🗄️ Github Repository
1주차 과제
SpringBoot Basic Weekly Mission
🔖 소감
책임분리
머지 전까지 들들 볶이던 주 원인이었다.
그리고, 참 많이 배운 내용이다.
책임을 분리하라고 해서 매번 최대한 작은 클래스랑 메소드로 나눌 생각을 했다.
그로인해 우후죽순 생겨나는 프로젝트 파일이 뭔가 죄스러웠다.
하지만 그게 당연한거고, 멀리 봤을때 좋은 프로그램을 만드는 것이라니,
놀라워!ㅎ
피드백을 받으면서 얻은 노하우는
- 메소드, 클래스 이름을 먼저 지어놓을 것
- 이름따라 책임분리가 쉬워짐
- 반환값을 나타낼 수 있도록 이름을 지을 것
- 보다 명확한 메소드, 클래스 구조 만들 수 있음
모호하게 적은것 같은데 암튼 신경쓰면서 해보면 무슨 소린지 알게됨.
테스트코드
이게 진짜 불속성 효자.
테스트코드가 진짜 자식이었으면 나는 애진작에 고려장 당했겠다 싶을 정도로
아주 고통스럽게 한 녀석이다.
결론부터 말하자면, 1 클래스 당 1 테스트 클래스가 필요하다.
다시 말해서 그냥 모든 것에 대해서 테스트를 하라는 것.
입출력은 오히려 테스트가 필요하다고 생각하는 경우에만 하라고 하더라 ㅇㅇ
@ParameterTest, @SpringJUnitConfig, @SpringBootTest 암튼 테스트에 쓰는 어노테이션이나 방식이 다양한데,
1주차 과제가 끝난 지금시점에서는
- 테스트 코드 컨벤션 정립
- 각 어노테이션 역할 이해
- 맞왜틀 양호해진 편
이 상태가 됐다.
나름 선방해서 만족한다.
특히 @SpringJUnitConfig를 쓰고, 테스트 설정 클래스를 따로 만들었는데도 안 되었다.
6주차가 지난 지금 시점에서는 이것저것 삽질을 많이 해본 덕분에 해법을 찾은것 같다.
2주차 과제에 한 번 적용해봐야지 ㅇㅇ
프로젝트 문서
계산기 과제에서 느꼈다.
UML은 귀찮지만 내 삶을 윤택하게 해준다고.
욕심내지 말고 흐름도, 다이어그램 중 하나.
이렇게 두 개만 프로젝트 별로 만들기로 했다.
저번에는 exelidraw 를 썼다.
근데, 구조 변경마다 새로 그림을 그려줘야 하는게 여간 소모적이라
타이핑으로 UML을 작성할 수 있는 mermaid라는 플러그인을 찾아서 써봤다.
가독성은 직접 그린것만 못하지만, 적당히 가지치기를 하면서 욕심을 지우면 그래도 봐줄만 하다.
하지만, 변경에 유리하다는 점이 나에게는 엄청난 이득이므로 앞으로도 계속 사용할 것 같다.
그리고 readme 파일도 멘토님이 차분히 읽어주실거라 생각했는데,
그렇지는 않아서 앞으로는 간략하게 핵심만 전달해서 읽을만 하도록 만들어 보낼 생각이다.
Domain, DTO, VO, 원시값 포장
이런게 있는줄도 몰랐다.
이래놓고 무슨 개발자가 된다고 생각을 했는지 모르겠다.
특히 백엔드 단에서는 위 개념이 상당히 중요해지는게
input 에서 오는 데이터 형식과 처리하는 데이터 형식이 다를 가능성이 높기 때문인 것 같다.
그 영향을 최소화하고, 프로그램 안정성을 높이는 방법으로 저런걸 사용한다.
각 역할과 특징에 대해서 어느정도 이해하고 나니, 프로젝트에 반영할 수 있게 됐다.
쓰기 전과 쓴 이후 구현과정이 조금 쉬워진 느낌을 받았다.
역시 옛 성현들의 말씀은 틀린게 하나 없었다.
모르면 배워 써야 한다.
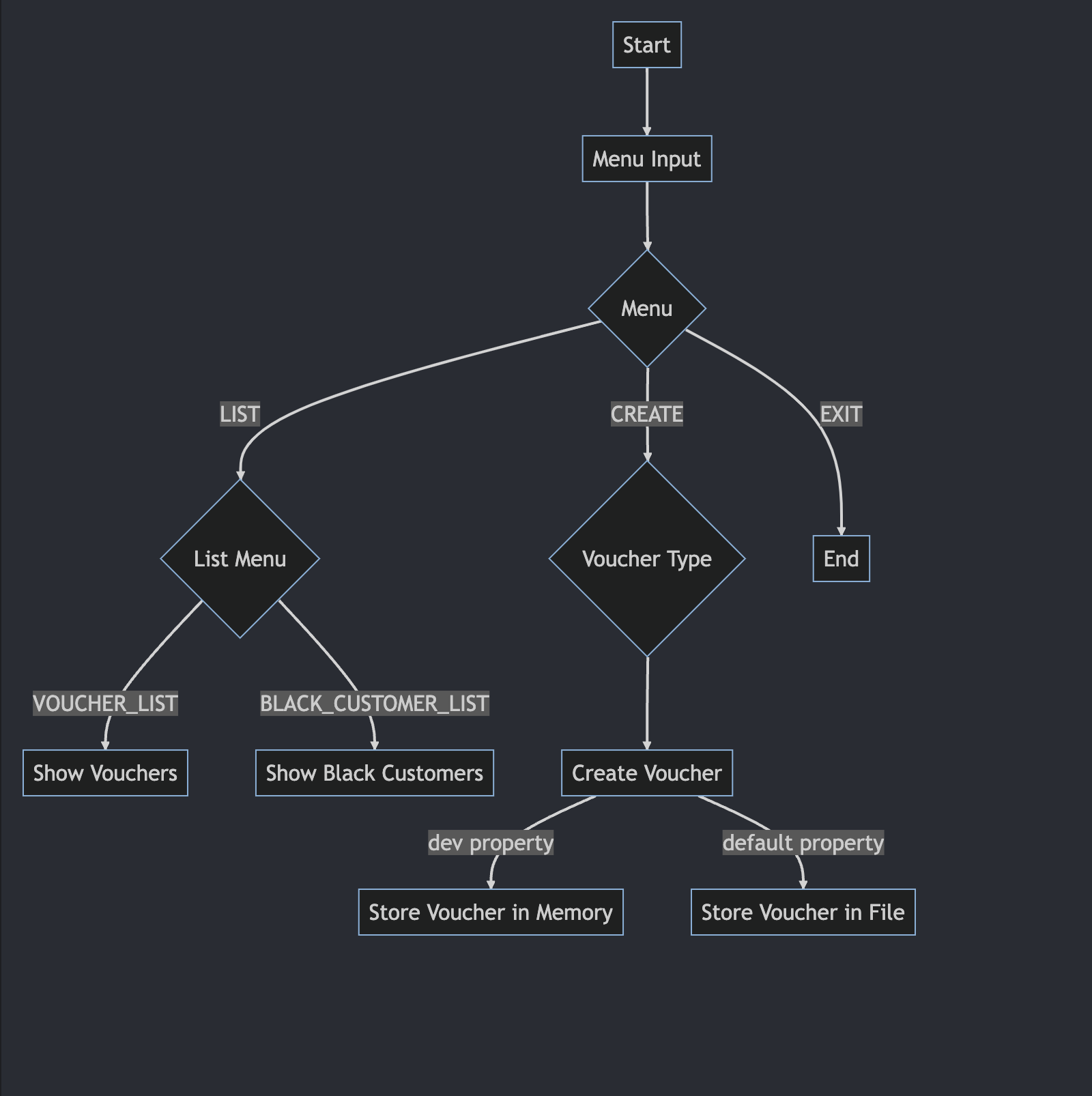
📌 과제 설명
흐름도
flowchart.mermaid
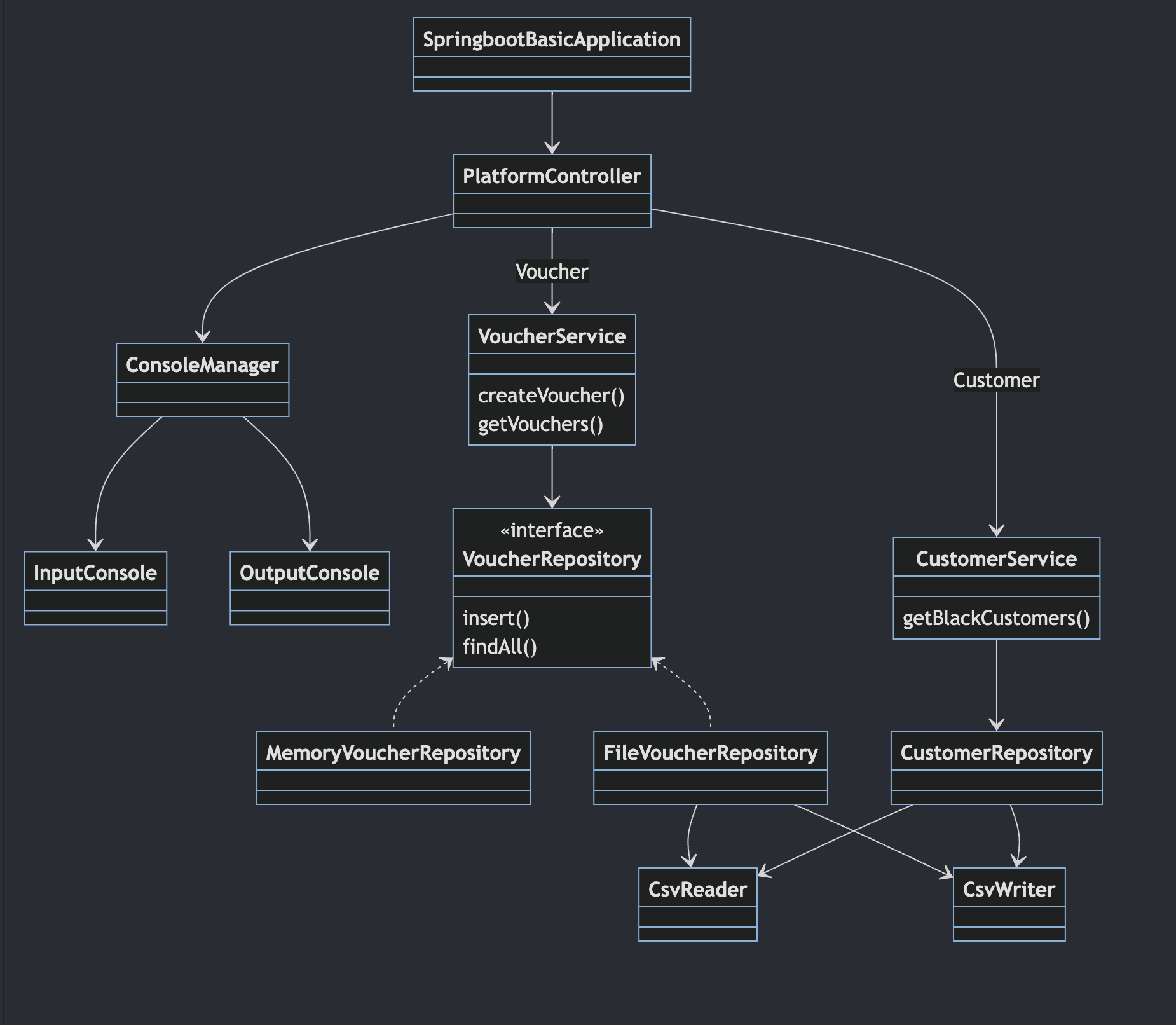
클래스 다이어그램
application.mermaid
✅ PR 포인트 & 궁금한 점
- 테스트 코드
- @ValueSource, @CsvSource, @MethodSource 처럼 테스트 소스를 받아오는 구문이 given-when-then 구조 중 given에 해당하는지 궁금합니다.
- @SpringBootTest 로 모든 빈을 등록해서 테스트하는데도 yaml 프로퍼티에 접근하지 못하는 경우가 있습니다.
- @Value 는 IoC에서 처리하지는 않는 건지 궁금합니다.
- 어플리케이션 실행에는 IoC 통해 프로퍼티를 얻는것 같은데, 테스트에서만 동작하지 않는게 이해되지 않습니다.
- Domain
- 컨트롤러, 서비스, 레포지토리 각 레벨별로 주고받는 데이터 타입이 통일되는게 좋은건가요?
- 파일에서 읽은 String을 도메인으로 변환하고, 컨트롤러에서 다시 String으로 변환해서 출력하도록 수정했는데, 불필요한 연산이 반복되는 것 같습니다.
- 변환을 하는 비용보다 레벨 별로 통일된 데이터 전달이 더 이득이라 이렇게 구현하는게 맞는건지 궁금합니다.
- 로직은 도메인에 있고, VO와 DTO에는 없는게 좋다고 합니다.
- 유효성 검사를 VO, DTO에 구현했는데 올바른 방식인지 궁금합니다.
- 바우처 할인 검사는 로직이라고 생각해 도메인에서 구현했습니다.
- 컨트롤러, 서비스, 레포지토리 각 레벨별로 주고받는 데이터 타입이 통일되는게 좋은건가요?
- 책임 분리
- 기존 구조의 책임이 복잡하다고 생각해 변경했습니다.
- 변경 후의 결합도는 어떤지 확인부탁드립니다.
👩💻 요구 사항과 구현 내용
- IO
- 입출력 (TextIO 라이브러리)
- 파일 입출력 (CSV 파일)
- 생성
- 고정값 바우처 생성
- 비율값 바우처 생성
- 메모리 저장 (dev 프로파일)
- 파일 저장 (default 프로파일)
- 조회
- 바우처 조회
- 블랙고객 조회
- 종료
- YAML 프로퍼티
- 로그 (level = {
error,debug}) - jar 파일 추출
✅ 피드백 반영사항
- 테스트 코드 작성
- 클래스 간 책임 분리
- 불필요한 책임 전가 제거
- DTO, VO 적용
Git Commit Convention
- feat : 기능
- fix : 버그 수정
- docs : 문서 작업
- style: 포맷팅, ;추가
- refactor : 리팩토링 (기능 변경 X)
- test : 테스트 코드 추가
- chore : 유지 (빌드 작업, 패키지 메니저 작업)
1차 피드백
- @Autowired 사용 ✅
- ‘필드 삽입은 권장되지 않는다’의 이유
- bean 객체들을 주입할 때 현재는 권장되지 않는다.
- 생성자 주입을 하는 필드의 후보를 선별하기 위해서 스프링 컨테이너가 필드의 상태를 체크한다. 이것에 대해 알아보자
- 찾아본 거
- 생성자 주입 방식의 더 큰 이점
◦ 초기화 시 필요한 모든 의존 관계 형성 → 안전성 확보
◦ 잘못된 패턴 찾기 가능 → 안전성 확보
◦ 테스트 쉬워짐 → 등록되지 않은 Bean에 의한 비정상 종료 방지
◦ 불변성 확보 → 멀티스레드 환경에서 thread-safety 보장 - 필드 주입 방식의 단점
◦ 의존성 파악이 모호해지는 경향 → 순환참조 가능성 증가
◦ 스프링 IoC 컨테이너에서 빈을 일치시켜 충족할 수 있는 의존성이 가장 많은 생성자가 선택→ 해당 과정에서 불필요한 오버헤드 발생.
- 생성자 주입 방식의 더 큰 이점
- DTO 활용 ✅
- 재료는 늘어나지만 파라미터는 늘어나지 않도록 하는 방법
- DTO 를 사용하면 늘어난 파라미터를 하나로 정리해서 넘겨줄 수 있다.
- 객체지향생활체조 준수 방법 중 하나
- Spring MVC (Controller, Service, Repository 간 데이터 전달 과정에서 layer로써 유용)
- DTO는 주로 Client ↔ Contoller ↔ Service 구간에서 자주 사용함
- Record 클래스 혹은 Enum 클래스로 구현하면 좋다
- data
- user input data(spring request parameter)
- entity → (db 혹은 persist layer)
- response, result
- Service → response, entity
- Controller → requeest, param
- Repository → entity
- 커스텀 예외 클래스 ✅
- throwable cause도 같이 넘겨주면 디버깅할 때 좋다.
- 예외가 다른 예외를 발생시킬 수 있기 때문
Chained Exception - 큰 분류의 예외로 묶어서 다루기 위해서
- 상속관계를 무시하고 사용하고 싶어서
- 부모를 공유하는 두 자식 예외가 부모 예외를 기준으로 catch하게 된다면 정확한 원인을 알 수 없게됨
- cause를 사용하므로써 상속관계를 무시하고 정확한 원인을 알 수 있다.
- checked 예외를 unchecked 예외로 바꿀 수 있어서
- 반드시 예외처리를 해줘야 하는 checked 예외를 상위 예외 클래스로 감싼다면 더이상 예외처리가 강제되지 않음
- checked 예외가 unchecked 예외로 바뀌는 거임
- 예외가 다른 예외를 발생시킬 수 있기 때문
- 정적인 것(메시지)와 분리해줘야 한다.
- 매번 예외 객체가 생성되기 때문
- error message(정적 String 모음)와 exception 클래스의 분리 필요
- throwable cause도 같이 넘겨주면 디버깅할 때 좋다.
- Script 식 코드 줄이기✅
- Platform 클래스 Switch Case 내부 로직
- 해야할 일을 순서대로 나열한 코드는 객체지향적이지 않다.
- 향상된 switch 문 ✅
- 한 case 문에 여러 조건 가능 (쉼표로 구분)
- break 문 필요없음
- : 말고 → 사용
- switch에서 값 리턴 가능
- 값 리턴하는 경우에는 반드시 default 가 있어야 함
- yield 키워드
- 스위치 표현식/문장에서 값을 명시적으로 리턴하기 위한 키워드
- 코드 블록 {} 내에서만 사용 가능
- 코드 블록 내 계산된 값을 반환
- return 키워드와 함께 쓸 수 없음 → level을 다르게 해서 써야함.return
- return : switch 구문 내에서 값을 반환 후 switch 문 종료
- yield: switch 구문 내에서 계산한 결과를 switch 표현식의 결과로 반환
- private 메소드로 뺀 건 좋은 시도✅
- template을 생각해보자. ✅
- command line을 프린트하는 역할과 데이터 처리를 분리해서 생각해 볼 필요가 있다.
- list menu template, createMenuTemplate , command line print이 따로 존재 & 파이프라인이 있다고 생각하고 짜도 좋을 것
- factory는 더 거시적으로 잘 보이도록!✅
- enum이 하는 일과 using Enum이 하는 일을 생각해보자. → 가독성, 유지보수성을 위해서
- Using Enum 구간에서 Factory를 사용하면 더 쉽게 사용접근이 가능할 것
- 제네릭 (profile에 따라서 파일저장과 메모리저장)✅
- standard Interface를 기준으로 구현
- interface가 기준
- 상속받은 클래스는 interface의 형태를 따라가야함
- 이게 standard interface
- 이런 코드는 지양하는게 좋다고 함..
- 왜인지는 모르겠음. 범용적이면 좋은거 아닌가? 타입 안정성이 필요한 것도 아닌데…
- 찾아본거
- 제너릭 한정자
- : T 타입 포함한 하위타입인 제네릭
- : T 타입 포함한 상위타입인 제너릭
- 제너릭 한정자
- standard Interface를 기준으로 구현
- 추상클래스 vs 인터페이스✅
- 추상클래스 : 실체가 명확할때
- 조금이라도 value를 가질 것 같으면 추상클래스
- 인터페이스 : 추상의 끝판왕
- 추상클래스 : 실체가 명확할때
- 주석, 로그는 필요한 곳에만✅
- Ex) menu 입력시 에러 발생하는 경우
- Exception에서 로그 작성하는 것이 아니라 예외 터진 후에 로그 메시지를 받아와서 작성하는 것이 좋다.
- output 과 logger를 분리하려는 목적
- 단위테스트는 테스트 대상과 이름이 공통되는 편이 좋음✅
- 테스트 대상 클래스에 테스트 클래스 만들기 기능으로 테스트 작성해보자.
- 중요로직은 꼭 테스트를 작성
- 출력같은 경우 테스트가 필요한지를 고려
- 책임이 많은 클래스가 아직도 많이 있음
- 템플릿으로 책임 분리
- 끊임없이 고민할 문제인 것 같음
- 메소드 이름만 보고 역할과 반환값 확인이 쉽지 않음
- 일단 단순하게 메소드를 사용하려고 했던 목적과 반환값을 표현할 수 있도록 이름 변경
- 메소드 별로 책임을 완전히 분리시켜서 메소드 이름을 단순화하는 방법이 좋아보임.
- 테스트 목적에 소홀하고 스프링 프레임워크 동작에만 의존해서 처리하려고 하는 것 같다.
- 직접 객체 생성자로 필요한 객체를 생성하는 방법으로 일단 테스트
@TestConfiguration어노테이션 역할에 대해서 알아보자@SpringBootTest,@SpringJUnitConfig어노테이션 차이점 알게됨
시도해본거
- 일급 컬렉션 사용
- MemoryVoucherRepository 안에서 사용하던 HashMap을 일급 컬렉션으로 사용
- VoucherMap 클래스를 만들어 원본 Map 불변성을 유지할 수 있도록 변경
- null 안정성 확보
- Optional 래퍼로 안전하게 값 전달 받도록 변경
- Optilnal.get() 말고 Optional.orElseGet() 을 사용해서 본래 목적 달성
- Optional은 좋아보이는데 왠지 불안한 구석이 있는 녀석인 것 같음
- 최대한 Optional도 안 쓰고, null도 발생하지 않도록 구성하는게 좋을 것 같음
- FileOutputStream 같은 자원 해제를 위해 AutoClose 활용
- try 문에 이런 기능이 있다는 것은 알았지만 실제로 알고 써보니 좋은 것 같음
- 코드량 늘리는 주범인 자원 해제를 생략할 수 있는 게 좋음
- 무엇보다 close 안해줘서 성능 손해보는 일이 없어서 좋음
2차 피드백
- 메소드 이름이 역할, 반환값을 나타내지 못함
- 메소드 별로 최대한 역할을 분리해서 이름 짓기 편하게 수정
- 메소드 이름을 짓기 편한지 아닌지로 책임 분리 수준을 확인할 수 있을 것 같음
@SpringBootTest,@SpringJUnitConfig어노테이션 차이@SpringBootTest- 통합 테스트에 유리
- 어플리케이션 전체에 대한 applicationContext를 가지고 테스트를 수행
- 따라서 어플리케이션 설정파일에 등록된 모든 빈을 이용해서 테스트 가능
@SpringJUnitConfig- 단위 테스트에 유리
@Configuration/@TestConfiguration+@ComponentScan을 이용해서 현재 테스트 클래스에 사용할 빈을 등록해서 테스트- 원하는 모듈을 빈으로 등록해서 적절하게 테스트 가능
- 테스트 목적에 소홀하고, 스프링 프레임워크 동작에만 의존해서 처리하고 싶어하는 것 같음
- 테스트 어노테이션을 활용해서 DI로만 테스트하려고 했기 때문
- mock, stub 같은 테스트 도구를 사용하는 방법
- 직접 생성자로 인스턴스 생성하는 방법
- 다양한 방법으로 테스트가 가능함
- toString, getter가 추상클래스에서 반환하는 게 이상함
- 실질적으로 작업을 하는 대상은 추상클래스가 아니라 구현 클래스
- 따라서 값을 가져오는 메소드도 구현 클래스에서 책임지는게 맞음
- yaml 파일 프로퍼티 적용하는 방법
- 프로퍼티 클래스 이용 방법
- 어플리케이션 동작은 가능
- 다만, 테스트가 안 됨. → 기각
@Value어노테이션 이용 방법- 어플리케이션 동작
- 마찬가지로 DI로 테스트는 불가
- setter로 경로를 직접 넣어주는 방식으로 테스트 → 채택
- 프로퍼티 클래스 이용 방법
- 에러 메시지, 출력 메시지 분리
- 같은 정적 메시지 클래스라더라도 역할을 기준으로 구분하는게 좋음
- 출력 메시지는 외부 파일로 저장해서 이용하는 방법도 존재
@EnableConfigurationProperties어노테이션- 따로 Configuration 클래스 생성해서 해당 클래스로 관리 가능토록 함
- 테스트 시 Enable되지 않는다면
@ConfigurationProperties가 활성화 되지 않을 수 있음
- 컨트롤러, 서비스, 레포지토리 각 레벨 별 역할
- 컨트롤러
- 사용자 입력, 어플리케이션 동작에 따라 원하는 서비스와 연결 계층
- 서비스
- 어플리케이션이 제공하는 기능 구현 계층
- 레포지토리
- 각 서비스가 활용할 데이터를 얻어오는 계층
- 컨트롤러
- 각 단계별로 주고 받는 데이터 단위(타입)이 다름
- 각 계층 별로 주고받는 데이터는 도메인, Dto로 통일하는게 좋음
- 컨트롤러 - Dto/Domain,
- 서비스, 레포지토리 - Domain
- 파일 String 라인을 도메인으로 변환하고, 컨트롤러에서 다시 String으로 변환하는 불필요한 과정이 발생하더라도 계층 간 데이터 통일에 대한 이득이 더 큼
- 각 계층 별로 주고받는 데이터는 도메인, Dto로 통일하는게 좋음
- 컬렉션 변수명은 record라는 이름 보단 s 복수형을 많이 사용
- Record 타입 클래스와 헷갈리기 때문에 사용하지 않는다고 함
- 대안
- 복수형 사용
- 컬렉션 타입 사용
- 불필요한 Optional 사용 지양
- null 이 발생하지 않도록 하는 것이 1순위요
- optional을 사용하지 않도록 하는 것이 2순위라
- InputConsole, OutputConsole 클래스가 도메인 클래스에 종속됨.
- 최대한 모듈 간 결합도를 낮게 유지해야 함.
- 요구사항 변경으로 특정 타입이 변할 가능성이 있을때 쓸 수 있는 원시값 포장
- 원시값 포장
- 요구하는 데이터 타입이 변하더라도 원시값 포장으로 영향을 줄일 수 있음
- 원시값 포장 클래스만 변경하면 되니까
- 요구하는 데이터 타입이 여러개더라도 적절하게 대응 가능
- VO랑 원시값 포장은 다른거임
- VO는 불변성 보장
- VO는 동등성 보장
- 원시값 포장
- 팩토리 클래스와 서비스의 역할이 중복됨 → 서로 책임을 전가함
- 디자인 패턴은 설계 단계에서 활용할 구간을 미리 정하는 게 좋을 것 같음
- 활용에 신경이 쏠려서 적절한 역할을 하도록 유도하는게 어려운 것 같음
- enum은 동등성 비교 가능
- enum은 클래스 로더가 메모리에 적재할 때 객체를 메모리에 하나만 만들어서 저장
- 동등성(==) 비교에 주소값을 사용하기 때문에 동등성을 사용할 수 있음 (같은 객체니까 주소값도 같음)
- 동일성(equals) 비교보다 동등성 비교가 더 나은 방법임
- 동일성 비교는 런타임 타임에 실행되기 때문에 NPE가 발생 가능
- 동등성 비교는 컴파일 타임에 타입 체크를 하기 때문에 NPE가 발생하지 않고 컴파일 오류가 발생
- 동등성 비교가 훨씬 안정적인 프로그래밍 방법
- 접근지정자 활용을 좀 더 고려해볼것 추상클래스에 선언한 필드를 구현클래스에서 접근하기 위해서
protected키워드를 사용
- 사용하지 않는 파일은 제거할 것
- 설계 단계에서 구상했을때 불필요하다고 생각하는 파일부터 먼저 지워놓고 시작하자
- 빌드 시 사용하지 않는 파일, 빌드에 포함할 필요 없는 파일 제거할 것
- gradle은 참 신기한 친구임. 다재다능함
- 테스트 코드 빌드 포함 X
tasks.withType(Test) { enabled = false } - 빌드 포함하지 않을 파일 지정
sourceSets { main { java { exclude("**/main/resources/voucher_record.csv") } } }
- 테스트 메소드 네이밍에 일정한 컨벤션을 적용하는 것이 좋음
- 테스트 시 given-when-then 패턴을 준수하면서 코드 작성할 것
- 프로그램 제어는 상태로 컨트롤하지 말고, return 으로 상태를 받아서 처리할 수 있도록 할 것
- static 메소드를 만들때 꼭 필요한지 한 번 더 고민해보기
→ 과제 통과!
📝 신경쓰인것들
YAML 프로퍼티 적용하는 방법
세 가지 방법 중에서 @ConfigurationProperties 이용한 방식을 썼다.
다른 방식보다 편하게 적용가능했기 때문.
다만, 한가지 간과한 점이 있었다.
내 방식대로 프로퍼티를 적용하려면 두 가지 조건을 신경써야 한다는 것.
- yaml 파일에 선언한 속성 이름과 프로퍼티 클래스 필드 이름이 일치해야 한다는 것
- 프로퍼티 클래스 필드에 대응하는 getter, setter가 모두 선언되어야 한다는 것
나는 setter를 선언하지 않아서 한참 걸림.
logback 로그 레벨 별로 동작 별도 처리하는 방법
이것도 별 것 아닌데 괜히 오래걸림.
원하는 동작은 이거였음.
- debug 레벨 이상은 그냥 콘솔에 로그 출력
- error 레벨 이상은 파일에 로그 기록
위와 같은 설정을 하기 위해서는 logback.xml 파일을 만들고 거기에서 설정해야 한다.
결론부터 말하자면 두 가지 과정을 통해서 원하는 동작을 구현할 수 있다.
- 파일 기록하는 appender에 filter 속성을 걸어둔다 (error일 때로)
- logger 에 error 레벨로 설정 후 1번 appender를 실행하게 한다.
내가 헤맸던 점은 root와 logger 간의 우선순위 차이였음.
여러 조합을 돌려보면서 느낀점은 이거임.
root: root 레벨 이상을 로깅
logger: 해당 로거의 레벨 이상인 경우 로깅
따라서 logger 레벨이 root 레벨보다 이상 레벨이어야 한다는 것.
그러지 않으면 로그 자체가 출력되지 않는다.
root = debug, logger = error
원하는 동작
root = error, logger = debug
error 레벨만 로깅
root = debug, None
모든 경우에 파일 기록
이렇게 된다.
