
1강. 개요
1. 쿼리 평가 엔진
- 성능 관점에서 가장 중요한 부분 → 특히 실행계획!!
- 계획 세우고 실행하는 DBMS 핵심기능 담당 모듈
- SQL 구문 분석
- 기억장치 데이터 접근 순서 결정 (실행계획)
- 접근 메소드
- 실행계획에 기반 둬서 데이터에 접근하는 방법
2. 버퍼 매니저
- 버퍼 메모리 영역 관리
3. 디스크 용량 매니저
- 데이터 저장 관리
- 데이터 Read / Write 제어
4. 트랜잭션 매니저, 락 매니저
- 트랜잭션 정합성 유지 → 트랜잭션 단위로 처리
- 데이터 락
5. 리커버리 매니저
- 데이터 정기 백업, 복구
2강. DBMS와 버퍼
1. 공짜 밥은 존재하는가?
- 버퍼는 성능에 굉장히 중요한 영향
- 기억비용 : 데이터 저장하는데 소모되는 비용
- 1차 기억장치 : 접근속도 빠름, 기억비용 높음 → 레지스터, 메모리
- 2차 기억장치 : 접근속도 보통, 기억비용 보통 → HDD, CD, DVD, 플래시 메모리
- 3차 기억장치 : 접근속도 느림, 기억비용 낮음 → 테이프
- 영속성과 속도는 반비례 → 트래이드오프 필요
2. DBMS와 기억장치 관계
- DBMS는 데이터 저장을 목적으로하는 미들웨어
- HDD
- 평균적인 효과
- 디스크 접근을 줄일 수 있다면 성능 향상
- 메모리
- 디스크에 비해 기억비용이 굉장히 비쌈
- 버퍼 활용한 성능 향상
- 일부라도 데이터를 메모리에 올리는 것
- SQL 구문 실행속도 빠르게 하는게 목적
- 디스크 접근을 줄이기 위한 목적
- 버퍼 : 버퍼 매니저 이용해서 관리
- 캐시
3. 메모리 위에 있는 두 버퍼
데이터 캐시
- 디스크 데이터 일부를 메모리에 유지하기 위한 영역 (in MEM)
- 굉장히 빠름 (메모리니깐)
- select 처리에 주로 사용
로그 버퍼
- 갱신 처리에 주로 사용 (insert, delete, update, merge)
- 로그 버퍼 위에 변경 정보 보내고 이후 커밋 시점에 디스크 변경 수행 → 비동기 (실행시점 - 갱신시점 다름)
- 커밋 때는 반드시 동기 접근 → 지연 발생
4. 메모리 성질이 초래하는 트레이드오프
- 휘발성
- 전원 끄면 날라감
- 영속성 부재
- 데이터 부정합 발생
- 데이터 캐시는 원본 데이터가 디스크에 남아 있으므로 노상관
- 로그 버퍼에 있는 데이터는 원본이 날아가므로 복구 안 됨
- 커밋 시점에 갱신 정보를 로그 파일로 기록 → 장애 시 정합성 유지 위한 복구에 사용
5. 시스템 특성 따른 트레이드오프
데이터 캐시, 로그 버퍼 크기 차이
- 데이터 캐시 크기가 로그 버퍼보다 월등히 큼
- DB는
검색이 메인이기 때문 - 되도록 데이터 캐시를 많이 할당하도록 권장
검색, 갱신 중에서 중요한 것
- 메모리 할당 자동화 DBMS 도 있지만 믿지마라.
- 로그 버퍼가 크다? → 갱신 처리에 부하 예상
- 데이터 캐시가 크다? → 검색 처리에 부하 예상
6. 워킹 메모리
- 정렬, 해시 관련 처리에 사용되는 추가적인 메모리 영역
- 필요한 때 (정렬, 해시 작업)에 할당, 종료되면 해제 → 임시 영역
- 용량이 부족해지는 경우 저장소(디스크)를 사용하기 때문에 성능에 영향
- 메모리 부족한 시점에 갑자기 느려지는 현상
- 용량이 부족해져도 DBMS는 멈추지 않아
3강. DBMS 와 실행 계획
1. 권한 이양 죄악
- RDB 는 비절차
- 사용자는 대상(what)만 기술
- 시스템은 절차(how) 담당
- 이 방식이 비즈니스 전체 생상성을 향상시키기 때문
2. 데이터 접근 방법 결정
- RDB에서 데이터 접근 절차 결정하는 모듈 = 쿼리 평가 엔진
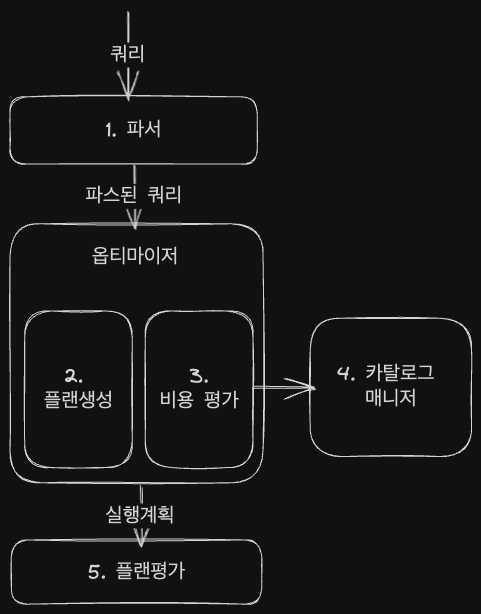
파서
- SQL 구문 분석 → 컴파일 같은 거
- SQL 구문 정형형식 변환 → DBMS 후속처리 효율화
옵티마이저
- 실행계획 최적화
- 선택가능한 많은 실행계획 작성 (플랜생성)
- 비용 연산 (비용 평가)(
- 가장 낮은 비용 실행계획 선택
카탈로그 매니저
- 실행계획 세울 때 옵티마이저에 중요한 정보 제공
- DBMS 내부 정보 모아둔 테이블
- 테이블, 인덱스 통계 정보 저장
플랜 평가
- 최적 실행 결과 선택
- 사람이 읽을 수 있는 문서
3. 옵티마이저와 통계정보
- 옵티마이저 잘 쓰는 게 성능 향상 지름길
- 카탈로그 매니저가 관리하는 통계정보에 대해서 항상 관심
- 통계 정보
- 테이블 레코드 수
- 테이블 필드 수, 필드 크기
- 필드 cardinality (차수: 컬럼 수)
- 필드값 히스토그램
- NULL 수
- 인덱스 정보
- 카탈로그 정보와 실제 테이블, 인덱스 정보 부정합 → 성능 문제
4. 최적 실행계획 작성하려면
- 통계 정보 갱신 필요
- 실행 비용이 굉장히 높지만 최적 플랜 선택을 위해서는 선택 아닌 필수!
4강. 실행 계획이 SQL 구문 성능 결정
1. 실행 계획 확인 방법
- SQL 구문 지연 발생 시 가장 먼저 확인할 것
2. 테이블 풀 스캔 실행 계획
- 실행 계획
- 조작 대상 객체
- 테이블, 인덱스, 파티션, 시퀀스, …
- 객체에 대한 조작 종류
- 실행계획에서 가장 중요한 거
- 조작 대상 레코드 수
- 조작 대상 객체
- 실행 계획 중 실행 비용은 그다지 유력한 척도가 되지 못함 → 예측일 뿐이므로
- 옵티마이저는 실제 테이블을 보지 않고, 통계라는 메타 정보만 보고 실행계획을 세움
3. 인덱스 스캔 실행 계획
- 인덱스 사용해 스캔 수행
- 풀 스캔에 비해서 성능 좋음
- 풀 스캔은 O(n)
- 인덱스 스캔은 O(log N) → B-tree
4. 간단한 테이블 결합 실행 계획
- SQL 지연은 대부분 결합과 관련
- DBMS 결합 알고리즘
- Nested Loops
- 한 쪽 테이블 읽으면서 레코드 하나마다 결합 조건에 맞는 레코드를 다른 쪽 테이블에서 찾는 방식
- Sort Merge
- 결합키로 레코드를 정렬, 순차적으로 두 개의 테이블 결합
- 결합 전 정렬 전처리 → 워킹 메모리 사용
- Hash
- 결합 키 값을 해시값으로 매핑하는 방법
- 결합 전 해시 전처리 → 워킹 메모리 사용
- Nested Loops
- 실행계획은 트리구조
- 중첩단계가 깊을수록 먼저 실행
- 같은 중첩단계에서는 위에서 아래로 실행
- 어떤 테이블에 먼저 접근하느냐가 성능에 영향
5강. 실행 계획의 중요성
- 실행계획을 수동으로 변경할 수 있다.
- 힌트 구를 사용하는 방법
- 그다지 추천 안 함
- DBMS 데이터 캐시가 메모리를 효율적으로 사용하기 위해 사용하는 알고리즘은 무엇인가? LRU (Least Recently Used)

개발하고 말테야