
💡 결합 지배하는 자가 SQL을 지배한다
- RDB는 설계적으로 정규화를 거치기 때문에 테이블 수 많아짐
- 여러 테이블에 산재하는 데이터 통합하려면 역정규화 혹은
결합필요 - 결합은 성능에 영향을 줄 수 있으므로 유의
18강. 기능적 관점으로 구분하는 결합 종류
크로스 결합 - 모든 결합의 모체
- 수학에서의 데카르트 곱
- 2개 테이블 레코드에서 가능한 모든 조합 구하는 연산
- 실무에서 잘 쓰지 않음
- 크로스 결합 결과가 필요한 경우 X
- 비용이 매우 비싼 연산
- 표준 SQL에 맞게 결합 구문을 사용해서 실수로 크로스 결합을 실행하지 않도록 하는 것이 좋음
내부결합
- 가장 많이 사용되는 조합 중 하나
- 결합 키는 양쪽 테이블 모두에 존재하는 필드여야 함
- 내부 결합 결과는 모두 크로스 결합 결과의 일부 (부분집합)
- 내부 = 데카르트 곱의 부분집합
- 실제 연산은 성능 향상을 위해 결합 대상을 축소해서 결합하지만, 결과는 부분집합임
- 기능적으로 상관 서브쿼리를 사용해 대체 가능한 경우 다수
- 기본적으로 결합 사용 지향
- 상관 서브쿼리를 스칼라 서브쿼리로 사용하면 결과 레코드 수 만큼 상관 서브쿼리를 실행하므로, 높은 비용
외부 결합
- 내부 결합과 배타적 연산
- 내부 결합이면서 외부 결합일 수는 없음
- 외부 결합은 데카르트 곱의 부분집합이 아닐 수 있음
- 종류
- 왼쪽 외부 결합
- 오른쪽 외부 결합
- 완전 외부 결합
- 마스터 테이블 쪽에만 존재하는 키가 있을 때는 해당 키를 제거하지 않고 null 로 결과에 보존
- 그래서 데카르트 곱의 부분집합이 아닐 수 있다는 의미
외부 결합 vs 내부 결합
- 외부 결합 결과 ≠ 크로스 결합 부분집합
- 외부 결합이 마스터 테이블의 정보를 모두 보존하고자 null을 생성하기 때문
- 크로스 결합, 내부 결합은 null 생성하지 않음
자기 결합
- 자기 자신과 결합하는 연산
- 같은 테이블(뷰)를 사용해 결합
- 생성되는 결과를 기준으로 분류하는 것이 아나라, 연산 대상으로 무엇을 사용하는지에 따른 분류
- 일반적으로 같은 테이블에 다른 별칭을 붙여 서로 다른 테이블을 대상으로 하는 것처럼 다룸.
19강. 결합 알고리즘과 성능
- 옵티마이저가 선택 가능한 결합 알고리즘
- Nested Loops (근-본)
- Hash
- Sort Merge
- 데이터 크기, 결합 키 분산이라는 요인에 따라 옵티마이저가 어떤 알고리즘을 사용하는지 결정됨
Nested Loops
작동
- 중첩 반복 알고리즘 (=이중 반복 알고리즘)
- 서순
- 결합 대상 테이블(=구동 테이블, 외부테이블) 에서 레코드를 하나씩 반복하면서 스캔
- 구동 테이블 레코드 하나마다 내부 테이블 래코드를 하나씩 스캔해서 결합 조건에 맞으면 리턴
- 이러한 작동을 구동 테이블 모든 레코드에 반복
- 특징
- 모든 DBMS 에서 지원
- 레코드 수 = R(A) * R(B) = Nested Loops 실행 시간
- 한 단계에서 처리하는 레코드 수가 적으므로 Hash, Sort Merge 에 비해 메모리 소비 적음
- 어떤 테이블을 구동 테이블로 사용할 지가 큰 요잉
- 구동 테이블이 작을 수록 성능 좋아짐.
- 이중 반복의 외측, 내측 반복처리가 비대칭이기 때문
- 내부 테이블 결합 키 필드에 인덱스가 존재하는 경우 구동 테이블 작을 수록 성능 향상
- 내부 테이블 인덱스를 통해 DBMS가 내부 테이블을 완전히 순환하지 않아도 되기 때문
- 내부 테이블 인덱스가 없다면 구동 테이블이 작아봐야 무쓸모
단점
- 결합 키로 내부 테이블에 접근할 때 히트되는 레코드가 너무 많은 경우
- 결합 키가 내부 테이블에 대해 유일하지 않은 경우
- 내부 테이블에 인덱스를 사용하고, 구동 테이블이 작더라도 성능이 안 좋을 수 있음
- 해결법
- 구동 테이블을 큰 테이블로 선택
- 내부 테이블에 대한 접근이 기본 키로 수행
- 항상 하나의 레코드 접근이 보장
- 해시 알고리즘
- 구동 테이블을 큰 테이블로 선택
Hash
작동
- 해시
- 입력에 대해 어느정도 유일성, 균일성 가진 값을 출력하는 함수
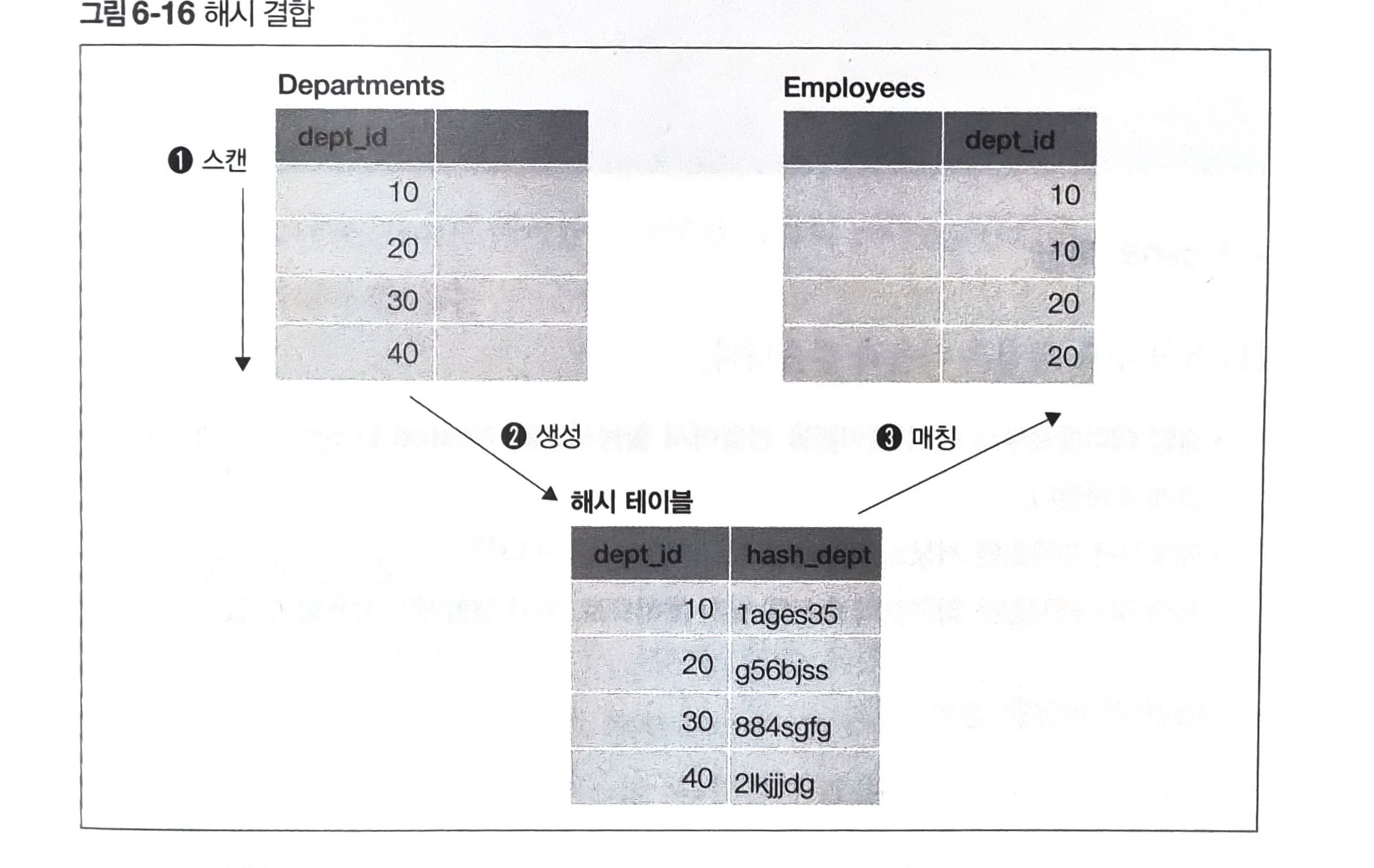
- 서순
- 작은 테이블 스캔, 결합 키에 해시 함수 적용해 해시값으로 변환 (해시 테이블 생성)
- 큰 테이블을 스캔, 결합 키가 해시 값에 존재하는지 확인
- 해시 테이블은 DBMS 워킹 메모리에 저장되므로 조금이라도 작은 것이 효율적이기 때문
- 해시가 사용되는 경우 어떤 한 쪽의 테이블이 극단적으로 작거나, 크지 않음
특징
- 결합 테이블로부터 해시 테이블 만들어서 활용 → Nested Loops 보다 메모리 크게 소모
- 메모리 부족하면 저장소 사용하므로 지연 발생 (TEMP 탈락)
- 동시 실행성이 높은 OLTP(사용자 요구에 즉각 반응) 처리 시 해시 사용하면 저장소 사용 가능성 향상
- 동시 처리가 적은 야간 배치 또는 BI/DWH 같은 시스템에 한해 이용하는 것이 좋음
- 해시값은 입력 값 순서 알지 못하므로, 등치 결합만 사용 가능
- 해시 결합은 반드시 양쪽 테이블 레코드를 전부 읽음
- 이 과정에서 풀 스캔 발생 → 이 점도 고려
해시가 유용한 경우
- Nested Loops에서 적절한 구동 테이블(충분히 작은 테이블)이 존재하지 않는 경우
- 구동테이블로 사용할 만큼 작은 테이블이 있지만, 내부 테이블에서 히트되는 레코드 수가 많은 경우
- Nested Loops 내부 테이블에 인덱스가 없는 경우
- 동시 처리가 적은 시스템
Sort Merge
작동
- 결합 대상 테이블을 각각 결합 키로 정렬, 일치하는 결합 키를 찾으면 결합
특징
- 대상 테이블 모두 정렬해야 함
- Nested Loops 보다 많은 메모리 소비
- 한 쪽 테이블만 해시 테이블을 만드는 Hash 알고리즘보다 많은 메모리 소비
- TEMP 탈락 가능성 가장 높은 알고리즘
- 부정 조건 결합 이외에 모든 결합(동치, 부등호) 사용 가능
<>만 사용 불가- 해시는 동치만 사용 가능
- 테이블이 결합 키로 정렬되어 있다면 정렬 생략 가능
정렬 병합이 유효한 경우
- 결합 시간 자체는 나쁘지 않은 편, 정렬에 많은 리소스 요구
- 테이블 정렬을 생략할 수 있는 경우에만 고려
- Nested Loops, Hash 알고리즘을 우선 고려!
의도하지 않은 크로스 결합
- 삼각 결합
- 세 개의 테이블 중 결합 조건이 없는 두 테이블을 먼저 결합한 경우 → 크로스 결합 발생
- 결합 조건이 없는 두 테이블이 충분히 작다고 옵티마이저가 판단한 경우 이런 실행계획 선택
- 결과적으로 성능 향상이 있을 수 있지만, 이런 경우에 문제가 됨.
- 비교적 큰 테이블끼리 결합 시 크로스 결합이 선택되는 상황
- 검색 조건으로 히트되는 레코드 수가 변하는 상황
- 결합 조건 존재하지 않은 테이블 사이에 불필요한 결합 조건 추가
20강. 결합이 느리다면
상황에 따른 최적의 결합 알고리즘
| 이름 | 장점 | 단점 |
|---|---|---|
| Nested Loops | 작은 구동 테이블 + 내부 테이블 인덱스 = 최강 메모리, 디스크 소비 적음 → OLTP 적합 비등가 결합 가능 | 대규모 테이블 결합에 부적합 내부 테이블 인덱스 없거나, 내부 테이블 히트율 높으면 성능 악화 |
| Hash | 대규모 테이블 결합에 적합 | 메모리 소비량 큰 OLTP 부적합 메모리 부족 시 TEMP 탈락 발생 등가 결합만 가능 |
| Sort Merge | 대규모 테이블 결합에 적합 비등가 결합 가능 | 메모리 소비량 큰 OLTP 부적합 메모리 부족 시 TEMP 탈락 발생 데이터 비정렬 시 비효율적 |
- 소규모 - 소규모
- 어떤 알고리즘 선택해도 큰 차이 X
- 소규모 - 대규모
- 기본적으로 Nested Loops
- 대규모 테이블 결합 키에 인덱스 필요
- 대규모 테이블 결합 키 인덱스 없거나, 히트율이 높으면 대규모 테이블을 외부 테이블로 두거나, 해시 알고리즘 사용
- 대규모 - 대규모
- 기본적으로 Hash 알고리즘
- 정렬된 상태라면 Sort Merge 알고리즘
실행계획 제어
- DBMS 별로 옵티마이저 제어를 힌트구를 이용해서 조작하거나, 못 함.
- 근데 비추
결론
- 결합은 SQL 성능 문제 화약고
- Nested Loops > Hash > Sort Merge
- Nested Loops는
작은 구동 테이블+내부 테이블 인덱스+내부 테이블 낮은 히트율가 전제 - 결합 사용하지 않은 것이 주요 전략
연습 문제
💡 EXISTS, NOT EXISTS 사용하는 경우에도 결합 발생 Nested Loops, Hash 와 다른 변형 형태의 결합 알고리즘- Semi-Join
- 준결합 / 반결합
- 일반적인 결합에는 나타나지 않고, EXISTS 사용시에만 쓰이는 특수 알고리즘
- 결과에 구동 테이블 데이터만 포함
- 1개 레코드는 반드시 1개 결과만 생성
- 내부 테이블에서 조건 맞는 레코드 1개라도 발견한 시점에서 남은 레코드 검색 생략 → 일반 결합 알고리즘보다 좋은 성능
- Anti-Join
- 반결합(이거는 반대할 때 반)
- 일반적 결합 말고, NOT EXISTS 사용시에만 쓰이는 특수 알고리즘
- 내부 테이블에서 조건 맞는 레코드 1개라도 발견한 시점에 남은 레코드 검색 생략
- 구동 테이블 레코드 데이터가 결과에서 제외됨
- EXISTS 와 IN 은 기능상 같은 결과를 얻지만, 성능면에서 다른 결합 알고리즘 사용으로 EXISTS 가 성능 우세

개발하고 말테야