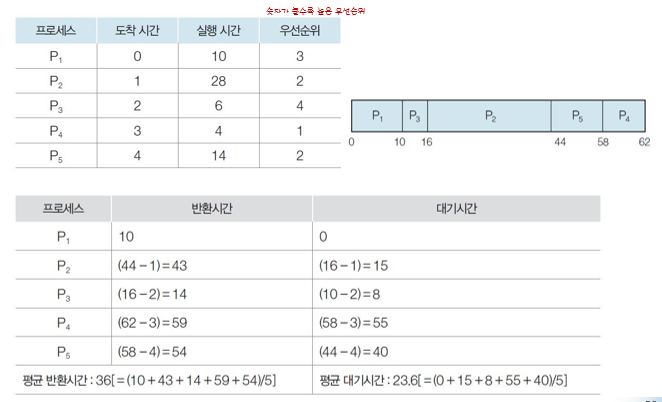
비선점 우선스케줄링의 예
선점과의 차이점->비선저므이 경우는 요청시간이 앞에 있어서 먼저 실행 중이던 프로세스가 있다면 해당 프로세스가 끝나고 반환시간 안에 요청을 보낸 프로세스들 중 우선순위를 비교하고 그리고 우선순위가 같다면 요청을 먼저 한 것을 실행한다.
선점 스케줄링의 예
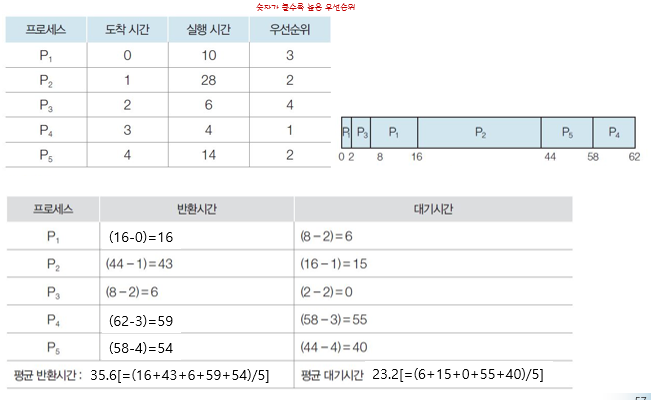
-
선점과 비선점을 비교 했을 때 선점이 꼭 평균반환시간과 평균 대기 시간이 짧아지라는 법은 없다. 단지 우선순위가 높은 프로세스가 먼저 실행된다는 장점이 있을 뿐이다.
-
문제점
->무한 정지와 기아 -
해결책
->에이징(Aging) 기다린 시간에 비례하여 우선순위를 높이는 방법이다. -
장점
->각 프로세스의 상대적 중요성을 정확히 정의할 수 있어서 좋다.
->다양한 반응으로 실시간 시스템에 사용이 가능하다. -
단점
->높은 우선순위 프로세스가 프로세서를 많이 사용하면 우선순위가 낮은 프로세스는 무한정 연기되는 기아가 발생할 수 있다.
🌻라운드로빈스케줄링(round-robin)
준비큐를 돌면서 일정시간씩 실행
- 규정 시간량을 작은 단위로 미리 정의
->Time quantum, time slice
->보통 10ms에서 100ms정도 ( Context Switch Time < 10ms )- 순환 큐
-
시분할 시스템에 적합하다
-
대화식 사용자에게 적당한 응답시간을 제공한다.
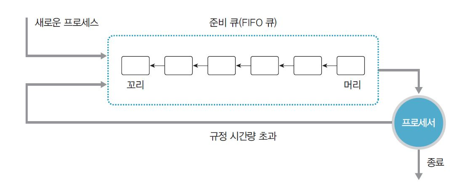
-
FIFO를 선점형태로 변형한 방법이다.
-
일반적으로 SJF보다 평균반환 시간은 길지만 응답시간이 빠르다.
-
시간할당량이 너무 작으면 스래싱에 소요되는 시간의 비중이 커진다.
정답
A B C A C A
4 4 4 4 1 9
( 26 + 8 + 17 ) / 3 = 51/3 = 17
3번
- 문맥 교환 횟수
->규정 시간량이 작을수록 문맥 교환 횟수가 증가한다.
->문맥 교환 소요 시간보다 규정 시간량이 충분히 커야한다.
규정시간량
- 작으면
->짧은 프로세스가 유리하다.
->문맥 교환 오버헤드 커짐 -> 평균 반환시간 증가 요인- 크면
->FIFO와 비슷해짐
-
프로세스들의 80% 정도는 RR에서 정의한 규정시간 내에 CPU버스트가 끝나도록 하는것이 바람직하다.
-
크기가 비슷한 프로세스들로 구성돼 있다면 규정시간량이 커야 평균반환 시간이 감소한다.

정답
A B C B C
2 3 3 1 4
(2+9+13) / 3 = 8
🌻다단계 큐 스케줄링(MLQ)
- MultiLevel Queue
우선순위 별로 준비큐를 분리한다.
- 우선순위가 높은 큐를 모두 처리한 후 낮은 우선순위의 큐를 처리한다.
->각 큐는 자신만의 독자적인 스케줄링 알고리즘을 갖을 수 있음
->큐 사이에 시간을 나눠 사용할 수도 있다
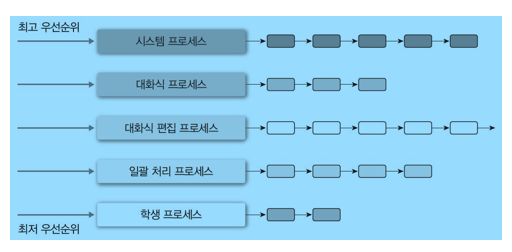
-
장점
->응답이 빠르다. -
단점
->여러 준비 큐와 알고리즘 때문에 추가 오버헤드가 발생한다.
->우선순위가 낮은 큐의 프로세스는 무한정 대기하는 기아가 발생할 수 있다.
🌻다단계 피드백큐(MLFQ)
-
MultiLebel Feedback Queue
-
프로세스들이 준비 큐를 갈아 탈 수 있는 다단계 큐 스케줄링
->예 : CPU 버스트가 크면 낮은 단계로
->aging구현도 가능하다.
->프로세스의 우선순위가 가변적이다.
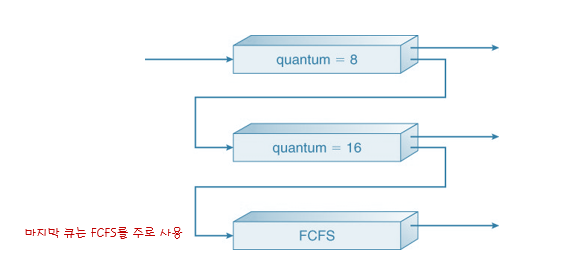
-
다단계 큐에서 나타나는 우선순위가 낮은 프로세스의 기아 현상을 방지하기 위해 만들어졌다.
-
CPU 사용이 끝난 프로세스는 우선순위가 낮은 준비 큐에 삽입된다.
-
우선순위에 따라 타임 슬라이스를 다르게 할 수 있으며 낮은 우선순위 큐 일수록 타임 슬라이스가 크다.
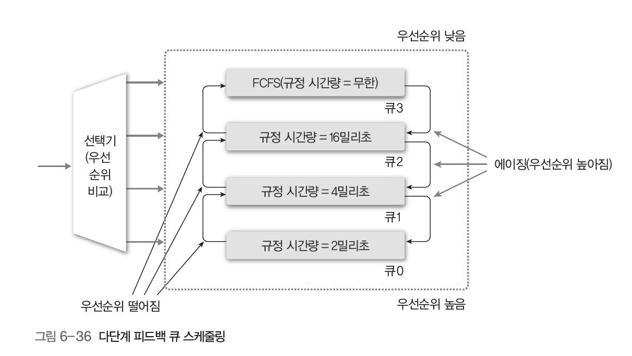
큐0이 우선순위가 가장 높다.
하지만 규정시간량이 적기 때문에 CPU버스트 타임이 작다.
여기서 큐0에서 실행을 못한 프로세스의 경우는 aging을 통해 큐1에 push_back 한다.

정답
4번
큐를 갈아 탈 수 있는가? 없는가?
- MLFQ 스케줄러의 정의 요소
->큐의 수
->각 큐의 스케줄링 알고리즘
->프로세스가 어느 큐에 들어갈 것인지 정하는 방법
->프로세스를 높은 우선순위의 큐로 격상시키는 방법
->프로세스를 낮은 우선순위의 큐로 격하시키는 방법
->큐들간의 스케줄링 방법 : 큐들간의 CPU 할당 비율

정답
커진다.
1번 : 이 스케줄링은 레디큐의 스케줄러이다.
-
장점
->매우 유연하여 스케줄러를 특정 시스템에 맞게 구성할 수 있다.
->자동으로 입출력 중심과 프로세서 중심 프로세스를 분류한다.
->적응성이 좋아 프로세스의 사전 정보가 없어도 최소작업 우선 스케줄링의 효과를 보여준다. -
단점
->설계와 구현이 매우 복잡하다. -
적응기법이란 시스템이 유동적인 상태 변화에 적절히 반응하도록 하는 기법을 의미한다. 스케줄링 기법 중 적응 기법의 개념을 적용하고 있는 것은
->MFQ -
MFQ는 모든 작업이 최상위 큐에서 실행되며 각 큐에 할당시간이 존재한다.
🌻HRN 스케줄링
-
프로세스 응답 비율 순으로 CPU를 할당한다.
->프로세스 응답시간 : 대기한 시간 + 서비스를 받을 시간
->프로세스 응답비율 : (대기한 시간 + 서비스를 받을 시간) / 서비스를 받을 시간 -
비선점
-
우선순위 스케줄링의 일종이다.
->짧으면 우선
->오래되면 우선 -
최소작업 우선 스케줄링의 약점을 보완했다.
->긴 작업과 짧은 작업 간의 지나친 불평등을 해소 -
선입선처리 스케줄링의 약점을 보완했다.
-
선입선처리의 경우는 무조건적으로 대기시간을 기준으로 스케줄링을 결정 했다면,
HRN은 대기시간도 고려하지만 CPU burst 시간 즉 서비스를 받을 시간까지도 고려를 한다.
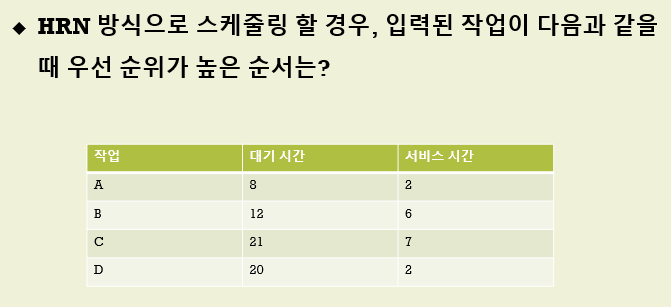
정답
A = (8+2) / 2 = 5
B = (12+6) / 6 = 3
C = (21+7) / 7 = 4
D = (20+2) / 2 = 12
D부터 시작한다. D를 시작하면 대기시간을 수정해주어야 한다.
전부 2를 더해준다.
A = 6
B = 3.3
C = 4.2
A를 해준다. A의 서비스 시간만큼 대기시간+ 2를 더해준다.
B = 3.6
C = 4.4
D->A->C->B 순이다.
-
장점
->자원을 효율적으로 활용한다.
->기아가 발생하지 않는다. -
단점
->오버헤드가 높을 수 있다.(메모리와 프로세서 낭비)

정답
SJF, Priority
RR -> MLFQ -> FCFS

정답
FIFO
A B C
5+6+9/3 = 20/3
0+5+6/3 = 11/3
SJF
B C A
1+4+9/3 = 14/3
0+1+4/3 = 5/3
SRTF
B C A
1+4+9/3 = 14/3
0+1+4/3 = 5/3
Priority
C A B
3+8+9/3 = 20/3
0+3+8/3 = 11/3
RR
A B C A C A C A A
1 2 3 4 5 6 7 8 9
9+2+7/3 = 6
4+1+4/3 = 3
HRN
(대기시간 + 서비스를 받을 시간) / 서비스를 받을 시간
모든 응답비율이 같다.
그러므로
A B C
5+6+9/3 = 20/3
0+5+6/3 = 11/3
🌻운영체제의 스케줄링 알고리즘
-
Solaris
->MLFQ, 선점 priority 스케줄링을 사용한다.
->time quantum이 있으므로 선점이다. -
Linux
->선점 priority-based 알고리즘을 사용한다.
->CFS(RR+Priority) : 준비큐를 레드블랙 트리로 구현 -
Window XP
->MLFQ, Priority-based, RR
🌻다중 프로세서 스케줄링
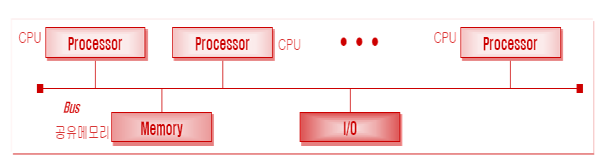
-
장점
->처리기가 많아 증가된 처리량
->프로세서가 주변 장치, 저장 장치 등을 공유하므로, 여러 개의 단일 시스템에 비해 비용이 절약된다.
->하나의 프로세서가 고장이 나도 다른 처리기가 그 일을 대신 할 수 있다. -
단점
->싱글 프로세서 방식에 비해 OS가 처리해야 하는 것이 많고 구현이 복잡하다.
->스케줄링이 복잡하여 오버헤드가 증가한다. -
강결합된 메모리 구조를 가지고 있다.
🌱대칭 다중처리(강결합된 공유 메모리 구조, SMP)
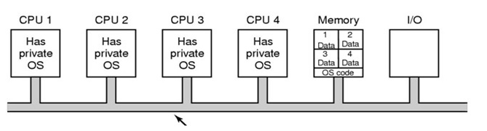
-
각 프로세서는 커널 수행, 프로세스 스케줄링
-
Windows XP, Linux, Solaris, and Max OS X support SMP
-
단점
->자원 충돌의 문제가 발생한다. -
모든 프로세서가 대등하다.
-
각 CPU는 공통의 준비 큐에서 실행 할 프로세스 하나씩 선택 할 수도 있고 각자의 준비큐를 가질 수도 있다. 공통의 준비큐가 더 많이 쓰인다.
-
공통의 준비 큐를 가질 경우 CPU 2개가 같은 프로세스를 선택하지 않아야 하고, 프로세스가 누락되지 않아야 한다.
🌱비대칭 다중처리(강결합된 공유 메모리 구조, AMP)
-
메인 프로세서만 시스템을 제어하고, 나머지들은 할당된 사용자 프로세스만 수행한다.
->메인 프로세서 : 커널 수행, 프로세스 스케줄링
->사용자 프로세스가 입출력 등의 서비스가 필요하면 메인 프로세서에게 요청한다. -
장점
->자원 충돌 문제를 쉽게 해결한다. -> 메인 프로세서가 메인 메모리와 입출력 자원들을 제어하기 때문이다. -
단점
->메인 프로세서가 성능의 병목 지점이다.
->메인 프로세서의 오류로 시스템 전체가 정지가 가능하다.
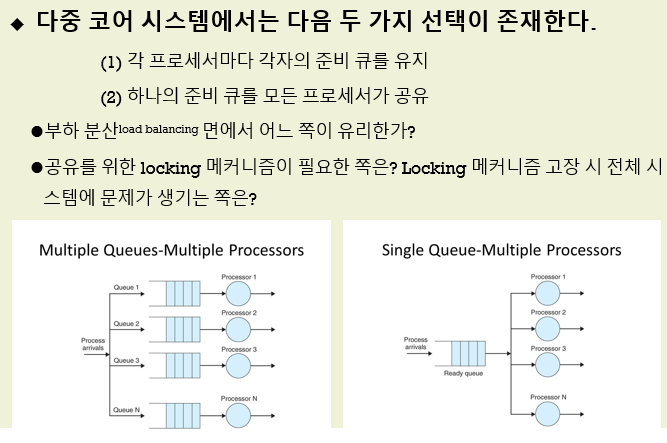
정답
2번
2번
🌻다중프로세서 스레드 스케줄링
- 스레드 스케줄링
->커널의 역할로서 스레드들의 실행 순서를 결정하는 방법이다.
스레드
- 한 프로세스는 동일한 주소공간에서 동시에 실행할 수 있는 스레드들로 구성된다.
->입출력을 동시에 할 수 있음
->프로세서 사용을 동시에 할 수 있음- 스레드 문맥 교환은 프로세스 문맥 교환에 비해서 작다
- 단일 프로세서 환경에서는 프로그램 구조화나 IO/계산의 중첩에 도움을 준다.
- 다중 프로세서 환경에서는 한 프로세스 내의 스레드들을 동시 실행하여 큰 성능 향상이 가능하다.
->스레드 간에 상호작용이 많으면 효과가 적다.
- 부하 공유 (load sharing)
- 갱 스케줄링
- 전용 프로세서 할당
- 동적 스케줄링
🌱부하공유
-
전역 큐에 스레드를 유지한다.
-
유휴 프로세서는 전역 큐에서 스레드를 선택한다.
-
장점
->부하 균등 분산
->프로세서 사용률이 높다.
->중앙 스케줄러가 불필요하다. -
단점
->전역 큐의 병목 현상 : 상호배제 메모리 영역
->선점된 스레드는 같은 프로세서에서 재실행되기 어렵다 : 캐시 사용이 비효율적이다.
->관련된 스레드들이 동시에 프로세서들을 할당 받지 못한다. : 한 프로세스 내의 관련된 스레드들이 빈번한 프로세스 문맥 교환을 유발한다.
🌱갱스케줄링
-
관련된 스레드 집합을 일대일로 동시에 프로세서 집합에 할당한다.
->한 프로세스 안에 스레드들을 동시 수행하는 것이 가능하다.
->한 프로세스 안에 스레드들이 동시에 수행돼야 성능이 나는 경우에 유용하다.
->Time-sharing이나 preemption은 허용되나 스레드 집합 단위로 허용한다. -
장점
->관련된 스레드를 동시 수행한다.
->동기화를 위한 대기가 적다
->프로세스 문맥 교환이 적다.
->스케줄링 오버헤드가 적다. : 한 번의 스케줄링 결정이 다수의 프로세서를 할당한다.
🌱전용 프로세서 할당
-
프로세스 시작부터 완료까지 각 스레드를 전용 프로세서에 할당한다.
->스레드가 IO나 동기화를 위해 대기하면 해당 프로세서는 유휴 상태이다.
->프로세서는 다중 프로그래밍을 안한다. -
장점
->문맥 교환이 없어 프로세스 속도가 향상한다 : 수십 또는 수백 개의 프로세서를 가진 병렬 시스템에서 프로세서 사용률이 주요 성능 지표는 아니다. -
단점
->프로세서 사용률이 낮다. : 프로세스 내의 활성화된 스레드들만 동시 실행하는 방안이 필요하다.
🌱동적 스케줄링
-
OS가 프로세스에게 프로세서들을 적당히 할당한다.
-
프로세스의 스레드 수가 실행 도중 변하면 프로세서 수를 변경해서 할당한다.
-
OS가 시스템 이용률을 높일 수 있도록 부하 조절을 허용한 방법이다.
-
스레드 라이브러리와 결합 될 수도 있다.

정답
갱 스케줄링
전용 프로세서 할당
cf) 갱 스케줄링이나 전용 프로세서 할당은 스케줄링이라기 보다 프로세서 할당에 더 가깝다. 주 관심사가 어떤 프로세스를 선택할 것이냐가 아니다. 오히려 프로세스에 얼마나 많은 프로세서를 할당할 것이냐 이다.
🌞스케줄링 알고리즘의 평가
🌻평가척도
- CPU 사용률
->전체 시스템 시간 중, CPU가 작업을 처리하는 시간의 비율 - 처리량
->CPU가 단위 시간당 처리하는 프로세스이 개수 - 반환시간
->프로세스가 도착해서 끝날 때까지의 시간 - 대기시간
->프로세스가 준비 큐에서 대기하는 시간의 총합 - 응답시간
->요청 후 첫 응답이 오기까지의 시간
cf) 프로세스 실행시간은 포함이 안된다!
🌱평가척도가 다양한데, 스케줄링 알고리즘을 실제로 어떻게 선택하는가?
-
시스템의 요구사항을 기반으로 선택한다.
-
평가 척도들의 상대적인 중요성을 정의해야 한다.

정답
CPU사용률과, 응답시간에서 응답시간을 줄이려면 문맥 교환을 자주해야 한다. 그러면 문맥교환 오버헤드로 인해 CPU 사용률이 낮아진다.
평균 반환시간, 최대 대기시간
평균 반환 시간은 SJF일 때 최소화된다.
그러면 긴 작업들은 기아상태에 빠지고 그들의 대기 시간도 늘어난다.
CPU버스트가 긴 프로세스를 문맥 교환 없이 수행하면 CPU 사용률이 높겠지만 입출력 장치 이용률이 낮다.
IO버스트가 긴 프로세스를 준비되는 대로 수행하면 입출력장치 이용률이 높겠지만 CPU사용률이 낮아진다.
왜냐하면 문맥교환 오버헤드가 생기기 때문이다.
🌻스케줄링 알고리즘의 평가방법
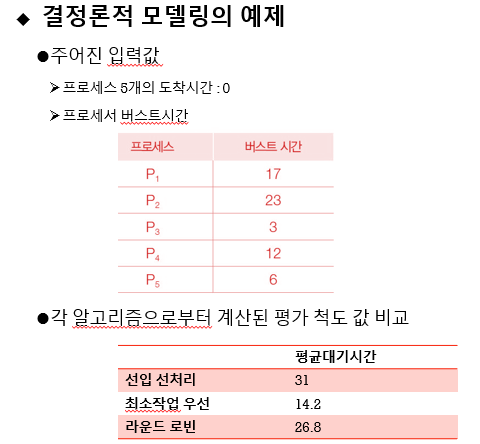
🌱결정론적 모델링
- 미리 정의된 특정한 작업 부하에 대해서 각 알고리즘의 성능을 평가한다.
- 주어진 입력값으로부터 각 알고리즘에 대해 평가 척도 값을 계산한다.
->입력값 : 프로세스들의 도착시간, CPU버스트시간, IO버스트시간등의 시스템 작업부하
->평가 척도 값 : CPU 사용률, 처리량, 반환시간, 대기시간, 응답시간 - 장점 : 단순하고 빠름
- 단점 : 평가 결과가 주어진 입력 값에만 의존한다.
- 일종의 분석적 평가방법이다.
->주어진 입력 값에 대하여 알고리즘의 성능을 평가하는 공식 또는 숫자를 생성한다.
🌱큐잉 모델
- 입력 값들을 활률적인 분포로 가정하고 이들 분포로부터 평가 척도 값을 수학적으로 계산한다.
- 큐잉 이론을 사용한다.
- 단점 : 확률적인 부포가 실제와 다를 수 있다.
🌱모의 실험
- 각 알고리즘의 동작을 컴퓨터 프로그램으로 모사하여 평가 척도 값을 측정한다.
- 단점 : 많은 시간을 요구한다.
🌱구현
- 실제 운영 환경에서 실제 알고리즘을 실행하여 평가 척도 값을 측정한다.
- 단점 : 높은 비용과 위험성

정답
결정론적 모델링
구현
큐잉모델
