기존에는 많은 데이터를 처리하기 위해 배열을 사용했었다. 하지만 배열은 크기가 고정되어 있고 삽입/삭제하는데 시간이 오래 걸린다는 불편한 점들이 많았고, 이를 보완하기 위해 자바에서 동적 배열 개념인 컬렉션 프레임워크를 제공한다. 컬렉션 프레임워크는 크기가 자유롭게 늘어나며 어떠한 자료형이라도 담을 수 있다는 특징이 있어, 자료의 삽입/삭제/검색 등이 용이해졌다. 종류는 대표적으로 List, Map, Set이 있다.
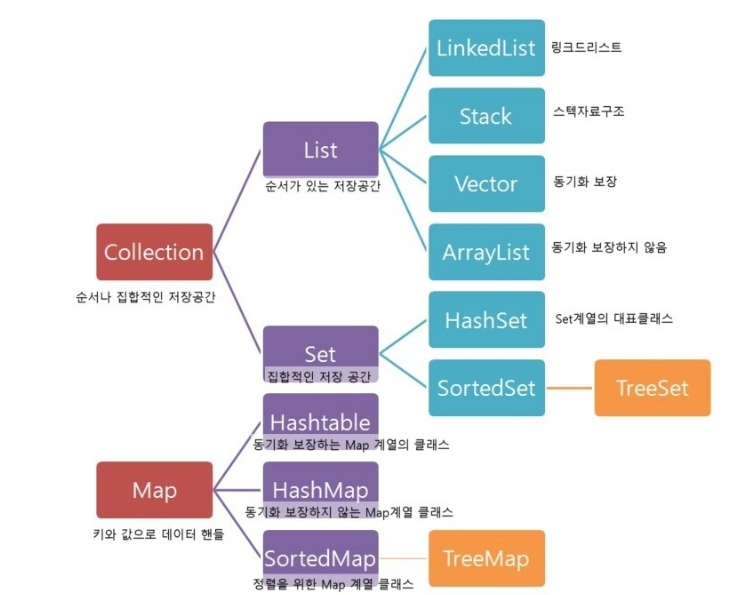
List
설명
순서와 중복이 있는 배열 자료 구조
- 순차적으로 대량의 데이터를 접근하거나 입력할 때 유리한 방식
- 원하는 위치에 데이터를 추가/삭제 가능
- 빈 공간이 생겼을 때는 하나씩 밀리며 자동으로 채워 비어있는 데이터가 없음
- Index를 이용해 모든 데이터에 접근할 수 있음
- 가변적인 배열(자동으로 늘어남)
- 순회를 하기 때문에, 원하는 데이터가 뒤쪽에 있을 경우 속도의 문제가 있을 수 있음
종류
ArrayList
객체 내부에 있는 배열 기반으로 데이터 저장
- 크기를 원하는대로 조절 가능
- 단방향 포인터 구조로, 데이터에 순차적으로 접근
- 검색 속도는 빠르나 데이터 삽입/삭제가 느림
LinkedList
- 양방향 포인터 구조로, 포인터로 각각의 노드들을 연결해 데이터 삽입/삭제 빠름
- 첫 번째부터 순회하기에 ArrayList보다 검색이 느림
- 조회보다 삽입/삭제가 많은 경우에 사용하는 것이 좋음
Map
설명
순서가 없는 Key와 Value의 형태의 집합 자료구조
- 다건의 데이터에서 원하는 특정 데이터에 접근(검색)할 때 유리한 방식
- Key는 중복이 불가하나, Value는 중복을 허용
- List와 Set에 비해 검색 개념 가미
- 뛰어난 검색 속도
- Index가 존재하지 않기에 Iterator 사용
종류
HashMap
- Key와 Value 값으로 NULL을 허용
- 동기화가 보장되지 않음
- 검색에 가장 뛰어난 성능
HashTable
- 동기화가 보장되어 병렬 프로그래밍이 가능
- HashMap 보다 처리 속도 느림
- Key와 Value 값으로 NULL을 허용하지 않음
LinkedHashMap
- Map의 특징과 다르게 입력된 순서를 보장
TreeMap
- 이진 탐색 트리(Red-Black Tree)를 기반으로 Key와 Value 저장
- Key 값을 기준으로 오름차순 정렬되며 빠른 검색이 가능
- 저장 시 정렬을 하기 때문에 시간이 다소 오래 걸림
Set
설명
순서가 없고 중복을 허용하지 않는 집합 자료구조
- 중복되지 않은 데이터를 구할 때 유리한 방식
- Index를 사용하지 않아 Iterator 사용
- 뛰어난 검색 속도
종류
HashSet
- 인스턴스의 해시값을 기준으로 저장하기 때문에 순서를 보장하지 않음
- NULL 값을 허용
- TreeSet보다 삽입/삭제 빠름
LinkedHashSet
- Set의 특징과 다르게 입력된 순서를 보장
TreeSet
- 이진 탐색 트리(Red-Black Tree)를 기반
- 데이터를 오름차순으로 정렬하여 저장
- 데이터 검색/정렬이 빠르나 삽입/삭제에는 시간이 걸림

기록만이 살 길 ... 말하는 감자애오