
HTTP 프로토콜이란?
- HTTP(Hypertext Transfer Protocol)는 인터넷상에서 데이터를 주고 받기 위한 서버/클라이언트 모델을 따르는 프로토콜
- 애플리케이션 레벨의 프로토콜로 TCP/IP위에서 작동
서버/클라이언트 모델
- 서비스 제공자(service provider)와 서비스 요청자 (service requester)로 구분되는 네트워크 모델
- 서비스 제공자의 역할 = 서버
- 서비스 요청자의 역할 = 클라이언트
- 서버/클라이언트 모델에서 모든 자원은 서버에 집중
- 클라이언트는 데이터 프리젠테이션(재현)을 위한 최소한의 자원을 가지는게 일반적
TCP/IP 프로토콜
- 인터넷 프로토콜 중 가장 중요한 역할을 하는 TCP와 IP의 합성어로 인터넷 동작의 중심이 되는 통신 규약
- 데이터의 흐름 관리, 데이터의 정확성 확인(TCP 역할), 패킷을 목적지까지 전송하는 역할(IP 역할)을 담당
- IP는 데이터를 한 장소에서 다른 장소로 정확하게 옮겨주는 역할을 함
- TCP는 전체 데이터가 잘 전송될 수 있도록 데이터의 흐름을 조절하고 성공적으로 상대편 컴퓨터에 도착할 수 있도록 보장해주는 역할을 함
웹브라우저의 통신 과정
클라이언트에서 요청(Request)를 보내면 서버는 요청을 처리해서 응답(Response)
URL 분석 및 접속
- 웹 브라우저는 URL을 분석해 서버의 IP 주소와 포트(기본은 80)를 이용해 서버와 TCP/IP 연결을 요청
Request 헤더 전송
- 브라우저에서 요청 파일명 등이 기술된 헤더를 전송
Request 바디 전송
- 필요한 경우에, 로그인 폼에 입력한 데이터나 첨부 파일 등의 추가적인 데이터를 전송
Response 헤더 해석
- 서버에서 헤더를 수신하고 응답 상태(404 등)를 확인하며, 바디의 Content-Type 등을 확인
Response 바디 해석
- 바디가 있는 경우, 서버에서 수신한 바디를 헤더에 기술된 Content-Type에 따라서 text/html인 경우에 HTML을 렌더링하고, image/jpeg인 경우에는 그림을 띄우는 등 적절히 해석
Connectless & Stateless
- HTTP는 Connectless 방식으로 작동함
- 서버에 연결하고, 요청해서 응답을 받으면 연결을 끊어버림
- 기본적으로는 자원 하나에 대해서 하나의 연결을 만듬
Connectless(비 연결성)
- HTTP는 실제로 요청을 주고 받을 때만 연결을 유지하고 응답을 주고나면 서버와의 연결을 끊음
Stateless(무상태성)
- HTTP는 특정 상태를 유지하지 않는 특징을 가짐
장점
- 불특정 다수를 대상으로 하는 서비스에 적합한 방식
- 수십만명이 웹 서비스를 사용하더라도 접속유지는 최소한으로 할 수 있기 때문에, 더 많은 유저의 요청을 처리할 수 있음
단점
- 연결을 끊어버리기 때문에, 클라이언트의 이전 상태를 알 수가 없음
- 이러한 HTTP의 특징을 Stateless라고 하는데, Connectless로 부터 파생되는 특징이라고 할 수 있음
- 클라이언트의 이전 상태 정보를 알 수 없게 되면, 웹 서비스를 하는데 당장에 문제가 생김, 클라이언트가 과거에 로그인을 성공하더라도 로그 정보를 유지할 수가 없음 HTTP는 cookie, session, token을 이용해서 이 문제를 해결하고 있음
URI
- 클라이언트 프로그램 (웹 브라우저)은 URI를 이용하여 자원의 위치를 찾음 * * URI는 HTTP와는 독립된 다른 체계
- HTTP는 전송 프로토콜이고, URI는 자원의 위치를 알려주기 위한 프로토콜
- Uniform Resource Identifiers 의 줄임로, World Wide Web 상에서 접근하고자 하는 자원의 위치를 나타내기 위해서 사용
- 자원은 문서, 이미지, 동영상, 프로그램, 이메일 등 모든 것이 될 수 있음
Http Header
- HTTP 헤더는 클라이언트와 서버가 요청 또는 응답으로 부가적인 정보를 전송할 수 있도록 해줌
- 부가적 정보라 함은, 대표적으로 요청자, 컨텐트 타입, 캐싱 등이 있음
Header의 종류
Http Header는 다음과 같이 크게 4가지로 분류됨
General header
- 요청과 응답 모두에 적용되지만 바디에서 최종적으로 전송되는 데이터와는 관련이 없는 헤더
Request header
- 패치될 리소스나 클라이언트 자체에 대한 자세한 정보를 포함하는 헤더 = 내가 보내는 메세지의 헤더
Response header
- 위치 또는 서버 자체에 대한 정보(이름, 버전 등)와 같이 응답에 대한 부가적인 정보를 갖는 헤더 = 내가 받은 메세지의 헤더
Entity header
- 컨텐츠 길이나 MIME 타입과 같이 엔티티 바디에 대한 자세한 정보를 포함하는 헤더
HTTP Request
- 웹 브라우저는 웹 서버에 데이터를 요청하는 클라이언트 프로그램
- 요청은 서버가 인식할 수 있는 약속된 형식 (HTTP 형식)을 따라야 함
- 요청 데이터는 Header와 Body로 구성
필수 요소로 요청의 제일 처음에 와야하는 3개의 필드가 존재
- 요청 메서드 : GET, PUT, POST, PUSH, OPTIONS 등의 요청 방식
- 요청 URI : 요청하는 자원의 위치를 명시
- HTTP 프로토콜 버전 : 웹 브라우저가 사용하는 프로토콜 버전
그 외의 키값
- Host : 요청을 보내는 Host
예) www.google.co.kr - Content-Type : 요청에 바디가 있는 경우 그 파일 포맷
예) Content-Type: application/json - Cookie : 웹 브라우저에 저장된 쿠키들
- User-Agent : 클라이언트의 정보, 이를 통해 사용하는 브라우저 감지
Method
메서드는 요청의 종류를 서버에게 알려주기 위해서 사용함
- GET : 주어진 URL에서 자원을 요청
- POST : 주어진 URL로 자원의 생성을 요청
- PUT : 주어진 URL로 자원의 대체를 요청
- PATCH 주어진 URL로 자원의 수정을 요청
- DELETE : 주어진 URL로 자원의 삭제를 요청
- HEAD : 주어진 URL에서 자원의 헤더만을 요청, 해당 자원이 존재하는지 혹은 서버에 문제가 없는지를 확인하기 위해서 사용
- OPTIONS : 주어진 URL에서 처리 가능한 메소드의 목록을 요청
필수 요소로 요청의 제일 처음에 와야 하는 3개의 필드가 있다.
PUT과 PATCH 의 차이?
- update 방식의 차이
- PUT은 모든 자원을 업데이트 함
- PATCH는 일부 자원을 업데이트 함
- 멱등성의 관점
- PUT은 멱등성을 보장하고, PATCH는 멱등성을 보장하지 않음
메소드의 멱등성: 여러 번 요청해도 같은 결과가 돌아오고, 리소스에 변화를 일으키지 않기 때문에 멱등성이 보장된 메서드라 함
- PUT은 멱등성을 보장하고, PATCH는 멱등성을 보장하지 않음
HTTP Response
- 프로토콜과 응답코드 : 웹 브라우저가 사용하는 프로토콜, 서버의 응답 상태 (1xx~5xx), 응답 메시지를 보여줌
- Set-Cookie : 웹 브라우저에게 쿠키 생성을 요청
예) Set-Cookie: UserID=tester; Max-Age=3600; Version=1 - Content-Type : 응답에 바디가 있는 경우 그 포맷
예) Content-Type: text/html; charset=utf-8
HTTP Status Code
2xx (성공)
- 200 (성공): 서버가 요청을 제대로 처리함
- 201 (생성됨): 요청이 성공했으며, 새로운 리소스가 생성됨
- 202 (허용됨): 요청을 받았으나 아직 처리하진 않음
- 204 (컨텐츠 없음): 요청을 처리했지만, 컨텐츠를 제공하지 않음
- 205 (컨텐츠 재설정): 요청을 처리했지만, 컨텐츠를 표시하지 않음. 그리고 문서를 재 설정할 것을 요구함
- 206 (일부 성공): 요청의 일부만 성공적으로 처리함
4xx (요청 오류)
- 400 (잘못된 요청): 서버가 요청의 구문을 인식하지 못함. 주로 헤더 포멧이 HTTP 규약에 맞지 않을 경우
- 401 (권한 없음): 인증을 필요로 하는 요청, 인증 실패
- 403 (Forbidden, 금지됨): 서버가 요청을 거부, 인가 실패
- 404 (Not Found, 찾을 수 없음): 서버가 요청한 리소스를 찾을 수 없음
- 405 (허용하지 않는 방법): 요청에 지정된 방법을 사용할 수 없음. 예를 들어 POST 방식으로 요청을 받는 서버에 GET 요청을 보내는 경우
5xx (서버 오류)
- 500 (내부 서버 오류): 서버에 오류가 발생하여 요청을 수행할 수 없음
HTTP/1.0
- 한 연결당 하나의 요청을 처리하도록 설계
- 서버에게 요청 시 매번 연결과 해제의 과정을 반복해야 했기에 RTT가 오래걸리는 문제 있음
RTT: 패킷이 목적지에 도달하고 나서 다시 출발지로 돌아오기까지 걸리는 시간 (패킷 왕복 시간)
HTTP/1.1
-
HTTP/1.0을 보완하여 매번 TCP 연결을 하는 것이 아니라 한 번 TCP 초기화를 한 이후에 keep-alive라는 옵션으로 일정 시간동안 연결 상태를 유지함
지속성(Persistent Connection), HTTP keep-alive
-
HTTP는 웹 서버 통신이기 때문에 TCP keep-alive가 아닌 웹 서버의 keep-alive 속성을 따름
-
HTTP는 일반적으로 Connectionless 방식으로 매 요청마다 연결을 새롭게 맺음
-
요청이 빈번하게 발생한다면 매번 연결을 새롭게 맺는 방식은 비효율적이기 때문에 HTTP는 keep-alive 헤더를 제공함
이 헤더를 이용해 keep-alive를 이용할지 말지 선택할 수 있음Connection: Keep-alive // 연결 유지
Connection: close // 연결 종료- HTTP 1.0 에서는 헤더에 keep-alive 옵션을 추가해줘야 동작함
- HTTP 1.1 부터는 keep-alive가 기본 값으로 설정되어 있어 별도 설정 없이 keep-alive 옵션을 이용 가능함
- 다만, 서버측의 웹 서버에 keep-alive 설정이 켜 있는 경우에만 동작함
- 서버측의 웹 서버에 keep-alive 옵션이 켜져있지 않다면, 동작하지 않음
-
-
Pipelining 추가
TCP의 특성상 요청 후 응답을 기다려야하는 문제를 보완
클라이언트는 앞 요청의 응답을 기다리지 않고 순차적으로 요청 전송, 서버는 요청이 들어온 순서대로 응답파이프라이닝(Pipelining)
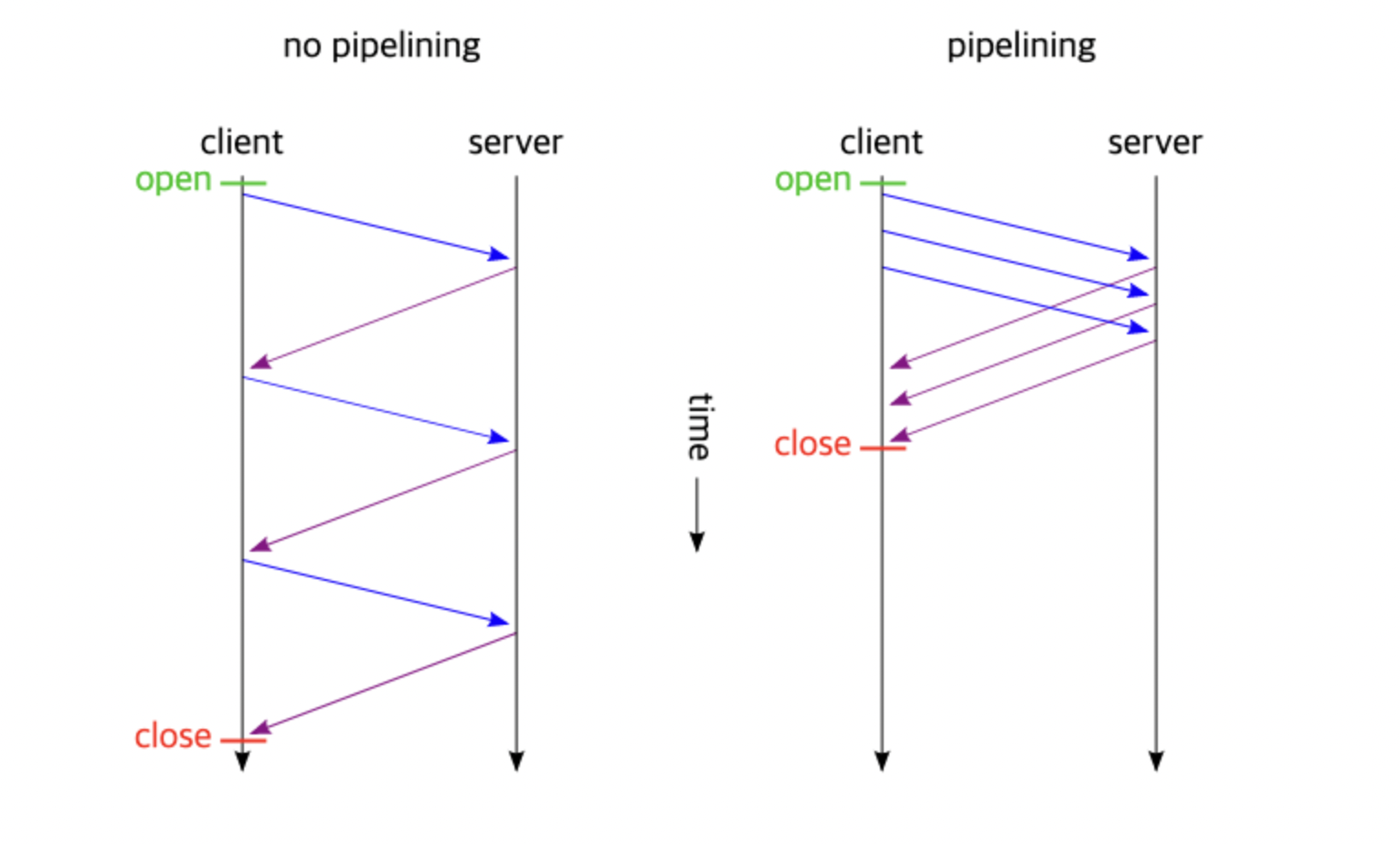
-
HTTP 이란 HTTP1.1 로 스펙이 업그레이드 되면서 클라이언트와 서버간 요청과 응답의 효율성을 개선하기 위해 만들어진 개념
-
HTTP Request 들은 연속적으로 발생하며, 순차적으로 동작
-
HTTP/1.0 에서 HTTP Request 는 소켓에 write 한뒤, 서버의 Response 를 받아 다음 Request 를 보내는 방식으로 웹이 동작함. 여러 요청에 대해 여러 응답을 받고, 각 처리가 대기되는 것은 Network Latency에 있어서 큰 비용을 요구
-
또한, HTTP 요청들은 연결의 맺고 끊음을 반복하기 때문에 서버 리소스 적으로도 비용을 요구
-
HTTP/1.1 에서 요청을 병렬로 처리할 수 있는 파이프라이닝(Pipelining) 기능을 지원
-
파이프라이닝이 적용되면, 하나의 Connection으로 다수의 Request와 Response를 처리할 수 있게끔하여 Network Latency를 줄일 수 있음
-
HOL Blocking (Head Of Line Blocking) 문제
앞의 요청(패킷)에 대한 응답이 늦어지면 뒤의 모든 요청들은 모두 blocking되어 응답이 지연됨
연속된 요청 간에 헤더의 많은 중복이 생긴다는 문제있음
HTTP/2.0
- HTTP/1.x의 시간 지연 문제를 해결
- Multiplexed streams (멀티플렉싱)
- HTTP/1.1의 Pipelining은 한번의 연결에서 여러 요청을 보낼 수는 있었지만 동시에 여러 요청을 처리하진 못했음
- 하나의 커넥션 내에 여러개의 스트림(stream, 양방향 데이터 흐름)을 사용하여 송수신
- 메시지가 이진화된 텍스트인 프레임(frame)으로 나뉘어 요청마다 구분되는 스트림(stream)을 통해 전달
- 프레임(frame)이 각 요청의 스트림(stream)을 통해 전달되며, 하나의 커넥션 안에 여러개의 스트림(stream)을 가질 수 있게되어 다중화(multiplexing)가 가능해짐
- 스트림(stream)을 통해 각 요청의 응답 순서가 의미가 없어져 HTTP/1.x의 HOL Blocking 문제 해결
- Header Compression (헤더 압축)
- 요청과 응답 헤더의 메타데이터를 압축해서 기존의 연속된 요청에서의 중복 헤더로 인한 오버헤드 문제를 해결
- 이전에 표시된 헤더를 제외한 필드를 허프만 코딩을 활용해서 압축
- Server Push (서버 푸시)
- 클라이언트가 서버에 요청하지 않아도 클라이언트에게 필요한 리소스를 서버가 추가적으로 push해주는 기능
- 각 요청마다 stream으로 구분해 병렬적으로 처리함에도 불구하고 TCP 고유의 HOL Blocking이 여전히 존재하는 문제
- 서로 다른 stream이 전송되고 있을 때, 하나의 Stream에서 유실이 발생되거나 문제가 생기면 결국 다른 Stream도 문제가 해결될 때 까지 지연되는 현상이 발생
HTTP/3.0
- TCP 위에서 돌아가는 HTTP/2.0와는 달리 QUIC라는 계층 위에서 돌아가며 TCP기반이 아닌 UDP 기반
- HTTP/2.0의 장점(멀티플렉싱 등)의 기능을 가지고 있음
- 초기 연결 설정 시 지연 시간 감소라는 대표적 특징 (UTP기반)
- 초기 연결(통신 시작)시 3-way handshaking 과정을 거치지 않아 1-RTT만 소요
- 클라이언트와 서버가 한번 신호를 주고받은 후 바로 통신 시작
- TCP의 stream은 하나의 chain으로 연결되는 것과 달리 각 stream당 독립된 stream chain을 구성하여 TCP의 HOL Blocking을 해결
HTTPS?
- SSL은 전자상거래에서의 데이터 보안을 위해서 개발한 통신 레이어
- SSL은 표현계층의 프로토콜로 응용 계층 아래에 있기 때문에, 어떤 응용 계층의 데이터라도 암호화해서 보낼 수 있음
- HTTP는 기본적으로 평문 데이터 전송을 원칙으로 하기 때문에 개인의 프라이버시가 오가는 서비스들 (전자상거래, 전자메일, 사내문서)에 사용하기 힘듬
- HTTPS는 SSL 레이어위에 HTTP를 통과 시키는 방식. 즉, 평문의 HTTP 문서는 SSL 레이어를 통과하면서 암호화 돼서 목적지에 도착하고, 목적지에서는 SSL 레이어를 통과하면서 복호화 돼서 웹 브라우저에 전달됨
- 간혹 HTTPS를 하나의 프로토콜로 인식하기도 하는데, HTTP와 SSL은 전혀 다른 계층의 프로토콜콜의 조합임. HTTPS over SSL로 보는게 좀더 정확한 시각
HTTP와의 차이
- HTTPS URL은 "https://" 로 시작
- 기본 포트번호는 443
- HTTP URL은 "http://" 로 시작, 기본 포트번호는 80
- HTTP는 평문 데이터를 기반으로 하기 때문에, 유저정보와 같은 민감한 정보가 인터넷 상에 그대로 노출됨, 이 정보는 수집되거나 변조될 수 있음
- HTTPS는 이러한 공격을 견딜 수 있도록 설계돼 있음
- HTTPS는 인증서를 이용해서, 접속 사이트를 신뢰할 수 있는지 평가할 수 있음
- 일반적으로 HTTPS는 HTTP에 비해서 (매우 많이)느림
- 많은 양의 데이터를 처리할 경우 성능의 차이를 체감할 수 있음
- 많은 웹 사이트들이 민감한 정보를 다루는 페이지 (로그인 혹은 유저정보) 페이지를 HTTPS로 전송하고, 기타 페이지는 HTTP로 전송하는 방법을 사용
참조
HTTP 프로토콜
HTTP 헤더
HTTP keep-alive
HTTP 파이프라이닝
HTTP 버전 차이 및 특징
